爬取一个或多个微博账号的内容(包括原创和转发),设置(一个或多个)关键词条件,进行推送。
以爬 wu2198 的微博为例,我们需要修改config.json文件,文件内容如下:
{
"user_id_list": ["1216826604"],
"filter": 0,
"remove_html_tag": 1,
"since_date": 1,
"start_page": 1,
"write_mode": ["sqlite"],
"original_pic_download": 0,
"retweet_pic_download": 0,
"original_video_download": 0,
"retweet_video_download": 0,
"download_comment":0,
"comment_max_download_count":100,
"result_dir_name": 0,
"cookie": "{your cookie}",
"mysql_config": {
"host": "localhost",
"port": 3306,
"user": "root",
"password": "123456",
"charset": "utf8mb4"
},
"user_keywords": {
"1216826604": ["仓","买","干","T","大家","%"]
},
"push": {
"method": "push_plus",
"token": "{your token}"
}
}
详细信息见程序设置。
配置完成后运行程序:
$ python weibo.py- 开发语言:python2/python3
- 系统: Windows/Linux/macOS
$ git clone https://github.com/gxcuit/weiboNotify.git运行上述命令,将本项目下载到当前目录,如果下载成功当前目录会出现一个名为"weiboNotify"的文件夹;
$ pip install -r requirements.txt打开config.json文件,你会看到如下内容:
{
