Disclaimer: This is not an official Google product.
What it solves • How it works • Get started • References
🍞 ML-ToAST is a tool that helps users cluster multilingual search terms captured from different time windows into semantically relevant topics. It helps advertisers / marketers surface the topics or themes their audience are interested in, and accordingly tailor their marketing activities.
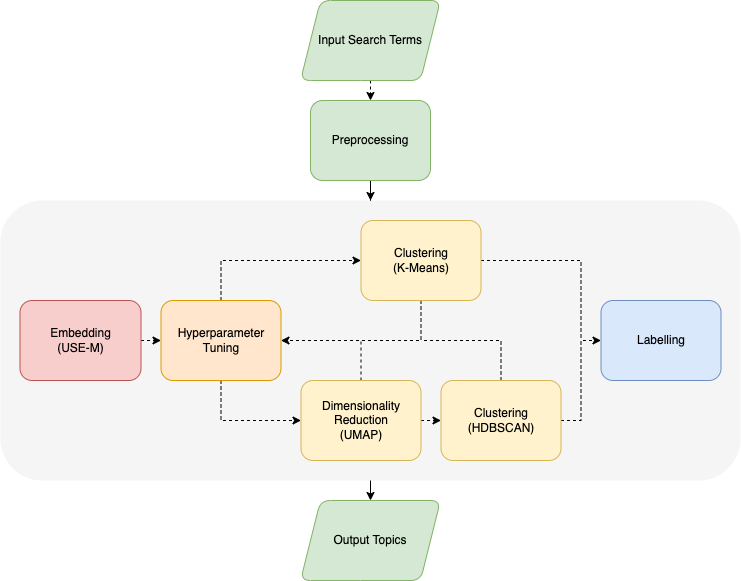
Under the hood, the tool relies on Google's Universal Sentence Encoder Multilingual model to generate word embeddings, applies a couple of widely-used clustering algorithms - namely K-Means and HDBSCAN (with UMAP dimensionality reduction) - to generate clusters, and then selects the most meaningful term(s) to represent each cluster. Input / Output is supported via Google Sheets and Google Cloud BigQuery.
Though the samples provided here are specific to Google Ads, the same approach can quite seamlessly be used for any other advertising platform, or simply for any application where clustering of short texts is the goal.
Advertisers spend a significant amount of time analyzing how customers are searching for and engaging with their business, in order to understand:
- Where their existing offerings resonate most; and
- How they can tailor facets of their ads, such as landing pages and creatives, to match changing consumer interest.
One of the approaches advertisers rely on is analyzing search queries against which their ads appear, categorizing these queries into meaningful themes, and analyzing themes to generate insights.
Topic clustering requires both time and expertise to execute properly, and may be computationally resource intensive.
In the context of Google Ads, the Search Terms report for a particular account lists all the search queries that have triggered the ads defined in that account, along with performance metrics (such as clicks, impressions, etc.). It is important to note that certain search terms that don't have enough query activity are omitted from the report in order to maintain Google's standards on data privacy.
Google Ads: though the Search Terms report can be downloaded and analyzed, it is cumbersome for advertisers to sift through thousands of queries - usually in multiple languages - to extract meaningful insights.
Google Ads employs several different AI-powered search optimization features, one of which is Broad Match. Whereas other keyword matching types focus only on syntax, Broad Match applies matching based on semantics - the meaning conveyed by a search - in addition to syntax. BM also looks at additional signals in the account - which include landing pages, keywords in ad groups, previous searches, and more - in order to match more relevant traffic.
Google Ads: the need to understand changing user interest is becoming ever more important, particularly with automated search optimization (e.g. Broad Match) becoming more fundamental.
Google Ads also provides search term insights within its user interface (UI). Search terms that triggered ads over the past 56 days are automatically analyzed and grouped into categories and subcategories, including performance metrics.
Google Ads: search term insights - though technologically more sophisticated than the methodology applied here - cover the past 8 weeks only, are not available beyond the UI, and cannot be collated across accounts.
🍞 ML-ToAST tackles the challenges mentioned above in a simple, configurable and privacy-friendly way. Input is supported via a Google Sheets spreadsheet or Google Cloud BigQuery table. For spreadsheet-based input, search terms from different lookback windows can be compared (configurable) to uncover terms that are new / trending, or also those that have not received enough impressions (configurable - unset by default). For BigQuery, the input is used as-is, therefore any filtering or lookback comparison needs to be done in BigQuery directly. This input data represents the corpus of search terms that can be further analyzed and categorized into semantically relevant topics.
Additional input groups pertaining to Google Ads Broad Match (BM) are extracted and analyzed to:
- Provide more transparency into BM's performance; and
- Give advertisers more control via keyword recommendations that they could add to / exclude from BM.
The figure below provides an overview of the core functionality of the tool.
The quickest way to get started with 🍞 ML-ToAST is to load the ml_toast.ipynb
notebook in Google Colaboratory via the link below:
The notebook provides an easy to use interface for configuring and running the tool, along with a code walkthrough and results visualization.
Alternatively, you can build the tool using the provided requirements.txt:
pip install -r requirements.txtand run topic_clustering.py manually, passing in the desired arguments:
Usage:
topic_clustering.py --csv_data_path=<INPUT_DATA_PATH>
--output_path=<OUTPUT_DATA_PATH>
[--data_id=<INPUT_DATA_ID>]
[--input_col=<INPUT_DATA_COLUMN>]
[--output_kmeans_col=<OUTPUT_KMEANS_COL>]
[--output_hdbscan_col=<OUTPUT_HDBSCAN_COLUMN>]
[--stop_words=<STOP_WORDS>]
[--kmeans_clusters=<KMEANS_CLUSTERS>]
[--umap_n_neighbors=<UMAP_N_NEIGHBORS>]
[--umap_n_components=<UMAP_N_COMPONENTS>]
[--umap_random_state=<UMAP_RANDOM_STATE>]
[--hdbscan_min_cluster_size=<HDBSCAN_MIN_CLUSTER_SIZE>]
[--hdbscan_min_samples=<HDBSCAN_MIN_SAMPLES>]
[--opt_threshold_unclustered=<OPT_THRESHOLD_UNCLUSTERED>]
[--opt_threshold_recluster=<OPT_THRESHOLD_RECLUSTER>]
[--hyperparameter_tuning] [--nohyperparameter_tuning]Options:
--help show this help message
--csv_data_path=<INPUT_DATA_PATH>
path to a csv file containing the data to use. Defaults
to the path 'samples/data.csv' relative to the current
(root) directory.
--output_path=<OUTPUT_DATA_PATH>
path where the output should be stored. Defaults to the
path 'output/data.csv' relative to the current (root)
directory.
--data_id=<INPUT_DATA_ID>
identifier of the input data. Useful for logging when
running the module with different inputs. Defaults to
the value 'data'.
--input_col=<INPUT_DATA_COL>
column in the input data corresponding to the
documents to cluster. Defaults to the value 'document'.
--output_kmeans_col=<OUTPUT_KMEANS_COLUMN>
column to write the generated K-Means cluster
assignments to. Defaults to the value 'topics_kmeans'.
--output_hdbscan_col=<OUTPUT_HDBSCAN_COLUMN>
column to write the generated HDBSCAN cluster
assignments to. Defaults to the value 'topics_hdbscan'.
--stop_words=<STOP_WORDS>
list of custom words to use as stop words for the
generated topic labels. Defaults to None.
--kmeans_clusters=<KMEANS_CLUSTERS>
list of clusters to use to identify the optimal value of
K. Defaults to the range 5-15.
--umap_n_neighbors=<UMAP_N_NEIGHBORS>
hyperparameter 'n_neighbors' for UMAP. Defaults to 15.
See https://umap-learn.readthedocs.io/en/latest/parameters.html#n-neighbors
for more information.
--umap_n_components=<UMAP_N_COMPONENTS>
hyperparameter 'n_components' for UMAP. Defaults to 30.
See https://umap-learn.readthedocs.io/en/latest/parameters.html#n_components
for more information.
--umap_random_state=<UMAP_RANDOM_STATE>
random seed for UMAP. Defaults to None.
Consider setting an explicit value (e.g. 32) for
reproducability. See https://umap-learn.readthedocs.io/en/latest/reproducibility.html
for more information.
--hdbscan_min_cluster_size=<HDBSCAN_MIN_CLUSTER_SIZE>
hyperparameter 'min_cluster_size' for HDBSCAN. Defaults
to 20. See
https://hdbscan.readthedocs.io/en/latest/parameter_selection.html#selecting-min-cluster-size
for more information.
--hdbscan_min_samples=<HDBSCAN_MIN_SAMPLES>
hyperparameter 'min_samples' for HDBSCAN. Defaults to 5.
See https://hdbscan.readthedocs.io/en/latest/parameter_selection.html#selecting-min-samples
for more information.
--opt_threshold_unclustered=<OPT_THRESHOLD_UNCLUSTERED>
1 of 2 thresholds for optimizing generated HDBSCAN
clusters through linear regression. This represents the
threshold for clustering unassigned data points (HDBSCAN
label = -1). Defaults to assign data points with at
least 40% (0.4) predicted cluster assignment confidence.
--opt_threshold_recluster=<OPT_THRESHOLD_RECLUSTER>
1 of 2 thresholds for optimizing generated HDBSCAN
clusters through linear regression. This represents the
threshold for reclustering assigned data points (HDBSCAN
label != -1). Defaults to reassign data points with at
least 80% (0.8) predicted cluster assignment confidence
from their original HDBSCAN cluster to their predicted
cluster.
--hyperparameter_tuning --nohyperparameter_tuning
whether to perform bayesian optimization to find the
optimal hyperparameters for UMAP + HDBSCAN or not.
Defaults to True.Please note that the tool relies on the
tensorflow-textpackage, which is no longer available for all platforms (e.g. Apple Macs and Windows) and accordingly might need to be built from source. Refer to these instructions for more information.
To cite this repository:
@software{ml_toast_github,
author = {Mohab Fekry and Christiane Ahlheim and Victor Paunescu},
title = {ML-ToAST: Multilingual Topic Clustering of Ads-triggering Search Terms},
url = {https://github.com/google/ml_toast},
version = {0.1.0},
year = {2023},
}