Author: Andreas Hadjiprocopis (andreashad2@gmail.com)
A collection of R procedures bundled inside a bash script.
The bash script can be run from the command line and provides
a very convenient way to execute tedious R procedures
with command-line parameters, debug capabilities and parallelisation
when appropriate. Specifically for parallelisation, all scripts understand
the -p num_threads option when multiple data is to be processed in
parallel over the specified number of threads. For an example of this
see Density Distribution Plots further down.
A bit of a warning: these scripts were written between 2009 and 2013.
They heavily rely on R package ggplot2 for rendering graphics and plots.
Since then ggplot2 has seen
major changes and older code has difficulties running along.
I have revised a lot of my scripts to catch up with newer ggplot2
versions. At least now they do run and do produce output.
But whenever the output of the scripts
is a plot, a graph you will find it at least aesthetically challenging.
For the purpose of demonstrating the scripts in this project
we need some random
data of arbitrary dimensions. To this end, the script
produce_random_dataset.pl can be used as follows:
produce_random_dataset.pl --N 100 --L 10000 --min -1.0 --max 1.0 --output data_100x10000.txt
- `-i an-input-file`
- `-o an-output-file`
- `-c 3,4,10 or -c 3 -c 4 -c 10` : operate only on these 3 columns of the input file. I do not need to tell you how useful this feature is.
- `-C 3,4,10 or -C 3 -C 4 -c 10` : IGNORE these 3 columns (and operate on all the rest).
- `-z 'foldchange' -Z 'duration'` : same as -c, i.e. choosing columns to operate on, by using column names IF a header exists (which will define column names).
- `-Z 'foldchange' ...` : same as -C, i.e. ignore these columns specified by the column name, only if a header is present!
- `-2 1234` or `-S 1234` : specify the seed to the random number generator.
- `-3 W,H,FS` : Width, Height and FontSize in the output PNG file - if any is produced.
- `-R Rscript_name` : specify the name of the R script which the bash scripts produce and run. At the end this file will not be deleted.
- `-H` : display help message
- `-h` : input data file contains a one-line header with the column names.
- `-e separator-string` : a string (or char) denoting the separator between columns. Common separators are space (-e ' '), comma (-e ','), tab (-e $'\t' <--- bash idiom for tab)
It will take a textfile spreadsheet (by which I mean rows and columns with optional header) and do PCA on it using R's prcomp.
There are various options in this script and pca_in_R.bash -H will
print a help message.
- The most important are:
- `-t preprocessingTransformationName` : transform the input data with one of the following: `none` (default), `scale`, `center`, `scale and center`
- `-u` : reverse PCA, i.e. you have already done PCA and you now want to apply the loadings to some new data. Use -L to specify the loadings matrix filename.
- `-v num_from_0_to_1` : specify the proportion of variance to capture (e.g. 0.75). It will discard dimensions which do not contribute to the variance
It will take a textfile spreadsheet
(by which I mean rows and columns with optional header),
do PCA on it (using pca_in_R.bash which is a standalone script)
and produce a plot in 2D of the PCAed data.
Here is one example with our random dataset:
visualise_high_dimensional_data_in_R.bash -i data_100x10000.txt -o visualise_in_2d.png -e $'\t'
The options -i and -o are for specifying the input and the output filenames. Option -h specifies that there is a header line at the beginning and should be ignored when reading the data. We do not need this option in this case.
Option -e $'\t' specifies that the separation between the columns is a TAB.
It could have been set to space or comma.
And here is the result 2D visualisation plot:

Which is what we expected because our data is a uniform distribution centred at 0.
The script cluster_in_R.bash will take an input data file (text spreadsheet)
and cluster it with any method specified, e.g. kmeans_lloyd, pam and a few others
and any distance metric specified, e.g. euclidean, max, manhattan, canberra, etc.
The number of clusters is required (for some clustering methods, e.g. kmeans) and can
be specified with the -N option.
The max number of iterations to convergence can be specified using -t option.
Here is an example:
cluster_in_R.bash -i data_100x10000.txt -o results -m kmeans_lloyd -M euclidean -N 3 -t 1000
The output consists of 3 files: general info (.info), cluster centers (.centers), cluster sizes (.sizes) and the most important, the cluster membership which for each row of input it assigns a label to one of the clusters (e.g. 1,2 or 3). Cluster labels start from 1.
Scatter plot is simply plotting two variables, one on the x-axis and the other on y-axis.
Here is how we do it.
scatter_plot_in_R.bash -i data_100x10000.txt -c 1:30 -o simple_scatter_plot
And here is the result,

The script scatter_plot_of_two_groups_with_densities_in_R.bash will take
one or more column-pairs, plot them as a scatter plot and in the same
plot estimate the density distribution of each column and append this
to the plot as well. Multiple column-pairs can be used and will all
be plotted on same plot (one output file).
What is a column-pair? Simply, it consists of two columns of data. For example data about the width and height of several rectangles. The first column is width the second column is height and each row is one distinct rectangle. Our aim is to estimate the density distribution of widths and heights separately. And also plot width against height for all data rows (rectangles in this case).
Similarly, in cell morphology analysis we may wish to see how
the relationship of cell area versus cytoplasm area for example.
Assume that our dummy data file (data_100x10000.txt) contains
100 morphological features of 10000 cells. Further assume that
cell area corresponds to column 5 and cytoplasm area to
column 10.
Here is how we do it.
scatter_plot_of_two_groups_with_densities_in_R.bash -i data_100x10000.txt -c 5:10 -o cell_area_versus_cytoplasm_area
And here is the result

It is possible to layer on the same plot the relationship of
cell area versus cytoplasm area (as above) and the
relationship of cell elliptical radius a with expression of NFkB
(in columns 30 and 45 respectively).
This is also possible with this script.
Here is how we do it.
scatter_plot_of_two_groups_with_densities_in_R.bash -i data_100x10000.txt -c 5:10 -i data_100x10000.txt -c 30:45 -o cell_area_versus_cytoplasm_area_AND_cell_elliptical_radius_versus_NFkB
And here is the result (notice the two lines in densities and the two-color scatter plot):

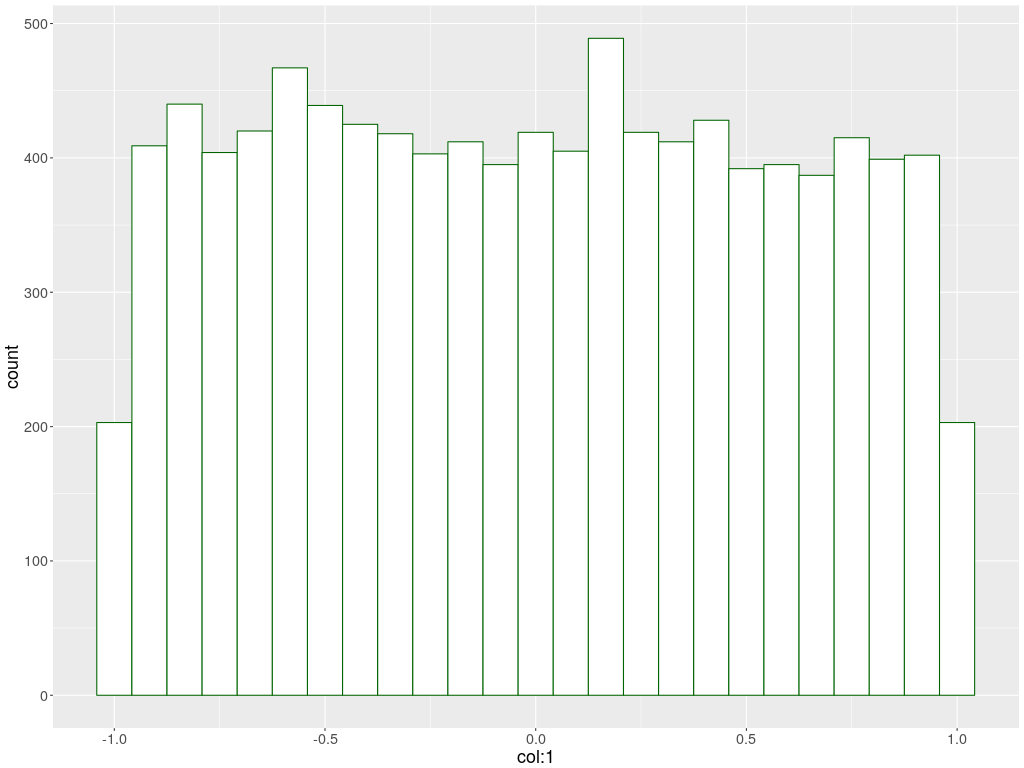
The command create_histogram_in_R.bash will produce simple 1D histograms.
Here is an example:
create_histogram_in_R.bash -i data_100x10000.txt -c 13 -b 10 -o simple_histogram
It extracts column 13 from the 100-dim text data file and makes its histogram with the specified number of bins (10) and lots of other options:
- `-B 0.12,0.15,0.17` : specify the actual bin breaks
- `-Q` : calculate bin breaks with variable bin-size so that they contain approximately the same number of items/counts.
- `-m counts|density' : the histogram can be using bin counts or probability density calculated from the counts.
- '-l' : pass the data from logarithmic function.
Here is the output:
The script for this is mutual_information_in_R.bash and can be used to
calculate the mutual information between any two of its columns (or between
all columns pair-wise if no columns are selected).
Here is an example,
mutual_information_in_R.bash -i data_100x10000.txt -o mutual_information.txt
The output file is all text and it is a matrix. Each entry (i,j)
contains the mutual information between data from column i and j.
MI is of course symmetric and this matrix reflects that.
Heatmap plotting function heatmap_in_R.bash requires a 2D matrix
of values (the heat) as input. The column-to-column mutual information
produced in the previous example is exactly that.
Here is how we make a heatmap of the mutual information calculated before:
heatmap_in_R.bash -i mutual_information.txt -N 0 -o mutual_information_heatmap
Notice how NA values are replaced with a 0 value. NA values occur when taking - or rather not taking - the MI of a column with itself.
and here is the result:

The script density_plot_in_R.bash calculates and plots the density
distribution of input data. This data must be a vector, i.e. a single
column in our test data file data_100x10000.txt.
Here is how it is done for the tenth column of the test data file:
density_plot_in_R.bash -i data_100x10000.txt -c 10 -o density_plot -t
This will estimate and plot the density of the data in the 10th column of the input file as well as a histogram (-t).
Here is how it looks:

Note that as with the other scripts (or most of them) when the operation is restricted to a single data column (a vector) and user specifies multiple columns, then the operation will be repeated for each column separately and separate output images (with column number in their name) will be produced.
The previous example is a good opportunity to demonstrate the parallelisation
ability of most of the R/bash scripts I wrote. Needless to say how
important this is for a proper scientist and for a proper programmer.
Most scripts support the -p num_threads option which will tell
the script to parallelise the task at hand. This is not done automatically
but I have implemented parallelisation on a per-script and a per-algorithm
basis. For example, in the Density Distribution plots example above,
I said that density can be calculated on a vector, i.e. on a single column
of our test input data file. When multiple columns are specified,
or none at all meaning "process all columns independently",
the script will process each column specified independently and produce
a separate plot for each. If the -p option is used then this, sometimes
herculean - consider we have 100 columns in our test file-, task
then the script will parallelise the task over the number of threads specified.
Here is an example to demonstrate this (warning heavy parallel computation). NOTE: I have selected the number of threads to be 7 because my computer has 8 cores (and it is good practice to leave one to the OS) and I have no other heavy tasks running at the moment. Beware! The number of threads to specify should never exceed the number of cores your computer has. You will gain nothing and most likely you will loose on task-switching.
density_plot_in_R.bash -p 7 -i data_100x10000.txt -o density_plot -t
Enjoy and remember that thousands of hours have been spent on these
scripts and the underlying library in order to create high level
tools for data analysis using R. That saved me a lot of hours later
on. And I am still using them today. Pitty ggplot2 had to undergo
such a drastic change costing my plots the aesthetic perfection
I aimed for - and had briefly achieved with older versions of ggplot2-,
side-by-side with algorithmic and processing perfection.