"user_id_list": ["1216826604"],
"filter": 0,
"remove_html_tag": 1,
"since_date": 1,
"start_page": 1,
"write_mode": ["sqlite"],
"original_pic_download": 0,
"retweet_pic_download": 0,
"original_video_download": 0,
"retweet_video_download": 0,
"download_comment":0,
"comment_max_download_count":100,
"result_dir_name": 0,
"cookie": "{your cookie}",
"mysql_config": {
"host": "localhost",
"port": 3306,
"user": "root",
"password": "123456",
"charset": "utf8mb4"
},
"user_keywords": {
"1216826604": ["仓","买","干","T","大家","%"]
},
"push": {
"method": "push_plus",
"token": "{your toksen}"
}
}
下面讲解推送需要设置的参数的含义与设置方法。
设置user_id_list
user_id_list是我们要爬取的微博的id,可以是一个,也可以是多个,例如:
"user_id_list": ["1223178222", "1669879400", "1729370543"],
上述代码代表我们要连续爬取user_id分别为“1223178222”、 “1669879400”、 “1729370543”的三个用户的微博,具体如何获取user_id见 如何获取user_id。
设置filter
filter控制爬取范围,值为1代表爬取全部原创微博,值为0代表爬取全部微博(原创+转发)。例如,如果要爬全部原创微博,请使用如下代码:
"filter": 1,
设置cookie(可选)
cookie为可选参数,即可填可不填,具体区别见添加cookie与不添加cookie的区别。cookie默认配置如下:
"cookie": "your cookie",
如果想要设置cookie,可以按照如何获取cookie中的方法,获取cookie,并将上面的"your cookie"替换成真实的cookie即可。
设置推送的关键词
在实际中,可能并不想关注的微博用户一发微博就进行推送。因此可以设置关键词,只有微博中包含指定的关键词,才进行推送。关键词的设置如下:注意:key是user_id,value是关键词列表。可以设置一个或多个用户。如果想推送所有的微博(也就是不设置关键词),将关键词设置为 [""] 即可。
"user_keywords": {
"1216826604": ["仓","买","干","T","大家","%"]
}
设置推送渠道及token
目前只支持pushPlus, 注册后将token填入即可。
大家可以根据自己的运行环境选择运行方式,Linux可以通过
$ python weibo.py运行;
- 首先修改
run_script.sh - 增加crontab
*/1 * * * * /bin/bash /root/workspace/weiboNotify/run_script.sh
本部分为可选部分,如果你不需要自己修改代码或添加新功能,可以忽略此部分。
本程序所有代码都位于weibo.py文件,程序主体是一个Weibo类,上述所有功能都是通过在main函数调用Weibo类实现的,默认的调用代码如下:
if not os.path.isfile('./config.json'):
sys.exit(u'当前路径:%s 不存在配置文件config.json' %
(os.path.split(os.path.realpath(__file__))[0] + os.sep))
with open('./config.json') as f:
config = json.loads(f.read())
wb = Weibo(config)
wb.start() # 爬取微博信息用户可以按照自己的需求调用或修改Weibo类。
1.打开网址https://weibo.cn,搜索我们要找的人,如"迪丽热巴",进入她的主页;
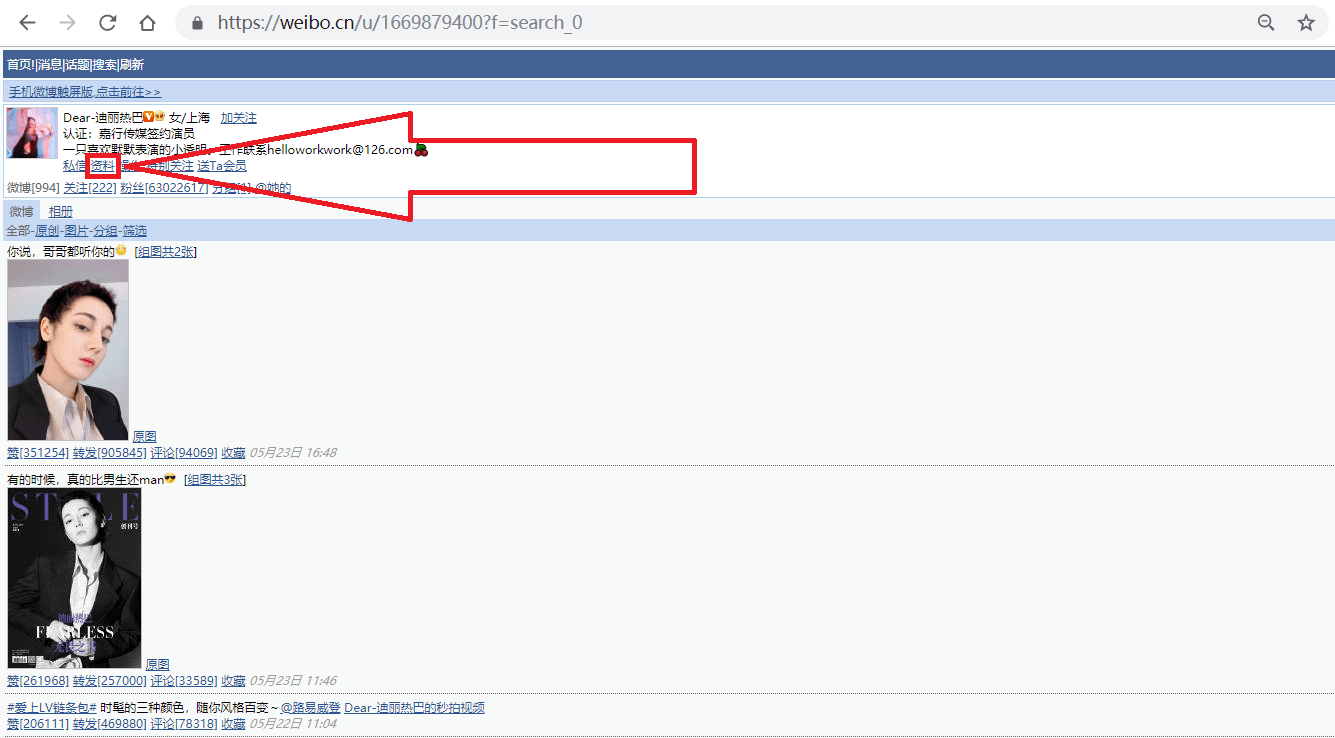
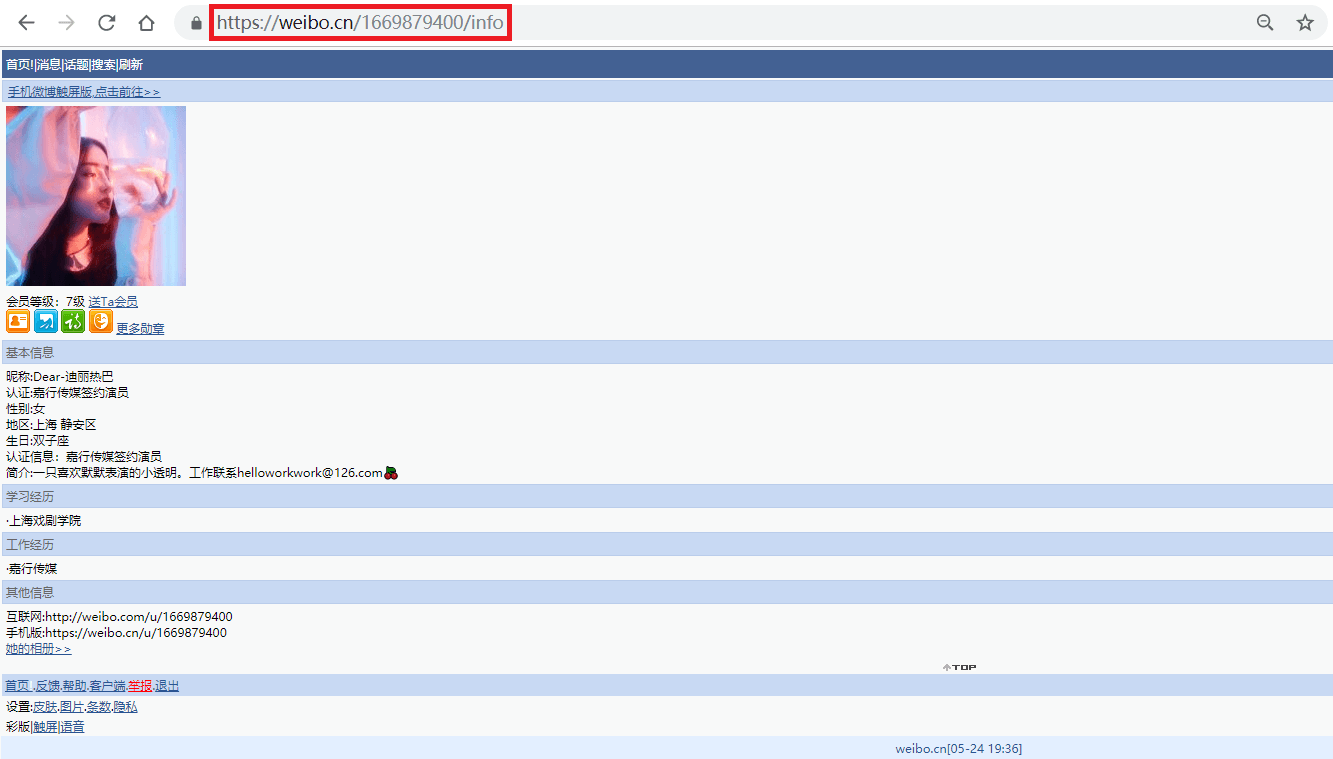
事实上,此微博的user_id也包含在用户主页(https://weibo.cn/u/1669879400?f=search_0)中,之所以我们还要点击主页中的"资料"来获取user_id,是因为很多用户的主页不是"https://weibo.cn/user_id?f=search_0"的形式,而是"https://weibo.cn/个性域名?f=search_0"或"https://weibo.cn/微号?f=search_0"的形式。其中"微号"和user_id都是一串数字,如果仅仅通过主页地址提取user_id,很容易将"微号"误认为user_id。
对于微博数2000条及以下的微博用户,不添加cookie可以获取其用户信息和大部分微博;对于微博数2000条以上的微博用户,不添加cookie可以获取其用户信息和最近2000条微博中的大部分,添加cookie可以获取其全部微博。以2020年1月2日迪丽热巴的微博为例,此时她共有1085条微博,在不添加cookie的情况下,可以获取到1026条微博,大约占全部微博的94.56%,而在添加cookie后,可以获取全部微博。其他用户类似,大部分都可以在不添加cookie的情况下获取到90%以上的微博,在添加cookie后可以获取全部微博。具体原因是,大部分微博内容都可以在移动版匿名获取,少量微博需要用户登录才可以获取,所以这部分微博在不添加cookie时是无法获取的。 有少部分微博用户,不添加cookie可以获取其微博,无法获取其用户信息。对于这种情况,要想获取其用户信息,是需要cookie的。
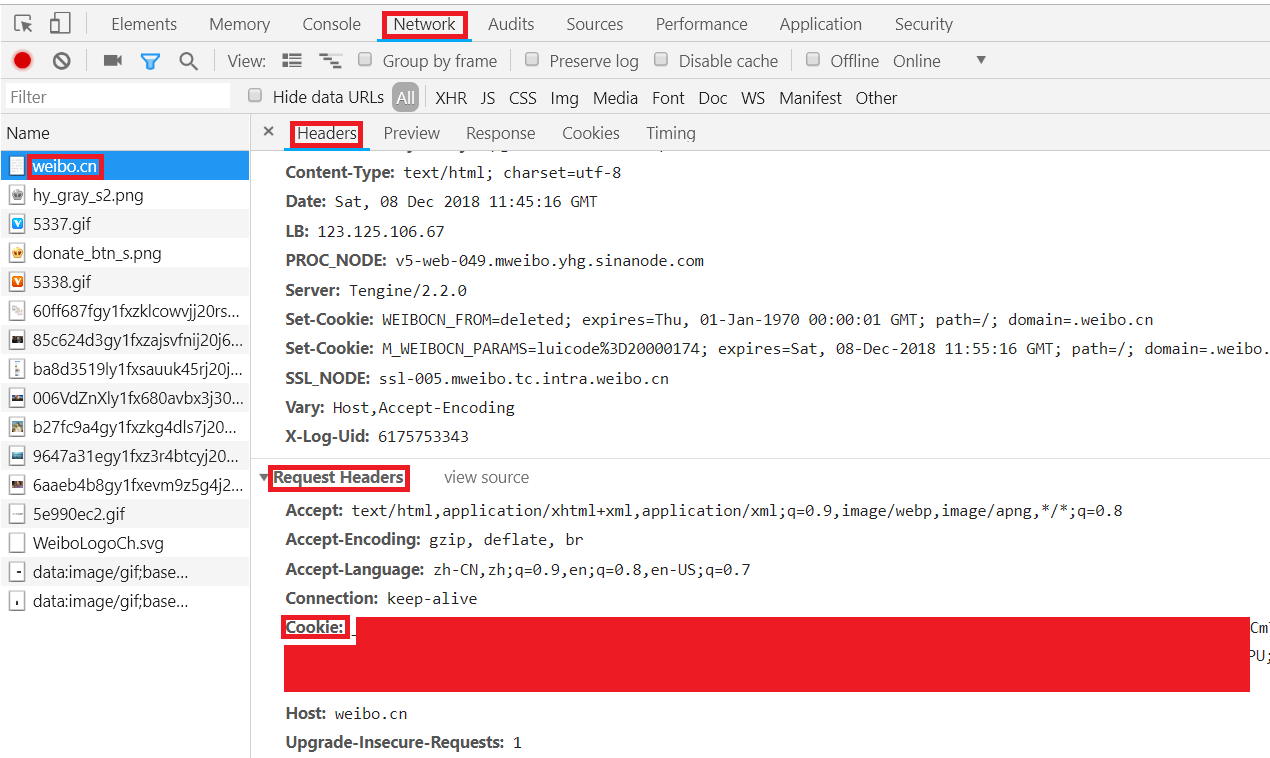
1.用Chrome打开https://passport.weibo.cn/signin/login;
2.输入微博的用户名、密码,登录,如图所示:
3.按F12键打开Chrome开发者工具,在地址栏输入并跳转到https://weibo.cn,跳转后会显示如下类似界面: