WIP: HashFromNode and VerifyDepTree #959
Conversation
* HashFromNode returns a deterministic cryptographic digest for a directory tree * VerifyDepTree verifies dep tree according to expected digests
|
Clearly the tests fail on the Windows testing rig whereas they pass on my macOS box. I'm glad tests are run on Windows before integration, and caught what's likely to be a bug due to a cross-platform mistake on my part. Yesterday was my OH's birthday. I'll take another look at this on Monday, perhaps even find a Windows box to run the tests on, and push an update when I figure out what I did wrong. |
internal/fs/hash.go
Outdated
| // While filepath.Walk could have been used, that standard library function | ||
| // skips symbolic links, and for now, we want to hash the referent string of | ||
| // symbolic links. | ||
| func HashFromNode(prefix, pathname string) (hash string, err error) { |
There was a problem hiding this comment.
Let's put this cool cat in internal/gps/pkgtree, rather than internal/fs. While we break the rule a bit with the fs functions, this is a key part of the domain solution gps provides, and it should be grouped with it. pkgtree makes sense as a a package to put it in, as this is another operation operating on trees of packages, and it shares some of the same nuanced semantics about what nodes are and aren't visited with pkgtree.ListPackages().
There was a problem hiding this comment.
also, let's return []byte instead of string.
and, style nit: please use named returns only when necessary for disambiguation of return values (which we don't need here).
There was a problem hiding this comment.
I buy everything you suggest here, but after working with the code, and keeping in mind the fact that Gopkg.lock has string versions of digest sums in them, I have a hard time seeing this as []byte rather than a string.
Please provide additional information that I might not be aware of to help me understand this choice.
There was a problem hiding this comment.
there's no strong argument for it - it's really just a consistency thing. i wasn't explicit about it above, but the big reason to move this into gps is because we try to treat gps as a library that has no idea that dep exists. the only exceptions to that right now are some calls into internal/fs, and then some tests that slipped into gps that we need to back out.
the only other place in gps with hashing is when we hash inputs (what shows up in Gopkg.lock as inputs-digest). that returns a []byte; it does so because that's what the sha256 writer returns, and changing it would be expressing an opinion about use - and gps has no opinion about use. maybe it goes to a file, where it must be encoded - or maybe it's being written directly to a database as a bytestream. gps will, at some point in the not-so-distant-future, be moved out of internal, so this isn't just our concern alone.
again, i realize this is totally bikesheddable territory, and there's no definitive, clear reason. just, trying to maintain consistency in the exposed API.
There was a problem hiding this comment.
I actually do not regularly use named return values. A quick perusal of everything I have on github reveals that it's not my style. I thought I saw something else in this library that used it, or perhaps some other library, and I wanted to maintain style discipline. Thanks for the feedback!
There was a problem hiding this comment.
yeah, the named return values was an issue i learned about myself in the course of working on all this. you probably saw some of my detritus 😢
There was a problem hiding this comment.
I completely understand your logic about []byte and string. In fact, I had a follow up question for you were you to actually answer []byte, but you answered my follow up question with a link to other use. The question would have been, "Do we return a byte slice of the hexidecimal output, or the actual raw bytes returned by the digest?" I have made the required changes to the source code to return the raw bytes returned by the digest just as the other link does.
internal/fs/hash.go
Outdated
| } | ||
| joined := filepath.Join(prefix, pathname) | ||
|
|
||
| // Initialize a work queue with the os-agnostic cleaned up pathname. Note |
There was a problem hiding this comment.
For this to be os-agnostic, i think we need filepath.ToSlash(), no? that'll ensure that path separators are always encoded as /.
There was a problem hiding this comment.
Absolutely correct; thanks for the nudge!
internal/fs/hash.go
Outdated
| } | ||
| // Write the referent to the hash and proceed to the next pathname | ||
| // in the queue. | ||
| _, _ = h.Write([]byte(referent)) |
There was a problem hiding this comment.
We need to differentiate between a normal file containing only the path the symlink points to, and an actual symlink. Maybe that's happening elsewhere...?
There was a problem hiding this comment.
Please restate your comment. For all non-skipped file system nodes, we always hash the pathname to the node. Then if it's a symlink, we also hash the referent. Else if it's a directory, we enqueue the sorted list of children. Else if it's a regular file, we hash the file size and the file contents.
There was a problem hiding this comment.
ah, if we're hashing the file size, that sorta incidentally achieves my stated goal, though maybe not entirely.
an example to illustrate - say that we have two nodes, one a file, and one a symlink. the content of the file is /foo, and the referent of the symlink is 4/foo.
is it true that, if the path to either of these nodes is filename, then the data that will be fed to the hasher is filename4/foo?
There was a problem hiding this comment.
@sdboyer, okay after reading your example about a dozen times, I think I understand your scenario. Basically we ought to protect ourselves against scenario of accidental hash collision when the stored symbolic link referent points to node, and when a regular file's contents might match the symbolic link referent. Crazy case here, but valid. I think if we write an addition NULL byte to the hash after every entry we write to the hash. Because NULL bytes are not legal file system characters for Windows or Linux, it provides a entry terminator of sorts, kind of like a new line character would.
This ought to prevent accidental hash collisions due to symlink referents matching the contents of a regular file.
There was a problem hiding this comment.
Okay, latest push writes NULL bytes after writing pathname information to the hash.
internal/fs/hash_test.go
Outdated
| t.Fatal(err) | ||
| } | ||
| expected := "9ccd71eec554488c99eb9205b6707cb70379e1aa637faad58ac875278786f2ff" | ||
| if actual != expected { |
There was a problem hiding this comment.
nit: we try to follow the (general) convention used within golang/go itself, which is "want" and "got" instead of "expected" and "actual". that applies to both var names and printed output.
There was a problem hiding this comment.
we also go a little further in gps by using a convention of:
(GOT): <data>
(WNT): <data>
which helps a bit with scannability. not that it matters with hash digests, ofc - just, again, consistency.
internal/fs/hash.go
Outdated
| } | ||
| } else { | ||
| _, _ = h.Write([]byte(strconv.FormatInt(fi.Size(), 10))) // format file size as base 10 integer | ||
| _, er = io.Copy(h, fh) |
There was a problem hiding this comment.
unfortunately, we have to do a little more than just a straight copy here - at minimum, we have to normalize CRLF to LF so that windows machines are working on the same literal data as the rest. i know that git itself does something like this, though i gave up looking after finding my way to here.
this would certainly explain why the windows appveyor tests are failing with different digests than both the travis failures and the wanted values.
i'm pretty sure this will be a correct operation across all vcs, but that belief needs verification.
There was a problem hiding this comment.
In my mind, at least, and correct me if you think differently, the priority is that the hash be consistent across any version of any of the operating systems supported by Go, and using any of the dep-supported VCS. Please tell me if my view is not consistent with your goals in mind.
Assuming that is agreed, your point about CRLF vs LF translation might reveal quite the complex problem for us to tackle.
We would need to perform CRLF translation on all text files we encounter. Obviously we don't need to mangle the bytes on disk, but just mangle the bytes as we stream them into the hash. (Also, I think we could even get away with in-memory translating every file, including binary ones, with impunity here, but this seems like a bizarre solution.)
Your thoughts?
There was a problem hiding this comment.
Assuming that is agreed, your point about CRLF vs LF translation might reveal quite the complex problem for us to tackle.
yep! i've been worried about this one for a while 😄
(Also, I think we could even get away with in-memory translating every file, including binary ones, with impunity here, but this seems like a bizarre solution.)
after poking at this and thinking about it for a while, i think this would actually be fine - a simple scanner that just reads the bytes into memory and mangles them there, effectively treating \r\n and \n as equivalent. while i wasn't able to find the actual logic in git that does this work, i did at least verify that git hash-object on a file produces the same hash when i replace a \r\n with a \n, so that appears to be the strategy they employ.
the (a?) tricky bit is that we could no longer rely on the file size to be an accurate byte count; we could only know afterwards, after having performed the mangling. i believe that would mean we'd either have to write the file length as a suffix, or keep the entire file's contents in a temporary buffer and then pass it to the hasher after we've reached the end and gotten an accurate count.
There was a problem hiding this comment.
In my mind, at least, and correct me if you think differently, the priority is that the hash be consistent across any version of any of the operating systems supported by Go, and using any of the dep-supported VCS.
oh, and 💯 yes. it's worse than useless if we don't have this property.
internal/gps/pkgtree/pkgtree.go
Outdated
|
|
||
| // LibraryStatus represents one of a handful of possible statuses of a | ||
| // particular subdirectory under vendor. | ||
| type LibraryStatus uint8 |
There was a problem hiding this comment.
"library" is a bit of a loaded term - we avoid it throughout dep/gps in favor of the generic "project", specifically because we do not differentiate between dependencies that contain package main(s) and those that do not.
given that, i think VendorStatus may be better here; these status types are only meaningful in the context of a vendor directory, anyway.
internal/gps/pkgtree/pkgtree.go
Outdated
| // Walk nodes from end to beginning; ignore first node in list | ||
| for i := len(nodes) - 1; i > 0; i-- { | ||
| currentNode = nodes[i] | ||
| // log.Printf("FINAL: %s", currentNode) |
There was a problem hiding this comment.
I will add a bit more embedded documentation to the answer why I create a tree of nodes, then walk them back to front.
* prevents many accidental hash collisions
|
The one thing I have yet to address at this point is the very valid issue of CRLF translations. I'm going to mull it over for a bit. Please let me know if you have a possible solution to this problem. |
The only suggestion i've got is the one i outlined in the code comment - create a new |
No problem. Just so we're on the same page, it will do that for all regular text files, even binary ones. That will not change the overall effect of the effort, because we just want to ensure on all platforms the hash matches.
Easy enough to do, but I'm not sure where this concern came from. Assuming we stream the data through standard libraries buffered handlers, we ought to never have to read the entire file into memory. Did I miss something? |
yep! this may well turn out to be a bad idea, but my mental roadmap suggests that we're going to have some time between when we get this initial PR in and when we actually start using it, during which time we can revisit this assumption.
i mentioned it above - the issue i'm imagining is being able to accurately report the length of files as a prefix on the file. if the algorithm unconditionally mangles CRLF -> LF, then that's going to reduce byte count, and we can't predict how much it'll reduce it until we've walked through the entire file. so, unless i've missed something, writing the modified length as a prefix would entail either reading the entire file (through the mangler) into a buffer, counting the modified length and writing it as a prefix, then flushing the entire buffer into the hasher. or, we avoid the buffer and write, through the mangler, straight into the (FWIW, this doesn't seem quite right to me; it does feel like i've missed something key here) |
|
note, it does appear that git only does the CRLF -> LF transformation on what it guesses to be non-binary files. |
Ah, this is why I misunderstood you. The function uses the file size reported by Also, the function uses the Speaking of which, the updated code includes a |
|
right, all the rest of this is 👍 👍, and what i was expecting. just this bit is what i'm on about:
right, i get that - and the concern i have is that that e.g., a file with these contents: would have size 12 on LF platforms - 3 3-byte long words + 3 bytes of LF - but size 15 on CRLF platforms (3x3 + 3x2). that inconsistency in the |
|
Oh doh! I'll fix that tomorrow morning. 🤓 Another excellent point! |
|
(note - I'm putting this here because i don't have time to write up an issue with fuller context right now, but i also don't want to lose the thought. as i indicated earlier, this PR should continue on the assumption that we can unconditionally mangle CRLF-LF) i went a bit further down the rabbit hole on the question of converting all CRLF->LF, or skipping it for "binary" files. here's an (old) note from mailing list about detecting binary files - https://groups.google.com/forum/#!topic/golang-nuts/YeLL7L7SwWs no surprises there really - "define binary?" - but it's still 😢 🤕 i think the happiest outcome here would be if we can avoid having to answer that question. for me to be comfortable with that, i'd love to have some kind of information theoretic argument that establishes boundaries on what sort of unintended semantic transformations could arise from unconditionally converting CRLF->LF when feeding data to a hash func. that seems like a vanishingly unlikely pipe dream, though, so i'd happily settle for comparable real-world cases where this tradeoff has been made, and what problems (if any) they've encountered. |
|
Since you're in the rabbit hole mood... ;) Any idea why the test fixtures directory, EDIT By print-style debugging, laugh if you must, I have figured out that the test scaffolding directory was in place, and the algorithm has a few few os-specific assumptions in it. Fixing those now. |
|
I don't think it would be difficult to have the I think the performance hit would be near minimal, and implementation could be quite clean. So the issue is not whether we could do it, but in knowing what the unknown side effects of either doing so or not doing so. One possible problem with this idea is false positives or false negatives. In other words, if the algorithm decides a file is binary when it is not, or vice versa, causing hash mismatch on platforms where VCS has done the translation for us on checkout, and we needlessly re-download the projects that have a file that happen to trick the algorithm. The advantage of ignoring the problem for now is we see whether there is impact of performing the translation on every file, binary or not. If we learn that always translating is a problem, we can add in the logic described in the above referenced RFC. However, if we had to revise the hash algorithm later, and projects commit their |
yep, this is exactly why i'm worried about it, and why i want to avoid the question initially. our text/binary determination algorithm must cover a superset of all the underlying source/VCS systems' text/binary determination algorithms. "everything is text and safe to mangle" - the current approach - is far and away the easiest way of ensuring that. |
|
new byte copy algo looks 👍 💯 |
* Only works with directories; no longer with files. * Takes a single argument, that of the directory to hash. * Hashes existance and type of all file system nodes in the directory that it finds. * When hashing file system node names, it no longer includes the prefix matching the directory name parameter.
|
Okay, I think I've caught up on your more recent feedback. Unless there is more we need to do with respect to your concerns about leaking the |
* In line with the original document describing hungarian notation, all file system path variable names have been prefixed with either `slash` or `os` to differentiate whether the variable holds a slash delimited pathname or a pathname delimited by an os-specific pathname delimiter. This is to make it much easier to visually see whether we are using the wrong pathname "type" than desired.
* device files, named pipes, sockets found in a vendor root tree are also reported, and will result in a status of `NotInLock`, because those node types are generally not in source control.
internal/gps/pkgtree/digest_test.go
Outdated
| {[]string{"\rnow is the time"}, "\rnow is the time"}, // CR not followed by LF ought to convey | ||
| {[]string{"\rnow is the time\r"}, "\rnow is the time\r"}, // CR not followed by LF ought to convey | ||
|
|
||
| {[]string{"this is the result\r\nfrom the first read\r", "\nthis is the result\r\nfrom the second read\r"}, |
There was a problem hiding this comment.
so, this case checks for correct behavior when a CRLF breaks across reads. excellent. but, with the way the algorithm carries state from one read to the next, it'd be great to see a few more test cases, just to be sure:
- three read segments, where 1->2 and 2->3 both break across a CRLF
- three read segments, where 1->2 breaks across CRLF and 2->3 does not
- three read segments, where 1->2 breaks across CRLF and 2 ends in CR but 3 does not begin LF
- three read segments, where 1 ends in CR but 2 does not begin LF, and 2->3 breaks across CRLF
- three read segments, where 1 ends in CR but 2 does not begin LF, and 2->3 does not break across CRLF
- four read segments, where 1->2 and 2->3 both break across a CRLF, but 3->4 does not
i'm just trying to put some checks into place that guard us against the possibility of weird OBO errors arising from the end state of a previous read affecting the bookkeeping of a subsequent read. unless some other test cases are covering that sort of thing, and i missed it?
internal/gps/pkgtree/digest_test.go
Outdated
|
|
||
| // NOTE: When true, display the digests of the directories specified by the | ||
| // digest keys. | ||
| if false { |
There was a problem hiding this comment.
i assume this is here for debugging purposes? why not put it down below and have the conditional be on t.Failed(), so that the mismatch will automatically be printed in the event of a failure?
There was a problem hiding this comment.
Great idea! Updated.
| // non-empty file, the file's contents are included. If a non-empty directory, | ||
| // the contents of the directory are included. | ||
| // | ||
| // While filepath.Walk could have been used, that standard library function |
There was a problem hiding this comment.
i meant to mention this earlier, but i thought i'd just point you at #588 - we do want to get away from filepath.Walk() in ListPackages() as well, and a) maybe there's some useful things for you to look at in there and b) maybe we can eventually think about abstracting out this walker implementation a bit so that we can reuse it both here and in ListPackages()
There was a problem hiding this comment.
Which walker implementation, the one created for this issue? If so, it sounds good. I'm happy to pull this out.
Please let me know whether you can foresee any constraints that you would like to ensure we code for, in order to support other requirements, other than the obvious ones that #121 needs.
There was a problem hiding this comment.
Well, I created a DirWalk function which has the exact same semantics as filepath.Walk, plugged it into a new DigestFromDirectoryDirWalk function, and ran benchmarks between the origin and the new. The benchmarks are not promising, and I am not completely certain why the performance has degraded so much.
BenchmarkDigestFromDirectoryOriginal-8 1 2524358442 ns/op
BenchmarkDigestFromDirectoryDirWalk-8 1 4717457411 ns/op
There was a problem hiding this comment.
The above benchmark was performed on one of my systems that has ~1.3 GiB total of file data.
I cannot imagine the performance degradation is due to the additional overhead of calling the anonymous function, which happens to close over a few variables, four of them to be exact.
Because DirWalk is really an excellent drop in replacement for filepath.Walk for when you need to visit every file system node, it makes it very attractive to keep DirWalk around for other portions of this project which may need it.
Just for performance comparison sake, I also benchmarked DigestFromDirectoryDirWalk against DigestFromDirectoryWalk, which invokes filepath.Walk. (I know filepath.Walk does not provide the operational functionality we need for this application, however I wanted to determine whether I was doing something completely wrong. Interestingly, DigestFromDirectoryDirWalk and DigestFromDirectoryWalk performed nearly identically. So perhaps the extra overhead of making the anonymous function call is causing the 1.8x slow down for my particular data set.
On the below graph, the chunk in the middle is using DirWalk. The bizarre stepped chunk on the right is using filepath.Walk, and the very short chunk on the left is using the original function with the embedded directory walk.

There was a problem hiding this comment.
Unless you do extra work (stuff them all in a struct, for example), each variable shared with the closure is allocated separately. That is so that its lifetime is independent of the others, which might be important in some cases. So each closed variable is a malloc, a gc, and a pointer.
If you want tighter code you can try putting your 4 variables in a struct and closing over the struct. That will cost one malloc and gc for all four. And you can try copying the vars into locals if they are accessed in a loop, since otherwise they must be treated like globals and cannot be kept in registers across any function calls.
There was a problem hiding this comment.
Looking at the original function with the embedded directory walk logic, the bulk of time is spent calling io.Copy. There is no observed time spent in lineEndingReader that is not accounted for by bytes.Index or os.(*File).Read. So the original function seems mostly spent waiting on I/O.
There was a problem hiding this comment.
After some more flamegraph splunking, it became apparent that more wallclock time is spent during reading when using DirWalk as compared to using embedded. However, both functions ought to be visiting the same files. Sure enough, a test case showed they both return different digests, so I'm looking into whether they are checking the same file list or not.
There was a problem hiding this comment.
Sure enough, that was the correct problem. The newer method using DirWalk neglected to compare the filepath.Basename(...) to the list of VCS directories and vendor directory, and the DirWalk method was evaluating a lot more data than the original.
The corrected version of DigestFromDirname using DirWalk runs on par with the original version, both in performance and benchmem statistics.
BenchmarkDigestFromDirectory-8 1 2732452505 ns/op 34895296 B/op 286238 allocs/op
BenchmarkDigestFromDirectoryDirWalk-8 1 2593032879 ns/op 34986464 B/op 287065 allocs/op
BenchmarkDigestFromDirectoryWalk-8 1 2551894026 ns/op 31213624 B/op 246494 allocs/op
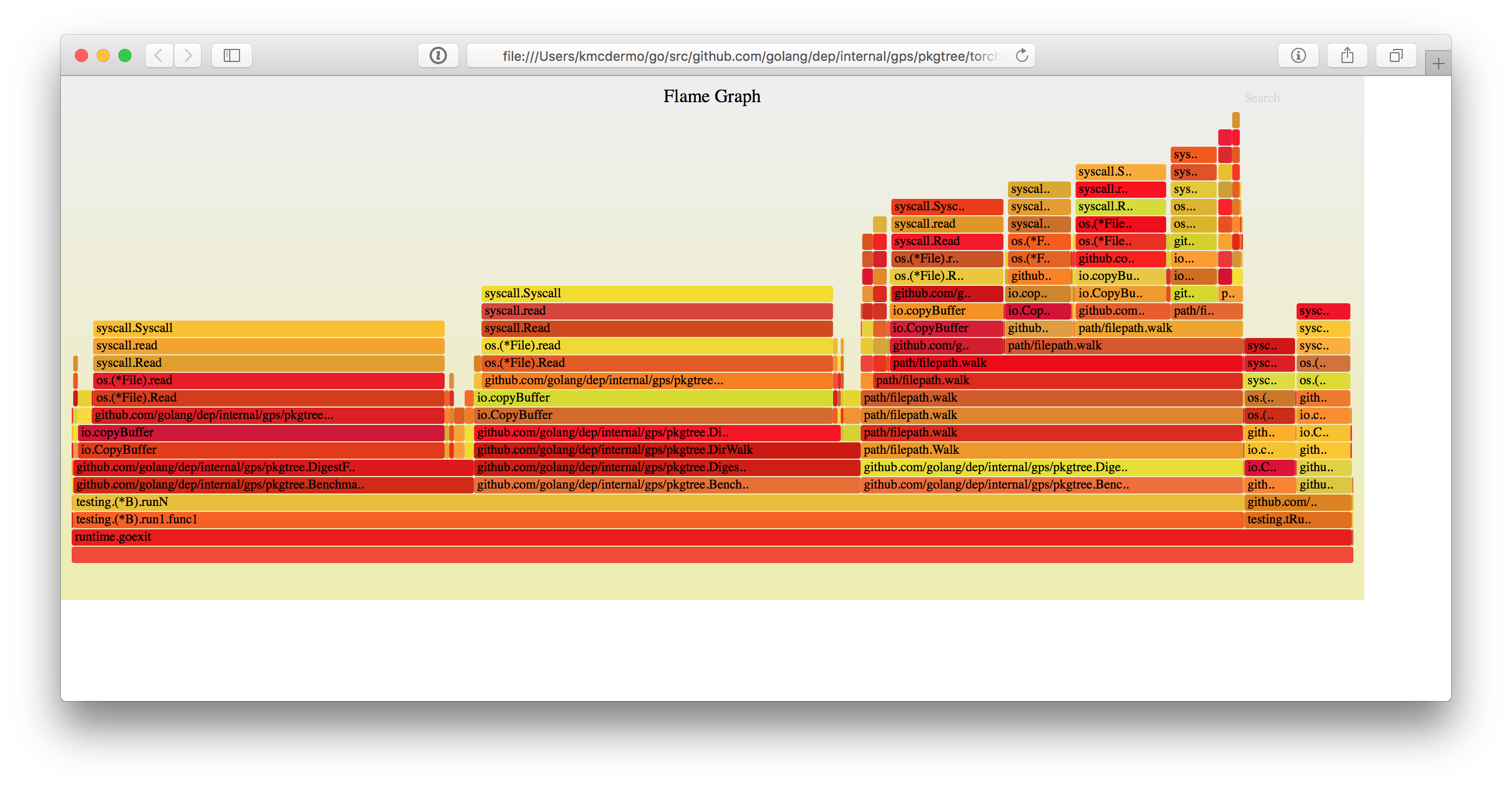
The additional levels in the middle flamegraph compared to the left hand flame graph are due to a higher callstack when the newer method is invoking the anonymous function passed to DirWalk.
|
I've been meaning to ask, what about pesky Perhaps |
|
I am pretty happy with |
|
Also, although |
|
i'm not too worried about The cache dirs, moreover, are aggressive about cleaning up any detritus files that might be left over in there (though bzr and hg probably need more work in this direction). so, even if someone did open them up in Finder, generated |
|
I had meant to ask you, @sdboyer, where ought |
|
@karrick i'd be fine with splitting just to note, i do think there's still some more headroom to be squeezed out of this, though, per some of what we see in #588. i may be wrong that this is the fastest path, but what i'm focused on is the |
|
woohooo! now we can move on to next steps 😄 🎉 🎉 |
|
Looking into |
What does this do / why do we need it?
HashFromNode creates a cryptographic digest (using SHA-256) of the directory rooted at the specified pathname. This can be used to address #121.
VerifyDepTree verifies the dependency tree against a map of known dependencies, along with file system nodes that were not expected to be found.
What should your reviewer look out for in this PR?
Function signatures do not exactly match what @sdboyer requested.
Do you need help or clarification on anything?
Which issue(s) does this PR fix?
These functions were requested in order to address #121. To completely make the
vendor/directory safe for use, every file system node reported byVendorDepTreeasNotInLockought to be removed prior to building software.