x/net/http2, net/http: client can hang forever if headers' size exceeds connection's buffer size and server hangs past request time #23559
Comments
|
/cc @bradfitz @tombergan |
|
Working on a patch to fix this, I realized that using the context deadline to timeout the i/o calls may not be appropriate. |
Addresses hanging transport when on blocking I/O. There are many scenario where the roundtrip hangs on write or read and won't be unlocked by current cancelation systems (context, Request.Cancel, ...). This adds read and write deadlines support. The writer disables the read deadline and enables the write deadline, then after the write is successful, it disables the write deadline and re-enables the read deadline. The read loop also sets its read deadline after a successful read since the next frame is not predictable. It guarantees that an I/O will not timeout before IOTimeout and will timeout after a complete block before at least IOTimeout. See issue: golang/go#23559
Addresses hanging transport when on blocking I/O. There are many scenario where the roundtrip hangs on write or read and won't be unlocked by current cancelation systems (context, Request.Cancel, ...). This adds read and write deadlines support. The writer disables the read deadline and enables the write deadline, then after the write is successful, it disables the write deadline and re-enables the read deadline. The read loop also sets its read deadline after a successful read since the next frame is not predictable. It guarantees that an I/O will not timeout before IOTimeout and will timeout after a complete block before at least IOTimeout. See issue: golang/go#23559
Addresses hanging transport when on blocking I/O. There are many scenario where the roundtrip hangs on write or read and won't be unlocked by current cancelation systems (context, Request.Cancel, ...). This adds read and write deadlines support. The writer disables the read deadline and enables the write deadline, then after the write is successful, it disables the write deadline and re-enables the read deadline. The read loop also sets its read deadline after a successful read since the next frame is not predictable. It guarantees that an I/O will not timeout before IOTimeout and will timeout after a complete block before at least IOTimeout. See issue: golang/go#23559 Change-Id: If618a63857cc32d8c3175c0d9bef1f8bf83c89df
The transport can hang forever if the server hangs after accepting the connection and the request headers (or control frames) exceeds the connection write buffer. Without respect to the context's deadline. The ClientConn writes to the connection without setting a write deadline thus blocks forever if the buffer is flushed to the socket. go test -v -run TestTransportTimeoutServerHangs ./http2
|
Any update here? Keep in mind that there are 3 goroutines per Transport connection to a server:
I think the behavior we want is:
|
There are cases where this isn't working. I believe the graph and tests demonstrates it.
Unfortunately, the writes almost never time out I don't know if this is specific to my use particular use case or if buffering makes it very long to happen. I run this CL in production for a very specific service that only makes requests to APNS and Firebase push gateways. The patch helps to recover from stuck connections and kills it but it's slow to converge, is incomplete and may not work properly for the general use case. What happens is that there are situations where the APNS gateway is blocking the connection, it behaves like a firewall that drops packet never reset the connection. Most of the time the requests are timing out correctly, the context allow to unlock the client stream goroutine and return to the caller however the connection read loop never times out nor receive any other error causing all requests to time out. (Also not that the APNS gateway doesn't allow pings). What I see most often is the writes are not timing out. I believe that the only way to guarantee to time out the connection is have a way to unblock the read loop. The reads (ClientConn) are asynchronous to the writes (ClientStream) so we have to find a way to add a deadline on the reads that will follow the writes (requests) or that follow a read (e.g reading the rest of the body) from the client stream side. The CL takes a simple approach and avoids synchronization between the client stream and the connection read loop. It resets the read deadline and sets a write deadline before every write from the client stream. After the write is done, it sets the read deadline. I wanted to experiment the following algorithm: Upon waiting for something from the network on the ClientStream / caller side, push a deadline in a heap data structure (probably under ClientConn.wmu lock) keeping track of the stream that pushes it. What do you think ? |
|
This is actually worse than just a single connection hanging, it can cause the entire app to hang. The blocking behaviour in both the This means a single connection can block all new requests potentially forever. |
|
@stevenh Could you please share a bit more on the context ? What your app does, which kind of services it talks to and when this kind of behavior happens ? |
|
I'd have to defer to a colleague to answer that but the high-level basics are its making http2 calls and the entire app hung due to this. The relevant stacks from the hung app are: |
|
I believe we just hit this same issue or extremely similar issue with go1.12.7. I have thread stacks from the "blocked" threads from As a result: Possible fixes:
DetailsStripe Veneur periodically sends a set of HTTP2 POSTs and waits for them to complete. When it is getting CPU overloaded, we have observed these calls to Client.Do getting "stuck" for ~10 minutes, even though the HTTP requests set a 10 second deadline. I think the following is happening:
cc.wmu.Lock()
endStream := !hasBody && !hasTrailers
werr := cc.writeHeaders(cs.ID, endStream, int(cc.maxFrameSize), hdrs)
cc.wmu.Unlock()
StacksThe first thread is the writer, holding cc.wmu. The second is the OTHER writer, blocked waiting on cc.wmu. The third is the read loop, for completeness (this lets us see that the http2Framer belongs to the connection, so these are in fact the threads involved in this issue. |
|
It looks like CL https://go-review.googlesource.com/c/net/+/181457/ mentioned on issue #32388 will probably address my issue. |
due to lots of issues with x/net/http2, as well as the hundled h2_bundle.go in the go runtime should be avoided for now. golang/go#23559 golang/go#42534 golang/go#43989 golang/go#33425 golang/go#29246 With collection of such issues present, it make sense to remove HTTP2 support for now
due to lots of issues with x/net/http2, as well as the bundled h2_bundle.go in the go runtime should be avoided for now. golang/go#23559 golang/go#42534 golang/go#43989 golang/go#33425 golang/go#29246 With collection of such issues present, it make sense to remove HTTP2 support for now
due to lots of issues with x/net/http2, as well as the bundled h2_bundle.go in the go runtime should be avoided for now. golang/go#23559 golang/go#42534 golang/go#43989 golang/go#33425 golang/go#29246 With collection of such issues present, it make sense to remove HTTP2 support for now
* fix: metacache should only rename entries during cleanup (minio#11503) To avoid large delays in metacache cleanup, use rename instead of recursive delete calls, renames are cheaper move the content to minioMetaTmpBucket and then cleanup this folder once in 24hrs instead. If the new cache can replace an existing one, we should let it replace since that is currently being saved anyways, this avoids pile up of 1000's of metacache entires for same listing calls that are not necessary to be stored on disk. * turn off http2 for TLS setups for now (minio#11523) due to lots of issues with x/net/http2, as well as the bundled h2_bundle.go in the go runtime should be avoided for now. golang/go#23559 golang/go#42534 golang/go#43989 golang/go#33425 golang/go#29246 With collection of such issues present, it make sense to remove HTTP2 support for now * fix: save ModTime properly in disk cache (minio#11522) fix minio#11414 * fix: osinfos incomplete in case of warnings (minio#11505) The function used for getting host information (host.SensorsTemperaturesWithContext) returns warnings in some cases. Returning with error in such cases means we miss out on the other useful information already fetched (os info). If the OS info has been succesfully fetched, it should always be included in the output irrespective of whether the other data (CPU sensors, users) could be fetched or not. * fix: avoid timed value for network calls (minio#11531) additionally simply timedValue to have RWMutex to avoid concurrent calls to DiskInfo() getting serialized, this has an effect on all calls that use GetDiskInfo() on the same disks. Such as getOnlineDisks, getOnlineDisksWithoutHealing * fix: support IAM policy handling for wildcard actions (minio#11530) This PR fixes - allow 's3:versionid` as a valid conditional for Get,Put,Tags,Object locking APIs - allow additional headers missing for object APIs - allow wildcard based action matching * fix: in MultiDelete API return MalformedXML upon empty input (minio#11532) To follow S3 spec * Update yaml files to latest version RELEASE.2021-02-14T04-01-33Z * fix: multiple pool reads parallelize when possible (minio#11537) * Add support for remote tier management With this change MinIO's ILM supports transitioning objects to a remote tier. This change includes support for Azure Blob Storage, AWS S3 and Google Cloud Storage as remote tier storage backends. Co-authored-by: Poorna Krishnamoorthy <poorna@minio.io> Co-authored-by: Krishna Srinivas <krishna@minio.io> Co-authored-by: Krishnan Parthasarathi <kp@minio.io> Co-authored-by: Harshavardhana <harsha@minio.io> Co-authored-by: Poorna Krishnamoorthy <poornas@users.noreply.github.com> Co-authored-by: Shireesh Anjal <355479+anjalshireesh@users.noreply.github.com> Co-authored-by: Anis Elleuch <vadmeste@users.noreply.github.com> Co-authored-by: Minio Trusted <trusted@minio.io> Co-authored-by: Krishna Srinivas <krishna.srinivas@gmail.com> Co-authored-by: Poorna Krishnamoorthy <poorna@minio.io> Co-authored-by: Krishna Srinivas <krishna@minio.io>
due to lots of issues with x/net/http2, as well as the bundled h2_bundle.go in the go runtime should be avoided for now. golang/go#23559 golang/go#42534 golang/go#43989 golang/go#33425 golang/go#29246 With collection of such issues present, it make sense to remove HTTP2 support for now
due to lots of issues with x/net/http2, as well as the bundled h2_bundle.go in the go runtime should be avoided for now. golang/go#23559 golang/go#42534 golang/go#43989 golang/go#33425 golang/go#29246 With collection of such issues present, it make sense to remove HTTP2 support for now
due to lots of issues with x/net/http2, as well as the bundled h2_bundle.go in the go runtime should be avoided for now. golang/go#23559 golang/go#42534 golang/go#43989 golang/go#33425 golang/go#29246 With collection of such issues present, it make sense to remove HTTP2 support for now
|
So we have a total deadlock scenario that hasn't been fixed for years now. This regularly break hundreds of requests for us because a whole process has to be killed because new requests coming in just sit behind the lock and do not get serviced so we kill the process and abandon any in-progress requests in that process in order to stop creating even more locked requests. I could quickly fix this if sync.Mutex supported TryLock() but that request (only a few lines of code) was rejected because a super strong use case for having it was required. Perhaps being able to fix a very serious bug that can't be fixed for years is a strong enough use case? (Or should we argue about whether the connection mutex should be replaced with a channel instead?) (TryLock proposal: #6123) So, if there is a chance this would be accepted, I'm happy to submit a code change proposal that adds sync.Mutex.TryLock() and then uses it to not deadlock when looking for a connection to reuse (by not considering connections that are currently locked and so really can't be reused with any guarantee of timeliness anyway). |
|
FWIW, I concur with the quibble about the name and would be happy to call it LockIfNoWait(). |
|
@TyeMcQueen what all is this pertaining with, I'm dealing with a bug on my PC that I'm not exactly sure how to execute the correct code for the fix |
|
FWIW, I am currently testing my 14-line fix for this problem (but it is not my first priority so that testing will have to be done as I can find time over the next while). |
|
I have found two other places where cc.mu.Lock() can be called while p.mu.Lock() is in effect and will apply similar fixes. Though I don't have evidence of those particular flows causing lock-up in the wild. The logic is still sound for all 3 cases: Locked connections should just be skipped until the next time. |
|
Change https://golang.org/cl/347299 mentions this issue: |
|
I don't believe the TryLock approach is the right fix here. In the usual case where the server is responsive and we do not exceed the server per-connection stream limit, we want to create a single HTTP/2 connection and use it for all requests. Creating a new connection whenever we are unable to unlock any existing connection means that we will create new connections much more aggressively. If, for example, we make ten simultaneous requests, we will be very likely to create several new connections as all the requests contend for the connection lock. The TryLock-based patch above also completely breaks the Possibly we should have a way to create multiple HTTP/2 connections to a single server even before we exceed the stream limit on a single connection, but if so, this should be done more deliberately than creating new connections every time two requests briefly contend on a mutex. The right fix to avoid connection pool deadlocks (#32388) is to avoid holding the connection mutex indefinitely during blocking operations, such as header writes. I have a proposed fix for that in CL 349594. The right fix to avoid requests hanging past the request deadline when writing headers blocks (this bug, as distinct from #32388) is to watch for cancelation while writing. Unfortunately, this means we need to move header writes to a separate goroutine, since there is no simple way to bound a write to a |
|
Change https://golang.org/cl/353870 mentions this issue: |
|
@gopherbot please open backport issues. |
|
Backport issue(s) opened: #48822 (for 1.16), #48823 (for 1.17). Remember to create the cherry-pick CL(s) as soon as the patch is submitted to master, according to https://golang.org/wiki/MinorReleases. |
What version of Go are you using (
go version)?Does this issue reproduce with the latest release?
Yes
What operating system and processor architecture are you using (
go env)?Also happened on
linux/amd64, see below.What did you do?
A bug in production showed an http2 client hanging more than 250 seconds without respect to the request context which was set to timeout after 5 sec.
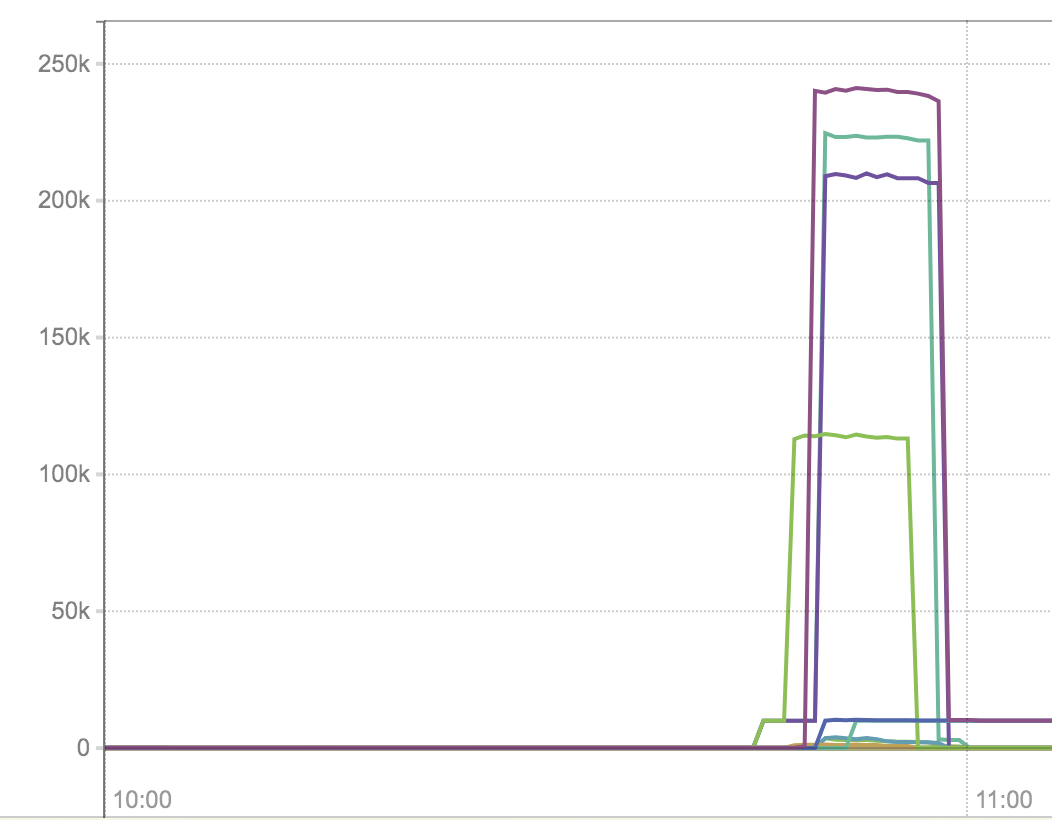
All possible timeouts are set on connection and TLS handshake and I didn't see many dials (they are monitored).
Latency graph in ms:
Clients are using net/http2.Transport directly.
What did you expect to see?
The requests should have timed out after 5s.
What did you see instead?
No or very long timeouts (I believe the server has reset the connection or TCP timed out).
The synchronous write
cc.writeHeadersto the connection inClientConn.roundTripdoes not set any deadline on the connection which can block forever (or being timed out by TCP) if the server or network hangs:https://github.com/golang/net/blob/0ed95abb35c445290478a5348a7b38bb154135fd/http2/transport.go#L833
I wrote a test that demonstrates this:
gwik/net@e4c191a
Setting the write deadline fixes the test:
gwik/net@052de95
It seems to fail when the header value exceeds 1MB.
I might miss something here, the default buffer size ofbufio.Writeris 4096 bytes, I had expected to see it fail around that value, maybe compression and/or TCP buffers...Also I don't think it sent 1MB headers when it failed in production something else must have fill the buffer.
The buffer is on the connection and shared among streams the buffer can be filled by other requests on the same connection.
Besides this particular call which is synchronous, no write nor read to the connection has a deadline set. Can't this lead to goroutine leaks and http2 streams being stuck in the background ?
The text was updated successfully, but these errors were encountered: