gmall-user用户服务8080 gmall-user-service用户服务的service层8070 gmall-user-web用户服务的web层8080
gmall-manage-service用户服务的service层8071 gmall-manage-web用户服务的web层8081
养成习惯,先赞后看!!!
@TOC
1.将Spring的@Service改成dubbo的@Service
2.将@Autowried注解换成@Reference(注意必须是dubbo的)
3.配置dubbo与zookeeper
#dubbo中的应用容器名称
spring.dubbo.application=user-web
#dubbo通信协议的名称
spring.dubbo.protocol.name=dubbo
#zookeeper注册中心地址
spring.dubbo.registry.address=47.98.59.8:2181
#注册中心的通信协议
spring.dubbo.registry.protocol=zookeeper
#dubbo扫描路径
spring.dubbo.base-package=com.auguigu.gmall4.dubbo在进行dubbo协议通讯的时候,需要实现序列化接口(封装的数据对象即我们的bean
如果出现子模块无法导入父模块的依赖,那么我们就需要先将整个子模块所依赖的父模块全部先clean,compile,install到我们对应的maven仓库之中,这样我们的子模块就能够引入我们的父模块的依赖了,,但是这时候我们一定要去本地的maven仓库里面将我们刚才install的jar包删除掉,否则每次我们运行项目,他都是自动将我们maven仓库里面的jar拿出来使用,所以就算我们对代码进行修改,也是看不出来任何修改的效果的。
进行端点调试的时候,consumer默认是在三秒内,每隔一秒就重新进行一次访问,如果超过三次,那么就会报超时异常,
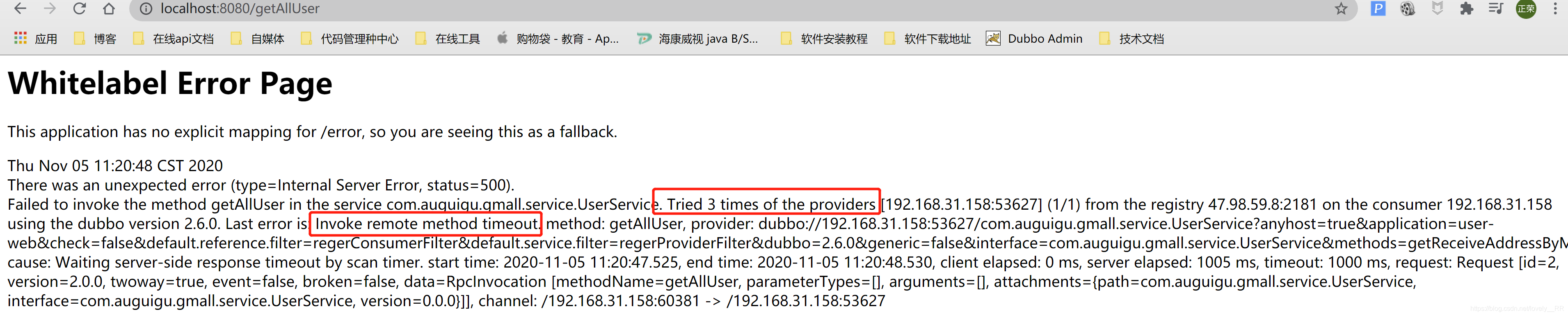
所以为了调试时候的方便,我们需要延长consumer的超时时间
#设置comsumer的超时时间,单位是毫秒
spring.dubbo.consumer.timeout=600000库存量单位:脑海中的实物即抽象的商品,举个例子联想拯救者电脑
库存存储单元:具体的实物,举个例子:联想拯救者Y9000x型号的电脑,具体到了联想拯救者电脑的特定类型的电脑
sku的结构:pms_sku_
spu的结构:pms_spu_
类目的结构:pms_catalog_
属性的结构:pms_attr_
jvm--node
maven--npm
idea--vscode
spring--vue
config:配置前端服务的IP和前端访问数据的后端的服务的IP地址
- dev.env.js:前端访问后端的数据的服务的IP地址
- index.js:前端服务器的端口
默认是通过json进行数据的传输
请求格式:@RequestBoby
返回格式:@ResponseBody

端口号与IP不同即为跨域
跨域注解@CrossOrigin
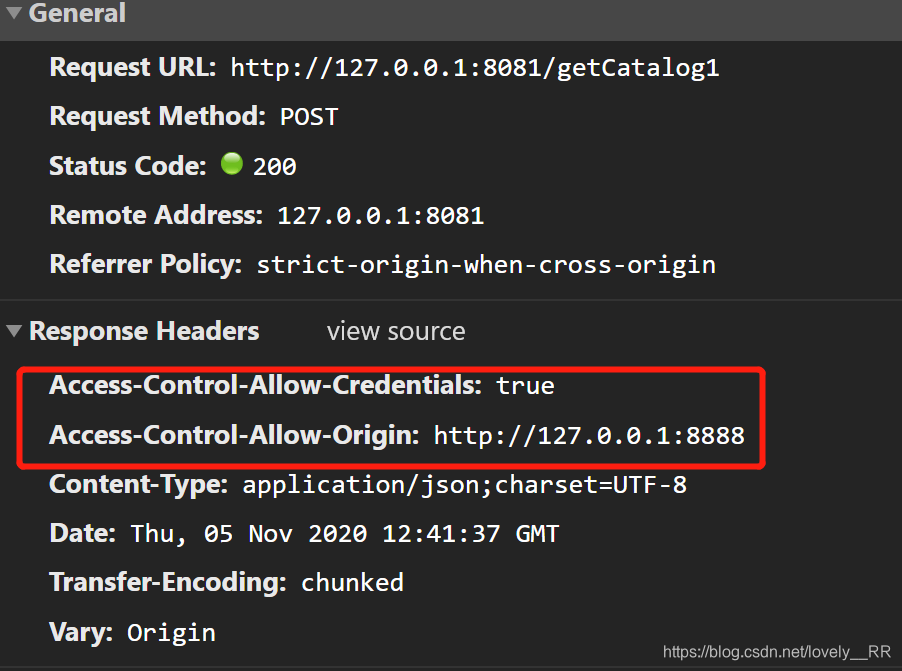
请求头中添加了信息,这样就能够进行跨域了
@RequestBody只适用于对象数据,这种对象数据包含这两种
- 已经封装好的对象,举个例子,User user这种已经封装好的对象
- Map集合的形式
@RequestParam适用于只有单独几个数据的时候,举个例子,比如说分页查询的时候,前端是需要传递page,size两个参数的时候,问我们就只需要通过@RequestParam Integer page,@RequestParam Integer size的形式就可以将数据接受过来即可。
但是他们两者都能够将数据已 json 的形式进行传输。
@GeneratedValue(strategy = GenerationType.IDENTITY)用于表示改属性是有数据库自己产生的,主要用于自增操作
并且使用了该注解之后就能够在对象插入之后获取到该对象自动生成的主键
类似于mybatis里面的这段代码的作用:
<insert id="insertSelective" parameterType="请求对象" useGeneratedKeys="true" keyProperty="Id">
</insert>这段代码同样是为了方便我们获得自增主键的值
//创建例子,这个例子就是你将要修改对象的数据类型
Example example=new Example(PmsBaseAttrInfo.class);
// 创建规则,
example.createCriteria().andEqualTo("id",pmsBaseAttrInfo.getId());
//
pmsBaseAttrInfoMapper.updateByExampleSelective(pmsBaseAttrInfo,example);- 图片对象数据:

上图即为图片的对象数据即图片本身
保存在分布式的文件系统之中fastdfs即保存图片本身
- 图片的源数据
上图即为图片的源数据即详细信息或属性
保存在数据库中即保存图片的名称,路径URL等详细信息
<form method="post" enctype="multipart/Form-data">
<input type="file"/>
</form>-
将压缩包上传到opt目录下
-
之后解压改文件
cd /opt tar -zxvf FastDFS_v5.05.tar.gz

- 这时候我们来编译文件
cd FastDFS
./make.sh- 如果出现下面的错误,那么我们需要先安装这个环境libfastcommon
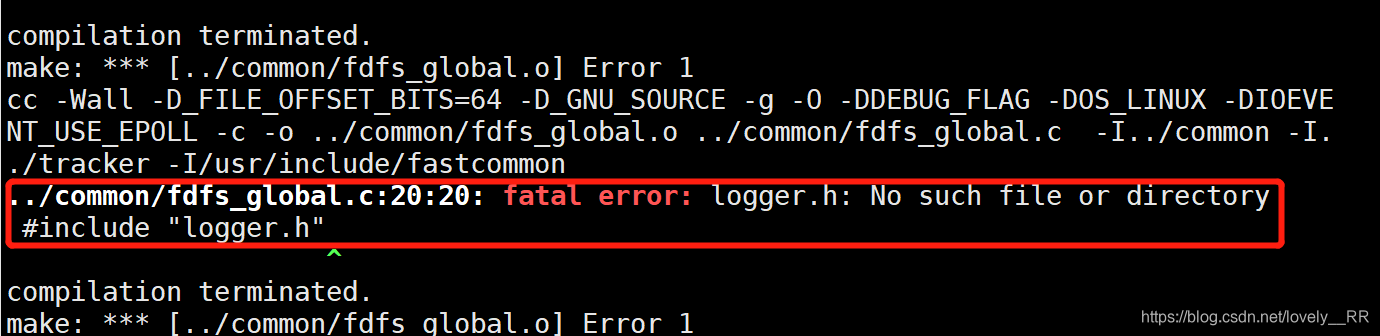
-
安装libfastcommon步骤
- 上传文件到/usr/local目录下
- 解压改文件
tar -zxvf libfastcommonV1.0.7.tar.gz

- 进入解压好的文件夹下,开始编译
cd libfastcommon-1.0.7
./make.sh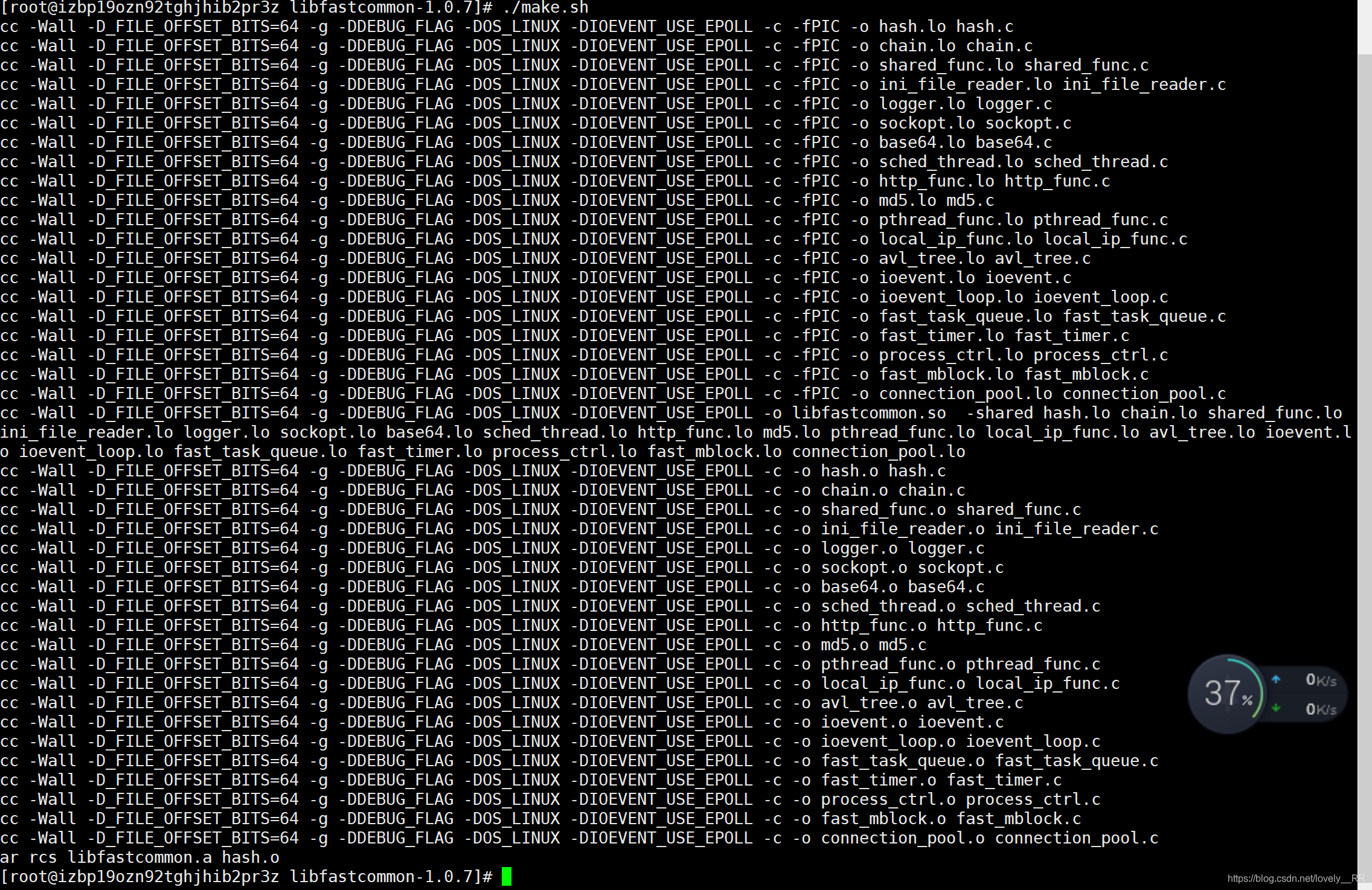
如果出现无法识别./make.sh,那么运行运行下面的代码即可
yum -y install zlib zlib-devel pcre pcre-devel gcc gcc-c++ openssl openssl-devel libevent libevent-devel perl unzip net-tools wget之后你就可以通过./make.sh命令进行编译了
- 便已完成之后我们就需要将它安装上来
./make.sh install
cp /usr/lib64/libfastcommon.so /usr/lib- 安装完libfastcommon之后我们再去重新编译我们的文件
./make.sh
./make.sh install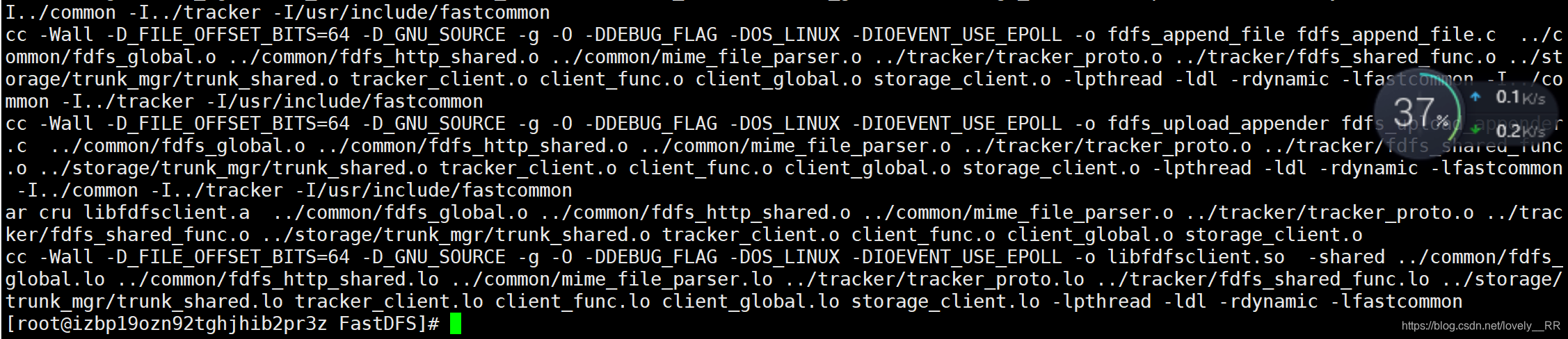
这样就算编译成功了。
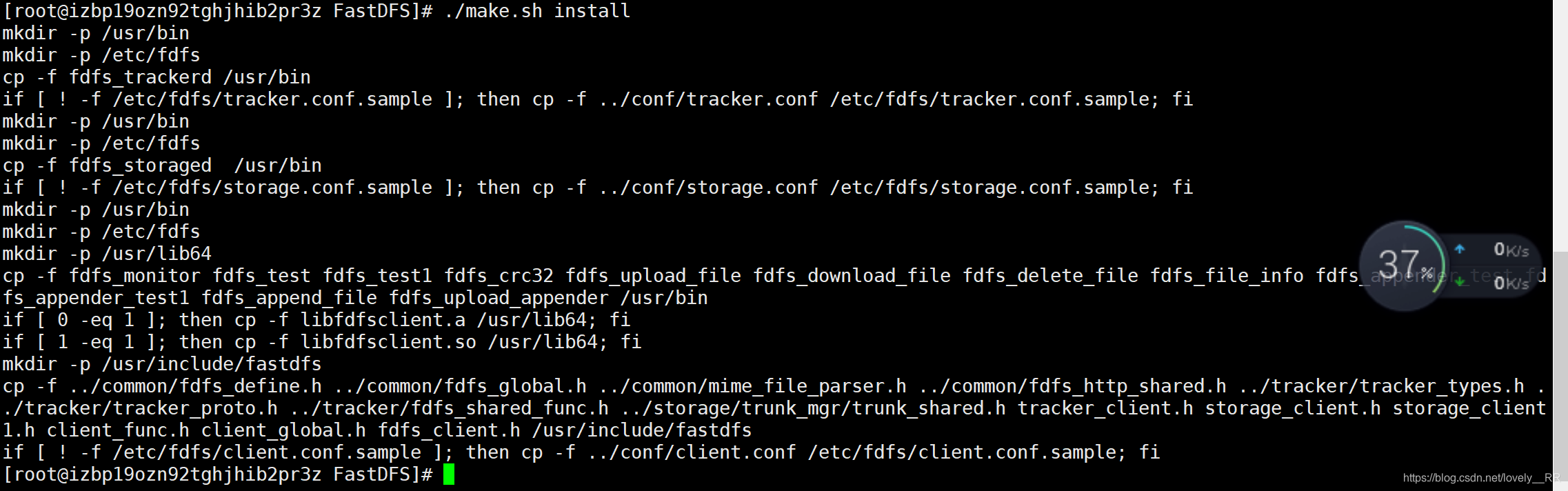
这样就算安装成功了。
- 将conf配置目录下的所有文件都拷贝到/etc/fdfs
这时候我们先去查看一下是否有该目录,我们检查之后发现是没有的

但是当我们选择去创建该目录的时候会发现该目录其实已经存在了,
mkdir /etc/fdfs
我们可以进入该目录去检验一下,可以发现我们是可以进入该目录的,
cd fdfs
这就说明我们在安装Fastdfs的时候,他就已经默认帮我们将它创建了,知识这个目录是隐藏的
所以我们可以直接将conf目录下的所有文件全部拷贝到/etc/fdfs目录下
cp * /etc/fdfs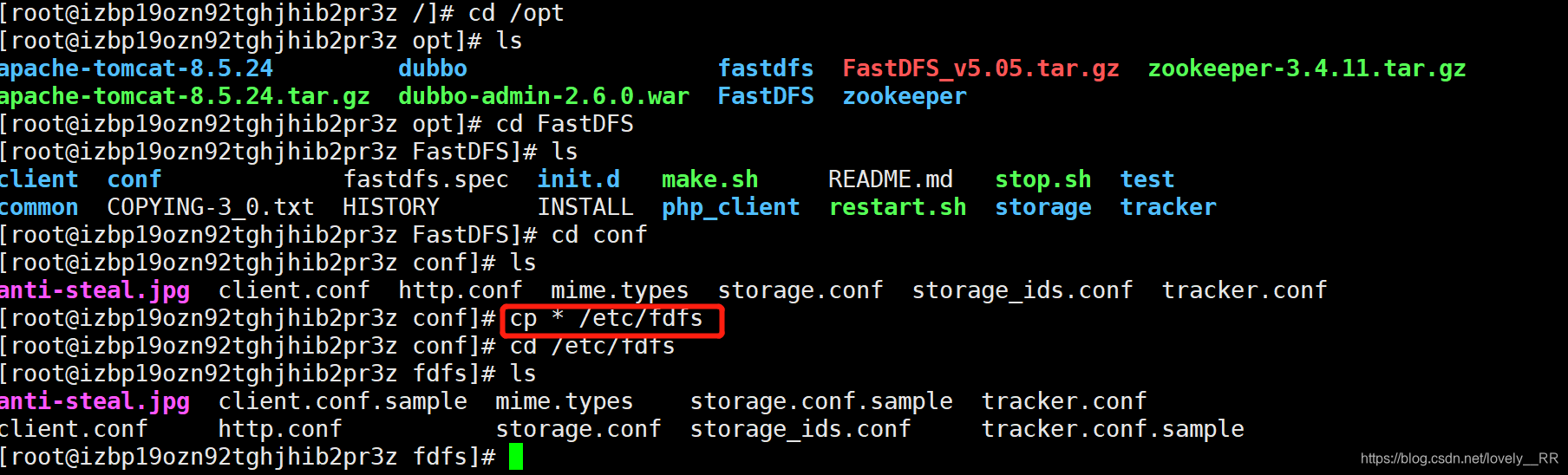
- 之后我们去配置/etc/fdfs目录下去配置tracker.conf,这其中主要就是设置软件数据以及日志目录
我们需要先创建一个目录来存放fastdfs的数据以及日志
mkdir /opt/fastdfs
cd /etc/fdfs
vi tracker.conf将这个目录修改成我们刚才创建的那个存放数据以及日志的目录

之后保存退出即可
- 之后我们还要去配置storage.conf文件
我们主要就是修改下面三处地方
这一处就是我们数据和日志存储的目录

这一处使我们文件将来存储的位置,我们可以看到这里面可以设置多个文件存储位置

这里就是修改成刚才部署tracker的那台服务器的IP就行了,因为我们这里tracker和storage是部署在同一台服务器上的,所以我们就直接用本机的IP即可,因为我们是阿里云的服务器,所以等会我们需要去配置防火墙以及开通安全组规则,否则这个22122端口是无法访问开启的
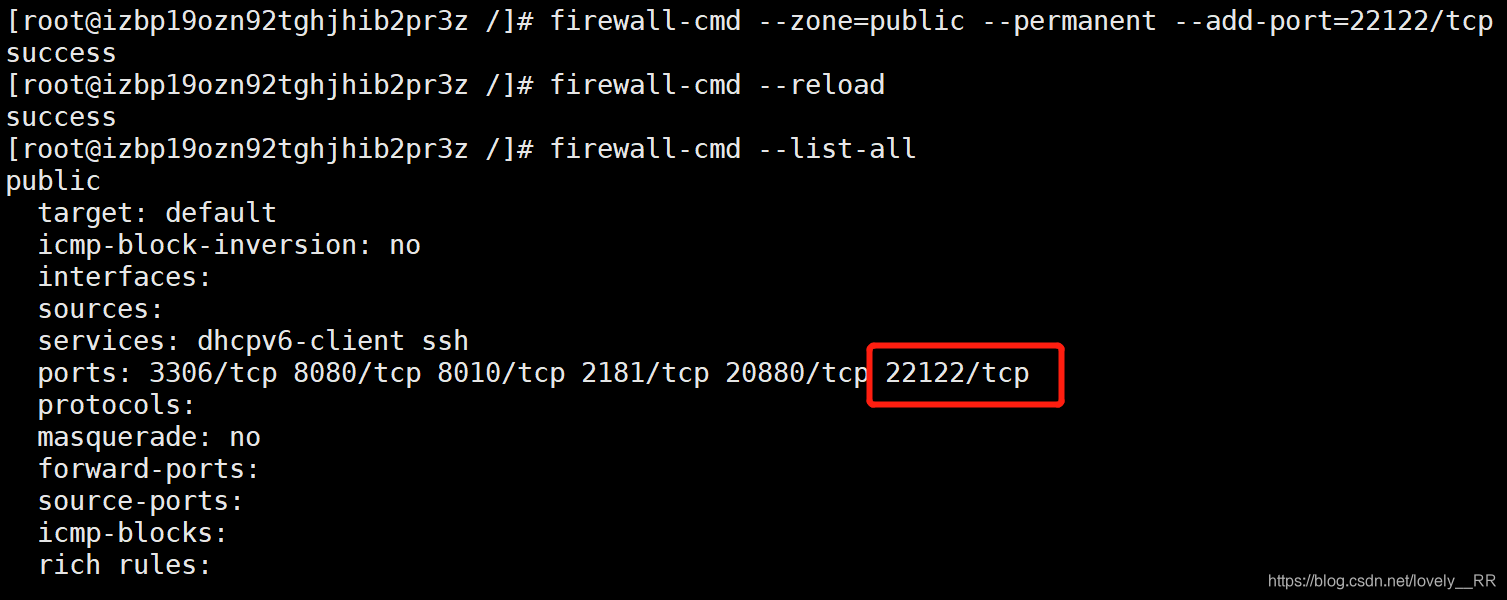
配置防火墙端口号:
service firewalld start
firewall-cmd --zone=public --permanent --add-port=22122/tcp
firewall-cmd --reload
firewall-cmd --list-all 
开通安全组:
记得入方向和出方向都需要配置

- 配置fdfs_storaged和fdfs_trackerd的启动服务
先创建/usr/local/fdfs,再将安装目录下的两个服务复制到/usr/local/fdfs目录下
mkdir /usr/local/fdfs
cd /opt/FastDFS
cp stop.sh /usr/local/fdfs
cp restart.sh /usr/local/fdfs

这是fdfs_trackerd文件需要修改的地方
cd /etc/init.d
vi fdfs_trackerd



fdfs_storaged需要修改的地方
cd /etc/init.d
vi fdfs_storaged



chkconfig --add fdfs_storaged
chkconfig --add fdfs_trackerd
service fdfs_storaged start
service fdfs_trackerd start
ps -ef|grep fdfs
如果能够看到下面的页面就说明fdfs服务就已经成功启动了

- 测试fastdfs服务
Fastdfs有一个专门让我们用来测试的目录,我们可以通过修改该目录来测试我们的文件服务是否真的成功 首先修改该文件etc/fdfs/client.conf的以下配置:
vim /etc/fdfs/client.conf

/usr/bin/fdfs_test /etc/fdfs/client.conf upload test.jpg
/usr/bin/fdfs_test 是fastdfs自带的一个测试demo
/etc/fdfs/client.conf 是我们刚才配置的测试的配置,命令会读取这个配置文件的信息
test.jpg 代表你要上传的文件名,是当前目录下的文件



- 在/opt目录下解压文件
tar -zxvf fastdfs-nginx-module_v1.16.tar.gz- 修改插件本身的配置文件
vi /fastdfs-nginx-module/src/config把中间的local删掉,注意有两个文件路径

- 将插件整合fastdfs的配置文件拷贝到fastdfs的配置目录下
cp mod_fastdfs.conf /etc/fdfs/-
修改该配置文件
主要有下面四处修改
- fdfs的软件安装目录

- fdfs的tracker的IP地址

- fdfs生成的URL是否使用分组

这个其实看我们刚才生成的图片URL就能看到包含group1这个字段
- fdfs的文件存储路径

cd /opt/nginx-1.12.2- 之后直接粘贴下面的命令
./configure \
--prefix=/usr/local/nginx \
--pid-path=/var/run/nginx/nginx.pid \
--lock-path=/var/lock/nginx.lock \
--error-log-path=/var/log/nginx/error.log \
--http-log-path=/var/log/nginx/access.log \
--with-http_gzip_static_module \
--http-client-body-temp-path=/var/temp/nginx/client \
--http-proxy-temp-path=/var/temp/nginx/proxy \
--http-fastcgi-temp-path=/var/temp/nginx/fastcgi \
--http-uwsgi-temp-path=/var/temp/nginx/uwsgi \
--http-scgi-temp-path=/var/temp/nginx/scgi \
--add-module=/opt/fastdfs-nginx-module/src如果出现这个错误configure: error: the HTTP rewrite module requires the PCRE lib
只需要依次输入以下的命令即可解决
yum -y install pcre-devel openssl openssl-devel
./configure --prefix=/usr/local/nginx
make
make install

之后重新粘贴我们之前的代码即可完成我们Nginx
- 修改Nginx的配置文件
主要有下面两处修改,这里修改的是本机的IP地址

另外一个就是将我们上面配置的插件添加进来

- 之后我们启动Nginx服务
我们需要进入/usr/local/conf/sbin目录下
#启动Nginx服务
./nginx
#重启Nginx服务
./nginx -s reload因为我已经启动过了,所以我这里是用的重启nginx服务的命令

这样就代表Nginx服务已经启动成功了。
之后我们去浏览器里面输入你服务器的IP地址,就能够看到下面的界面了:
之后我们再无重新访问我们之前上传图片时生成的URL地址,可以发现这时候图片就可以正常访问了。

- clone并将客户端导入到项目
因为FastDFS不像我们其他的框架,直接就可以从Maven仓库下载他相应的依赖,然后直接跟着教程后面敲就行了,他是必须我们先从Git上面把它的客户端Clone下来,然后导入到我们的项目,才能够直接使用的。 所以我们首先需要将客户端clone下来。 找到我们的Git工具,然后以管理员身份运行,之后输入下面的命令就能够将客户端clone先来了
git clone https://github.com/happyfish100/fastdfs-client-java




- 导入FastDFS客户端的依赖

这里有个小坑,到后面我会告诉大家怎么解决。
- 创建并配置Tracker的配置信息
在需要文件上传的模块的resource文件夹下面创建配置文件
#tracker_server服务的地址及端口号
tracker_server=tracker服务的IP:22122
#连接超时间,默认是30秒
connect_timeout=30000
#网络通讯超时时间,默认是60秒
network_timeout=60000
- 编写上传文件的工具类
之后我们就可以正式的来编写我们的工具类了
public static String uploadImage(MultipartFile multipartFile) throws IOException {
//这里是我定义的常量类
ConstantUtil constantUtil=new ConstantUtil();
String ImageUrl= constantUtil.getImageUrl();
//获取tracker的配置文件路径
String tracker=PmsUploadUtil.class.getResource("/tracker.conf").getPath();
//读取配置文件
try{
ClientGlobal.init(tracker);
}catch (Exception e){
e.printStackTrace();
System.out.println("配置实例化失败");
}
TrackerClient trackerClient=new TrackerClient();
TrackerServer trackerServer=trackerClient.getTrackerServer();
//创建一个StorageClient对象,需要两个参数TrackerServer对象、StorageServer的引用
StorageClient storageClient = new StorageClient(trackerServer, null);
//获取文件的byte数组
byte[]bytes=multipartFile.getBytes();
//获取文件的后缀名
String multipartFileName=multipartFile.getOriginalFilename();
int index=multipartFileName.lastIndexOf(".");
String extNamne=multipartFileName.substring(index+1);
//使用StorageClient对象上传图片;扩展名不带“.”
try {
String[] strings = storageClient.upload_file(bytes, extNamne, null);
//返回数组。包含组名和图片的路径。重组成URL链接
for (String string : strings) {
ImageUrl+="/"+string;
}
}catch (Exception e){
e.printStackTrace();
}
return ImageUrl;
}这里还有一个注意点就是 FastDFS1.27 和 FastDFS1.29 两个版本有些许的不一样
在1.27的版本里面:
我们获取TrackerServer是通过trackerClient.getConnection()来获取的,
但是在1.29的版本里面:
我们获取TrackerServer是通过trackerClient.getTrackerServer()来获取的,
其次FastDFS中的上传函数主要是下面两种,

Detected both log4j-over-slf4j.jar AND slf4j-log4j12.jar on the class path, preempting StackOverflowError
这个bug的意思就是你项目里面同时使用了 log4j-over-slf4j.jar 和 slf4j-log4j12.jar ,刚好这两个包是冲突的,所以我们必须要将其中一个去掉,但是之前自己的项目都是能够正常运行的,所以不出意外应该是FastDfS客户端里面应该是引用了上面依赖中的一个,所以这里我们重新进FastDFS客户端的pom依赖里面就能够看到他的依赖有哪些,我们可以看到如下图所示:

<dependency>
<groupId>org.csource</groupId>
<artifactId>fastdfs-client-java</artifactId>
<version>1.29-SNAPSHOT</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>这样我们的项目基本就能运行了
- 上传演示
到了这里我们就可以来进行实际的测试一下了

thymeleaf使用的是HTML的扩展标签,需要在页面上申明thymeleaf的模板约束
引入thymeleaf相关联的三个依赖:
<!--热部署,松校验-->
<dependency>
<groupId>net.sourceforge.nekohtml</groupId>
<artifactId>nekohtml</artifactId>
</dependency>
<dependency>
<groupId>xml-apis</groupId>
<artifactId>xml-apis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.xmlgraphics</groupId>
<artifactId>batik-ext</artifactId>
</dependency>之后在application.properties文件里面配置以下代码:
#关闭thymeleaf缓存(热部署)
spring.thymeleaf.cache=false
#松校验
spring.thymeleaf.mode=LEGACYHTML5这里的热部署不是实时的,还是需要我们先提交文件,才能看到更新的文件
提交文件快捷键:Ctrl+shift+F9
前端获取的数据都是通过后台通过ModelMap进行返回的
@RequestMapping("/index")
public String index(ModelMap modelMap){
List<String>list=new ArrayList<>();
for(int i=0;i<5;i++){
list.add("循环数据"+i);
}
modelMap.put("hello","are you ok");
modelMap.put("list",list);
modelMap.put("check",1);
return "index";
}- 取值
<p th:text="${hello}">默认值</p>先检查thymeleaf标签,如果标签里面有值就先显示该值,否则显示默认值
- 循环
<p th:each="str:${list}" th:text="${str}"></p>
<p th:each="str:${list}" >
<input th:text="${str}" th:value="${str}" />
</p>
- 判断
<input type="checkbox" th:checked="${check}==2">
- 传值给JavaScript
<a th:href="'javascript:a(\''+${hello}+'\')'">点我</a>
<script language="JavaScript">
function a(hello) {
alert("js函数被调用了"+hello);
}
</script>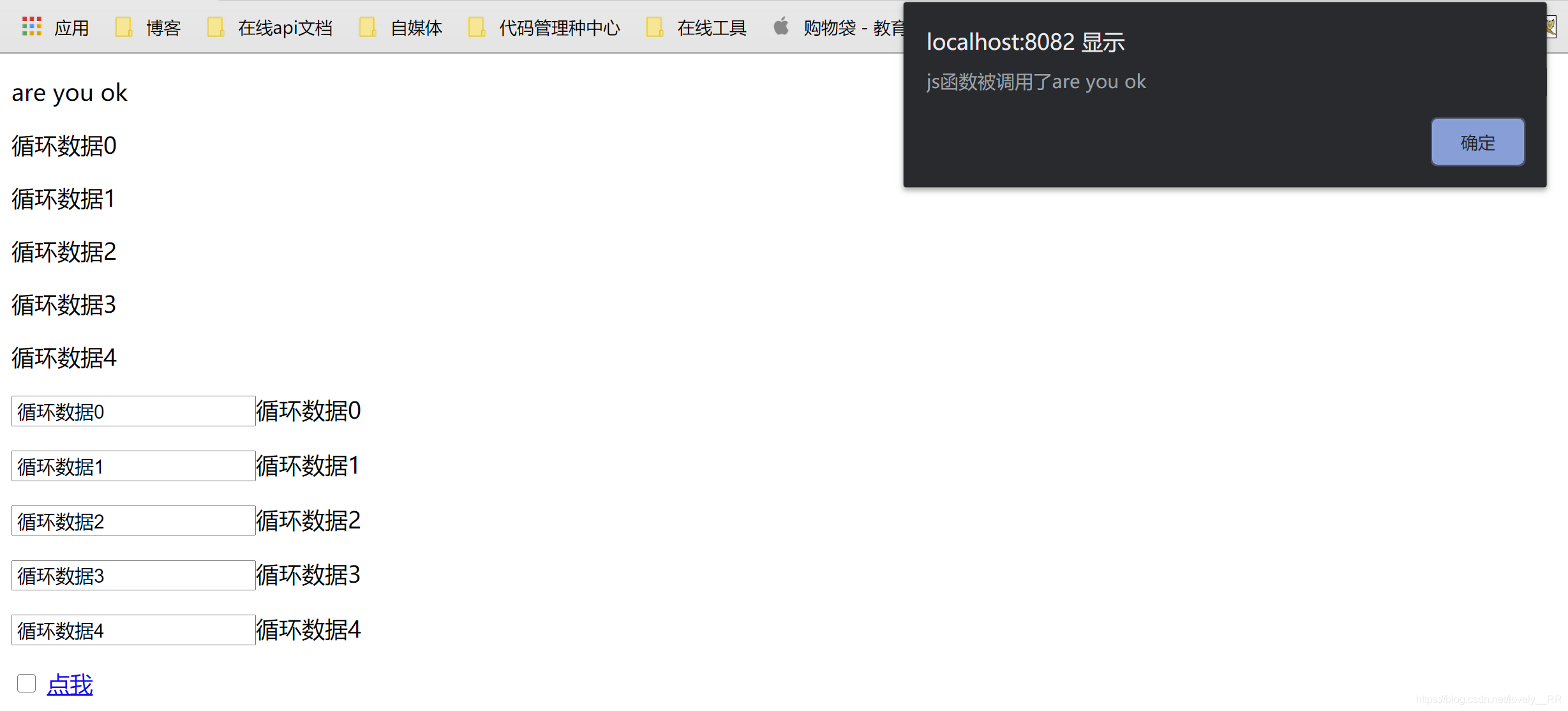
这个?主要是为了防止空指针异常,如果出现我们不存在的skuinfo对象,显然页面时根本无法显示的,所以为了防止这种现象,我们必须拦截这种类似的请求
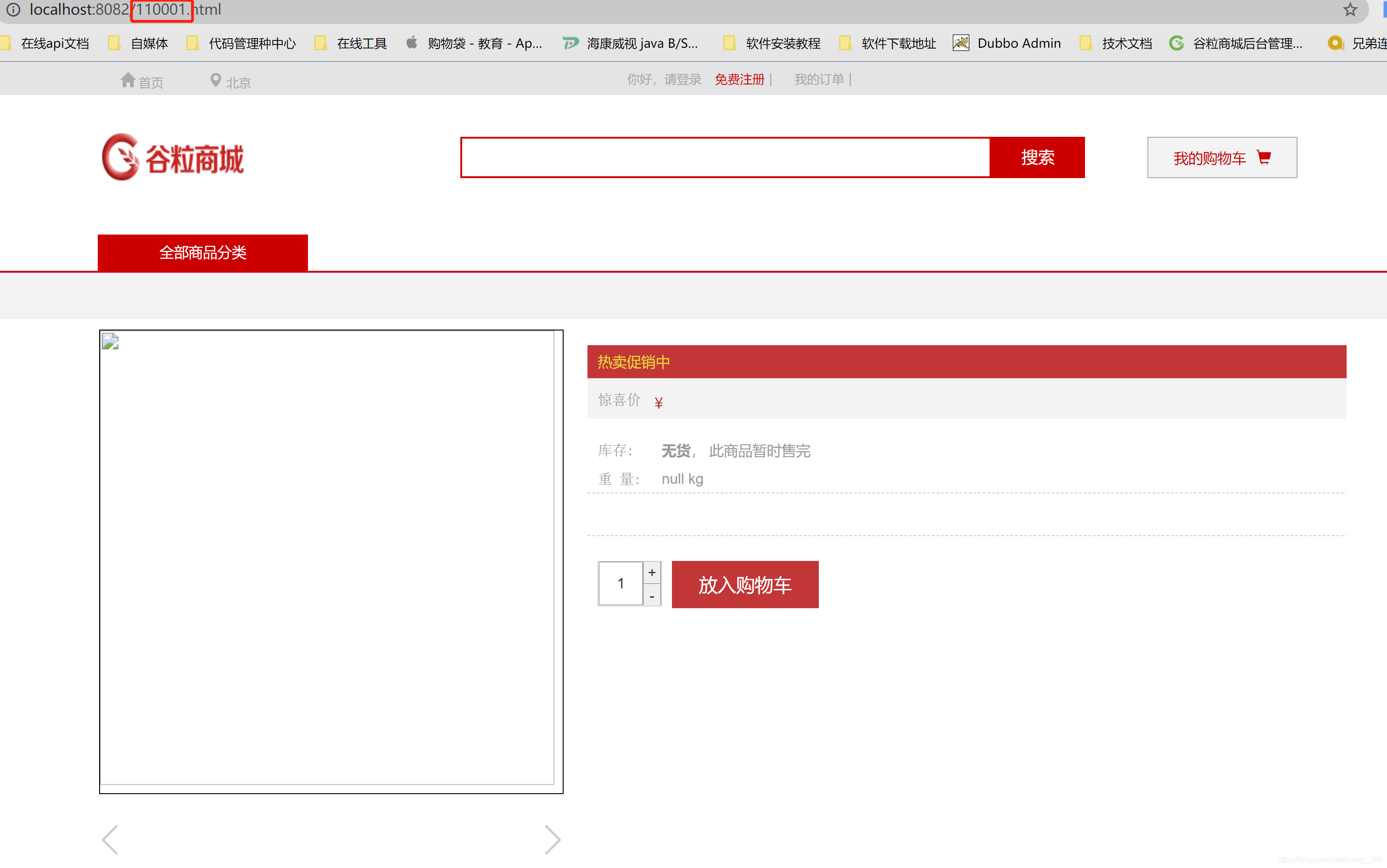
显然这个SKU对象的id我们是没有的,所以我们必须对于这种请求进行拦截,拦截之后应该生成上述的页面,如果我们将这个?去掉的话,我们再次访问该页面就会出现下面的错误:

显示内连接查询绑定pms_product_sale_attr 与pms_product_sale_attr_value两张表的信息
SELECT
sa.*,
sav.*
FROM
pms_product_sale_attr sa
INNER JOIN pms_product_sale_attr_value sav ON sa.product_id = sav.product_id
AND sa.sale_attr_id = sav.sale_attr_id
AND sa.product_id = 70查询结果:
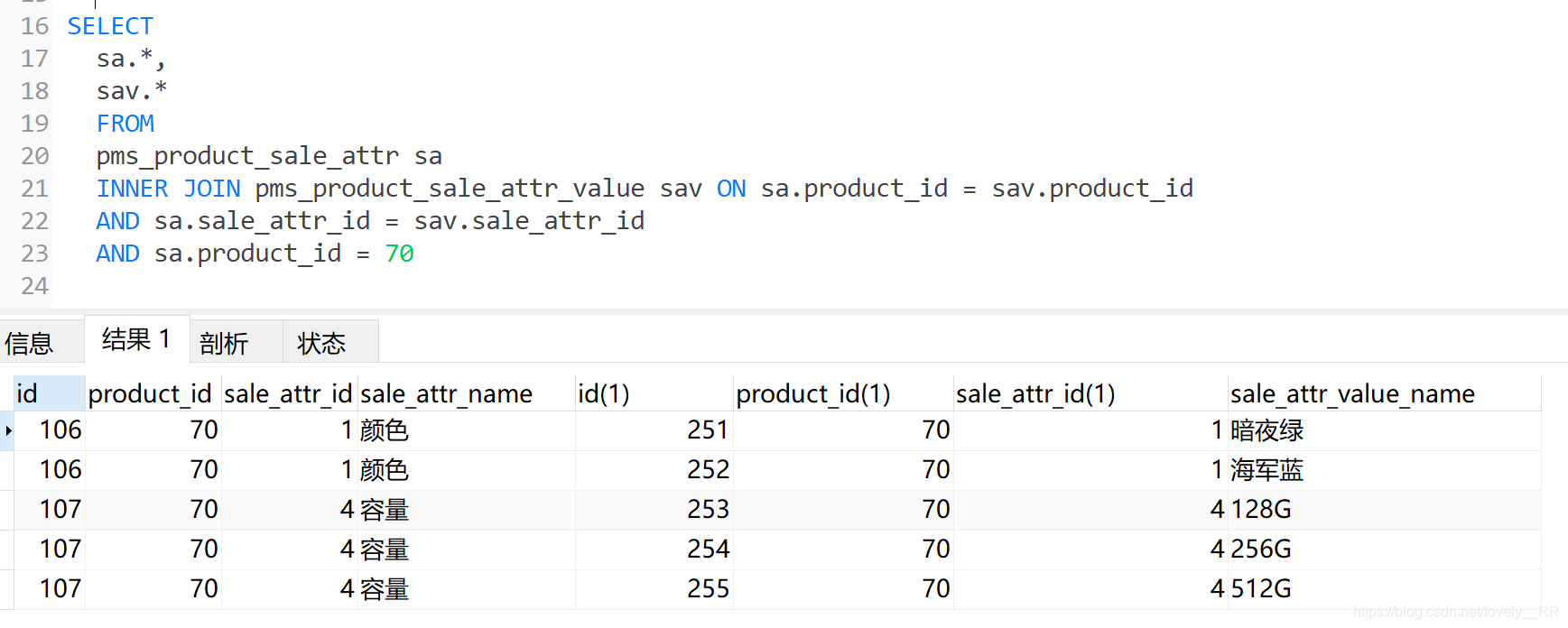
我们这里只是简单的先将我们需要的SPU自带的销售属性及其属性值全部查询出来的,但是因为我们还要做到能够直接定位到当前SKU所固定的销售属性值,所以我们还需要再关联一张表即pms_sku_sale_attr_value,这张表主要就是帮我们筛选出我们当前SKU对象所对应的销售属性,这里我们主要是通过左连接进行绑定
SELECT
sa.*,
sav.* ,
ssav.*
FROM
pms_product_sale_attr sa
INNER JOIN pms_product_sale_attr_value sav ON sa.product_id = sav.product_id
AND sa.sale_attr_id = sav.sale_attr_id
AND sa.product_id = 70
LEFT JOIN pms_sku_sale_attr_value ssav ON sav.id = ssav.sale_attr_value_id
WHERE
ssav.sku_id = 106;查询结果:
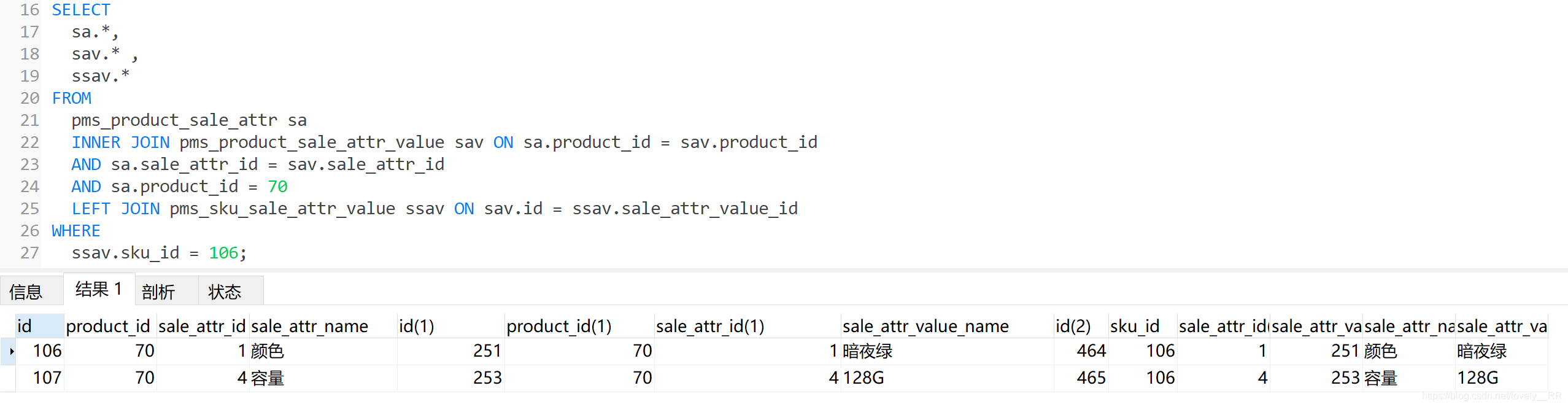
但是运行完成之后我们会发现,只剩下了两条数据,那么这样的话我们就无法将SPU整个的销售属性及其属性值取出来,显然是不行的.经过我们的排查之后我们发现这里主要就是where字段的范围太大了,我们将where 写在了最后就说明,他是需要整个数据中满足 sku_id=106的数据保留下来,但是很明显这里我们其实只是应该将我们后半段左连接中的数据中满足sku_id=106的数据保留下来,所以我们简单的修改以下代码
SELECT
sa.*,
sav.*,
ssav.*
FROM
pms_product_sale_attr sa
INNER JOIN pms_product_sale_attr_value sav ON sa.product_id = sav.product_id
AND sa.sale_attr_id = sav.sale_attr_id
AND sa.product_id = 70
LEFT JOIN pms_sku_sale_attr_value ssav ON sav.id = ssav.sale_attr_value_id AND ssav.sku_id = 106;查询结果:
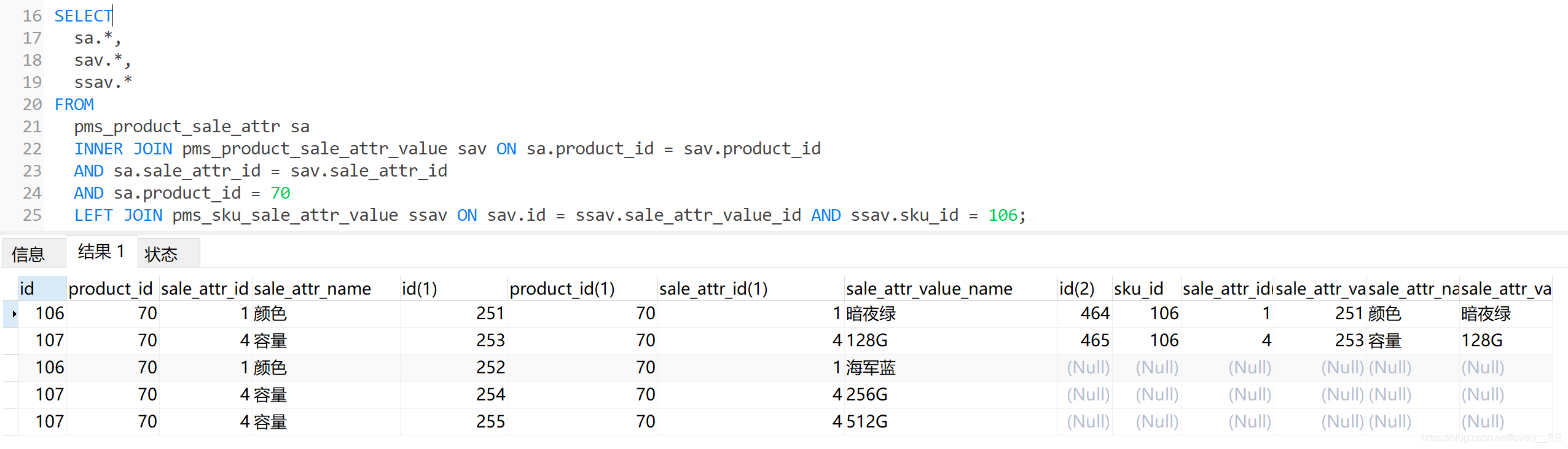
可以看到这样才是我们最后需要的结果,既能将SPU所有的销售属性及其属性值全部查询出来,同时又能将该SKU对象的销售属性值取出来.两全其美.
如果对于内连接,左连接,右连接还是有不清楚的,可以去看我的这篇博客:
Mysql中外连接,内连接,左连接,右连接的区别,里面有详细解释.
两者的区别主要就是在返回类型上.
在mybatis中我们可能返回的数据类型主要就是下面这两种:
-
单个集合----ResultType,ResultMap
-
多重集合----ResultMap
那么什么样的数据才叫单个集合,什么样的数据才叫多重集合呢?我们通过下面两张图,大家就能理解了:
单个集合:

多重集合:

看完上面两张图大家就能基本知道他们的差别了,,那么他们俩的具体使用场景又是怎样的呢?
举两个例子大家就懂了
在 获取所有用户的数据 的时候显然我们只需要获得用户信息即可了,并不需要在获取其他额外的数据.
但是在 进行用户的角色校验 的时候,显然我们不仅需要获得该用户的相关信息,其次我们还需要获得该用户的角色信息,那么显然我们返回的数据就不能只包含用户信息,所以我们必须将数据封装成上述多重集合的形式,这样才能方便我们进行角色的校验.
了解完上面的概念之后,大家基本就了解了他们两者的区别了,但是大家又要问了,上面你说 ResultMap既能用于单个集合,又能用于多重集合,那么我们为什么不全是用ResultMap呢?还要使用ResultType呢?
这里主要是因为ResultType虽然只针对单个集合,但是他是可以直接调用我们已经编写好的实体类的,但是ResultMap则不同,它不管如何都需要我们进行自定义,所以主要还是用在多重集合的情况下,单个集合的情况下还是使用ResultType.
这样大家基本就能了解清楚他们俩的不同了,了解完不同之后,我们再来具体的讲解一下如何使用他们:
ResultType
ResultType使用起来就比较的简单了,上面我们已经说过了,是可以直接调用我们的实体类的,所以我们基本上就是直接copy实体类的相对路径即可了,下面是一个栗子:
<select id="selectAll" resultType="com.auguigu.gmall.bean.PmsProductInfo">
select * from pms_product_info
</select>可以看到我们只需要将我们需要返回的实体类的路径直接赋给ResultType即可,简单方便.
ResultMap
但是ResultMap相对来说就比较麻烦,其实主要就是 需要告诉Mybatis你是将那几个实体类进行多重组合的 ,这样剩下的事就可以全交给mybatis来做了.还是通过下面的栗子,我们详细讲解一下.
多重集合的两个实体类:
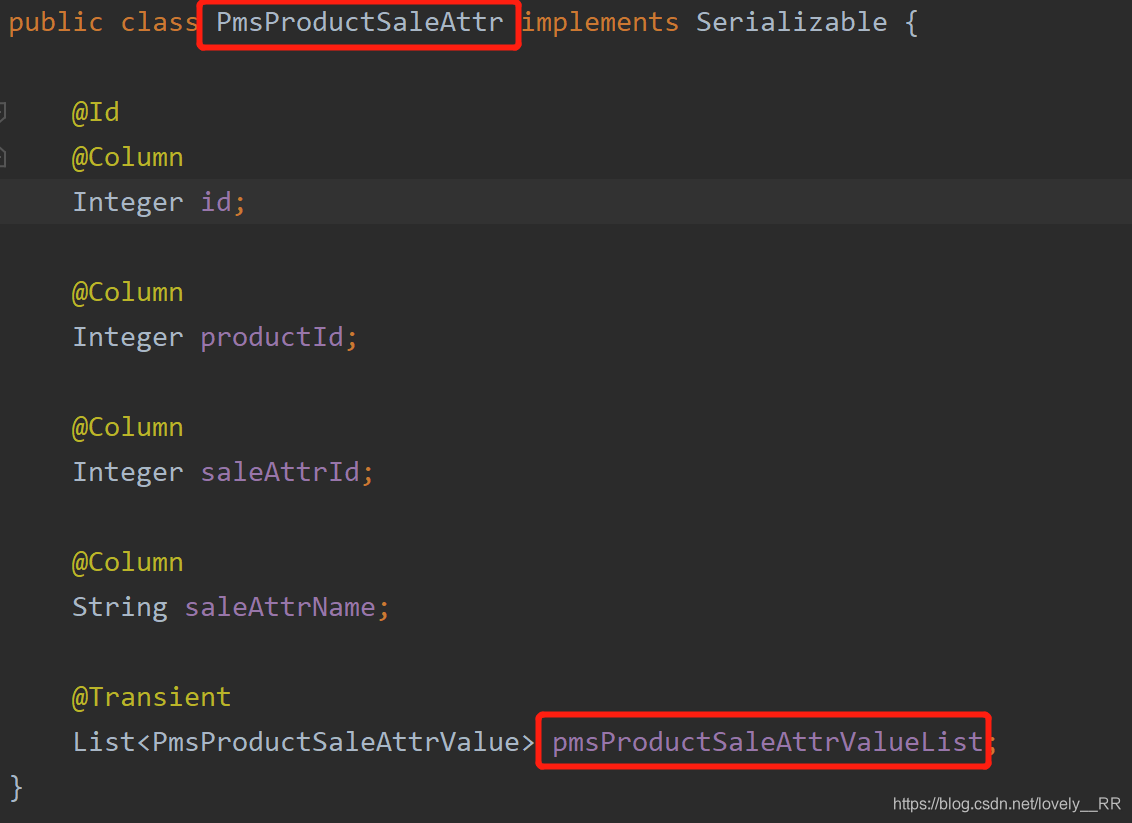
- PmsProductSaleAttr
public class PmsProductSaleAttr implements Serializable {
@Id
@Column
Integer id;
@Column
Integer productId;
@Column
Integer saleAttrId;
@Column
String saleAttrName;
@Transient
List<PmsProductSaleAttrValue> pmsProductSaleAttrValueList;
}- PmsProductSaleAttrValue
public class PmsProductSaleAttrValue implements Serializable {
@Id
@Column
Integer id;
@Column
Integer productId;
@Column
Integer saleAttrId;
@Column
String saleAttrValueName;
@Transient
Integer isChecked;
}之后我们再来看一下我们在mapper.xml文件中定义的代码:
<select id="selectspuSaleAttrListCheckBySku" resultMap="selectspuSaleAttrListCheckBySkuMap">
SELECT
sa.id as sa_id,
sav.id as sav_id,
sa.*,
sav.*,
if(ssav.sku_id,1,0) as isChecked
FROM
pms_product_sale_attr sa
INNER JOIN pms_product_sale_attr_value sav ON sa.product_id = sav.product_id
AND sa.sale_attr_id = sav.sale_attr_id
AND sa.product_id = #{productId}
LEFT JOIN pms_sku_sale_attr_value ssav ON sav.id = ssav.sale_attr_value_id
AND ssav.sku_id = #{skuId}
ORDER BY sav.id
</select>
<resultMap id="selectspuSaleAttrListCheckBySkuMap" type="com.auguigu.gmall.bean.PmsProductSaleAttr" autoMapping="true">
<result column="sa_id" property="id"></result>
<collection property="pmsProductSaleAttrValueList" ofType="com.auguigu.gmall.bean.PmsProductSaleAttrValue" autoMapping="true">
<result column="sav_id" property="id"></result>
</collection>
</resultMap>在分析代码之前,我们下来看一下该SQL语句执行之后,我们获得的数据是什么样的?
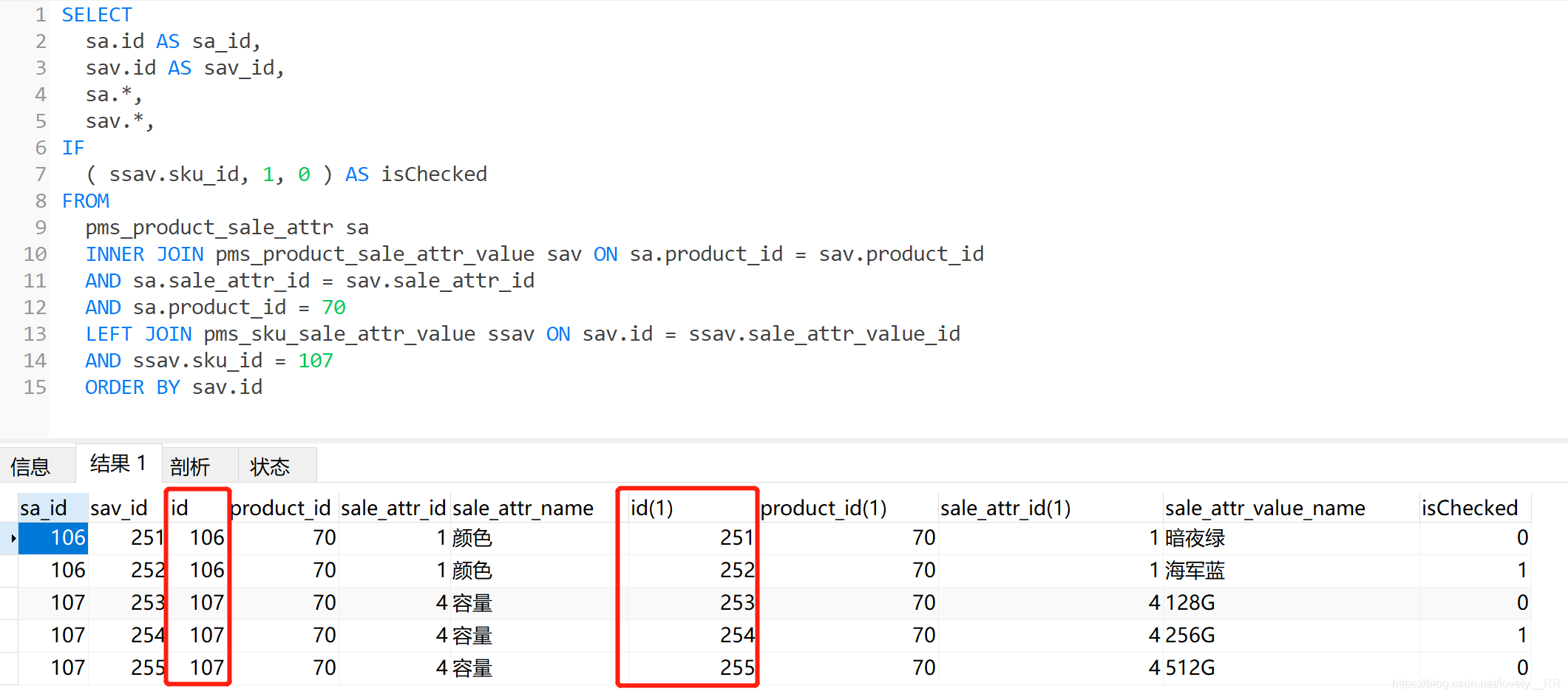
可以看到我们获得数据中又好几个字段名称都是重复的,这样就使得mybatis很难去做匹配,所以我们重点就是告诉mybatis该如何去做匹配.
首先ResultMap里面填的就是我们下面已经定义好的ResultMap的名字,接下来我们就重点看我们是如何来定义这个ResultMap的.
首先我们先来看ResultMap部分,再来看Collection
<resultMap id="selectspuSaleAttrListCheckBySkuMap" type="com.auguigu.gmall.bean.PmsProductSaleAttr" autoMapping="true">
<result column="sa_id" property="id"></result>
</resultMap>我们首先需要先给我们的ResultMap定义一个名称即id,之后我们就需要定义ResultMap的type,这里的type是我们多重集合中最外层的实体对象,之后我们就需要定义该实体对象的主键即可,column指的是我们定义的返回数据中的字段名,property则是指的是我们在实体类中定义的主键,剩下的字段我们通过autoMapping=true即可让mybatis帮我们自动处理了.
<collection property="pmsProductSaleAttrValueList" ofType="com.auguigu.gmall.bean.PmsProductSaleAttrValue" autoMapping="true">
<result column="sav_id" property="id"></result>
</collection>了解完ResultMap是怎么定义的之后,collection看起来就比较简单了,这里我们就只需要看collection中的property即可,这里填的是最外层的实体类中定义的下一层集合的对象的名称,即下图所示:
HTML-CSS的基本选择器:
- ID选择器
看到ID,其实大家就都能首先想到一点,那就是一般的ID都是唯一的,所以我们一般在页面上面一个ID也只会使用一次.
定义规范一般是这样的:
这样我们便能通过下面的命令来进行ID的选择获取到该对象,并且 该对象是唯一的:
#valueSKU(即ID名){}, 重点是前面的#号
- 类选择器
类选择也叫作样式选择器,一般就是页面控件上class里面的内容例如:
之后我们便可以通过下面的命令来进行class的选择获取该对象, 该class对象是唯一的,但是使用该class的对象并不一定是唯一的:
.haha(即类名){},重点是前面的.号
- 标签选择器
HTML中我们有很多的标签,比如最常见的
等等,看到这些大家就知道了,这些标签在页面上一般都是不唯一的,一般都是有好几个的举个例子:
可以看到这两个都是div标签,但是他们的类缺失不一样的.
之后我们便可以通过下面的命令来进行标签的选择来获取到该对象们,这些对象一般都是不唯一的:
div{},直接通过标签名即可获取
了解完上面三个之后,我们便可以来了解一下下面的代码是什么意思了
var saleAttrValuesIds=$(".redborder div");
$(saleAttrValuesIds).each(function(i,saleAttrValueId){
alert($(saleAttrValueId).attr("value"));
});可以看到我们现实通过类选择器获取到class=redborder的所有空间,但是后面我们又加了这么一段代码:" div",意思是选取下一层级中所有的div标签,那么显然这里我们最后获得的就是一个div标签数组,
接下来我们再看就很简单了,就是一个简单的对div标签数组的遍历,遍历获得所有div标签中的value值
最后这就是我们修改好的代码:
function switchSkuId() {
//测试hash表是否已经传输到前端
var SkuInfoHashMapjsonStr=$('#valueSku').val();
alert(SkuInfoHashMapjsonStr);
// 被选中属性
var checkDivs = $(".redborder div");
var valueIds="";
// 拼接成属性值串
for (var i = 0; i < checkDivs.length; i++) {
var saleAttrValueDiv = checkDivs.eq(i);
if(i>0){
valueIds= valueIds+"|";
}
valueIds=valueIds+saleAttrValueDiv.attr("value");
}
//页面上的hashjson
var valuesSku = $("#valuesSku").attr("value");
var valuesSkuJson=JSON.parse(valuesSku);
// 看看hash有没有
var skuId= valuesSkuJson[valueIds];
// 当前sku
var skuIdSelf=$("#skuId").val();
// 判断是否跳转
if(skuId){
if(skuId==skuIdSelf){
$("#cartBtn").attr("class","box-btns-two");
}else{
window.location.href="/"+skuId+".html";
}
}else{
$("#cartBtn").attr("class","box-btns-two-off");
}
}-
通过winscp将Redis的压缩包上传到服务器的/opt路径下,或者直接在/opt路径下运行下面的命令:
# wget http://download.redis.io/releases/redis-3.0.4.tar.gz
这样我们就已经将Redis下载完成了
-
解压
tar -zxvf redis-3.0.4.tar.gz
-
之后依次运行下面的命令:
make make install
这样就说明已经安装完成了
-
将redis-cli和redis-server命令添加到环境变量里面,这样我们之后就可以在任意路径下使用该命令了,不用每次先运行:
find / -name redis-cli查找redis-cli的位置再运行之后的命令了
首先先定位redis-cli的位置
find / -name redis-cli

之后复制该路径
修改profile文件即配置环境变量
vi /etc/profile在最后添加下面的代码
export PATH=$PATH:/opt/redis-3.0.4/src/redis-cli
export PATH=$PATH:/opt/redis-3.0.4/src/redis-server 
记住后面的路径名需要和你自己的相适应,之后保存退出即可.
之后重新刷新一遍profile文件即可,这样redis-cli命令就能在任意路径下使用了

最后就是修改Redis的配置文件了
-
将Redis的配置文件拷贝到/etc目录下,当前命令在redis-3.0.4目录下使用
# cp redis.conf /etc/
修改配置文件:
vi /etc/redis.conf
添加这段代码,主要是让Redis能够在后台运行以及日志的存储位置:
#是否后台运行 daemonize yes #pid文件保存路径 pidfile /usr/redis/run/redis_6379.pid #端口号 port 6379 #接收来自于哪个个ip地址的请求,如果不设置,将处理所有请求 bind 127.0.0.1 #超时,单位为秒 timeout 300 #log日志级别分为4级,debug,verbose,notice,warning,生产环境一般开启notice loglevel notice #log日志位置,不设置,默认打印命令行终端 logfile stdout #数据库个数,默认使用0数据库 datebase 16 #设置redis进行数据库镜像的频率,单位为秒,意思为当900秒之内有1个key发生变化时,进行镜像备份 save 900 1 save 300 10 save 60 10000 #进行镜像备份是否压缩 rdbcompression yes #镜像备份文件名 dbfilename dump.rdb #数据库镜像存放位置 dir /usr/redis/var/ #设置该数据库是否为其他数据库的从数据库 slaveof yes #设置同时链接的客户端数量 maxclients 12800 #是否默认备份数据库镜像到磁盘 appendonly no #设置对appendonly.aof同步的频率,always表示每次读写都进行,everysec表示只对写进行累积,每秒同步一次 appendfsync everysec #是否开启虚拟内存 vm-enabled no vm-swap-file /tmp/redis.swap vm-max-memory 0 vm-page 134217728 vm-page-size 32 vm-max-threads 4 hash-max-zipmap-entries 512 hash-max-zipmap-value 64 list-max-ziplist-entries 512 list-max-ziplist-value 64 set-max-intset-entries 512 activerehashing yes


之后保存退出即可,这样我们的Redis就已经配置完成了,之后我们就可以启动Redis了
通过下面的命令启动redis并且指定redis的配置文件:
redis-server /etc/redis.conf虽然我们不会看到像网上一样的图形化界面,但是我们去查看一下日志文件,就能看到了:
vi /var/log/redis/redis-server.log这样我们就能看到redis的图形化界面了:
之后我们在开一个窗口,输入下面的命令,如果能够看到下面的界面,说明redis就正常启动了:

redis-cli如果还是不放心的话,我们还可以通过下面的命令进行进一步的确认:
ps ajx |grep redis
可以看到服务端与客户端都已经启动了
之后我们就需要在防火墙里面将6379,redis的默认端口号打开
firewall-cmd --zone=public --permanent --add-port=6379/tcp
firewall-cmd --reload
firewall-cmd --list-all 这样就结束,但是如果你是在阿里头的服务器上安装的,那么你还需去阿里云的安全组里面将6379端口打开

这样我们关于redis就已经配置安装启动完成了.
-
向相应的模块引入Redis的pom依赖
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency>
-
创建Redis的工具类-----(初始化Redis的连接池到Spring容器中)
public class RedisUtil { private JedisPool jedisPool; //初始化连接池 public void initPool(String host,int port ,int database,String password){ System.out.println(host+"|"+port+"|"+"password"); JedisPoolConfig poolConfig = new JedisPoolConfig(); poolConfig.setMaxTotal(200); poolConfig.setMaxIdle(30); poolConfig.setBlockWhenExhausted(true); poolConfig.setMaxWaitMillis(10*1000); poolConfig.setTestOnBorrow(true); jedisPool=new JedisPool(poolConfig,host,port,20*1000,password); } //从连接吃中返回一个连接给调用者 public Jedis getJedis(){ Jedis jedis = jedisPool.getResource(); return jedis; } }
-
创建Spring整合Redis的配置类-----(创建Redis连接处到Spring中)
Redis的配置文件
@Configuration public class RedisConfig { //读取配置文件中的redis的ip地址 @Value("${spring.redis.host:disabled}") private String host; @Value("${spring.redis.port:6379}") private int port; @Value("${spring.redis.database:0}") private int database; @Value("${spring.redis.password:@Yzr143253}") private String password; @Bean public RedisUtil getRedisUtil(){ if(host.equals("disabled")){ return null; } RedisUtil redisUtil=new RedisUtil(); redisUtil.initPool(host,port,database,password); return redisUtil; } }
-
测试Redis连接-----Bug解决
Class not found: "com.auguigu.gmall.GmallManageServiceApplicationTests"
这一个bug其实大家很明显就能知道这个bug是什么意思,意思就是没有找到我们的测试类,这里主要通过下面的方法来解决:
通过勾选设置里面的该选项:
Failed to execute goal org.apache.maven.plugins:maven-surefire-plugin:2.18.1:test (default-test) on project

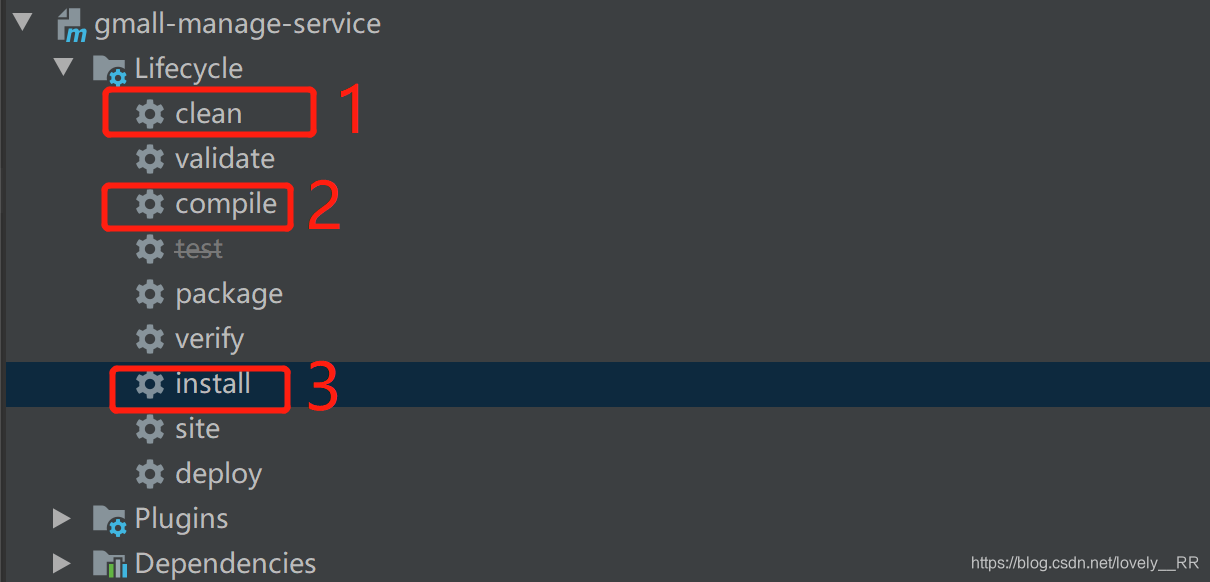
这个Bug的具体意思就是我们通过Maven尽心打包的时候因为项目中的测试文件可能有损导致我们的打包操作失败了.
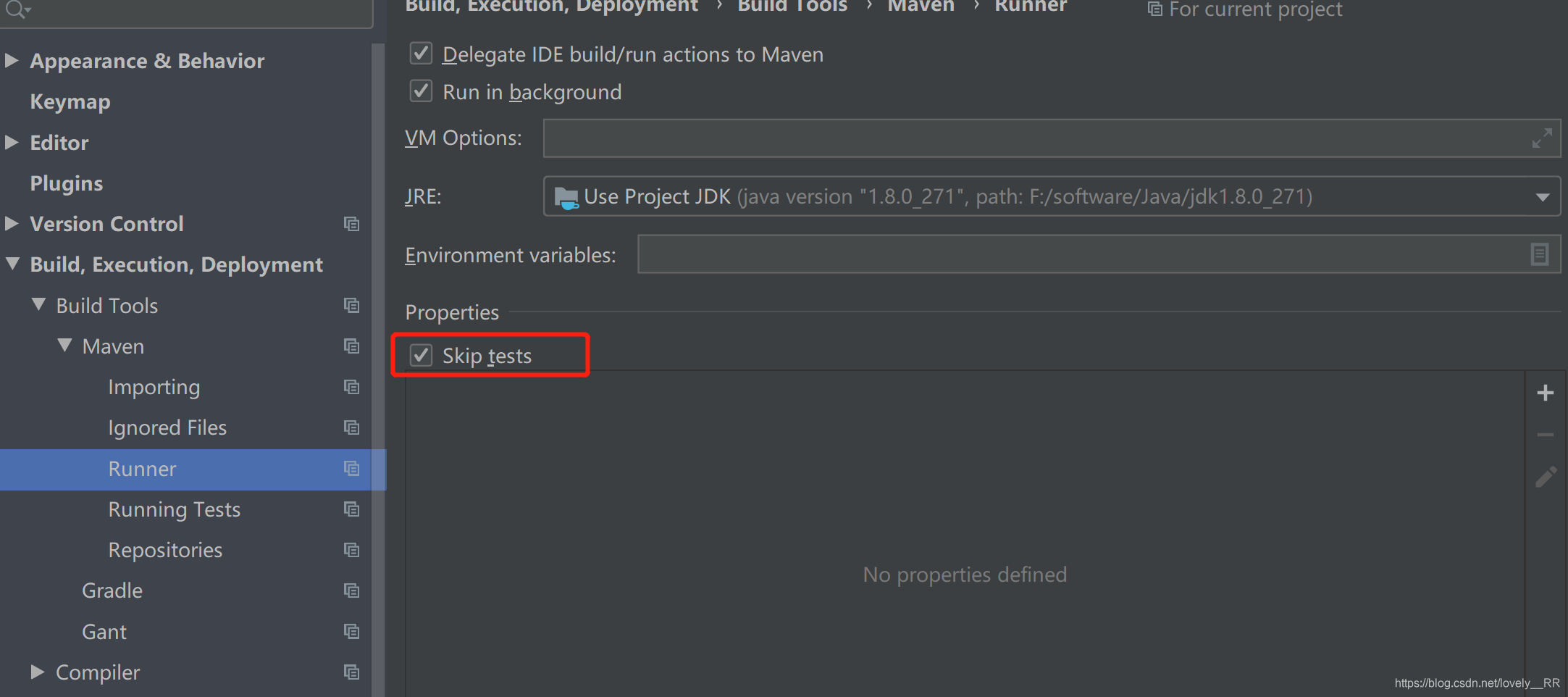
因为我们这里是Test类可能有错,所以我们可以直接忽略测试类,这样我们就能够正常打包了,这里我们可以通过勾选下面的方框,或者也可以直接在Maven选项里勾选:
Cannot determine embedded database driver class for database type NONE

java.lang.IllegalStateException: Failed to load ApplicationContext的错误
我们接着去查看他的相关错误的时候我们会发现主要错误是这个Cannot determine embedded database driver class for database type NONE,意思就是没有找到相应的数据库驱动,
百度之后,网上解释说:因为spring boot默认会加载org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration类,DataSourceAutoConfiguration类使用了@Configuration注解向spring注入了dataSource bean。因为工程中没有关于dataSource相关的配置信息,当spring创建dataSource bean因缺少相关的信息就会报错。
所以我们需要在Springboot的测试启动类上面修改该注解:
@SpringBootApplication(exclude={DataSourceAutoConfiguration.class})
这样之后就能启动了,但是自己测试之后还是出现一模一样的错误.

我们的数据库驱动一般都是编写在application参数文件里面的,并且application参数文件也刚好是我们的ApplicationContext,所以不出意外,应该是Springboot测试启动类根本就没有自动加载我们的application参数文件,所以我们只能手动把这个文件加进去了,这里我们可以直接通过添加下面的注解实现:
@PropertySource(value={"classpath:application.properties"})
这样我们再次启动我们的测试启动类就能发现已经能够正常启动了,并且已经能够正常连接到我们的Redis服务了.
但是这里我们要注意一个路径的问题,这里的classpath就已经表示是在resources文件夹下面了,所以我们的application文件的路径就只需要写resources下面的路径即可.
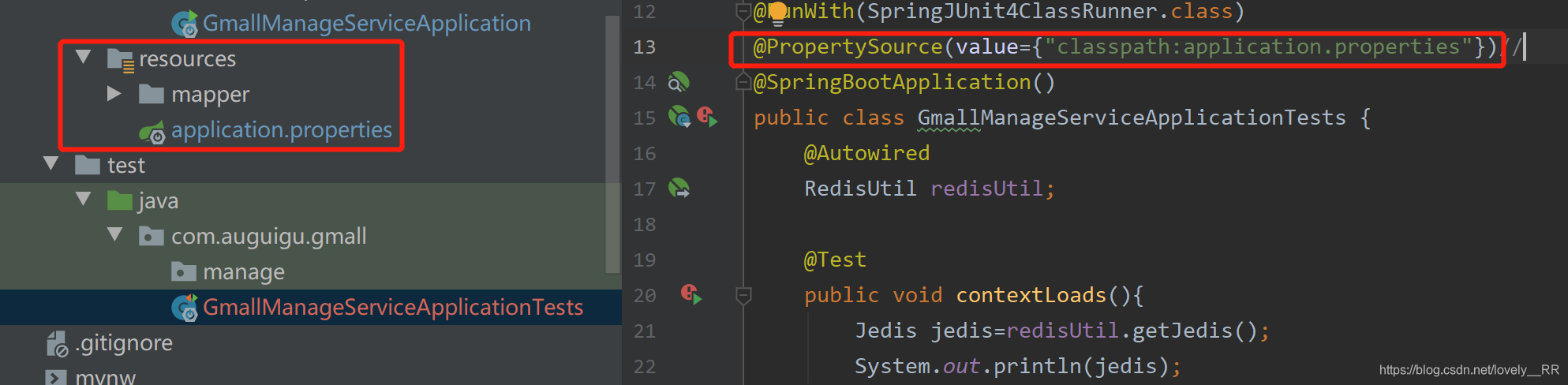
可以直接手动添加application.properties文件,就能够运行成功.
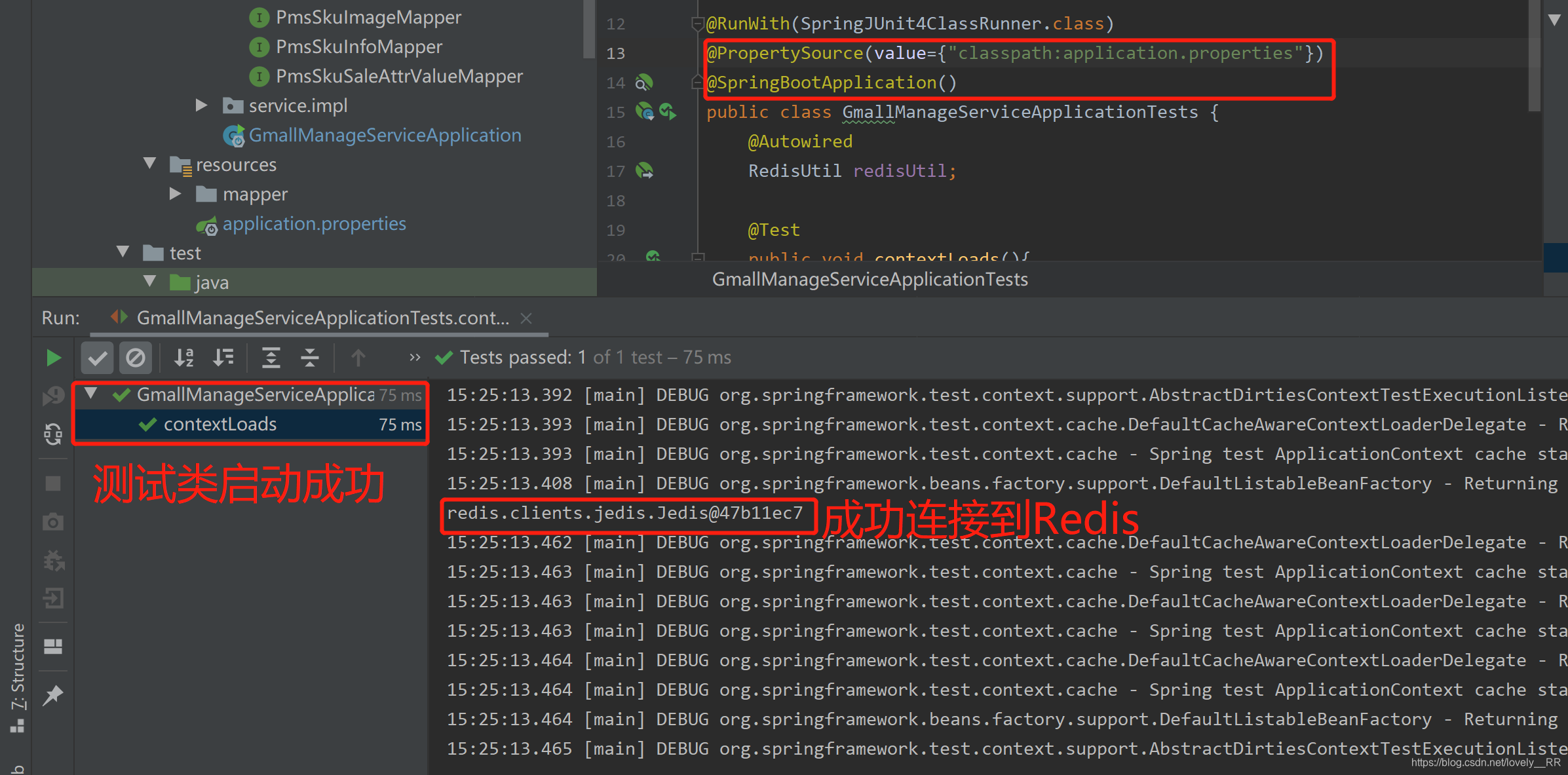
这里我们虽然测试成功了,但是自己在编写service层的时候还是遇到了一些问题还是配置文件--RedisConfig没有扫描到的问题,但是这个问题其实已经在上面解决了,只需要我们将我们的Springboot启动类转移到com.auguigu.com的路径之下,就能够正常扫描到我们的配置文件以及相应的工具类了:

如果是像我们之前的项目即完整的一个项目,并不是采用微服务的形式,那么我们直接就可以通过@Configuration注解将该配置文件注入到Spring容器之中,再在配置文件里面通过@Bean注入我们需要的各种Bean.
但是因为我们现在使用的微服务的形式,那么很显然,并不像我们之前的项目一样,他是由多个模块组合而成的,那么很显然各模块之间的通信就会比较麻烦,就比方说我们上面的配置文件读取的问题.所以我们必须要将我们**Springboot启动类与我们平常的配置文件的层级对齐 **这样才能够扫描到我们的配置文件.
或者我们也可以通过在Springboot启动类上添加 @ComponentScan进行扫描,这样也能够将我们的配置文件扫描到,但是这样的方式会严重影响我们程序的性能,毕竟之前我们一般只通过@MapperScan扫描我们相应的Mapper文件,但是如果再去扫描我们的 配置文件的话会严重影响我们程序的性能.
一般都是下面这种存储策略:
数据对象名:数据对象ID:对象属性
举例:
User:1001:username
User:1001:password
设计完数据存储策略之后我们便可以重新改写我们相应的查询逻辑了:
//从数据库中查询Sku数据
public PmsSkuInfo selectBySkuIdFromDB(Integer skuId) {
PmsSkuInfo pmsSkuInfo=new PmsSkuInfo();
pmsSkuInfo.setId(skuId);
PmsSkuInfo pmsSkuInfo1=pmsSkuInfoMapper.selectOne(pmsSkuInfo);
//sku的图片集合
PmsSkuImage pmsSkuImage=new PmsSkuImage();
pmsSkuImage.setSkuId(skuId);
List<PmsSkuImage> pmsSkuImageList=pmsSkuImageMapper.select(pmsSkuImage);
pmsSkuInfo1.setPmsSkuImageList(pmsSkuImageList);
//平台属性
PmsSkuAttrValue pmsSkuAttrValue=new PmsSkuAttrValue();
pmsSkuAttrValue.setSkuId(skuId);
List<PmsSkuAttrValue>pmsSkuAttrValueList=pmsSkuAttrValueMapper.select(pmsSkuAttrValue);
pmsSkuInfo1.setPmsSkuAttrValueList(pmsSkuAttrValueList);
//销售属性
PmsSkuSaleAttrValue pmsSkuSaleAttrValue=new PmsSkuSaleAttrValue();
pmsSkuSaleAttrValue.setSkuId(skuId);
List<PmsSkuSaleAttrValue>pmsSkuSaleAttrValueList=pmsSkuSaleAttrValueMapper.select(pmsSkuSaleAttrValue);
pmsSkuInfo1.setPmsSkuSaleAttrValueList(pmsSkuSaleAttrValueList);
return pmsSkuInfo1;
}
@Override
public PmsSkuInfo selectBySkuId(Integer skuId) {
PmsSkuInfo pmsSkuInfo=new PmsSkuInfo();
//连接缓存
Jedis jedis=redisUtil.getJedis();
//查询缓存
String skuKey="sku:"+skuId+":info";
String skuJson=jedis.get(skuKey);
//缓存不为空
if(StringUtils.isNotBlank(skuJson)){
//通过fastjson将我们的字符串转化成我们对应的Sku对象
pmsSkuInfo = JSON.parseObject(skuJson, PmsSkuInfo.class);
}
else{
//如果缓存没有,查询mysql
pmsSkuInfo=selectBySkuIdFromDB(skuId);
//mysql查询结果存储到Redis
if(pmsSkuInfo!=null){
jedis.set("sku:"+skuId+":info", JSON.toJSONString(pmsSkuInfo));
}
}
jedis.close();
return pmsSkuInfo;
}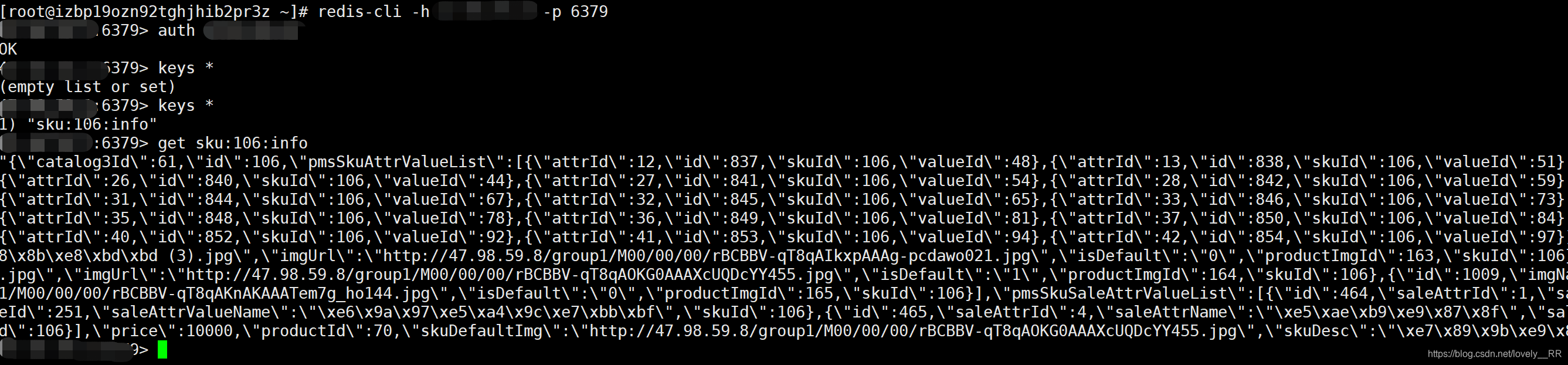
测试完成之后可以看到我们的数据已经成功存储到我们的redis中了,之后如果再次读取到相应的Sku数据就可以直接从内存中读取到,不用再去数据库中读取了
要了解下面的内容,我们首先需要了解我们完整的查询操作是一个什么样点的流程.
我们通过下面的图来让大家更加清晰的了解:

我们首先先来了解一下这三者分别代表了什么意思.
- 缓存穿透

缓存穿透指的是用户持续访问了一个数据库中根本就没有的数据,使得大量这样的访问直接怼到了数据库上,使得数据库最后直接崩掉.
这时候可能有朋友要问了,既然没有没有那为啥要查数据库呢?

别笑,可能还真有朋友会问,至少刚接触计算机时候的我可能还真会问.
我们是怎么知道数据库没有这条数据的呢,很明显是我们已经查询数据库之后才知道的,并且一般我们的查询都是对数据库中的数据进行全表查询之后再返回结果的,这种查询是特别消耗时间和性能的.
那么有人又要问了,既然都知道数据库里面没有这条数据了,那之后的请求为什么还要去查询数据库呢?

这里主要是因为第一次查询的时候,数据库里面没有这条数据,所以我们无法将数据填充到缓存中,缓存中没有,那么就只能再去数据库里面找了,主要问题就是出在下面红框内的步骤:

想想我们之前的操作,很明显都是数据库里面查出相应的数据之后,我们才把相应的数据存储到缓存中,那样我们之后才能直接读取缓存,然后返回我们的结果,但是数据库中都没有的数据显然缓存中肯定也没有,所以之后的请求就全部都怼到数据库上导致数据库的崩溃.
我们也可以通过下面的图来理解:

缓存穿透一般是黑客或不法分子利用Redis与数据库的数据漏洞进行 集中一点,连续攻击 ,从而使得我们的数据库服务直接崩溃的异常.
- 缓存击穿

缓存击穿指的是,由于各种原因导致Redis中的一个热点Key ( 目前访问人数较多的数据可以理解成 微博热搜 ) 失效了,这样突然大量的访问就直接又怼到了数据库上,导致数据库也是直接就崩掉了.
我们也可以通过下面的图来理解:

其实这种问题可能是离我们生活最近的,就比方说 微博又炸了:

百万级别的,关键是这种请求又基本是 同一时间点怼到数据库上.
百万级别的请求直接怼到数据库上,这就好比马保国跟普通群众比赛一样,很明显就只有一个结果:

- 缓存雪崩

缓存雪崩指的是缓存中的 大量数据在同一个时间段内失效 ,导致大量对于这部分数据的访问直接怼到了数据库上,导致数据库直接就崩掉了.
我们也可以通过下面的图来理解:

Redis中的缓存数据的过期时间是一样的,导致同一时间点大部分的缓存数据直接过期,这样对于这部分的数据访问肯定又是直接怼到数据库上了.数据库又崩了.
数据库只能说我好难,为什么都欺负我,嘤嘤嘤.

了解完三者的概念之后,我们可以横向对比一下三者:

- 缓存穿透解决方案
了解完上述关于缓存穿透的概念之后我们就知道了只要问题就出在数据库无法将不存在的数据存储到Redis中,导致Redis中一直没有该数据,使得关于该数据的访问全部都是直接怼到数据库上,最后导致数据库崩溃.
既然这样,我们就将该数据存储到Redis里面,这样对于该数据的访问就又重新怼到Redis上面了,但是我们要注意这条数据既然不存在,那么我们就将该数据定义为空,并且要 给它设置过期时间,并且这种国旗时间不要设置的太长,20-30秒即可,否则这种无用的数据一致存储在Redis里面,也是浪费.
public PmsSkuInfo selectBySkuId(Integer skuId) {
PmsSkuInfo pmsSkuInfo=new PmsSkuInfo();
//连接缓存
Jedis jedis=redisUtil.getJedis();
//查询缓存
String skuKey="sku:"+skuId+":info";
String skuJson=jedis.get(skuKey);
//缓存不为空
if(StringUtils.isNotBlank(skuJson)){
//通过fastjson将我们的字符串转化成我们对应的Sku对象
pmsSkuInfo = JSON.parseObject(skuJson, PmsSkuInfo.class);
}
else{
//如果缓存没有,查询mysql
pmsSkuInfo=selectBySkuIdFromDB(skuId);
//mysql查询结果存储到Redis
if(pmsSkuInfo!=null){
jedis.set("sku:"+skuId+":info", JSON.toJSONString(pmsSkuInfo));
}
else{
//数据库中同样也不存在该数据
//将空值设置给该Key,并且设置30秒的过期时间
jedis.setex("sku:"+skuId+":info",30,JSON.toJSONString(""));
}
}
jedis.close();
return pmsSkuInfo;
}- 缓存击穿解决方案
缓存击穿的解决方案就比较复杂了,不像缓存穿透和缓存雪崩一样,只需要设置相应的过期时间或者是将数据存进Redis即可解决.
缓存击穿的解决方案相应的就比较多,主要有两种:
- Redis自身的分布式锁实现
- 通过redisson框架实现
接下来我们分别讲一下两者的实现方式:
- Redis自身的分布式锁
缓存击穿的特殊性就在于是一个热点数据突然失效,导致大规模的请求直接怼到数据库上,这其中的重点就是一条热搜数据,大规模的请求在同一时间点怼到数据库.
所以分布式锁的思想就是, 每次向Redis请求数据的时候,都在Redis里面给该条数据上锁,一旦锁设置成功,那么就只有当前的进程可以进入到数据库中进行查询,并且查询完成之后就 将该数据重新存到Redis之中,数据存储成功之后 再释放掉该锁,在此之前其他锁没有设置成功的进程就 只能自旋等待锁被释放为止.
因为第一条请求结束之后,Redis中就已经重新有了该热点数据的缓存,所以之前自旋的进程就可以 直接从Redis中拿到该热点数据,不用再去访问数据库了,这样就极大的降低了数据库的压力.
我们也可以通过下面的思维导图来帮助大家理解:

下面是一个小的Demo:
public PmsSkuInfo selectBySkuId(Integer skuId,String ip) {
System.out.println("ip:"+ip+"的机器进入访问,"+"进程名称为:"+Thread.currentThread().getName());
PmsSkuInfo pmsSkuInfo=new PmsSkuInfo();
//连接缓存
Jedis jedis=redisUtil.getJedis();
//查询缓存
String skuKey="sku:"+skuId+":info";
String skuJson=jedis.get(skuKey);
//缓存不为空
if(StringUtils.isNotBlank(skuJson)){
System.out.println("ip:"+ip+"的机器进入访问,"+"进程名称为:"+Thread.currentThread().getName()+"已经成功拿到缓存中的数据");
//通过fastjson将我们的字符串转化成我们对应的Sku对象
pmsSkuInfo = JSON.parseObject(skuJson, PmsSkuInfo.class);
}
else{
System.out.println("ip:"+ip+"的机器进入访问,"+"进程名称为:"+Thread.currentThread().getName()+"开始申请分布式锁:"+"sku:"+skuId+":lock");
//如果缓存没有,查询mysql
//设置分布式锁,避免缓存击穿
String OK=jedis.set("sku:"+skuId+":lock","1","nx","px",10*1000);
if(StringUtils.isNotBlank(OK)&&OK.equals("OK")){
System.out.println("ip:"+ip+"的机器进入访问,"+"进程名称为:"+Thread.currentThread().getName()+"已经申请到分布式锁:"+"sku:"+skuId+":lock"+"过期时间为10秒");
pmsSkuInfo=selectBySkuIdFromDB(skuId);
try {
Thread.sleep(1000*7);
} catch (InterruptedException e) {
e.printStackTrace();
}
//mysql查询结果存储到Redis
if(pmsSkuInfo!=null){
//过期时间随机避免缓存雪崩
jedis.setex("sku:"+skuId+":info", (int) (10*Math.random()*10),JSON.toJSONString(pmsSkuInfo));
}
else{
//数据库中同样也不存在该数据,也传到Redis中,避免缓存穿透
jedis.setex("sku:"+skuId+":info",30,JSON.toJSONString(""));
}
System.out.println("ip:"+ip+"的机器进入访问,"+"进程名称为:"+Thread.currentThread().getName()+"使用完毕了,释放了分布式锁:"+"sku:"+skuId+":lock");
//在访问mysql之后,需要将分布式锁释放掉
jedis.del("sku:"+skuId+":lock");
}
else{
System.out.println("ip:"+ip+"的机器进入访问,"+"进程名称为:"+Thread.currentThread().getName()+"没有申请到分布式锁:"+"sku:"+skuId+":lock"+"已经开始自旋");
try {
//进程休眠几秒之后,开始自旋
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//开始自旋
return selectBySkuId(skuId,ip);
}
}
jedis.close();
return pmsSkuInfo;
}可以看到这是测试结果:

- redisson框架 引入Redisson框架之后,我们就不用上面使用Redis的分布式锁那么繁琐.直接几行代码就能搞定. 首先我们需要先引入Redisson框架所需要的依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.10.5</version>
</dependency>之后我们就需要配置Redisson框架的配置信息
@Configuration
public class RedissonConfig {
//读取配置文件中的redis的ip地址.端口号,数据库,密码
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private String port;
@Value("${spring.redis.database}")
private int database;
@Value("${spring.redis.password}")
private String password;
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
//链式编程
config.useSingleServer().setAddress("redis://" + host + ":" + port)
.setPassword(password)
.setDatabase(database);
RedissonClient redisson = Redisson.create(config);
return redisson;
}
}这样我们就已经将Redisson引入到我们的Spring容器之中了
之后我们便来编写代码进行测试:
@Controller
public class RedissonController {
@Autowired
RedisUtil redisUtil;
@Autowired
RedissonClient redissonClient;
@RequestMapping("/testRedisson")
@ResponseBody
public String testRedisson(){
Jedis jedis=redisUtil.getJedis();
RLock lock=redissonClient.getLock("lock");//声明锁
//上锁
lock.lock();
try {
String v=jedis.get("k");
if(StringUtils.isBlank(v)){
v="1";
}
System.out.println("---->"+v);
jedis.set("k",(Integer.parseInt(v)+1)+"");
jedis.close();
}
finally {
//解锁
lock.unlock();
}
return "success";
}
}为了模拟高并发,我们通过Apache来进行压力测试(后续我会单独出一篇博客讲解压力测试,主要因为篇幅已经很长了)


8072端口:

8073端口:

- 缓存雪崩解决方案
了解完上述的缓存雪崩的概念之后,解决办法就比较简单了,既然是因为数据的过期时间都是一样的才导致数据同时失效,那么我们就可以通过 将数据的过期时间设置成随机的 ,这样就会在极大程度上减少大量数据同时过期的情况.
举个例子,可以通过下面的方法来实现:
public PmsSkuInfo selectBySkuId(Integer skuId) {
PmsSkuInfo pmsSkuInfo=new PmsSkuInfo();
//连接缓存
Jedis jedis=redisUtil.getJedis();
//查询缓存
String skuKey="sku:"+skuId+":info";
String skuJson=jedis.get(skuKey);
//缓存不为空
if(StringUtils.isNotBlank(skuJson)){
//通过fastjson将我们的字符串转化成我们对应的Sku对象
pmsSkuInfo = JSON.parseObject(skuJson, PmsSkuInfo.class);
}
else{
//如果缓存没有,查询mysql
pmsSkuInfo=selectBySkuIdFromDB(skuId);
//mysql查询结果存储到Redis
if(pmsSkuInfo!=null){
//设置随机过期时间
jedis.setex("sku:"+skuId+":info", (int) (10*Math.random()*10),JSON.toJSONString(pmsSkuInfo));
}
else{
//数据库中同样也不存在该数据
jedis.setex("sku:"+skuId+":info",30,JSON.toJSONString(""));
}
}
jedis.close();
return pmsSkuInfo;
}下载地址:http://nginx.org/en/download.html
点击下载

下载完成之后解压到相应的文件夹下,之后我们去修改配置文件
之后我们便可以去启动服务

如果碰到该问题: nginx: [error] CreateFile() "E:\nginx\nginx-1.19.5/logs/nginx.pid" failed
我们就直接在cmd命令窗口创建该文件即可:

即可创建文件
这样我们的Nginx就已经启动成功了.
- 下载安装解压
下载地址:https://www.apachehaus.com/cgi-bin/download.plx

下载完成之后解压该文件,会出现一个叫Apache24的文件夹
之后我们需要去修改以下他的配置文件:

修改服务的根目录路径

服务监听的端口号
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RxCMXOqX-1607338889993)(C:\Users\22935\AppData\Roaming\Typora\typora-user-images\1606906868873.png)]

- 启动服务

这样服务就算启动成功
-
压力测试命令
ab -c 200 -n 1000 http:nginx负载均衡/压力方法
ab是压力测试的命令
-c代表并发数
-n代表总请求数
测试我们的Redis:

接下来我们再来看看我们的Redis是否是线程安全的:



通过压力测试,我们便可以迅速检查是否有安全问题,测试之后我们可以发现我们的程序的确存在相应的安全问题
我们先通过通过官方的解释来理解一下什么是搜索引擎.当然了我们之后会通过更加通俗的方式来详细讲解搜索引擎的概念.
维基百科对于搜索引擎的介绍:
搜索引擎(英语:search engine)是一种信息检索系统,旨在协助搜索存储在计算机系统中的信息。搜索结果一般被称为“hits”,通常会以表单的形式列出。网络搜索引擎是最常见、公开的一种搜索引擎,其功能为 搜索万维网上储存的信息。
其实维基百科的解释比较到位的,,说白了搜索引擎就是一个帮助我们 快速检索信息 的工具.
但是大家又要说了,概念是知道了但是我好想没怎么用过搜索引擎啊.
相信我,其实大家 每天都在接触搜索引擎 ,这里我们可以举一个非常简单的栗子.
如果我们使用的是谷歌浏览器的话,那么我们在设置里面就能看到这么一个选项就是更换我们的搜索引擎.
百度,360 这些都是属于搜索引擎.当然了像 阿里的夸克,搜狗,UC 等等都是搜索引擎.

既然说到搜索引擎的搜索,那么我们相应的,我们就会想到数据库里面的搜索,那么我们就会问同样是搜索为什么最后选择通过搜索引擎来实现搜索而不是通过数据库来实现搜索呢?

其实我们通过上面的概念能够总结出搜索引擎的一个最最最最最最大的特点就是搜索的速度非常的快 ,大家都知道数据库在 百万级别的数据量 的时候就会明显表现出 搜索能力的下降 ,必须通过 优化SQL的方式才能提高运行的速度 ,但是搜索引擎因为在 底层的搜索算法 上面就和数据库的搜索不同,这就使得搜索引擎本质上搜索的速度就呈现 飞一般感觉

既然这样我们肯定就会想,卧槽快快快,到底他们俩的算法有什么区别呢? Come on! Just Teach Me!

既然我们想要知道搜索引擎为什么这么快的话,我们就必须要将他与数据库 横向对比,这样才能够体现出他为什么强大.
我们先来讲解一下数据库底层的搜索算法-正排索引:
再讲解正排索引之前,我们需要先明白数据库关于搜索的一些流程,在数据库中相信大家都十分清楚主键这个概念吧,接下来我们需要明确下面主键的这几个概念以及搜索内容的概念,需要先明白这几个概念,后续才能更好的理解:
- 主键一般定义成数值类型即int,一般不会通过字符来进行定义,排除
身份证,电话号码等等这些行业里面特定的主键,一般是会通过int来定义主键的. - 主键一般都是在后台显示的,一般不会在前台的页面里面显示,
就算在前台显示,也是显示前端写好的序号即递升的主键:1,2,3,4.......n,这就是使得使用前台使用搜索功能的用户 一般是不会直接搜索主键的,毕竟他们根本就不知道主键是啥,在哪里看. - 用户使用搜索功能的时候一般都是 通过字符串来进行搜索 ,这就使得搜索一般不会直接匹配主键----正如我们第一点强调的,主键一般都时定义成int类型
- 用户也一般不会直接通过主键来进行搜索----正如我们第二点说的,主键一般都是在后台显示的,一般不会显示在前台的页面里面,用户一般根本就不知道主键是什么,因为根本就看不到
明白了上述四点内容之后我们再来讲解正排索引,正排索引的概念其实很简单他就是按照我们的主键顺序查找,根据主键找到该对象之后,在依次将该对象的属性与用户输入的内容进行匹配,如果匹配到就停止,如果没有的话就继续重复上面的查找过程.
接下来查我们通过一个简单的栗子来不夯筑我们理解一下:
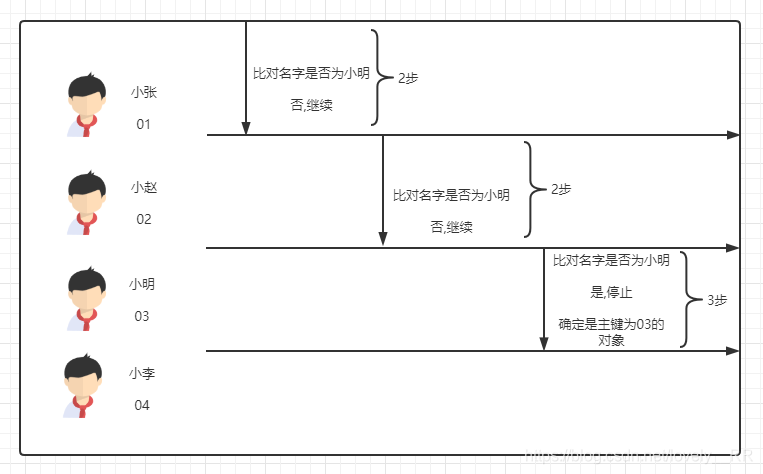
假设我们到一个教室里面找小明同学,但是呢我们只知道这些学生的学号,那么显然我们的查找过程应该是这样的:

显然这样的效率是不行的,首先先要按照主键顺序查找相应的对象,其次就是需要校验对象的每个对象是否与我们搜索的内容匹配,如果对象的属性多的离奇,那么这个过程会更加的消耗时间.
接下来我们再讲解一下搜索引擎的搜索算法-倒排索引:
倒排索引则采取了另外一种方式来存储数据,他在与数据库中的数据绑定之后他会将数据库中的数据进行重构,先将对象的各项属性进行分词处理,处理完成之后将相应的属性与他们的主键进行绑定但是这个绑定过程不再是主键----属性的格式,而是更换成属性分词----主键的形式,这样进行搜索匹配的过程中就可以直接匹配属性,之后再将最后查询出来的主键进行匹配即可.可能这样说大家不是很能理解,我们还是通过下面的栗子来帮助大家理解:
显然这样是能够极大的降低查询的时间的,因为我们 可以直接将主键对象与我们的内容进行匹配 了,不用先找到对象之后再比对对象的属性这么麻烦了.
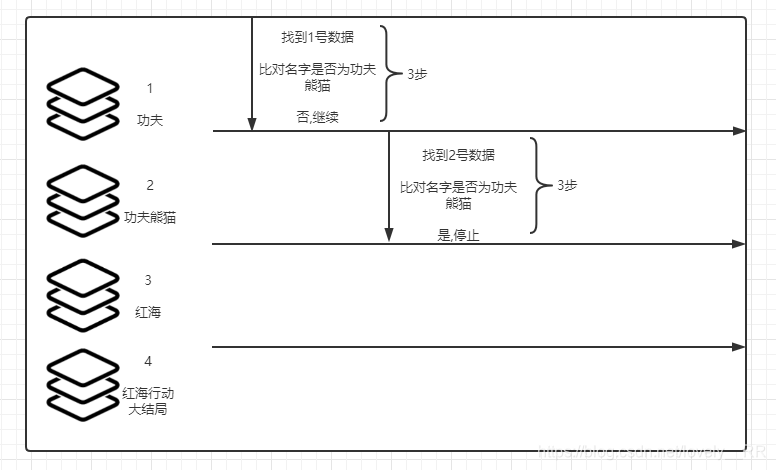
如果还是不是能够理解的话,我们再通过下面的栗子加深理解: 假设我们数据库中的 数据是这样的:

假设我们查询 功夫熊猫 这个内容,那么显然我们数据库搜索的过程就是这样的
我们再来看我们搜索引擎的搜索过程:
首先我们会将数据重构成这样

将数据重构成这样之后,我们再来看看搜索引擎的搜索过程:
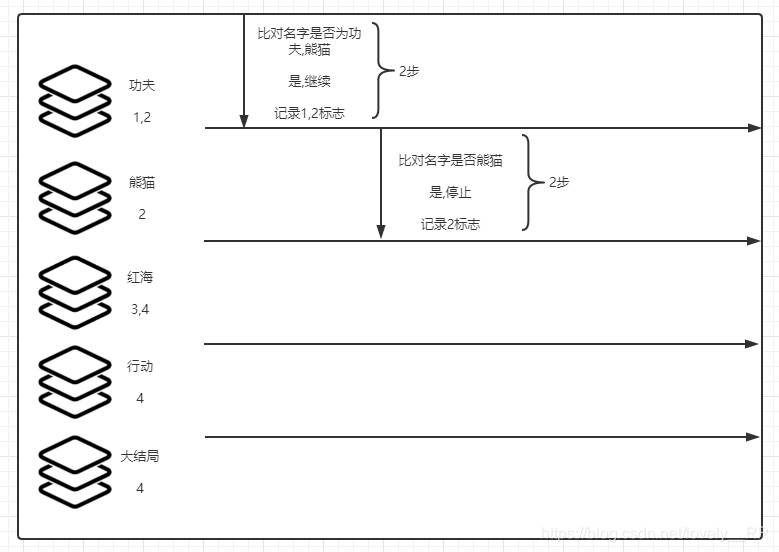
每获得一个分词之后就只检查是不是剩下的分词中的一个,并且 记录主键是采取数据交集的策略,这样就使得搜索的速度大大加快.
接下来的是我自己的想法,可能说的不对,大家就当看着玩玩!!
如果用两个数据结构分别来表示正排索引以及倒排索引的话,可以是下面这样:
链表----正排索引
每次都必须按序查找,就像链表一样,必须从头开始查找,并且也像链表的比对过程一样.
Map----倒排索引
也是需要 按序查找,但是查找的过程变得简便很多,匹配之后就可以像Map一样直接取出相应的主键值,类似于Map的get()方法,直接获取key的value值
了解完什么是搜索引擎之后,我们再来看看目前主流的搜索引擎运用的 技术 有哪些?
目前主流的搜索引擎技术主要有两大家:
-
Solr
-
ElasticSearch
接下来我们简单介绍一下这两者:
其实Solr与ElasticSearch两者的底层都是通过Apache的Lucene来实现的,只是Solr先被开发出来而已,ElasticSearch后开发出来而已.两者的基本功能其实相差不大,只是一些特定的方位内存在差异
Solr:
优点:
- 支持
多种数据格式:json,xml,html等等等 - 更加的成熟,稳定(毕竟是最先开发出来的,姜还是老的辣)
非实时搜索的 情况下搜索的速度更快
缺点:
- 建立索引实现实时搜索 的情况下搜索
速度明显降低
ElasticSearch:
优点:
- 支持
实时搜索,搜索速度不会降低 - 支持
分布式
缺点:
- 自动化程度还不够高
安装环境
-
首先是安装环境:
Centos7+jdk1.8
主要配置文件
- 配置文件:
elasticsearch.yml(主要配置ElasticSearch集群信息) jvm.options(jvm内存信息)

创建文件夹并上传文件并解压
-
创建文件夹并上传文件并解压
mkdir -p /opt/es
将我们的文件上传到该目录下
这时候这些文件都是没有权限的,我么你需要给这些文件分配权限
解压文件:
tar -zxvf elasticsearch-6.3.1.tar.gz


修改配置文件
-
修改配置文件
ES使用最大线程数,最大内存数,访问的最大文件数
如果是Centos6的话,上面三个都需要进行配置,否则linux不会允许该环境使用这么大的线程数
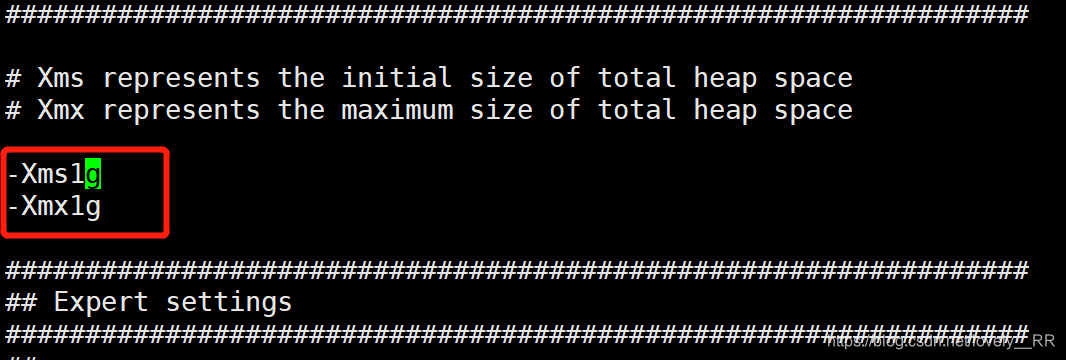
但是在Centos7里面就只需要配置访问的最大文件数即可.
主要就是elasticSearch的默认内存太大,可能超过了我们服务的承受范围,我这里默认的是1G
这里我们把他修改成256M
之后再去启动试试:
之后我们可能会遇到这个问题:
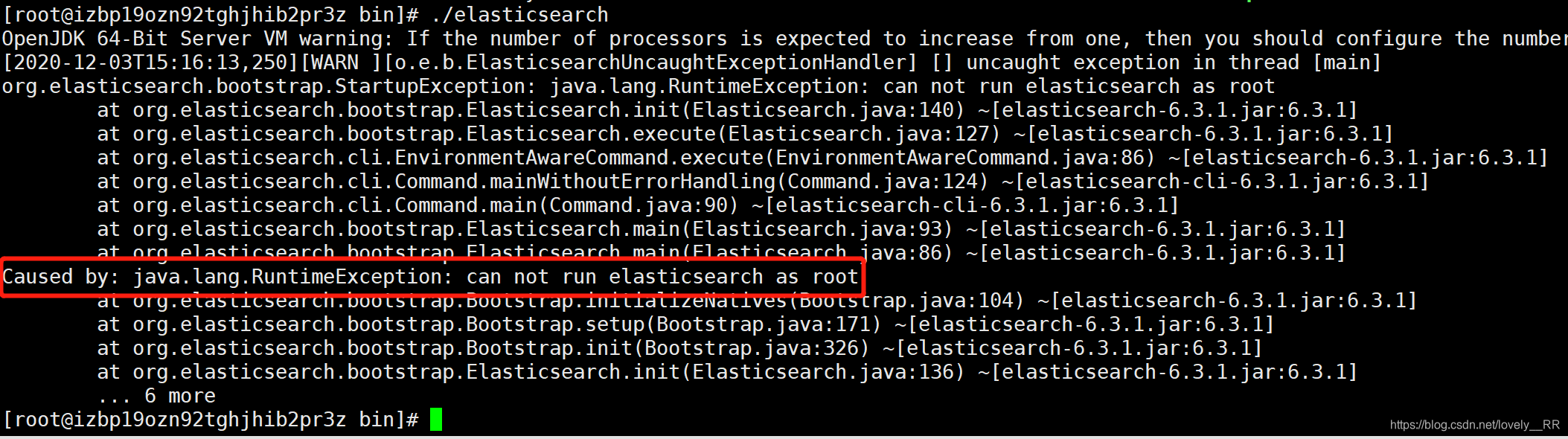
原因是在
elasticSearch5.0版本以后,很多大公司也已经开始采用ElasticSearch作为他们搜索引擎的技术了,大公司使用之后发现ElasticSearch存在安全漏洞,因为在5版本的ElasticSearch中,ElasticSearch运行都是通过root用户进行的,所以有些黑客就通过这个特性直接获取到root用户的密码以及其他信息,使得信息外泄.所以在5版本之后,ElasticSearch都开始采用这种方案,即
所有的操作不能再是root用户,必须单独创建一个用户来操作elasticSearch.所以我们如果按照默认的配置文件来启动ElasticSearch的话就还是通过root用户启动,所以我们需要重新创建一位用户并且通过在该用户的状态下启动ElasticSearch.
//创建一个新的用户 adduser es //切换到es用户下 su es
切换完成之后我们能够发现,
前面的用户就已经改变了,并且命令前面的符号也已经发生改变了.不再是#号,而是换成了$符号之后我们再来重新启动一下elasticSearch试试
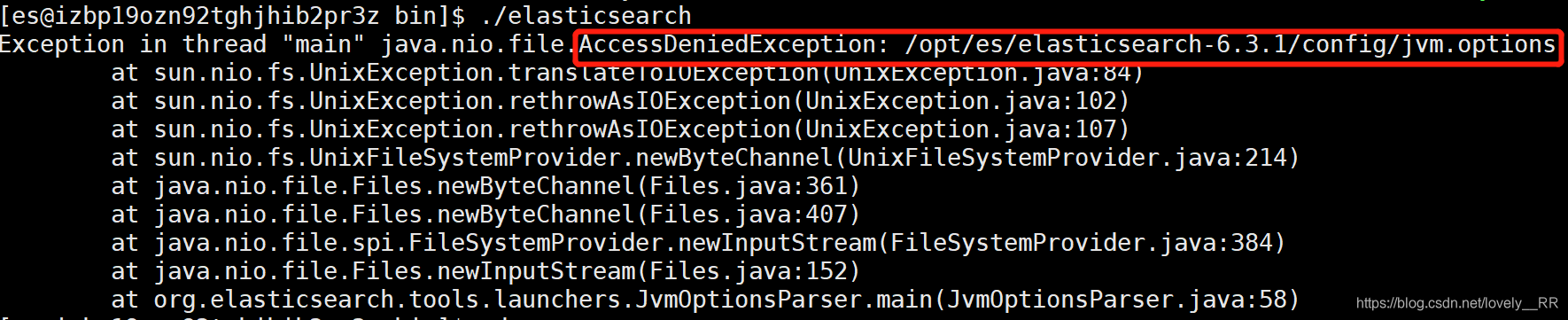
之后我们又遇到这个问题,意思是:我们的es用户没有权限访问该文件jvm.options
所以我们需要切换回root用户去修改以下es用户的访问权限
//切换成root用户 su root //返回上级目录 cd .. //进入config cd config //将config下的所有文件都给予最大权限 chmod 777 *
这样我们的es用户即可访问jvm.options文件了.
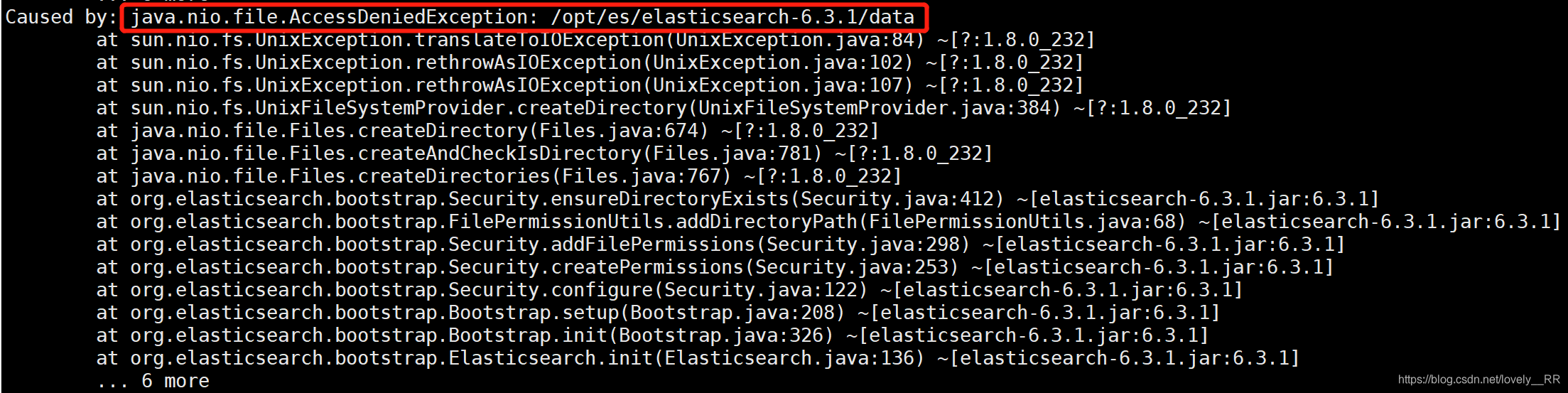
之后我们再去重新启动一下我们的elasticSearch但是我们又会遇到下面的问题
该问题主要是es用户没有权限访问data文件夹(data是es的软件和日志数据目录)
这里为了解决之后所有可能遇到的权限不足的问题,我们决定通过切换到root用户,之后将elasticSearch的根目录下将所有的文件的权限都打开,但是
不建议大家这样做,最好是启动之后哪里报权限不足的时候,我们在依次切换到root用户去将相应的文件的权限打开.我们切换到root用户之后,使用下面的命令将elasticSearch下的文件通过轮询的方式将权限都打开.
chmod 777 -R elasticsearch-6.3.1
这样我们就已经将所有文件的权限都已经打开了,这时候我们切换成es用户来进行我们接下来的操作.
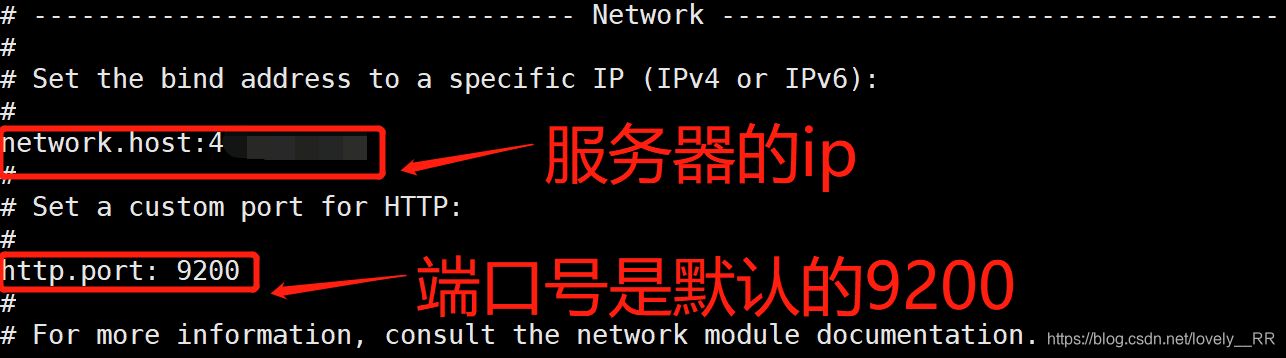
之后我们需要去配置我们的默认ip以及端口号,这样外网才能访问我们的elasticSearch
这里我们是在elasticsearch.yml文件里面进行配置:
进去之后我们主要配置这两个参数:
如果不是云服务器的话,你就直接按下面我的提示配置即可
如果你是云服务器的话,那么你就不能这么配置了,如果还是按照上面的配置的话,那么我们启动elasticSearch就会出现下面的错误:
这时候我们需要这样配置:
记住这里不能填云服务器的公网ip地址,否则还是连不上的
并且这样配置完成之后,如果是云服务器,我们还需要在防火墙以及阿里云控制台打开9200以及9300两个端口,否则还是连接不上.
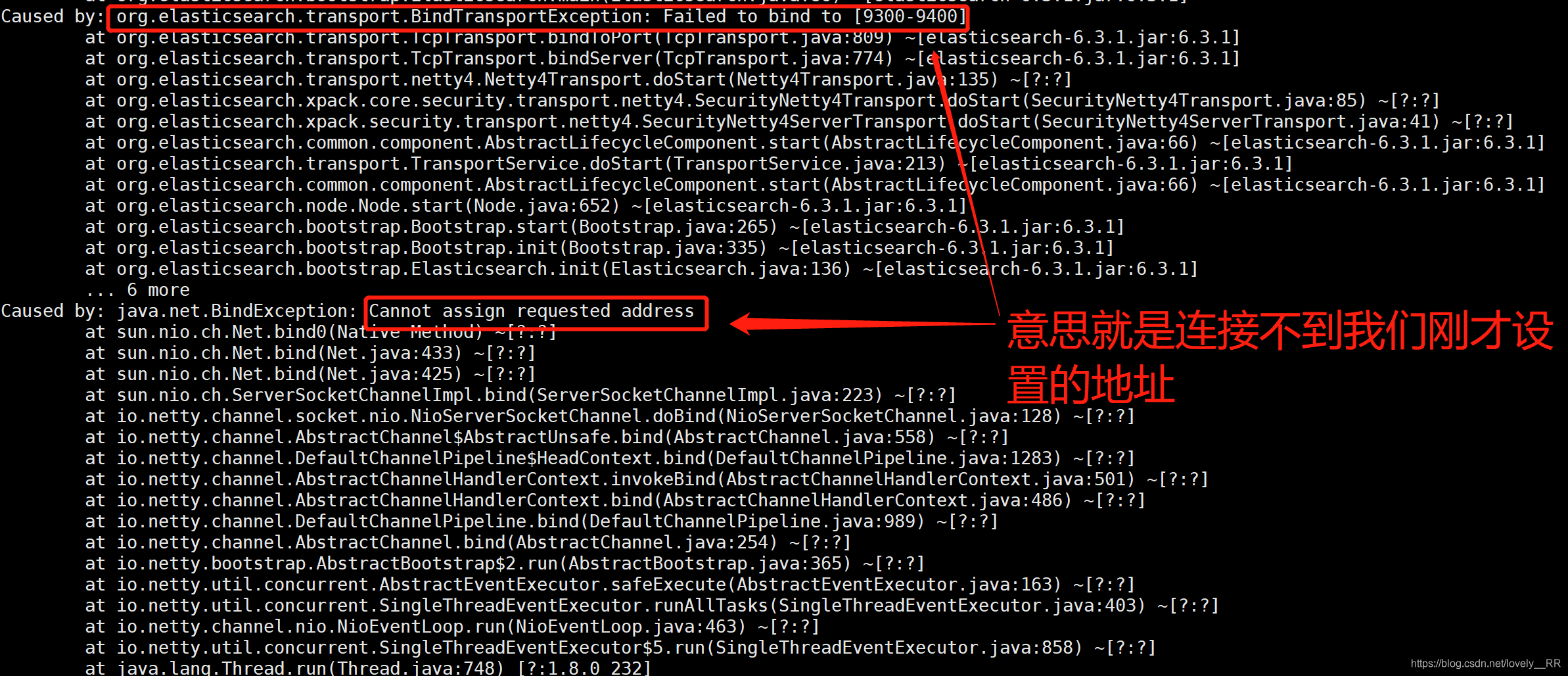
这样我们配置完就不会报上面的错误了,但是我们重新启动之后会报另外的问题:
意思就是elasticSearch鄙视我们当前的系统,说我们当前系统能够打开的最大文件数以及能够使用的最大内存数也都不够,需要升级到他相应的最低要求
既然这样我们就要去修改linux的配置(配合es的启动需求),该操作需要在root用户下进行,否则会提示权限不足:
1.修改linux的limits配置文件,设置内存线程和文件
该文件所在位置: /etc/security/limits.conf
添加下面的代码:
*hard nofile 65536 *soft nofile 131072 *hard nproc 4096 *soft nproc 2048
这些代码需要写在#End of file之前,否则这些代码是不会生效的,如果你是云服务器的话,那么你还需要将#End of file后面的参数也修改以下,否则之后启动还是会报相同的错误
之后我们中心刷新一下该文件,使其生效.
source /etc/security/limits.conf
2.修改linux的sysctl配置文件,配置系统使用内存
文件所在位置: /etc/sysctl.conf
添加下面的代码:
vm.max_map_count=655360 fs.file-max=655360
之后保存退出之后,我们就需要让该配置生效
sysctl -p
这样配置就已经生效了.
之后我们便可以重新用es用户去启动elasticSearch了,可以发现已经启动成功了:
虽然他显示的
发布地址是通过我们的内网ip地址,但是我们通过浏览器访问的时候还是直接通过公网ip:9200访问即可.










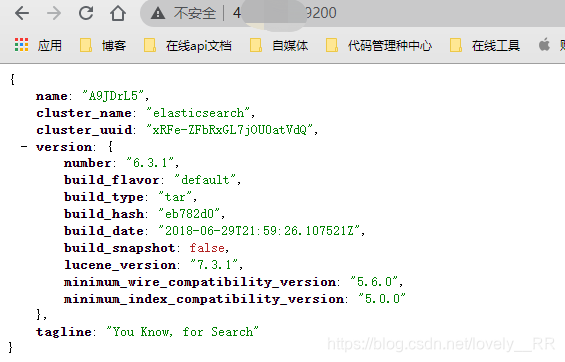
这样我们的elasticSearch就算是安装并且启动成功了.
我们在启动elasticSearch的时候,如果是直接使用 ./elasticsearch 命令启动的话,他是会一直停留在运行成功的界面,我们无法继续在页面上进行命令的执行的.所以如果我们需要后续命令的执行的话,我们就可以通过下面的命令启动elasticSearch
nohup ./elasticsearch &这样我们启动完elasticSearch之后,就可以继续在页面上输入我们的命令了.