- This repository is created from Linux Academy course, AWS certified solutions architect - Associate Level and my readings of different websites such as AWS docs
- It includes
- AWS Services description (see the table of contents, below):
- It describes AWS services from the architect role perspective
- There's particularly a section for the following topics: Scalability, Consistency, Resilience, Disaster Recovery, Security which includes Encryption, Pricing, Use cases, Limits and, Best practices
- AWS CLI commands: it's still a work in progress
- Anki flashcards exported file: 318 cards
- AWS Services description (see the table of contents, below):
- Infrastructure
- Security: Identity and Access Control (IAM)
- Security: Security Token Service (STS)
- AWS Organization
- Compute - Elastic Cloud Computing (EC2)
- Serverless Compute - Lambda
- Serverless Compute - API Gateway
- Containerized Compute - Elastic Container Service (ECS)
- Networking - Virtual Private Cloud (VPC)
- Networking - Route 53
- Storage - Simple Storage Service (S3)
- Networking - CloudFront
- Storage - Elastic File System (EFS)
- Database - SQL - Relational Database Service (RDS)
- Database - SQL - RDS Aurora Provisioned
- Database - SQL - RDS Aurora Serverless
- Database - NoSQL - DynamoDB
- Database - In-Memory Caching
- Hybrid and Scaling - Elastic Load Balancing (ELB)
- Hybrid and Scaling - Auto scaling Groups (ASG)
- Hybrid and Scaling - Virtual Private Networks (VPN)
- Hybrid and Scaling - Direct Connect (DX)
- Hybrid and Scaling - Snow*
- Hybrid and Scaling - Data Migration - Storage Gateway
- Hybrid and Scaling - Data Migration - DB Migration Service (DMS)
- Hybrid and Scaling - Cognito
- Application Integration - Simple Notification Service (SNS)
- Application Integration - Simple Queue Service (SQS)
- Application Integration - Elastic Transcder
- Analytics - Athena
- Analytics - Elastic Map Reduce (EMR)
- Analytics - Kinesis
- Analytics - Redshift
- Logging and Monitoring - CloudWatch
- Logging and Monitoring - CloudTrail
- Logging and Monitoring - VPC Flow Logs
- Operations - CloudWatch Events
- Operations: Key Management Service (KMS)
- Deployment - CloudFormation
- Deployment: Elastic BeansTalk
- Deployment: OpsWorks
- AWS Services - Comparisons
Global Infrastructure
Region
- It's a collection of data centers (AZs)
- It has 2 or more data centers (AZs)
- Regions AZs are independ from each other (to decrease failure likeliness)
- Regions AZs are close enough to each other so that latency is low between them
- High Speed network:
- Some regions are linked by a direct high speed network (see link above)
- It'sn't a public network
- E.g., Paris and Virginia regions are linked by a high speed network
- Data created is a specific region wont leave the region
- Unless we decide otherwise (data replication to another region)
- Regions allow to operate in a specific country where laws are known
- We make sure that data will only operate under the jurisdiction of those laws
- E.g., US East (N. Virginia) region:
- It's the 1st AWS region (launched in 2006)
- It's always up-to-date: all new services are delivered 1st in this region
- It's good for all training purposes
Availability Zone (AZ)
- It's a logical data center within a region
- There could be more physical data centers within an AZ
- Its name could be different from 1 aws account to another
Edge Locations
- They're also called "Points of Presence" (Pops)
- They host AWS CDN
- There're many more than regions
Regional Edge Caches
- It's a Larger version of Pops
- It has more capacity
- It can serve larger areas
- There're less of them
Description
-
It's a centralised control of an AWS account
-
It's a global service
-
It controls access to AWS Services via policies that can be attached to IAM Identities
-
It's a shared Access to our AWS account.
-
It has granular Permissions:
- It allows to set permission at service level
-
It allows Multifactor Authentication (MFA)
-
It allows to set up our own password rotation policy
-
It supports PCI DSS Compliance (see Foundation, below)
User
- It's an IAM Identity
- It's given long-term credentials
- It's good for known identities
- It has NO permission when it's created (Default Deny or Non-Explicit Deny)
- It has Permission Boundaries:
- It allows to define boundaries beyond which user permission should never go
- For more details
- It has an access type:
-
Programmatic access by key ID and a secrete access key
- It couble active or inactive
- It's viewable only once (view, download in a csv file)
- It's deleted, when it's lost. A new one is generated
-
Programmatic access by SSH public keys to authenticate access to AWS CodeCommit repositories
-
AWS Management Console access:, it uses email/password
-
- It's possible to add from 1 to 10 users at once
- ARN:
- Format: arn:partition:service:region:account:user/userName
- E.g. 1, arn:aws:iam::091943097519:user/hamid.gasmi (normal aws servers)
- E.g. 2, arn:aws-cn:iam::091943097519:user/hamid.gasmi (Beijin aws servers).
Group
- It's an IAM Identity
- It's NOT a real identity
- because it can't be identified as a Principal in a permission policy
- It's used for administrative functions:
- It's a way to attach policies to multiple users at one time
- ARN:
- Format: arn:partition:service:region:account:group/groupName
- E.g., arn:aws:iam::091943097519:group/ITDevelopers
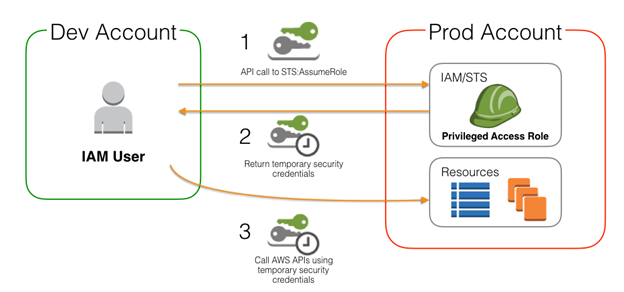
Role
- It's an IAM Identity
- It's given temporary access credentials when it's assumed (max: 36 hours)
- It allows to delegate access with defined permissions to trusted entities without having to share long-term access keys
- It's not logged in; it's assumed
- It's assumed as follow:
- An identity makes an AssumeRole API call: it requests to assume a role
- Then Security Token Service (STS) uses IAM Trust Policy to check if the identity is allowed to assume the role
- The STS uses then IAM Permission Policy attached to the role to generates a temporary access keys for the identity
- For more details
- Manage Multiple AWS Accounts with Role Switching
Policy
- It's attached to an IAM identity
- It's evaluated as follow:
- All attached policies are merged
- Explicit Deny => Explicit Allow => Implicit Deny
- Identity vs. Resource Policies:
- Identity Policy: it's attached to an IAM identity (role, user, group)
- Resource Policy: it's attached to a resource.
- Inline vs. Managed Policies:
- Inline Policy:
- It's created inside an IAM identity (role, user, group)
- It allows exceptions to be applied to identities
- Managed Policy:
- It's created independently from any IAM identity
- It's available on Policy screen of IAM console
- It allows the same policy to be reused and to impact many identities
- It's low overhead but lack flexibility
- Customer-Managed policy is flexible but requires administration
- Inline Policy:
- Policy Json Document:
- Json version: 2012-10-17;
- Statement: [{sid: "myStatementId", effect: "Allow"; "Action": ""; "Resource":""} ... ]
- Identity Based Policy:
- ARN:
- Format: arn:partition:service:region:account:policy/policyName
- E.g., arn:aws:iam::aws:policy/AmazonDynamoDBFullAccess (this is a default aws policy: see account)
Use cases
- Roles:
- To delegate access to IAM users managed within your account
- To delegate access to IAM users under a different AWS account
- To delegate access to an AWS service such as EC2
- E.g. 1: create a role to allow for example an EC2 machine to talk to an S3 server
- E.g. 2: for Break Glass style process:
- We have a support team with low right access
- In case of a crash, we may need to grant them temporary extra rights to let them fix the issues
- E.g. 3, Merging with another company
- Our current company has 2000 employees, and the bought company has also 2000 employees
- We want to quickly let the bought company employees to be able to access our AWS account while the merger is taking place
- Instead of starting the creation of 2000 new users in our company's AWS account (lot of work)
- We could create a new role and set the trust policy to the AWS account of the company that is merging with our
- So our admin overhead is only creating the role by adding the trust policy for this remote account
- E.g. 4, a company with multiple accounts:
- If a company has multiple AWS accounts. Let say 10
- Instead of creating for each employee, a user in each 10 AWS account,
- We could create them in a single account and create a role to let them connect to the other accounts
- E.g. 5, a company of more than 5000 employee and multiple accounts:
- If a company has more than 5,000 employees, it has also multiple accounts
- Roles could also help to let users of account A to have access to account B
- E.g. 6: Web Identity Federation
- Our company developed an application
- The application may have more than 5,000 users
- One of the users operations is writing to a database that is in a single account
- How could we let all these users writing on the database on their behalf?
- We can define a role by adding the trust policy for facebook users/twitter users, ...
Limits
- IAM Users # / AWS account: 5,000
- IAM MFA # / AWS account: 5,000 (Same as above: Users # / account)
- IAM MFA # / User: 1
- IAM Access keys # / User: 2 (regardless the status of the access keys: Active or Inactive)
- IAM Groups # / User: 10
- IAM Role credential expiration: 36 hours
- IAM Managed policies # / User: 10
- IAM Managed policies # / Role: 10
- IAM Inline policies # / Identity: Unlimited
- IAM Inline policies Total Size / User: 2,048 characters (white space aren't counted)
- IAM Inline policies Total Size / Group: 5,120 characters
- IAM Inline policies Total Size / Role: 10,240 characters
Best practices
- IAM Users and Groups should be given least privileges (only the required access to aws resources) Don't create (or delete) access keys for root account. Always setup an MFA on our root account.
- Authentication by secret keys is not recommended:
- If aws is hacked (ec2 instance?), secret keys will be found in
~/.awsfolder.
- If aws is hacked (ec2 instance?), secret keys will be found in
Foundation
- Principal
- It could be a person or application that can make an authenticated
- It could be also an anonymous request to perform an action on a system
- Authentication:
- It's the process of authenticating a principal against an identity
- It could be via username/password or API keys
- Identity:
- It's an object that requires authentication
- It's authorized to access a resource
- When the authentication succeeds, the principal is an Authenticated identity
- Authorization:
- It's the process of checking and allowing or denying access to a resource for an identity (Policies)
- Payment Card Industry Data Security Standard (PCI DSS):
- It's a compliance
- It ensures that a company that is dealing with credit card information (accepts, processes, stores or transmits) maintains a secure environment
Description
-
in progress
-
Session tokens from regional STS endpoints are valid in all AWS Regions.
-
If you use regional STS endpoints, no action is required.
Use cases
Limits
Best practices
- To use regional STS endpoints to reduce latency
Limits
- Organization Max Account #: 2 (Default limit)
- It could be increased:
- Support > Support Center > Create a Case > Service Limit Increase >
- Enter "Organization" in "Limit Type" field
- Select "Number of Accounts" in "Limit" field
- Enter a value in "New limit value" field
- Enter a description in "Use case description"
Best practices
Description
- It provides sizable compute capacity in the cloud
- It's a IaaS (Infrastructure as a Service) AWS Service
- It takes 2mn to obtain and boot new server instances
- It allows to quickly scale capacity both up and down as your computing requirement changes
- It has 1 or more storage volumes
- It has a Root Volume is attached to an instance during the launch process
- Additional volume could be attached to an instance after it's launched
- ARN:
- Format: arn:${Partition}:ec2:${Region}:${Account}:instance/${InstanceId}
- E.g., arn:aws:ec2::191449997525:instance/1234j8r3kdj
Architecture

Families, Types and, Sizes
- Each EC2 family is designed for a specific broad type workload
- A type determines a certain set of features
- A Size decides the level of workload a machine can cope with
- Instance name: Type + Generation number + [a] + [d] + [n] + ".[Size or Metal]"
- Type letter + Generation #: see item below (families)
- "a" it's for AMD CPUs
- "d" it's for NVMe storage +
- "n" it's for Higher speed networking +
- ".Size": "nano", "micro", "small", "medium", "large", "xlarge", "nxlarge" (n > 2) and, "large"
- ".metal" it's for bare metal instances
- E.g.,: t2.micro, t2.2xlarge, t3a.nano, m5ad.4xlarge, i3.metal, u-6tb1.metal
- General Purpose Family:
- A1: Arm-based machine
- Scale-out workloads, web servers
- T2, T3:
- It's Low-cost instance types
- It uses Credits
- It's for occasional traffic bursts (non for 24/7 workloads)
- It's for general and occasional workloads
- E.g., test Web Servers, small DBs
- M4:
- M5, M5a, M5n:
- They're for general workloads: 100% of resources at all times (24/7)
- E.g., Application Servers
- A1: Arm-based machine
- Compute Optimized Family: - C5, C5n, C4: - They provides more capable CPU - E.g., CPU intensive Apps/DBs
- Memory Optimized Family: - R5, R5a, R5n, R4: - Optimize large amounts of fast memory - E.g., Memory Intensive Apps, memory intensive DBs - X1e, X1: - Optimize large amounts of fast memory - E.g., SAP HANA, Apache Spark - High Memory (u-6tb1.metal, ..., u-24tb1.metal) - z1d: - High compute capacity and a high memory footprint - E.g., Ideal for electronic design automation, EDA - E.g., Certain relational DB workloads with high per-core licensing costs
- Storage Optimized Family: - I3, I3en: - They Deliver fast I/O - E.g., NoSQL DBs, Data Warehousing - D2: - Dense Storage - E.g., Fileservers, Data Warehousing, Hadoop - H1: - High Disk Throughput - E.g., MapReduce-based workloads, - E.g., Distributed file systems such as HDFS and MapR-FS
- Accelerated Computing Family: - P3, P2: - They deliver GPU - They're for General Purpose GPU - E.g., Machine Learning, Bitcoin Mining - G4, G3: - They deliver GPU - E.g., Video Encoding, 3D Application Streaming - F1: - It delivers FPGA - E.g., Genomics research, financial analytics, real time video processing, big data
- For more details
Virtualization
- Xen-based hypervisor: The Xen Project is a Linux Foundation Collaborative Project
- The Nitro Hypervisor that is based on core KVM technology
- Bare metal instances: With virtualization (High Memory Instance)
- For more details
Instance Metadata & User Data
- Instance Metadata:
- It's available at: http://169.254.169.254/latest/meta-data/metadataName from within the EC2 instance itself
- To get the list of all available metadata: #curl http://169.254.169.254/latest/meta-data/
- E.g., ami-id, instance-id, instance-type, local-ipv4, mac, public-ipv4, security-groups
- User Data:
- It's available at: http://169.254.169.254/latest/user-data/ from within the EC2 instance
- To get the list of all available user data: #curl http://169.254.169.254/latest/user-data/
- For more details
Bootstrap
- It's the process of providing "build" directives to an EC2 instance
- It uses user data and can take in
- Shell script-style commands: Power Shell for Windows or Bash for Linux
- Cloud-init directives
- These commands or directives are executed during the instance launch process
- User data can be used to run these commands or directives
- Actions could be involved:
- Configuring an existing application on an EC2
- Performing software installation on an EC2
- Configuring an EC2 instance
- Action that can't be involved
- Configuring resource policies
- Creating an IAM User
Storage: Elastic Block Storage (EBS) Volume
- It's a virtual hard disk in the cloud
- It's a persistent block storage volume for EC2 instances
- It's located outside of the EC2 Host hardware but in the same AZ as the EC2 instance it's attached to
- It's automatically replicated within its AZ to protect from component failure
- It supports a maximum throughput of 1,750 MiB/s per-instance
- It supports a maximum IOPS: 80,000 per instance
- General Purpose (gp2):
- It's SSD based storage (Small IO size)
- Its performance dominant attribute: IOPS
- IOPS / volume: 100 IOPS - 16,000
- IOPS Scalability: 3 IOPS / GiB
- Max Bursts IOPS / volume: 3,000 (credit based)
- Max Throughput / volume: 250 MiB/s
- Size: 1 GiB - 16 TiB
- Use case patterns: It's the default for most workloads
- Provisioned IOPS (io1):
- It's SSD based storage (Small IO size)
- Its performance dominant attribute: IOPS
- Max IOPS / volume: up to 64,000
- Max Throughput / volume: 1,000 MiB/s
- Size: 4 GiB- 16 TiB
- Use case patterns: applications that require sustained IOPS performance with small IOPS size
- Throughput Optimized (st1):
- It's HDD based storage (Large IO size)
- Its performance dominant attribute: Throughput
- Max Throughput / volume: 500 MiB/s
- Max IOPS / volume: 500
- Size: 500 GiB - 16 TiB
- It has a Low storage cost
- Use case patterns: It's used for frequently accessed, throughput-intensive workloads; it can't be a boot volume
- Cold HDD (sc1):
- It's HDD based storage (Large IO size)
- Its performance dominant attribute: Throughput
- Max Throughput / volume: 250 MiB/s
- Max IOPS / volume: 250
- Size of 500 GiB - 16 TiB
- It has the lowest storage cost
- Use case patterns: Infrequently accessed data, Cannot be a boot volume (See use case)
- It could be created at the same time as an instance is created
- It could be created from scratch (type, size, AZ, encryption, tags, ...)
- It could be created (restored) from a snapshot
- It could be created in any AZ within the snapshot region
- If a snapshot isn't encrypted, we could choose weather or not to create an encrypted volume
- If a snapshot is encrypted, we can only create an encrypted volume
- EBS-Optimized vs. non-EBS-Optimized instances:
- Legacy non-EBS-optimized instances:
- It used a shared networking path for data and storage communications
- It resulted in lower performance for storage and normal networking
- EBS-optimized mode:
- It was historically optional
- It's the default now
- It adds optimizations and dedicated communication paths for storage and traditional data networking
- It allows consistent utilization of both
- It's one required feature to support higher performance storage
- Legacy non-EBS-optimized instances:
- More details:


Storage: Instance Store (Ephemeral) Volume
- It's a non persistent storage
- It's based on Non-Volatil Memory Express NVMe
- It has the highest Throughtput and IOPS (data is accessed simultaneously because of its thousands of queues and commands in each queue)
- Its data is lost when:
- The underlying disk drive fails
- The underlying EC2 host fails
- The instance stops or terminates
- It's located within the the EC2 Host hardware
- It's included as part of its instance's usage cost
- There're EC2 instances that include:
- Instance store volumes only: to create it:
- Choose an AMI from Community AMIs > Select "Root Device Type"
- Filter: "Instance Store" > choose a machine
- A mix of Instance store volumes and EBS, to create it:
- Choose an instance which "Instance Storage (GB)" is different from "EBS Only"
- EBS volume only, to create it:
- Choose an instance which "Instance Storage (GB)" is "EBS Only"
- Instance store volumes only: to create it:
- For more details
Storage: Snapshot
- It's an Incremental backup
- At point in time T, a snapshot contains only changes made since T - 1
- The 1st snapshot contains the initial state of a disk (long)
- The following snapshots contain only the changes made since the previous snapshot
- It doesn't have the limitation of incremental backup:
- A restore could be not possible if an intermediate backup (Backup i) is lost
- To restore a backup at time "t", all backups from 1 to t will be used
- It's stored in S3:
- It doesn't have a storage limitation
- It's crash consistent:
- It's consistent to their point-in-time
- It's done transparently from the OS and any applications that are inside the instance
- It could potentially contain data in an inconsistent state: data that isn't persisted is lost
- Crash Consistent vs. Application consistent
- It could be created from a volume:
- If a volume is encrypted, the snapshot will be encrypted
- If a volume isn't encrypted, the snapshot won't be encrypted
- It could be created from another snapshot:
- It could be done by using "Copy Snapshot" feature
- It could be done from one region to a new region
- If the source snapshot isn't encrypted, the target snapshot could be encrypted
- If the source snapshot is encrypted, the target snapshot will be encrypted
- Snapshot Lifecycle Policy:
- It allows to automate snapshot creation
- It's run periodically
- It requires to be attached to an IAM role
- Automating the Amazon EBS Snapshot Lifecycle
- For more details

Amazon Machine Image (AMI)
- It's stored in S3
- It contains base OS and any "baked" components
- Instance Store-backed AMI:
- It's for instance store backed instance
- It creates an instance with an instance store backed root volume
- It's created from a template which includes bootstrapping code
- EBS-backed AMI
- It's for EBS-backed instance
- It creates an instance with an EBS backed root volume
- It references 1 or more Snapshots
- It contains Block device mapping:
- It links its snapshots to how they're mapped to the new instance
- It's used when an instance is created to map its volumes to the instance
- It contains permission: who can use it to create a new instance:
- It's by default private for the account it is created in
- It could be shared with specific AWS accounts (no encryption)
- It could be public (no encryption)
- For more details

Network: Elastic Network Interface (ENI)
- It's a logical networking component in a VPC that represents a virtual network card
- It's attached to 1 Subnet (and 1 VPC, consequently)
- It can be associated with a max of 5 Security Groups
- Each EC2 instance is created with a Primary ENI device (eth0):
- Additional ENI devices (eth1 ...) could be added to an EC2 instance, if supported
- Elastic Network Interfaces
Network: Private IP
- It's associated to an ENI device
- Primary private IP @:
- It's associated with the primary ENI device (eth0)
- It's created during the instance launch process
- It's static: it remains unchanged during instance lifetime
- It remains unchanged when an instance is in stopped state
- It remains unchanged when an stopped instance is restarted
- It's known by the instance OS: it's displayed by ifconfig command
- Secondary private IPs:
- They're assigned when supported by the instance type the ENI is attached to
- Are They known by the instance OS? Are they displayed by ipconfig
- They're within the IP range of the subnet their instance is associated with
Network: Public IP
- It could be associated to an EC2 instance
- It isn't configured on an instance itself
- A NAT is done to translate between the private and the public addresses
- See Internet Gateway in VPC description
- It's unknown by the instance OS
- It isn't displayed by ipconfig command
- It's dynamic:
- It's released when an instance is stopped
- It's released when an Elastic API is allocated to an instance (To check)
- There's not any public IP attached to a stopped instance
- It's changed when a stopped instance starts
- because the EC2 instance moves to a new physical EC2 host
Network: Elastic IP (EIP)
- It's Static
- It's Public
- It's picked from AWS Elastic IP pool (it's NOT AZ specific)
- It replaces the normal public IP when it's allocated to a public instance:
- It changes the instance public DNS name
- It remains unchanged even if the instance is stopped
- When it's disassociated from an EC2 public instance, a new public IPv4 and public DNS are released and associated with the EC2 instance
- It can be moved to a new instances
- It's charged (because they're in short supply)
Network: Private DNS
- It only works inside its internal network (VPC)
- It's based on the primary Private IP
- Format: ip-0-0-0-0.ec2.internal
- E.g., an EC2 instance which private IPv4 is 172.31.9.16, the private DNS will be ip-172-31-9-16.ec2.internal
- It remains unchanged during instance stop/start
- It's released when the instance is terminated
Network: Public DNS
- Resolution:
- It's resolved to the public address externally
- It's resolved to the the private address internally (in its VPC)
- When it's pinged inside the EC2 instance VPC, the private IP is returned
- When it's pinged outside of EC2 instance VPC (E.g., Internet), the public IP is returned
- It's based on the Public IP (Public IP or Elastic IP):
- Format: ec2-0-0-0-0.compute-1.amazonaws.com
- E.g., an EC2 instance with a public IPv4 54.164.90.18, its public DNS is: ec2-54-164-90-18.compute-1.amazonaws.com
- It's dynamic:
- It's released when an instance is stopped
- There's not any public DNS attached to a stopped instance
- It's changed when a stopped instance starts
Operations
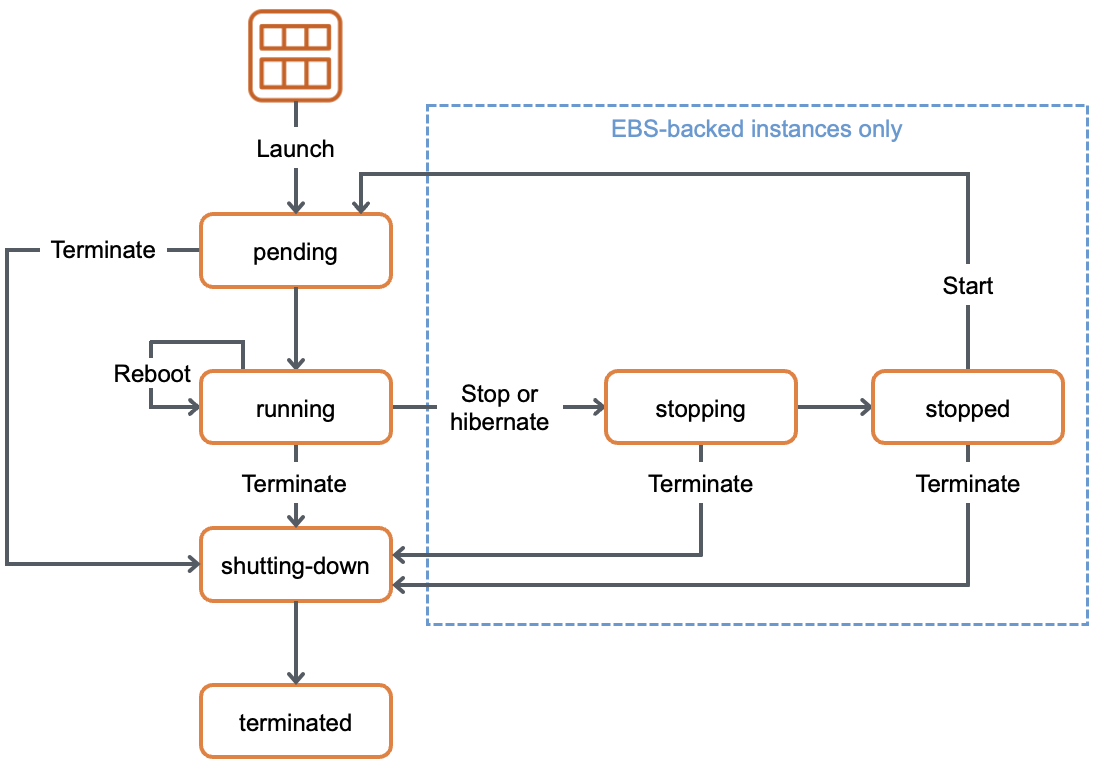
- EBS backed-instance Pending:
- A new instance is launched in a host within the selected AZ (Subnet)
- EBS and/or Instance store volumes are created and attached to the instance
- A default ENI (eth0) is attached to the instance:
- A private IP within the EC2 subnet IP range is created
- A private DSN name is associated with the instance
- A public IP is created and mapped to the instance eth0, if applicable (a public subnet + public IP sitting is enabled)
- Bootstrap script is run
- EBS backed-instance Stopping:
- It performs a normal shutdown and transition to a stopped state
- All EBS volumes are kept
- All Instance store volumes are detached from the instance (their data is lost)
- Plaintext DEK is discarded from EC2 Host hardware, if applicable
- Private DNS, IPv4 & IPv6 are unchanged
- Public DNS, IPv4 & IPv6 are released from the instance, if applicable (in case of public Subnet)
- Charges related to the instance (instance and instance store volumes) is suspended
- Charge related to EBS storage remains
- EBS backed-instance Stopped:
- Attach/detach EBS volumes
- Create an AMI
- Create a Snapshot
- Scale down/up: Change the kernel, ram disk, instance type
- EBS backed-instance Starting (from stopped):
- An instance is launched in a new the host and in the intial AZ
- EBS volumes are attached to the new instance
- Encrypted EBS volumes DEK is decrypted by KMS, if applicable
- The plaintext DEK is stored in EC2 host hardware, if applicable
- Bootstrap script is run?
- Instance store volumes are back to their initial states when the instance was 1st started (or impacted by bootstrapping)
- Private DNS, IPv4 & IPv6 are unchanged
- New Public DNS, IPv4 & IPv6 are attached to the instance, if applicable (in case of public Subnet)
- EBS backed-instance Rebooted:
- The EC2's plaintext DEK is discarded
- "Starting" action are run?
- EBS backed-instance Terminating:
- Private IPv4 & IPv6 are released from the instance
- Public IPv4 & IPv6 are released from the instance
- For more details
Performance
- Use EBS-Optimized Instances (See EBS)
- EBS Optimization:
- It's about the performance of restoring a volume from a Snapshot
- When we restore a volume from a snapshot, it doesn't immediately copy all that data to EBS
- Data is copied as It's requested
- So, we get the max performance of a the EBS volume, only when all that data has been copied across in the background
- Solution: to perform a read of every part of that volume in advance before It's moved into production
- To ensure that our restored volume always functions at peak capacity in production, we can force the immediate initialization of the entire volume using dd or fio
- For more details:
- Enhanced Networking - SR-IOV:
- It stands for Single Root I/O volume
- Opposite to the traditional network virtualization
- Which is using Multi-Root I/O Volume (MR-IOV)
- A software-based hypervisor is managing virtual controllers of virtual machines to access one physical network card
- It's slow
- SR-IOV allows virtual devices (controllers) to be implemented in hardware (virtual functions)
- In other words, it allows a single physical network card to appear as multiple physical devices
- Each instance be given one of these (fake) physical devices
- This results in faster transfer rates, lower CPU usage, and lower consistent latency
- EC2 delivers this via the Elastic Network Adapter (ENA) or Intel 82599 Virtual Function (VF) interface
- Fore more details
- Enhanced Networking - Placement Groups:
- It's a good way to increase Performance or Reliability
- Clustered Placement Group:
- Instances grouped within a single AZ
- It's good to increase performance
- It's recommended for application that need low network latency, high network throughput (or both)
- Only certain instances can be launched in to a clustered group
- Spread Placement Group:
- It's good to increase availability
- Instances are each individual placed on distinct underlying hardware (separate racks)
- It's possible to have spread placement groups inside different AZ within one region
- So if a rack does go through and fail, It's only going to affect 1 instance
- Partition Placement Group:
- It's good to increase availability for large infrastructure platforms where we want to have some visibility of where those instances are from a partition perspective
- Similar to spread placement group except there are multiple EC2 instances within a partition
- Each partition within a placement group has its own hardware (own set of racks)
- Each rack has its own network and power source
- It allows to isolate the impact of hardware failure within our application
- If needed, we can even make it automated, if we give that information to our applications itself, it can have visibility over its infrastructure placement
- Multiple EC2 instances HDFS, HBase, and Cassandra
- Dedicated Hosts:
- Physical server dedicated for our use for a given type and size (Type and Size are inputs)
- The number of instances that run on the host is fixed - depending on the type and size (see print screen below)
- It can help reduce cost by allowing us to use our existing server-bound software licenses
- It can be purchased On-Demand (hourly)
- Could be purchased as a reservation for up to 70% off On-Demand price
- Amazon EBS Volume Performance on Linux Instances
Scalability
Resilience
- An instance is located in a subnet which is located in an individual AZ
- It uses EBS storage that is also located in the instance AZ
- If its AZ fails, the instance fails
- It's NOT resilient by design across an AZ
- EBS is automatically replicated within its AZ, though
- Solution to improve EC2 resiliency:
- See Spread Placement Group
- See Partition Placement Group
- See Auto Scalling Group with 1 desired instance; 1 min instance; 1 max instance
Disaster Recovery
- See EBS Snapshot Lifecycle Policy
Security
- Instance Role:
- It's a type of IAM Role that could be assumed by EC2 instance or application
- An application that is running within EC2,
- It'sn't a valid AWS identity
- It can't therefore assume AWS Role directly
- They need to use an intermediary called instance profile:
- It's a container for the role that is associated with an EC2 instance
- It allows applications running on EC2 to assume a role and
- It allows application to access to temporary security credentials available in the instance metadata
- It's attached to an EC2 instance at launch process or after
- Its name is similar to the IAM role's one It's associated to
- It's created automatically when using the AWS console UI
- Or It's created manually when using the CLI or Cloud Formation
- EC2 AWS CLI Credential Order:
- (1) Command Line Options:
- aws [command] —profile [profile name]
- This approach uses longer term credentials stored locally on the instance
- It's NOT RECOMMENDED for production environments
- (2) Environment Variables:
- You can store values in the environment variables: AWS_ACCESS_KEY_ID, AWS_ACCESS_KEY, AWS_SESSION_TOKEN
- It's recommended for temporary use in non-production environments
- (3) AWS CLI credentials file:
- aws configure
- This command creates a credentials file
- Linux, macOS, Unix: it's stored at ~/.aws/credentials
- Windows, it's store at: C:\Users\USERNAME.aws\credentials
- It can contain the credentials for the default profile and any named profiles
- This approach uses longer term credentials stored locally on the instance
- It's NOT RECOMMENDED for producuon environments
- (4) Container Credentials:
- IAM Roles associated with AWS Elastic Container Service (ECS) Task Definitions
- Temporary credentials are available to the Task's containers
- This is recommended for ECS environments
- (5) Instance Profile Credentials
- IAM Roles associated with Amazon Elastic Compute Cloud (EC2) instances via Instance Profiles
- Temporary credentials are available to the Instance
- This is recommended for EC2 environments
- (1) Command Line Options:
- Security Group (SG):
- It acts at the instance level, not the subnet level
- See VPC description
- Network Access Control List (NACL):
- It acts at the subnet level
- See VPC description
- Snapshot Permission:
- It's by default private for the account it is created in
- It could be shared with specific AWS accounts if it's not encrypted
- It could be public if it's not encrypted
- AMI Permission:
- Same as Snapshot permission
- Encryption in Transit:
- It's done by EC2 host hardware to encrypt data in transit between an EC2 instance and its EBS storages
- Encryption At Rest:
- It's done by EC2 host hardware to encrypt/decypt EC2 volumes:
- It uses AWS KMS CMK to generates a Data Encryption Key (DEK) in each region
- AWS KMS encryption/decryption is supported by most instance types (Especially those that use the Nitro Platform)
- AWS KMS isn't encrypting neither It's decrypting EBS data
- It stores the DEK with each EC2 EBS volume
- It uses the same DEK to encrypt any EC2 volume, snapshots, AMIs
- It doesn't impact EC2 performance:
- EC2 instance and OS see plaintext data
- EC2 host hardware:
- It uses AWS KMS to decrypt EC2 DEK by using the related AWS KMS CMK
- It stores the plaintext DEK in its memory
- It uses the plaintext DEK to encrypt (decrypt) data from (into) EC2 instance to (from) an EBS volume
- It erases the plaintext DEK when the instance is stopped/rebooted
- Encryption from an OS perspective:
- It requires to use an OS level encryption available on most OS (Microsoft Windows, Linux)
- It ensures that data is encrypted from from the OS perspective
- It's possible to use OS encryption + EC2 volume encryption at rest
- Snapshot: when an encrypted EBS snapshot is copied into another region:
- A new CMK should be created in the destination region
- The new snapshot will be encrypted
- For more details:
Monitoring
- VolumeReadBytes:
- VolumeWriteOps:
- VolumeThroughputPercentage:
- Monitoring the Status of Your Volumes
Pricing
- On Demand:
- It allows to pay a fixed rate by second with a minimum of 60 seconds
- No commitment and It's the default
- Spot:
- It enables to bid whatever price we want for instance capacity
- It's exactly like the stock market: it goes up and down (The price moves around)
- When Amazon have excess capacity (there're available EC2 servers capacity. Not used)
- Amazon drops then the price of their EC2 instances to try and get people to use that spare capacity
- The maximum price indicate the highest amount the customer is willing to pay for an EC2 instance
- We get the price that we want to bid at,
- if it hits that price we have our instances
- If it goes above that price then we're going to lose our instances within 2 minutes window
- The default behavior is to automatically bid the current spot instance price
- The price fluctuates, but will never exceed the normal on-demand rates for EC2 instances
- Real examples: https://aws.amazon.com/ec2/spot/testimonials/
- Spot Fleet:
- It's a container for "capacity needs"
- We can specify pools of instances of certain types/sizes aiming for a given "capacity"
- A minimum percentage of on-demand can be set to ensure the fleet is always active
- Reserved:
- Contract terms: 1 or 3 Year Terms
- Payment Option: No Upfront, Partial Upfront, All Upfront (max cost saving)
- It could be Zonal: The capacity is then reserved in the specific zone (capacity reservation). So if there capacity constraint on a zone, those with zonal reserved instances are prioritized
- It could be also on regional: The capacity isn't reserved in a particular region's zone? (more flexibility)
- It offers a significant discount on the hourly charge for an instance
- Standard Reserved Instance:
- Up to 75% off on demand instances
- The more we pay up front and the longer the contract, the greater the discount
- Convertible Reserved Instances:
- Up to 54% off on demand capacity to change the attributes of the RI as long as the exchange results in the creation of reserved instances of equal or greater value
- So it allows you to change between your different instance families
- E.g.: We have an EC2 R5 instance that is very high ram with Ram utilization; we would like to convert it to EC2 C5 instance that has very very good CPE use
- Scheduled Reserved Instances:
- They're available to launch within the time windows we reserve (predictable: fraction of a day/week/month)
- E.g. 1: We run a school
- E.g. 2: We need to scale when everyone comes in at 9:00 on logs
- Capacity Priority: how AWS resolves capacity constraint:
- Zonal Reserved instance are guaranteed to get the reserved instances on the zone
- On Demand instances
- Spot instances
Use cases
- EC2 instance:
- Monolothic application that require a traditional OS to work
- EC2 AMI:
- AMI baking (or AMI pre-baking):
- Base installation:
- Immutable architecture:
- It's a technique where servers (EC2 here) are never modified after they're created
- E.g., if a web app. failed for unknown reasons,
- Rather than connecting to it, performing diagnostics, fixing it and hopefully getting it back into a working state,
- We could just stop it and launch a brand new one from its known working AMI and
- Optionally investigate offline the failed instance if necessary or terminate it
- Scaling and High-availability: see ASG
- EC2 storge:
- General Purpose (gp2) is the default for most workloads
- Recommended for most workloads
- System boot volumes
- Virtual desktops
- Low-latency interactive apps
- Development and test environments
- Provisioned IOPS (io1):
- Critical applications that require sustained IOPS performance, or more than 16,000 IOPS or 250 MiB/s of throughput per volume
- Large database workloads: MongoDB, Cassandra
- Applications that require sustained IOPS performance
- Throughput Optimized (st1):
- Frequently accessed,
- Throughput-intensive workloads
- Streaming workloads requiring consistent, fast throughput at a low price
- Big data,
- Data warehouses
- Log processing
- It cannot be a boot volume
- Cold HDD (sc1):
- Throughput-oriented storage for large volumes of data that is infrequently accessed
- Scenarios where the lowest storage cost is important
- It cannot be a boot volume
- General Purpose (gp2) is the default for most workloads
- EC2 ENI:
- To use for applications that are Media Access Control (MAC) address dependent
- It's possible to create it with a fixed MAC address
- It ensures that the MAC address of the EC2 instance will not change even if the instance restarts or reboots
- To use for applications that are Media Access Control (MAC) address dependent
- Princing models:
- On Demand:
- Application with short term, spiky, or unpredictable workloads that can't be interrupted
- Application being developed or tested on Amazon EC2 for the 1st time
- Spot:
- Good for stateless parts of application (servers)
- Good for workloads that can tolerate failures
- Applications that have flexible start and end times
- Applications that are only feasible at very low compute prices
- Users with urgent computing needs for large amounts of additional capacity
- Spot instances tend to be useful for dev/test workloads, or perhaps for adding extra computing power to large-scale data analytics projects
- Antipattern: spot isn't suitable for long-running workloads and require stability and can't tolerate interruptions
- Spot Fleet:
- Reserved:
- Long-running, understood, and consistent workloads
- Applications that require reserved capacity
- Users able to make upfront payments to reduce their total computing
- On Demand:
- Placement Groups:
- Spread Placement Group:
- Applications that have a small # of critical instances that should be kept separate from each other: email servers, Domain controllers, file servers
- Partition Placement Group:
- Multiple EC2 instances HDFS, HBase, and Cassandra
- Spread Placement Group:
- Dedicated Hosts:
- Regulatory requirements that may not support multi-tenant virtualization
- Licensing which doesn't support multi-tenancy or cloud deployments
- We can control instance placement
Limits
- EBS max throughput / instance: 1,750 MiB/s
- EBS max IOPS / instance: 80,000 (instance store volume if more is needed)
- Max SG # / Instance (ENI): 5
- Max instance # / Spread Placement Group: 7 (SPG is located in a single AZ)
- Max Instance # / Partition Placement Group: 7 partitions per AZ
- Encryption is NOT supported by all Instance types
- Add/remove an instance store volume after an instance is created: Not possible
Best practices
- To create application-consistent Snapshot, it's recommended:
- To stop the EC2 instance or to Freeze applications running on it
- To start the snapshot only when
- The application running on the instance are running on backup mode
- The application running on the instance are "flushed" any in memory cache to disk
- To unfreeze (release the "Freeze" operation), as soon as the snapshot starts (snapshot is consistent to its point-in-time)
- Clustered Placement Group:
- We should always try to launch all of the instances that go inside a placement group at the same time
- AWS recommends homogenous instances within cluster placement groups
- We might get a capacity issue when we ask to launch additional instances in an existing placement group

Description
- It's a Function as a Service (FaaS):
- It care of provisioning and managing the servers where to run the code
- It's an abstraction layer where AWS manages everything:
- Data centers, hardware, Assembly code/Protocols, OS, Application layer/AWS APIs, scaling
- All we need to worry about is our code
- It scales automatically: 2 requests => 2 independent functions are triggered
- It supports Event-Driven architecture:
- It runs our code in response to events: this includes schedule time
- These events could be changes to data in S3 bucket, or a DynamoDB table, etc
- These events are called triggers
- It runs in response to HTTP requests using AWS API Gateway or API calls made using the AWS SDKs
- It's stateless by design: each run is clean
- It supports different languages: Node.js, Java, Python, C#, PowerShell, Ruby
- It can consumes:
- Internet API endpoints or Other Services
- Other Lambda functions (a Lambda Function can trigger other Lambda functions)
- It could be allowed to access a VPC
- It allows access to private resources
- It's slightly slow to start
- It has an IP address
- It inherits any of the networking configuration inside the VPC (custom DNS, custom routing)
- ARN:
- Qualified ARN
- The function ARN with the version suffix
- arn:aws:lambda:aws-region:acct-id:function:my-function:$LATEST
- arn:aws:lambda:aws-region:acct-id:function:my-function:$Version$
- E.g. 1, arn:aws:lambda:aws-region:acct-id:function:helloworld:$LATEST
- E.g. 2, arn:aws:lambda:aws-region:acct-id:function:helloworld:1
- Unqualified ARN
- The function ARN without the version suffix
- arn:aws:lambda:aws-region:acct-id:function:my-function
- It can't be used to create an alias
- E.g. , arn:aws:lambda:aws-region:acct-id:function:helloworld
- Alias ARN:
- It's like a pointer to a specific Lambda function version
- It's used to access a specific version of a function
- A Lambda function can have one or more aliases
- arn:aws:lambda:aws-region:acct-id:function:my-function:my-alias
- arn:aws:lambda:aws-region:acct-id:function:helloworld:PROD
- arn:aws:lambda:aws-region:acct-id:function:helloworld:DEV
- For more details:
- Qualified ARN
Architecture

Runtime environment
- It's a temporary environment where the code is running
- It's used by Lambda function to store some files:
- E.g., Libraries when Lambda includes additional libraries
- When a lambda function is executed, it's downloaded to a fresh runtime environment
- Limit: 128 MB to 3008 MB
Triggers
- API Gateway: api application-services
- AWS IoT
- Alexa Skills Kit
- Alexa Smart Home
- Application Load Balancer
- CloudFront
- CloudWatch Events
- CloudWatch Logs
- CodeCommit
- Cognito Sync Trigge: authentication aws identity mobile-services sync
- DynamoDB
- Kinesis
- S3
- SNS
- SQS
Scalability
- It scales automatically: 2 requests => 2 independent functions are triggered
- When it's used with a VPC, we must make sure that our VPC has sufficient ENI capacity to support the scale requirements of our Lambda function:
- ENI capacity = Projected peak concurrent executions * (Memory in GB / 3 GB)
- Peak Concurrent Execution = Peak Requests per Second * Average Function Duration (in seconds)
- Scaling Lambdas inside a VPC
- VPC Configuration
- Configuring a Lambda Function to Access Resources in a VPC
- Reserved concurrency:
- Concurrency is subject to a Regional limit that is shared by all functions in a Region (see limit section)
- When a function has reserved concurrency, no other function can use that concurrency
- It ensures that it can scale to, but not exceed, a specified number of concurrent invocations
- It ensures to not lose requests due to other functions consuming all of the available concurrency
- For more details
- AWS Lambda Function Scaling
Consistency
Resilience
- It's HA
- It runs in multiple AZs to ensure that it's available to process events in case of a service interruption in a single AZ
- For more details
Disaster Recovery
Security
- Execution role:
- It's the role that Lambda assumes to access AWS services
- It gets temporary security credentials via STS
- It's basic permission is to CloudWatch
- Resource Policies:
- It allows to give give a service, resource, or account access to a Lambda function
- It could be applied on a function or to one of its versions
- It's updated either through the AWS CLI or the AWS DSK (it's NOT possible through AWS Console)
- Using Resource-based Policies for AWS Lambda
- Lambda Function Versions and Ressource Policies
Monitoring/Auditing/Debugging
- AWS X-Ray:
- It collects data about events that a function processes,
- It identifies the cause of errors in an serverless applications
- It lets trace requests to an application's API, function invocations, and downstream calls
- CloudWatch
- 1 Log Group per Lambda Function
- 1 Log Stream per period of time
Pricing
- Number of Requests:
- 1st 1 million requests are free
- $0.20 per 1 million requests
- Duration and Memory:
- It's calculated from the time our code begins executing until it returns or terminates
- It's rounded up to the nearest 100ms
- It depends on the amount of memory we allocate to our function
- We're charged $0.00001667 for every GB-second used
Use cases
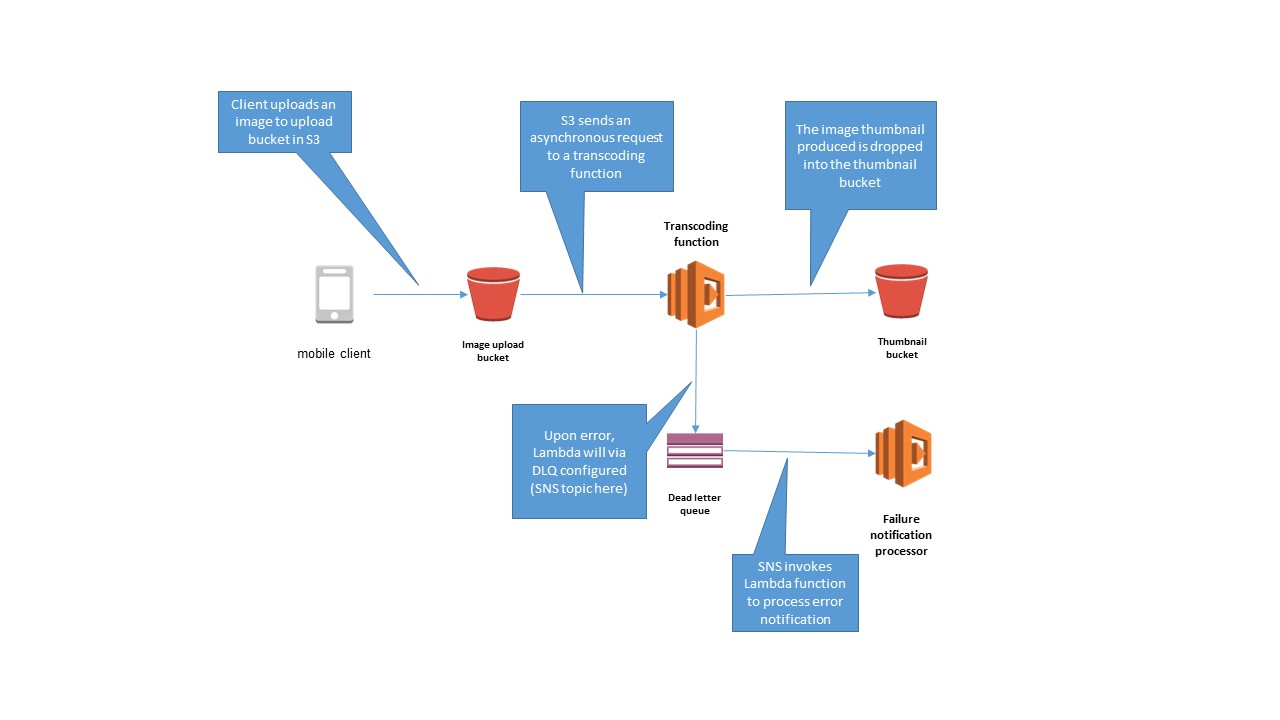
- Lambda:
- Robust Serverless Application Design with AWS Lambda Dead Letter Queues (DLQ)
- Failed events are sent to a specified SQS Queue
- SNS invokes Lambda function to process error notification
- For more details
- Robust Serverless Application Design with AWS Lambda Dead Letter Queues (DLQ)
- Alias:
- To define multiple version
- PROD
- DEV-UNIT
- DEV-ACCP
- To avoid deployment overhead when a Lambda function versions changes:
- When an Event sources is mapping configuration is used with alias ARN, no change is required when the function version changes
- When a resource policy is created with an alias ARN, no change is required when the function version changes
- To define multiple version
Limits
- Function timeout: 900 s (15 minutes)
- Function memory allocation: 128 MB to 3,008 MB, in 64 MB increments
- Max concurrent executions: 1,000 per Region shared by all functions in a Region (default limit: it can be increased)
- Max /tmp directory storage size: 512 MB
- For more details
Best practices
- If a Lambda function is configured to connect to a VPC, specify subnets in multiple AZs to ensure high availability
- Manage RDS Connections from AWS Lambda Serverless Function:
- Ensure that the maximum number of connections configured for an RDS database is less than the Lambda function Peak Concurrent Execution
- More details
- Scaling Lambdas inside a VPC:
Description
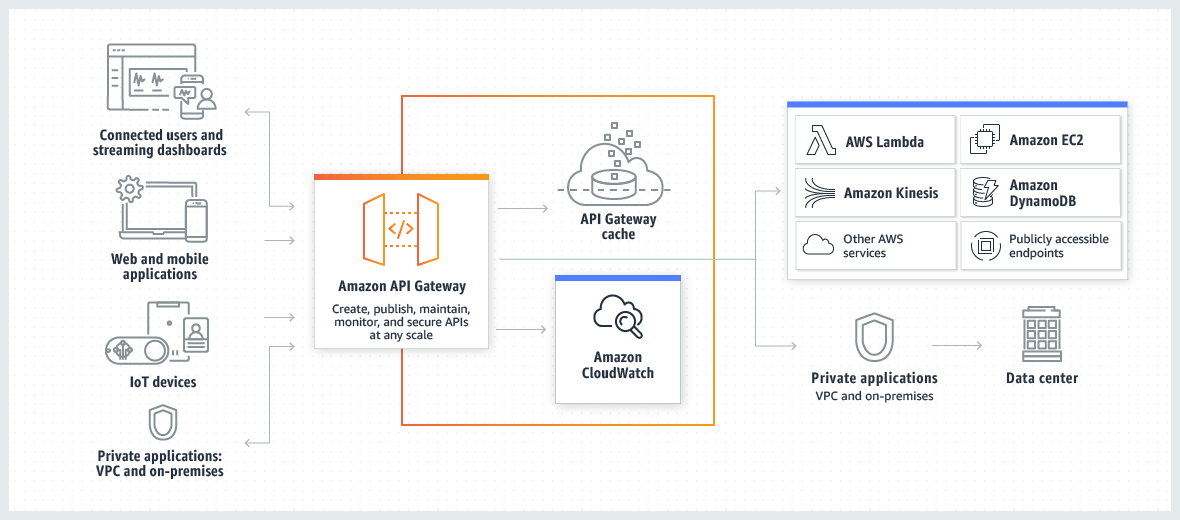
- It's a fully managed Web API service
- It supports: Rest API and WebSocket API
- Expose HTTPS endpoints to define a RESTful API
- Serverless-ly connect services like Lambda & DynamoDB
- It could access directly some services without the need for any intermediate compute
- It allows to maintain multiple versions of our API (Unit, Acceptance, Production APIs for example)
- E.g., it allows access to data stored in DynamoDB with a Lambda function
Architecture

Configuration
- Protocol: Rest API, WebSocket API
- Define an API (container):
- Define Resources and nested Resources (URL paths):
- For each Resource:
- Select supported HTTP methods
- Set security
- Choose target (EC2, Lambda, DynamoDB)
- Set request and Response transformations
Integration
- VPC Link to integrate on-premises backend solutions through DirectConnect and private VPC
Deployment
- It Uses API Gateway domain, by default
- It can use custom domain
- It supports AWS Certificate Manager: free SSL/TLS certificates
Scalability
- It scales effortlessly
- API Gateway Caching:
- It caches endpoints' responses (E.g., DynamoDB endpoint)
- It allows to reduce the # of calls made to an endpoint (reduce costs)
- It allows to improve APIs latency
- It requires to be enabled
- It requires to specify a TTL (time-to-live) period in seconds
- Enable Amazon API Gateway Caching
Consistency
Resilience
Disaster Recovery
Security
- It throttles requests to prevent attacks:
- It sets a limit on a steady-state rate and a burst of request submissions against all APIs in an account
- It's using the token bucket algorithm where the token counts for a request
- The steady-state rate:
- The number of requests per second and API Gateway can handle
- It's set to 10,000 by default
- The burst:
- It's the maximum bucket size across all APIs within an AWS account
- It's the number of concurrent request submissions that API Gateway can fulfill at any moment without returning 429 Too Many Requests error reponse
- By defaut it's set to 5,000
- It fails the limit-exceeding requests and returns 429 Too Many Requests error to the client, when request submissions exceed the steady-state rate and bust limits
- E.g. 1, If a caller sends 10,000 req. in a 1 second period evenly (10 req/ms), API Gateway processes all req. without dropping any
- E.g. 2, If a caller sends 10,000 req. in the 1st ms, API Gateway serves 5,000 of those req. and throttles the rest in the 1-second period
- E.g. 3, If a caller sends 5,000 req. in the 1st ms and then evenly spreads another 5,000 req. through the remaining 999 ms (~5 req/ms), API Gateway processes all 10,000 req. in the 1-second period without returning 429 error error responses
- E.g. 4, If a caller sends 5,000 req. in the 1 ms and waits until the 101st ms to send another 5,000 requests,
- API Gateway processes 6,000 req. and throttles the rest in the 1-second period
- This is because at the rate of 10,000 rps, API Gateway has served 1,000 requests after the first 100 ms and thus emptied the bucket by the same amount
- Of the next spike of 5,000 requests, 1,000 fill the bucket and are queued to be processed
- The other 4,000 exceed the bucket capacity and are discarded
- E.g. 5, If a caller sends 5,000 req. in the 1st ms, sends 1,000 requests at the 101st ms, and then evenly spreads another 4,000 req through the remaining 899 milliseconds,
- API Gateway processes all 10,000 requests in the 1-second period without throttling
- Token Bucket Burst
- Throttle API Requests for Better Throughput
- Amazon API Gateway Usage Plans Now Support Method Level Throttling
- It's provided by default with "Distributed Denial-of-Service" (DDoS) attacks
- IAM Roles and Policies
- Resource Policy:
- It supports AWS Certificate Manager: free SSL/TLS certificates
- CORS (Cross-Origin Resource Sharing):
- It's a way to relax same-origin policy
- It allows different AWS components to talk to each other (They've different domain names: S3, CloudFront, API Gateway domain names)
- Enable CORS for an API Gateway REST API Resource
- Lambda authorizers
- Amazon Cognito user pools
- Client-side SSL certificates
- Usage plans
- Controlling Access to API Gateway APIs
Monitoring
- Cloud-Watch to log all requests for monitoring
- Access Loggin:
- It's to log who has accessed an API and how the called accessed it
- For more details
- AWS CloudTrail:
- It provides a record of action taken by an AWS user, role, or an AWS service in API Gateway
- For more details
Pricing
- API calls # +
- Data transferred Size +
- Caching required to improve performance
Use cases
- Migration: From On-premise monolith application to Cloud Serverless application
- Traditional APIs can be migrated to API Gateway in a monolithic form
- Then gradually they can be moved to a microservices architecture
- Finally, once components have been fully broken up to micro-services, a serverless and FaaS based architecture is possible
- v1: Monolith application in AWS:
- API Gateway can access some AWS services directly using prixy mode
- E.g. EC2 instances
- v2: Microservices:
- API Gateway + Amazon Fargate + Amazon Aurora
- v3: Serverless:
- API Gateway + AWS Lambda + Amazon DynamoDB
Limits
- Throttle steady-state request rate: 10,000 rps (default)
- The burst size: 5,000 requests across all APIs within an AWS account (default)
Best practices
Foundation
- Web-API and Rest
- Web Socket protocol
- Same-Origin policy
- CORS
- SSL/TLS certificates
- Micro-Services architecture
Description
- It's a managed container engine
- It allows Docker containers to be deployed and managed within AWS environments
- An ECS container instance:
- It's an EC2 instance
- It runs the ECS Container Agent
- A Cluster
- It's a container
- It's a logical collection of ECS resources (either ECS EC2 instances or ECS Fargate infrastructure)
- A Task Definition:
- It Defines an application
- It's similar to a Dockerfile but for running containers in ECS
- It can contain multiple containers
- It's used by ECS Placement Engine to create 1 or more running copies of a given application (Tasks)
- A Container Definition:
- Inside a task definition, it defines the individual containers a task uses
- It controls the CPU and memory each container has, in addition to port mappings for the container
- A Task is a copy of an application
- It's a single running copy of any containers
- It's defined by a task definition
- It's one working copy of an application (e.g., DB and web containers)
- It's usually made of 1 or two containers that work together
- E.g., an nginx container with a php-fpm container
- We can ask ECS to start or stop a task
- A Service:
- It allows task definitions to be scaled by adding additional tasks
- It defines minimum and maximum values
- A Registry
- It's a storage for container images
- It's used to download image to create containers
- E.g., Amazon Elastic Container Registry or Dockerhub
- 2 Modes: ECS can use infrastructure clusters based on EC2 or Fargate:
- ECS with EC2 Mode:
- ECS with Fargate mode
Architecture
- ECS: Scheduling and Orchestration, Cluster Manager, Placement Engine
- EC2 Instance: OS + Docker Agent + ACS Agent
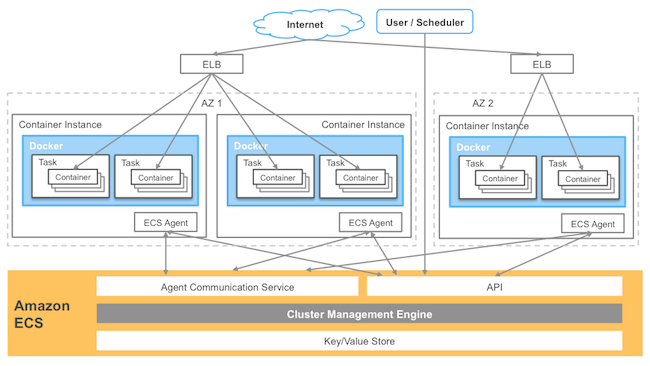

EC2 Mode
- It's NOT serverless
- It resources are: Cluster + VPC + Subnet + Auto Scaling group with a Linux/Windows AMI
- Task: EC2 Task
- The container instance is owned and managed customers
Fargate Mode
- It's serverless
- It's a managed service: AWS manages the backing infrastructure
- Its resources are: Cluster + VPC (optional) + Subnets (optional)
- Task: Fargate Task
- Tasks are auto placed: AWS Fargate manages the task execution
- There's not any EC2 instances to manage anymore but behind the scene, it uses also EC2 instances
- Each task comes with a dedicated ENI, a private IP @
- All containers of the same task can communicate with each other via localhost
- Inbound and outbound task communication goes through the ENI
- A public IP @ can be enabled as well
Scalability
- EC2 Mode by Auto Scaling Group
- There's not obvious metric to scale a cluster
- There's not integration to scale when the task placement fails because of insufficient capacity
- ECS and ASG are not aware of each other: It makes task deployments very hard during cluster scale in or rolling updates via CloudFormation
- We have to scale down without killing running tasks which is an even more significant challenge for long lived tasks
- Fargate mode: Scale out and in automatically:
- For more details
Consistency
Resilience
- EC2 Mode:
- It's not resilient by design
- It's the responsability of customer to design it HA architecture (2 or 3 AZs)
- Fargate mode:
Disaster Recovery
Security
- A Task Role gives a task (an application) the permissions to interact with other AWS resources
Monitoring
Pricing
- EC2 Mode: ECS is free of charge. We only pay for the EC2 instances
- Fargate mode: We pay for running tasks
Use cases
Limits
Best practices
Description
- It's a virtual network within AWS: It's our private data center inside AWS platform
- It can be configured to be public/private or a mixture
- It's isolated from other VPCs by default
- It can't talk to anything outside itself unless we configure it otherwise
- It's isolated from network blast radius
- It's Regional: it can't span regions
- It's highly available: It's on multiple AZs which allows a HA (Highly Available) architecture
- It can be connected to our data center and corporate networks: Hardware Virtual Private Network (VPN)
- It supports different Tenancy types: it could be:
- Dedicated tenant: it can't be changed (Locked). It's expensive
- multi-tenant (default): it still could be switched to a dedicated tenant
Architecture (UML notations)

IPv4 CIDR
- It's from /28 (16 IPs) to /16 (65,536 IPs)
- We need to plan in advance CIDR to support whatever service we will deploy in the VPC:
- We need to make sure our CIDR will support enough subnets
- We need to make sure our CIDR will let our subnets have enough IP addresses
- Some AWS services require a minimum number of IP addresses before they can deploy
- We need to plan a CIDR that allows HA architecture:
- We need to break our CIDR down based on the number of AZs we will be using and then
- We need to break down our CIDR based on the number of tiers (subnets) our VPC will have. E.g., public/private/db tiers
- We need to plan for future evolutions: additional AZs, additional tiers (subnets)
Types
- Default VPC:
- It's created by default in every region for each new AWS account (to make easy the onboarding process)
- It's required for some services:
- Historically some services failed if the default VPC didn't exist
- It was initially not something we could create, but we could delete it
- So if we delete, we could run into problems where certain services wouldn't launch,
- We needed to create a ticket to get it recreated on our behalf
- It's used as a default for most
- Its initial state is as follow:
- CIDR: default 172.31.0.0/16 (65,000 IP addresses)
- Subnet: 1 "/20" public subnet by AZ
- DHCP: Default AWS Account DHCP option set is attached
- DNS Names: Enabled
- DNS Resolution: Enabled
- Internet Gateway: Included
- Route table: Main route table routes traffic to local and Internet Gateway (see below)
- NACL: Default NACL allows all inbound and outbound traffic (see below)
- Security Group: Default SG allows all inbound traffic (see below)
- ENI: Same ENI is used by all subnets and all security group
- Custom VPC (or "Bespoke"):
- it can be designed and configured in any valid way
- Its initial state is as follow:
- CIDR: initial configuration
- Subnet: none
- DHCP: Default AWS Account DHCP option set is attached
- DNS Names: Disabled
- DNS Resolution: Enabled
- Internet Gateway: none
- Route table: Main route table routes traffic to local (see below)
- NACL: Default NACL allows all inbound and outbound traffic (see below)
- Security Group: Default SG allows all inbound traffic from itself; allows all outbound traffic (see below)
- ENI: none
DHCP Options Sets
- It stands for: Dynamic Host Configuration Protocol
- It's a configuration that sets various things that have provided to resources inside a VPC when they use DHCP
- It's a protocol that allows resources inside a network to auto configure their network card such as IP address
- It allows any instance in a VPC to point to the specified domain and DNS servers to resolve their domain names
- The default EC2 instance private DNS name is: ip-X-X-X-X.ec2.internal (Xs correspond to EC2 instance private IP digits)
- More details
DNS
- It stands for: Domain Name System
- There're 2 features related to DNS: VPC DNS hostnames and DNS Resolution
- It allows to associate a public DNS name to a VPC public instance
- The default EC2 instance public DNS name is: ec2-X-X-X-X.compute-1.amazonaws.com (Xs correspond to EC2 instance public IP digits)
- Public DNS name resolution:
- From outside EC2 instance VPC, it's resolved to the EC2 instance Public IP
- From inside EC2 instance VPC, it's resolved to the EC2 instance Private IP
Subnet
- Analogy: It's like a floor (or a component of it) in our data center
- Description: It's a part of a VPC
- Location: It's inside an AZ: subnets can't span AZs
- CIDR blocks:
- It can't be bigger than CIDR blocks of the VPC It's attached to
- It can't overlap with any CIDR blocks inside the VPC It's attached to
- It can't be created outside of the CIDR of the VPC It's attached to
- 5 Reserved IPs:
- Subnet's Network IP address: e.g., 10.0.0.0
- Subnet's Router IP address ("+1"): Example: 10.0.0.1
- Subnet's DNS IP address ("+2"): E.g., 10.0.0.2
- For VPCs with multiple CIDR blocks, the IP address of the DNS server is located in the primary CIDR
- For more details
- Subnet's Future IP address ("+3"): e.g., 10.0.0.3
- Subnet's Network Broadcast IP address ("Last"): E.g., 10.0.0.255
- For more details
- Security and Sharing:
- Share a subnet with Organizations or AWS accounts
- Resources deployed to the subnet are owned by the account that deployed them: so we can't update them
- The account we shared the subnet with can't update our subnet (what if there is a role that allow them so?)
- A subnet is private by default
- A subnet is Public if:
- If It's configured to allocate public IP
- If the VPC has an associated Internet Gateway
- If It's attached to a route table with a default route to the Internet Gateway
- Share a subnet with Organizations or AWS accounts
- Type:
- Default Subnet:
- It's a subnet that is created automatically by AWS at the same time as a default VPC
- It's public
- There is as many default subnets as AZs of the region where the default VPC is created in
- Custom Subnet: It's a subnet created by a customer in a costum VPC
- Default Subnet:
- Associations:
- Subnet & VPC:
- A subnet is attached to 1 VPC
- A VPC can have 1 or more subnets: The number of subnets depends on VPC CIDR range and Subnets CIDR ranges
- If all subnets have the same CIDR prefix, the formula would be: 2^(Subnet CIDR Prefix - VPC CIDR Prefix)
- For a VPC of /16, we could create: 1 single subnet of a /16 netmask; 2 subnets of /17; 4 subnets of /18; ... 256 subnets of /24
- Subnet & Route Table:
- A subnet must be associated with 1 and only 1 route table (main or custom)
- When a subnet is created, It's associated by default to the VPC main route table
- Subnet & NACL:
- A subnet must be associated with 1 and only 1 NACL (default or custom)
- When a subnet is created, It's associated by default to the VPC default NACL
- Subnet & VPC:
Router
- It's a virtual routing device that is in each VPC
- It controls traffic entering the VPC (Internet Gateway, Peer Connection, Virtual Private Gateway, ...)
- It control traffic leaving the subnets
- It has an interface in every subnet known as the "Subnet+1" address (is it the ENI?)
- It's fully managed by AWS
- It's highly available and scalable
Route table (RT)
- It controls what the VPC router does with subnet Outbound traffic
- It's a collection of Routes:
- They're used when traffic from a subnet arrives at the VPC router
- They contain a destination and a target
- Traffic is forwarded to the target if its destination matches the route's destination
- Default Routes (0.0.0.0/0 IPv4 and ::/0 IPv6) could be added
- A route Target can be:
- An IP @ or
- An AWS networking object: Egress-Only G., IGW, NAT G., Network Interface, Peering Connection, Transit G., Virtual Private G.,
- Location: -
- Types:
- Local Route:
- Its (Destination, Target) = (VPC CIDR, Local)
- It lets traffic be routed between subnets
- It doesn't forward traffic to any target because the VPC router can handle it
- It allows all subnets in a VPC to be able to talk to one another even if they're in different AZs
- It's included in all route tables
- It can't be deleted from its route table
- Static Route: It's added manually to a route table
- Propagated Route:
- It's added dynamically to a route table by attaching a Virtual Private Gateway (VPG) to the VPC
- We could then elect to propagate any route that it learned onto a particular route table
- It's a way that we can dynamically populate new routes that are learned by the VPG
- Certain types of AWS networking products (VPN, Direct Connect) can dynamically learn routes using BGP (Border Gateway Protocol)
- External networking products (a VPN or direct connect) that support BGP could be integrated with AWS VPC, they can dynamically generate Routes and insert them to a route table
- We don't need then to do it manually by a static route table
- Main Route table:
- It's created by default at the same time as a VPC It's attached to
- It's associated "implicitly" by default to all subnets in the VPC until they're explicitly associated to a custom one
- In a default VPC: it routes outbound traffic to local and to outside (Internet Gateway)
- In a custom VPC: It routes outbound traffic to local
- "Custom" route table:
- It could be created and customized to subnets' requirements
- It's explicitly associated with subnets
- Local Route:
- Routing Priority:
- Rule #1: Most Specific Route is always chosen:
- It's when multiple routes' destination maches with traffic destination
- A matched /32 destination route (a single IP address) will be always chosen first
- A matched /24 destination route will be chosen before a matched /16 destination route
- The default route matches with all traffic destination but will be chosen last
- Rule #2:
- Static routes take priority over the propagated routes
- When multiple routes' destination with same prefix maches with traffic destination and longest prefix match cannot be applied (Rule #1):
- Static is prefered over the dynamic ones
- A matched /24 destination static route will be always chosen first before a matched /24 destination propagated route
- More details
- Rule #1: Most Specific Route is always chosen:
- Associations:
- A RT could be associated with multiple subnets
- A subnet must be associated with 1 and only 1 route table (main or custom)
Internet Gateway (IGW)
- It can route traffic for public IPs to and from the internet
- It's created and attached to a VPC
- A VPC could be attached to 1 and only 1 Internet Gateway
- It doesn't applies public IPv4 addresses to a resource's ENI
- It provides Static NAT (Network Address Translation):
- It's the process of 1:1 translation where an internet gateway converts a private address to a public IP address
- It make the instance a true public machine
- When an Internet Gateway receives any traffic from an EC2 instance, if the EC2 has an allocated public IP:
- Then the Internet Gateway adjusts those traffic's packets (Layer 3 in OSI model)
- It replaces the EC2 private IP in the packet source IP with the EC2 associated Public IP address
- It sends then the packets through to the public Internet
- When an Internet Gateway receives any traffic from the public internet,
- It adjusts those packets as well,
- It replaces the Public IP @ in the packet source IP with the associate EC2 private IP address
- It sends then the packets to the EC2 instance through the VPC Router
Network Access Control Lists (NACL)
- It's a security feature that operates at Layer 4 of the OSI model (Transport Layer: TCP/UDP and below)
- It impacts traffic crossing the boundary of a subnet
- It doesn't impact traffic local to a subnet: Communications between 2 instances inside a subnet aren't impacted
- It acts FIRST before Security Groups: if an IP is denied, it won't reach security group
- It's stateless
- It includes Rules:
- There're 2 sets of rules: Inbound and Outbound rules
- They're explicitly allow or deny traffic based on: traffic Type (protocol), Ports (or range), Source (or Destination)
- Their Source (or Destination) could only be IP/CIDR
- Their Source (or Destination) can't be an AWS objects (NACL is Layer 4 feature)
- Each rule has a Rule #
- They're processed in number of order, "Rule #": Lowest first
- When a match is found, that action is taken and processing stops
- The "*" rule is an implicit deny: It's processed last
- Ephemeral Ports:
- When a client initiates communications with a server, it uses a well-known port #: e.g., TCP/443, ssh/22
- The response from the server is NOT always on the same port
- The client decides the ephemeral port (e.g., TCP/22000)
- This is why a NACL outbound rules need to include the ephemeral port range: 1024-65535:
- E.g, connection to a server with ssh
- NACL outbound rules should include: SSH (22) TCP (6) 22 0.0.0.0/0 ALLOW
- NACL outbound rules should include: Custom TCP Rule TCP (6) 1024 - 65535 0.0.0.0/0 ALLOW
- Location: It'sn't specific to any AZ
- Type:
- Default NACL:
- It's created by default at the same as the VPC It's attached to
- It's associated "implicitly" to all subnets as long as they're not associated explicitly to a custom NACL
- It Allows ALL traffic: Rule 100: Allow everything
- Custom NACL:
- It's created by users
- It should be associated "explicitly" to a subnet
- It blocks ALL traffic, by default: it only includes "*" rule only
- Default NACL:
- Associations:
- It could be associated with multiples subnets
- A subnet has to be associated with 1 NACL
Security Group (SG)
- It's a Software firewall that surrounds AWS products
- It a Layer 5 firewall (session layer) in OSI model
- It acts at the instance level, not the subnet level
- It could be attached/detached from an EC2 instance at anytime
- It's Stateful:
- The response to an allowed inbound (or outbound) request, will be allowed to flow out (or in), regardless of outbound (or inbound) rules
- If we send a request from our instance and It's allowed by the corresponding SG rule, its response is then allowed to flow in regardless of inbound rules
- More details (see Tracking)
- Comparison between Security Group and ACL (stateless)
- SG Rules include: Inbound and Outbound rule sets:
- Type: TCP
- Protocol: e.g., HTTP, SSH
- Port Ranges: e.g., Port 22 (SSH), Port 53 (UDP), Port 3060 (MySQL), Port 80 (http), Port 443 (https)
- Source/Destination: Since It's a Layer 5 Firewall, it supports:
- IP addresses, CIDRs (Layer 4 info)
- a Security Group (Layer 5 info)
- It can auto-reference itself in an Inbound rules' Source:
- It allows traffic from itself
- All resources in the same SG are allowed to communicate to each other
- Implicit Deny: Explicit Allow > Implicit Deny
- There is no explicit denies
- All rules are analyzed
- If a rule matches, the request is allowed
- If there is no match, the request is implicitly denied
- Types:
- Default SG in a default VPC:
- It's created at the same time as a VPC
- It allows all inbound and outbound traffic (open to the word)
- Default SG in a custom VPC:
- It's created at the same time as a VPC
- It allows all inbound traffic from the same SG
- It allows all outbound traffic
- Custom SG:
- It's created by users in a default or custom VPC
- It implicitly denies all inbound traffic: there isn't any inbound rule
- It allows all outbound traffic
- Default SG in a default VPC:
- Associations:
- SG : VPC - * : 1
- It's associated with a single VPC: it doesn't span VPC's
- A VPC could contain multiple SGs
- SG : ENI - * : 1
- It's attached to 1 ENI
- An ENI could be attached to multiple SGs
- SG : EC2 Instance : * : *
- It could be assigned to multiple instances
- It could be assigned to multiple instances in another AWS account within the same region (Peering Connection?)
- An EC2 instance could be attached to Multiple SGs
- SG : VPC - * : 1
Bastion Host (JumpBox)
- It's a host (EC2 instance) that sits at the perimeter of a VPC
- It's in a public Subnet
- it usually involves access from untrusted networks or computers
- It functions as an entry point to the VPC for trusted admins
- It allows for updates or configuration tweaks remotely while allowing the VPC to stay private and protected (private subnets)
- It's generally connected to via SSH (Linux) or RDP (Windows)
- Its goal is to reduce the surface area in which we need to harden:
- Instead to harden all private instances (we could have many of them),
- We just need to harden 1 Bastion Host
- Multifactor authentication, ID federation, and/or IP blocks
- How it works:
- Traffic is going through the Internet gateway > route tables > NACL > Security Groups > Bastion host
- Then the bastion host basically just forwards the connection through SSH/ADP to private instances
- All what we need to do is harden our bastion host as strongly as possible because It's exposed to the public
- Then, we don't have to worry about hardening our private instances in our private subnet
- For more details:
NAT Instances & NAT Gateway
- It provides Dynamic NAT (Network Address Translation):
- It's a variation of Static NAT (see Internet Gateway, above)
- It allows many private IP addresses to get outgoing internet access using a smaller number of public IPs (generally one)
- 1 public IP <-> many private IPs
- Its purpose is to let EC2 instances in private subnets to go out and download software
- Its benefits:
- Security reasons: the concept of least privilege (if a resource doesn't need internet access, than we shouldn't give them access)
- We're running out IP addresses: so we can't allocate a specific IP address for each instance
- How it works: let's have an example:
- A private EC2 instance which private IP is: 10.0.0.10
- The EC2 instance requires to update its software for a public IP: 1.3.3.7
- A NAT Gateway/Instance which Elastic IP is: 172.162.0.10
- An Internet Gateway with a Public IP is: 53.12.23.11
- Outgoing Traffic:
- The EC2 L3 layer will create a packet (Src IP, Dest IP) = (10.0.0.10, 1.3.3.7)
- The EC2 instance will send the packet to the NAT Gateway
- The NAT Gateway will update the packet Src IP by its EIP: (Src IP, Dest IP) = (172.162.0.10, 1.3.3.7)
- The NAT Gateway will then send the packet to the Internet Gateway
- The Internet Gateway will also update the packet Src IP by its Public IP: (Src IP, Dest IP) = (53.12.23.11, 1.3.3.7)
- The Internet Gateway will then send the packet to the Internet
- Ingoing Traffic:
- It's similar to the outgoing process above
- In this case, the packet Destination IP is updated
- It's updated 1st by the Internet Gateway with the NAT Gateway EIP
- Then, It's updated by the NAT Gateway with the EC2 Private IP
- NAT Gateway:
- 1 NAT Gateway inside an AZ
- It requires a Public Subnet and a Public Elastic IP
- It understands and allow session traffic (layer 5)
- It's scalable but isn't highly available by design (Redundant): if an AZ fails, all underlying NAT Gateway will fail
- It can NOT be associated with a Security Group
- Performance:
- Initially 5GB of bandwidth
- It can scale to 45GB
- For more bandwidth, we can distribute the workload by splitting our resources into multiple subnets inside an AZ
- Then specify for each subnet to go to a separate gateway
- NAT Instance:
- It's a single EC2 instance
- It could be created from a specific AMI
- it requires to Disable EC2 Source/Destination Checks:
- Each EC2 instance performs source/destination checks by default
- This means that the instance must be the source or destination of any traffic it sends or receives
- However, a NAT instance must be able to send and receive traffic when the source or destination is not itself
- Therefore, It's required tp disable source/destination checks on the NAT instance
- Disadvantage:
- It's a single point of failure
- If the instance is terminated, the route status: blackhole
- For more details:
VPC Peering
- It allows communication between 2 VPCs via a direct network route using private IP addresses
- It can span AWS accounts and even regions (see limits below)
- It's involved at layer 3 of OSI model (network)
- It uses peering connection object:
- it's a network gateway
- It's similar to Internet Gateway but used to link VPCs
- Traffic goes through RTs, NACLs and, SGs. Therefore:
- Routes are required at both sides
- NACLs and SGs can be used to control access
- SG reference is cross-account but it's not cross-region (see limits below)
- DNS resolution to private IPs can be enabled,
- It's needed in both sides
- Public DNSes will therefore be resolved to their private IP and,
- It won't be traveling over the public Internet
- Data transit:
- It's encrypted
- It uses AWS global-backbone for VPC peering cross-region: low latency and higher performance than public internet
VPC EndPoint
- It's a virtual gateway object created in a VPC
- It provides a method of connecting to public AWS services:
- Its related traffic doesn't leave AWS network
- It doesn't require a public IP address,
- It doesn't require an Internet gateway,
- It doesn't require any other resource: a NAT device, a VPN connection nor, an AWS Direct Connect connection instances
- It's horizontally scaled (bandwidth)
- There're 2 types of VPC endpoints:
- Gateway endpoint:
- It's used for S3 buckets and DynamoDB
- It's similar to Internet Gateway
- Its related traffic goes through RT: (Destination, Target) = (AWS Service Prefix Lists, Gateway Endpoint ID)
- Prefix Lists are more specific than general public internet (0.0.0.0/0)
- Therefore, Prefix Lists will override the use of the IG when they're in the same RT
- It can be restricted via policies: full access is selected by default
- It's HA (Highly available) across AZs in a region: 1 Gateway endpoint by VPC
- Interface endpoint:
- It's used for most other AWS services such as SNS, SQS
- It's an ENI with a private IP address
- It provides another unique endpoint for the selected service (different from the service public endpoint)
- It's attached to a subnet
- For HA, it should be associated with multiple AZs
- Its related traffic goes through SGs and NACLs
- It doesn't require a RT: it adds or replaces the DNS for the service
- It provides multiple DNS names: 1 per selected subnet + 1 general DNS name (not specific for an AZ)
- It replaces the default service public DNS when "Private DNS Names" feature is enabled
- For more details about AWS Services endpoint
- Gateway endpoint:
- Limits:
- Gateway endpoints are used via route
- For more details about Interface endpoints
IPv6
- VPC IPv6:
- It's currently opt-in (disabled by default)
- It's enabled from VPC -> Edit CIDR feature
- It's a /56 CIDR allocated from AWS pool
- It can't be adjusted
- Subnet IPv6:
- It's a /64 CIDR
- It can be chosen from the VPC /56 range
- It's enabled from subnet -> Edit CIDR feature
- It's publicly routable:
- There is no concept of Private IPv6 address
- There is no concept of Elastic IPs with IPv6
- IG doesn't do static NATs for IPv6
- IG is routing from VPC to the public Internet
- RT can contain IPv6 routes
- IPv6 default route is: "::/0"
- It should also be configured in NACL and SG
- To use it:
- Enable it for VPC
- Enable it for a subnet
- Add IPv6 routes in subnet's RT (particularly ::/0)
- Make sure corresponding NACL allows traffic with IPv6
- Make sure corresponding SGs allow traffic with IPv6
- DHCP6:
- It let resources of subnets with IPv6 range configure a public IPv6 address
- The OS is configured with the public IPv6
- DNS Name:
- It'sn't allocated to IPv6 addresses
Egress-Only Gateway
- It provides instances with outgoing access to the public internet using IPv6 and,
- It prevents them from being accessed from the internet (or outside VPC?)
- It allows outbound and inbound response traffic
- Analogy:
- It's similar to NAT Gateway but
- it doesn't provide Dynamic NAT since It'sn't relevent with IPv6
- NAT Gateway doesn't support IPv6
Use cases
- NACL:
- Because NACL are stateless and ephemeral ports are thousands, to manage the overhead of NACL rules is very high:
- A single Communication involves 4 individual sets of rules
- We should think to "allow" traffic for every "ephemeral" ports on Client Inbound and Outbound rules and,
- We should think to "allow" traffic for every "ephemeral" ports on Destination Inbound and Outbound rules as well
- They tend not to be used all that much generally in production usage (Security Groups are preferred)
- They're used when we have an explicit deny that we would like to add (E.g., an IP @ we were attacked from)
- Because NACL are stateless and ephemeral ports are thousands, to manage the overhead of NACL rules is very high:
- NAT Instance:
- There is only one use case
- When cost saving is absolutely required and, a NAT and bastion hosts are needed
- We could then combine bastion host and NAT in the same machine
- VPC Peering:
- To make a service that is running in a single VPC accessible to other VPCs
- To connect our VPC to a vendor VPC or a partner VPC to access an application
- To give access to our VPCs for security audit
- We have a requirement to split an application up into multiple isolated network to limit the blast raduis in the event of network based attacks
- VPC EndPoint:
- An entire VPC is private without an Internet Gateway
- A specific private instance needs to access public services
- To access resources restricted to specific VPCs or endpoints (private S3 buckets)
Limits
- VPCs # / region:
- Default: 5
- Non default: 100
- More: Support ticket
- VPC max/min netmask: /16 ... /28
- VPC Peering:
- VPC CIDR blocks can't overlap
- Transitive Peering is NOT Possible:
- A VPC can't talk to another VPC through a 3rd VPC
- A Direct peering is required between 2 VPCs so that they can talk to each other
- Cross-Region:
- An SG can't be referenced from another region
- IPv6 support isn't available cross-region
- Subnet max/min netmask: /16 ... /28
- Subnets # / VPC: 200
- NAT Gateway
- NAT Bandwidth: 5 Gbps - 45 Gbps (For more, distribute the workload by splitting resources into multiple subnets, and creating a NAT gateway in each subnet)
- NAT Gateway # / AZ: 5
- It can be associated with a SG
- It can NOT be used by resources outside of its VPC:
- We can't route traffic to a NAT gateway through a VPC peering connection, a Site-to-Site VPN connection, or AWS Direct Connect
- A NAT gateway cannot be used by resources on the other side of these connections
- It can't be accessed by a ClassicLink connection associated with your VPC
- IPv4 CIDR blocks / VPC: 5
- IPv6 CIDR blocks / VPC: 1
- IPv6:
- It'sn't currently supported across every AWS product
- It'sn't currently supported with every feature
- It'sn't currently supported by VPNs, customer gateways, and VPC endpoints
- Gateway Endpoint:
- It's supported within the same Region only: we cannot create an endpoint between a VPC and a service in a different Region
- It can't be used to extend connections out of a VPC:
- It can't be used by resources outside of the VPC
- E.g., resources on the other side of a VPN connection, VPC peering connection, Transit Gateway, DX connection, ClassicLink connection in our VPC cannot use the endpoint to communicate with resources in the endpoint service
- For more details
Best practices
- CIDR:
- To plan for a VPC in advance even though
- To Expand existing VPC by adding Secondary CIDR instead of creating a brand new one
- To ensure that VPCs we work with don't overlap CIDR blocks:
- It will make things a lot easier further down
- Lots of networking features don't like the same CIDR block
- E.g., Our corporate network VPCs, any other VPC we work with, VPCs of any partners and vendors that we interact with
- DNS: Always enable VPC DNS hostnames and, VPC DNS resolution
- RT:
- It's recommended not to update the main route table
- It's particularly recommended not to add the route to the Internet Gateway in the main route table:
- Since by default, all VPC's Subnets are associated "implicitly" to the main route table
- All existing and future subnets could be public by default (if Public IP is enabled)
- NACLs:
- Inbound and Outbound Rules # should use an increment of 100:
- 100 for the 1st IPv4 rule, 101 for the 1st IPv6 rule
- 200 for the 2nd IPv4 rule, 201 for the 2nd IPv6 rule
- Ensure that you place the DENY rules earlier in the table than the ALLOW rules that open the wide range of ephemeral ports
- Inbound and Outbound Rules # should use an increment of 100:
- Bastion Host - JumpBox:
- It must be kept updated, its security hardened and, audited regularly
- Multifactor authentication, ID federation, and/or IP blocks
- It's recommended to add tags to be able to differentiate from other regular EC2 instances
- Create a specific SG for bastion hosts:
- Since bastion hosts require specific rules, we could make them in a unique SG
- The SG could then be shared with bastion hosts only
- It will allow to reduce bastion hosts creation overhead
- Use SSH forwarding: it allows to connect to the private instance through the bastion host without leaving SSH keys within the bastion host
- NAT Gateway:
- For an HA architecture
- We need 1 NAT Gateway by AZ
- We need a Single Route table for each AZ (each NAT Gateway)
- Each NAT Gateway should be then associates with all private subnets of the related AZ
- Interface Endpoints:
- Enable Private DNS Name
- It allows to avoid modifying application code
- The service public endpoint will be resolved to the endpoint ENI private IP @
- Enable Private DNS Name
- Create conventions:
- Subnet Name: sn-[public/private]-[AZ]: sn-public-a; sn-private-a
- Peering Connection name: pc-[Requester VPC name]-[Accepter VPC name]. E.g., pc-VPC1-VPC2
- Subnet range:
- In some cases, humans do need to understand the networking structure that we use inside a VPC
- We could match a subnet's CIDR to its AZ and its application tear
- E.g., for a VPC 10.0.0.0/16 with Subnets: /24 + 2 AZs + 3 tiers:
- AZ1: (Tier 1, 10.0.11.0); (Tier 2: 10.0.21.0); (Tier 3: 10.0.31.0)
- AZ2: (Tier 1, 10.0.12.0); (Tier 2: 10.0.22.0); (Tier 3: 10.0.32.0)
Description
- It's AWS Domain Registrar and DNS service
Domain Registrar
- It checks a domain is available: It's done against the database of the TLD or the subdomain operator
- It allows to register a domain:
- It contacts then the TLD to add a record into the corresponding zone (the registration is "Pending")
- It publishes All or Some Registrant Contact details in the public WHOIS database
- It stores Registrant Contact, Administrative Contact and, Technical Contact details in the domain record
- It allow to renew the domain automatically
- It allows to host a domain: It gives the rights to specify name servers (NS) to be authoritative for our domains
- It allows to register and host a domain, register only or host only a domain
- It allows to add records (www, ftp, mail…) into the name servers (NS) zone files
DNS Service
- Hosted Zone:
- It corresponds to a domain name
- It's a collection of records (see below)
- It supports public and private hosted zones:
- Public Zone:
- It's created by default when a domain is registered/transfered with Route 53
- It's also created when we create a domain manually (how could it be done?)
- It has the same name as the domain it relates to: It's FQDN (Fully Qualified Domain Name)
- It's accessible globally since the TLD zone delegates to its name servers
- It's accessible either from internet-based DNS clients or from within any AWS VPC
- It has an NS record that is given to the corresponding domain operator (Route 53 becomes then "Authoritative")
- Private Zone:
- It's created manually and associated with one or more VPCs
- It's accessible from VPCs It's associated with
- It needs "enableDnsHostname" and "enbaleDnsSupport" enabled on a VPC
- Not all Route 53 features supported (limits on health checks)
- Split-view:
- It allows to have 2 different websites with the same domain name:
- One website is available on the public Internet and
- a different website available on a private network
- How it works:
- Create a public zone for a domain name
- Create a private zone with the same zone name and with specific VPCs
- The private zone will then override the public zone within the specificied VPCs
- It the private zone doesn't have any record, the private zone doesn't then override the public zone
- Use cases:
- We have 2 versions of an application. The internal version may contain additional information or features for administration
- We have a new version of an applicaiton. We would like to test it without distrupting the public version
- It allows to have 2 different websites with the same domain name:
- Zone's Records:
- NS Record has the server names that are authoritative for a subdomain
- SOA Record (Start of Authority Records)
- A Record provodes an IPv4 address for a given host (www)
- AAAA record provodes an IPv6 address for a given host (www)
- CNAME record (Canonical Name):
- It allows to resolve one domain name to another
- It cannot be used at the APEX (top) of a domain
- E.g. 1, add Cnames for mobile.example.com that is pointing m.example.com server
- It could reference an original record (A or AAAA) instead of an explicit IP address
- E.g. 2, add a CNames (www, ftp, vpn) for example.com:
- www.example.com; ftp.example.com; vpn.example.com
- All CNames could reference the original A record (example.com)
- If the original record IP address changes, there's no impact on CName records
- We can reference names that are outside our domain with FQDN (the last . is required "anotherexample.com.")
- Alias record type:
- It's a Route 53 specific feature
- It's an extension of CNames
- It can be used at the APEX of a domain (for naked domain names)
- It can refer to AWS logical services (LBs, S3 buckets)
- It allows to specify a hostname in our DNS records which then resolve to the correct A/AAAA records at the time of a request
- AWS doesn't charge for alias records against AWS resources
- It's recommended by AWS
- MX record:
- It's quired whenever a server is attempting to send an email to a given domain
- It provides the email servers for a given domain
- Eeach server within MX record has a priority value
- The lower priority value is preferred
- TXT record:
- It's used to store plain text inside a domain
- It's often used to verify domain ownership:
- If we are adding a domain to Gmail or Office 365,
- They'll probably ask to add a text record to the domain with some random text that they're aware of
- They can then perform a resolution on that text record against the text of that "TXT record"
- If it matches, it guarantees that we own that domain
- It can be used in spam filtering
- VPC DNS Resolver ?
Health Check
- It can be created within Route 53
- It's used to influence Route 53 routing decisions:
- Records can be linked to health checks
- If the check is unhealthy, the record isn't used
- It can be used to do failover and other routing architecture (see Routing policies, below)
- Its status are: Unknown (1st status), Health, Unhealthy
- Endpoint Check:
- It checks the physical health of an endpoint
- It species an endpoint by IP address or a domain name (usefull when we have a domain name which IP address changes often)
- It's impacted by resources security features (SG, NACL)
- It occurs every 30 seconds (default) or every 10s
- It has a failure threshold: if x checks are unhealthy, then the healthcheck is unhealthy
- E.g., If the check occurs every 30s and the failure threshold is 3, then Route 53 will be able react for a fealure only after 90s (long time)
- Each endpoint check corresponds actually to multiple healthchecks that are done by Health Checkers (a global health check system)
- Endpoint Check aggregates the data from the health checkers and determines whether the endpoint is healthy:
- If more than 18% of health checkers report that an endpoint is healthy, Route 53 considers it healthy
- If 18% of health checkers or fewer report that an endpoint is healthy, Route 53 considers it unhealthy
- Health Checkers evaluation is based on the Response time which depends on the type of health check:
- For HTTP/S healthchecks: 4s to establish a TCP connection with the endpoint + an HTTP status code of 2xx or 3xx within 2 seconds after connecting
- For a TCP healthchecks: 10s to establish a TCP connection with the endpoint
- For HTTP/S with string matching: All the checks as with HTTP/S but the body is checked for a string match
- Endpoint Check other Options are:
- TCP options includes
- IP @ (for TCP and HTTP/S)
- Hostname (for HTTP/S): it's useful if we have multiple websites under the same IP (the same server); we could create then 1 healthcheck/website
- Port (for TCP and HTTP/S):
- Path (for HTTP/S)
- Latency graphs: ?
- Invert health check status:
- Health checker regions:
- More details
- Calculated healthcheck:
- It monitors the health of multiple healthchecks
- We could select how many sub-healthcheck should be healthy to make the calculated health check healthy
- Usefull particularly when we have got lots of different services/components of our system
- We created an individual healthcheck for each of them
- It summarizes the health of all these individual components
- E.g., We have a front-end tier, a logic tier and, a database tier,
- Each tier has a healthcheck
- Whe can then create a calculated healthcheck that will check the status of these individual checks to report the whole system healthy
- CloudWatch alrams health checks:
- They monitor CloudWatch alarms
- e.g., we may want to consider something unhealthy if a DynamoDB table is experiencing performance issues
Simple Routing Policy
- It's a single record with multiple values a hosted zone (Error for a new 2nd record with the same type and domain name)
- It can contain multiple values (IP addresses) or
- It can also contain a single AWS resource as an alias type record (1 LB, 1 S3 Bucket Endpoint, 1 VPC Endpoint...)
- It returns to a DNS query all the values in a random order (the client can select the appropriate one)
- It doesn't support Health check isn't possible
- Pros:
- Simple as a starting point for our DNS architecture: Good when we're not aware of how our traffic patterns are
- Simple with a somewhat even spread of requests (TTL is very important here to avoid the issue below)
- Cons:
- No performance control (It'sn't a LB architecture): if a big organization caches an IP @, all its users will query a single IP
- No healthcheck: if a resource behind an IP @ fail, it will continue sending requests to it
Failover Routing Policy
- It enhances "Simple Routing" policy
- It's a single Primary record + a single Secondary record with the same name
- Its records (primary and secondary):
- They can contain multiple values (IP addresses) or a single AWS resource as an alias type record
- They support healthcheck (calculated healthchecks if primary record contains multiple values?)
- It resolves queries to the primary unless It's unhealthy
- It resolves queries to the secondary if the primary is unhealthy
- Its secondary records cold provide emergency resources during failures:
- E.g., an S3 static website that presents a maintenance page
- with usefull information: Failure status, contact details
- It can be conbined with other routing policies to allow multiple primary and secondary records
Multivalue Answer Routing Policy
- It's multiple records with the same name
- Its records can contain 1 value only (IP address or AWS product)
- It supports healthcheck
- It responds to DNS queries with up to 8 random healthy records
Weighted Routing Policy
- It's multiple records with the same name
- Its records have a weight and a unique Set ID
- It allows to split traffic based on different weights assigned
- It can be used to control the amount of traffic that reaches specific resources:
- To test new software/products/ AB Testing
- When resources are being added or removed from a configuration that doesn't use an ELB
- No performance or loading control (It'sn't a LB architecture)
- It could be attached with a health check to a record: It can then omit the record as long as the associated EC2 instance is unhealthy
- Its weight is a value:
- It'sn't a %
- If we add to address with the following weights: 20 and 30 => the corresponding % will be: 40% and 60%
- E.g., we can set 10% of our traffic to go to US-EAST-1 and 90% to go to EU-WEST-1
Latency-based Routing Policy
- It's multiple records with the same name: they're considered part of the same latency-based set (if the name is different, they're not)
- Its records are allocated to a unique region and have a unique Set ID
- It consults a latency database (DNS Resolver location - Policy Region - Latency) when a request occurs from a resolver server
- It returns the record set with the lowest network latency to the resolver server (end-user)
- Its latency calculation is NOT made between customer's resolver server location and our resource location!
- It'sn't related to geography but to network condition instead
- Its records can be attach with a health check
Geolocation Routing Policy
- It's multiple records with the same name
- It lets to choose the resources that server traffic based on the geographic region from which queries originate
- Its records are configured for:
- a Country: the lowest abstration level
- a Continent:
- Default: the highest abstration level (while planete)
- Its IP matching process is:
- A record set is used for queries originated from its region
- When multiple regions match a query region, the record set with the lowest abstraction level is returned
- If this process fails, the default record set is returned (if it exists)
- If no record set is configured for the originating query region, the default record set is returned (if it exists)
- If matching record set health check fails, It's then excluded in this process
- If there is no record matching and there is no default record, then "No answer" is returned
- E.g. 1, a website like Netflix: its content is based on their customer' country
- E.g. 2, we might want all queries from Europe (/US) to be routed to a fleet of EC2 instances:
- They're specifically configured for our European (US) customers
- They may have the local language (English, Spanish, Chinese) of our European (US) customers
- They may display all prices in Euros ($)
- We could set US record set as a default, canadien customers will be then redirected to the US EC2 fleet
Geoproximity Routing Policy (Traffic Flow Only)
- To use Geoproximity routing, It's required to use Route 53 traffic flow
- Traffic flow is: ?
- Geoproximity Routing lets Route 53 routes traffic to our resources based on the geographic location of our users and our resources
- We can also optionally choose to route more or less traffic to a given resource by specifying a value, known as a bias
- A bias expands or shrinks the size of the geographic region from which traffic is routed to a resource
Monitoring
- Endpoint Check (see above)
- CloudWatch alrams health checks (see above)
- Calculated healthcheck (see above)
Pricing
Use cases
- Split-view:
- We have 2 versions of an application. The internal version may contain additional information or features for administration
- We have a new version of an applicaiton. We would like to test it without distrupting the public version
Limits
Best practices
- Conventions:
- Healthcheck name: same as the corresponding domain name
- Failover Routing recommendation: TTL <= 60 to let client respond quickly to changes in health status
Description
- It's a secure, durable, highly scalable objects storage
- Objects are organized into Buckets
- An object is:
- Object key: object name
- Value: object data
- Version ID: It's possible to do version control
- Object Metadata: expires, content-type, cache
- Subresources:
- ACLs: see permission below
- Torrents:
- A folder could be created within a bucket:
- It's not an actual object
- It's added as a prefix into the underlying objects' key
- S3 FAQ
Bucket Name, URL, ARN
- It's a Universal Namespace:
- It must be unique globally
- It must use DNS Name-like rules:
- It can't have capital letters
- It can't have a "-"
- It can't be IP address-like
- It must be from 3 to 63 characters long
- URL:
- Virtual Hosted Style Access:
- Path-Style Access:
- Format: http://s3.*Region.*amazonaws.com/bucket-name/key-name (the region is optional)
- It will be deprecated from september 2020
- E.g. 1, https://s3.us-east-1.amazonaws.com/selfservedweb/Web_Scalability_for_StartupEngineers.pdf
- E.g. 2, https://s3.amazonaws.com/selfservedweb/Web_Scalability_for_StartupEngineers.pdf
- For more details
- ARN:
- Format: arn:partition:s3::bucketname:
- E.g., arn:aws:s3:::selfservedweb
Uploads
- It's done using the S3 console, the CLI, or APIs
- It uses a single operation (Single PUT upload) or multipart upload
- A successfull upload will return an HTTP 200 code
- Single PUT Upload:
- An object is uploaded in a single stream of data
- Limit of 5 GB/PUT
- It can cause performance issues
- If the upload falls the whole upload falls
- Multipart Upload:
- An object is broken up into parts (up to 10,000)
- All parts are upluded in parallel
- All parts are merged once they're all uploaded
- Each part is 5MB to 5GB, except the last part which can be less
- It's faster
- If an individual part upload falls,
- It won't impact the whole upload
- It will be retried individually
- It's recommended for anything over 100 MB
- It's required for anything beyond 5 GB
- It's not possible via the console:
- CLI: aws s3 cp myFile S3://MyBucket/
- API?
Static Websites
- A bucket can be configured to host a website:
- Content should be uploaded to the bucket:
- "Static web hosting" feature should be enabled
- It can host many types of content: HTML, CSS, JavaScript, Media (audio, movies and, images)
- It can host front-end code for serverless application or
- It can be an offload location for static content:
- Instead storing media on a web server,
- We could store it on S3 and
- Direct the Web server to point S3
- It can host custom domains:
- Create a bucket with an acual DNS name
- Create a record in Route 53 that points at the bucket (Alias)
- It can redirect requests:
- We can specify a full set of redirection rules
- It can redirect requests for an object to another object in the same bucket or to an external URL
- CloudFront can also be added as a CDN for global users
- SSL can be added for custom domains
Cross-Origin Resource Sharing (CORS)
- It's a way a web server can relax the same-origin policy
- It allows a web server running in one domain to reference resources in another
- This particularly helpful: each S3 bucket (and even AWS product) has its own domain name
- For more details
- Use case Scenarios
Versioning
- It allows multiple versions of an object to exist in an S3 bucket
- It's disabled by default
- It requires to be enabled at a bucket level
- Once it's enabled,
- It can never switched off (only suspended)
- It add a new feature on the console to Hide or Show the older versions
- Any modification operation on an object,
- It generates a new version of the object with a new Version-ID
- It hides the older version
- A delete operation on an object doesn't delete it:
- It generates a new version of the object marked as deleted ("Delete" marker)
- It can be undone: if the "Delete" marked version is deleted
- Older versions of an object are still accessible by using the object name and a version ID
- To delete physically an object, all versions must be selected and deleted
- AWS accounts are billed for all versions:
- Be careful, the bucked size could get very big
- Previous versions aren't deleted!
- MFA Delete:
- It's a feature designed to prevent accidental deletion of objects
- Once enabled, a one-time password is required:
- To delete an object version or
- To change the versioning state of a bucket
- Versioning is required
- For more details:
Cross-Region Replication (CRR)
- It's an S3 feature that can be enabled on S3 buckets
- It allows a one-way replication of data from a source bucket to a destination bucket in another region
- It's a set of rules:
- They could be applied on the entire source bucket objects
- They could also be applied on a part of source bucket objects (based on prefixes and/or tags)
- They could be overlapping
- They've a priority value to resolve conflicts that occur when an object is eligible for replication under multiple rules
- A higher value indicates a higher priority
- It requires:
- Versionning feature to be enabled on both buckets (src. and dest.)
- to allocate an IAM role with permissions to let S3 replicates objects
- By default, replicated objects keep their:
- Storage class
- Object name (key)
- Owner
- Object permission
- Override is possible for:
- Storage class,
- Storage ownership (select a different aws account)
- Object permission at the destination bucket
- Exclusion, the following are excluded from Replication:
- System actions (lifecycle events aren't replicated)
- SSE-C encrypted objects - only SSE-S3 an KMS (if enabled) encrypted objects are supported
- Any existing objects from before replication is enabled (replication isn't retroactive)
- "Mark Delete" objects: it doesn't replicat deletions
- The replication is using SSL protocol?
Presigned URL
- It's created by an identity to let someone else (a bearer) access to a private object on a temporary basis
- Its creator is an IAM Identity: User, Group, Role
- The bearer of the URL gets the same level of authorization as the creator
- It's encoded with authentication built in
- It has an expiry time: 7 days maximum
- When It's used,
- AWS verifies the creator's access to the object
- AWS doesn't verifies the bearer access to the object
- It can be created even on objects the creator doesn't have access to
- The bearer lose access when:
- The presigned URL has expired (7 days max)
- The creator permissions have changed
- The URL was created using a role and its temporary credentials have expired (36-hour max)
Storage Tier/Class
- It influences for objects in S3:
- The durability (Fault Tolerance?):
- It refers to long-term objects protection
- How it can operate through a failure with no user impact
- How well objects are protected from loss or any compromises
- It's concerned with object redundancy
- The availability:
- It refers to system uptime
- How quick a system can recover in the event of a failure
- The storage system is operational and can deliver data upon request
- The "1st byte latency"
- It's the amount of time that passes between:
- The time a request to get an object is made and
- The time its 1st byte is received
- The cost:
- Storage Size fee: per GB used with a Minimum Capacity charge
- Storage Duration fee: with a Minumum Storage duration charge
- Data Transfer fee (Retrieval Fee) per GB
- Requests type: PUT, COPY, POST, or LIST Requests / GET, SELECT
- Requests type #: nbr of requests by type
- Minimu capacity doesn't mean that we can't upload a file less than the minimum size
- Minimum duration doesn't mean neither that we can't delete an object before the minimum duration
- They only mean that we'll be billed for a minimum size and a minimum period of time
- The durability (Fault Tolerance?):
- It's setup at object level
- Initially: during the upload process or
- Once the object is loaded, it can be Changed manually or by Lifecycle policies
- S3 Standard:
- It's the default class
- Use cases:
- All purpose storage
- We don't have any specific requirements or
- We don't know the usage of the object
- S3 IA (Infrequently Access):
- Same as S3 Standard (Designed for durability, Designed for availability, +3 AZ Replication and, 1st byte latency - rapid access)
- but it's for data that is accessed infrequently
- Storage Size fee: Lower than S3 standard
- But we're charged:
- A retrieval fee
- Minimum capacity charge per object: billet at least for 128K / object
- Minimum duration charge per object: billed at least for 30 days / object
- S3 One-Zone - IA (Infrequently Access):
- Lower-cost option accessed data
- Use cases:
- For Cross Region Replications:
- The data is stored somewhere else
- A replication isn't the main location,
- So the "standard" durability isn't needed here
- Output of data processes:
- If the data is lost, the process can be run again and the output can be reproduced
- This's particularly true, when the process is quick
- What if the process to get the output data is long?
- Non important data (non mission critical data)
- For Cross Region Replications:
- Use cases: ?
- S3 RRS - Reduced Redundancy Storage
- It's obsolete (not recommended)
- Durability Design: 4 nines (99.99%)
- Durability SLA: ?
- Availability Design: 4 nines (99.99%)
- Availability SLA: N/A
- AZ: >= 3
- Concurrent facility fault tolerance: 1
- "1st byte latency" SLA: milliseconds
- Use cases: ?
- S3 - Glacier:
- It's a storage class for data archiving
- It's an archival storage on a file system or disk back ups in a traditional backup system
- We're charged:
- A retrieval fee
- Bigger Minimum capacity charge per object
- longer Minimum duration charge per object
- Use cases: file system or disk back ups
- S3 - Glacier Deep Archive:
- It's for long-term archival
- It's like tape storage
- It's S3 lowest-cost storage class
- We're charged:
- A retrieval fee
- Biggest Minimum capacity charge per object
- longest Minimum duration charge per object
- Use cases: Cold backups
- S3 - Intelligent Tiering:
- It moves objects automatically between 2 tiers:
- An Object that isn't accessed for 30 days is moved to IA tier
- If it's accessed, it's then moved back to frequent access tier
- Cost:
- No cost when data is moved from a tier to another one
- Automation and Monitoring fee: monthly
- Use cases:
- We don't known access patterns or it's unpredictable
- We don't want admin overhead
- It moves objects automatically between 2 tiers:
- For more details:
- Data Availability vs. Durability
- [Classes]
- In AWS Certification exams:
- It seems like answers should be based on ‘designed for’ durability/availability (unless the question specifies otherwise)

Lifecycle Management
- It's done at Bucket level
- It's done by creating Life Cycle rules
- Rules could be applied on objects with specific tags
- Transition rules:
- They're to automate moving objects from one tier to another
- They could be applied on current version and/or older ones
- Expiration rules:
- They're to automate expiring of objects that are no longer required
- They could be applied on current version and/or older ones
- Current versions could be expired
- Previous versions could be permanently deleted (physically)
- Clean up expired object delete markers (You cannot enable clean up expired object delete markers if you enable Expiration)
- Clean up incomplete multipart uploads
- Supported transitions:
- See diagram below

Scalability
- CRR minimizes latency for global applications by creating Performance Replicas
- Use CloudFront with S3 to distribute content with low latency and a high data transfer rate
- Use ElastiCache with S3 for Frequently Accessed Content
- Use S3 Transfer Acceleration if you want fast data transport over long distances between a client and an S3 bucket
- Horizontal Scaling and Request Parallelization for High Throughput
- For more details:
Consistency
- Read after write consistency for PUTS of new objects: a new object is ready to read as soon as It's uploaded
- Caveat: If a HEAD or GET request to an object key name is made before creating the object (to check if the object exists), S3 provides eventual consistency for read-after-write
- Eventual Consistency for overwrite PUTS and DELETE: update and deletes may need some time to propagate
Resilience
- CRR cloud be used to create Resilience Replicas
Disaster Recovery
- CRR could be used as Disaster Recovery solution that provides a low RPO (Recovery Point Objective)
- S3 RTC (Replication Time Control) could be combined with CRR: 99.99% of replications happens <= 15 minutes
Security
- The only entity that initially has access to a booket is the account that creates it (the root account)
- The bucket by default isn't public (it doesn't trust any other aws account; it doesn allow public access)
- Bucket authorization is controlled using:
- IAM Identity policies for known principals
- It's added to IAM Identities (Users, Groups, Roles)
- It can include S3 elements
- It only works for identities in the same account as the bucket
- Bucket policies (resource policies)
- It's added a bucket level but
- It's applied to all bucket objects
- It can apply to anonymous accesses (public access)
- Bucket or Object Access Control Lists (ACLs):
- It's for also all principals
- It's not recommended anymore
- Block Public Access Bucket Setting:
- It's a setting applied on top of any existing settings as a protection
- It OVERRULES any other public grant
- It can disallow ALL public access granted to a bucket and its objects
- It can also block new public access grants to a bucket and its objects
- It uses ACLs, bucket policies, access point policies, or all
- It's turned on by default
- IAM Identity policies for known principals
- If more than 1 policy apply for a principal:
- All policies are combined
- least-privilege principle is applied:
- 1- Explicit Denies are the top priority
- 2- Explicit Allows are the second priority
- 3- Implicit Denies are the default
- Client-side Encryption:
- It's the responsibility of the client/application:
- Encryption/decryption process (CPU intensive process)
- Encryption keys
- Objects are encrypted before they're uploaded in S3
- It's used when strict security compliance is required
- It has a significant admin and processing overhead:
- To Keep track of keys
- To manage which ones are used for which files
- To store them securely
- To back them up
- To manage rotation
- It requires a powerful machine
- It's the responsibility of the client/application:
- Encryption In Transit:
- It's achieved by SSL/TLS
- Encryption At Rest:
- Objects aren't encrypted by default
- It can be configured on a per-object basis
- Sever-Side Encryption with Customer-Managed Keys (SSE-C):
- S3 handles the encryption/decryption process (a CPU intensive process)
- The customer is responsible for keys management
- Keys must be supplied with each PUT/GET request
- It also has a significant admin and processing overhead (see Client-Side Encryption)
- Sever-Side Encryption with S3-Managed Keys (SSE-S3 or Amazon S3 master-key):
- Keys are generated by S3 using AWS KMS
- KMS provides 2 versions of the key: 1 encrypted version and 1 decrypted version
- S3 encrypts object by using AES-256 and the key decrypted version
- S3 takes the key encrypted version and stores it with object
- We always know which key is used to encrypt which object
- Pros:
- No admin and processing overhead
- No CPU machine is necessary
- Cons:
- Less security: Role separation isn't possible
- If an IAM Entity has permission to manage an S3 bucket (read/write), they could then also encrypt/decrypt data
- Sever-Side Encryption with AWS KMS-Managed Keys (SSE-KMS):
- Objects are encrypted using individual keys generated by KMS
- Encrypted keys are stored with the encrypted objects
- Decryption of an object needs both S3 and KMS key permission
- E.g., We could have an S3 administrator with full control on S3 objects but without the ability to read S3 data
- Pros:
- No admin and processing overhead
- No CPU machine is necessary
- Role separation: allow an identity to be given S3 administrator rights, but not allow them to interact with objects
- Bucket Default Encryption Propriety:
- Objects are encrypted in S3 (not buckets)
- Each PUT operation needs to specify encryption (and type) or not
- A bucket captures any PUT operations where no encryption method/directive is specified
- It doesn't enforce what type can and can't be used
- Bucket policies can enfore what type can be used
- For more details:

Monitoring
- Server access logging:
- It provides detailed records for the requests that are made to a bucket
- It's disabled by default
- It stores logging requests in a specific S3 bucket in the same AWS account or in a completely different AWS account
- It requires to allow
- Principal: AWS root account (arn:aws:iam::000000000000:root)
- Action: "S3:PutObject"
- Resource: log buckets
- Enabling Logging Using the Console
- Server access logging overview
- Object-level logging:
- It records object-level API activity by using CloudTrail data events
- It's disabled by default
Pricing
- Lifecycle management:
- Data transfer fee when data is moved from a tier to another one
- Automation and Monitoring fee?
Use cases
- CRR:
- Compliancy of data and making sure data is kept in a dedicated region (for example for GDPR compliance)
- See Scalability, Resilience and DR sections
- Lifecycle management:
- Reduce admin overhead
- Presigned URLs:
- Stock images website:
- Media stored privately on S3
- Presigned URL generated when an image is purchased
- Client access to upload an image for process to an S3 bucket
- Stock images website:
- Security:
- Use IAM policies if:
- We need to control access to AWS services other than S3:
- IAM policies will be easier to manage since you can centrally manage all of your permissions in IAM, instead of spreading them between IAM and S3
- You have numerous S3 buckets each with different permissions requirements:
- IAM policies will be easier to manage since you don’t have to define a large number of S3 bucket policies and can instead rely on fewer, more detailed IAM policies
- You prefer to keep access control policies in the IAM environment
- We need to control access to AWS services other than S3:
- Use S3 bucket policies if:
- You want a simple way to grant cross-account access to your S3 environment, without using IAM roles
- Your IAM policies bump up against the size limit (up to 2 kb for users, 5 kb for groups, and 10 kb for roles)
- S3 supports bucket policies of up 20 kb
- You prefer to keep access control policies in the S3 environment
- S3 ACL:
- It's NOT recommended
- It's a legacy access control mechanism that predates IAM
- If it's already used and is sufficient, there is no reason to change
- Controlling Access to S3 Resources
- Use IAM policies if:
Limits
- Object # / Bucket: Unlimited
- Bucket Capacity: Unlimited
- Bucket Name:
- Length: 3 to 63
- Unique globally
- No uppercase
- No underscores
- It must start with a lowercase letter or a number
- It can't be formatted as an IP address (1.1.1.1)
- Bucket # / AWS Account:
- 100: Default limit
- 1,000: non default
- More: Support Ticket
- Object max size: 5 TB
- Multipart upload max size supported: 5 TB (Object max size)
- Put max size supported: 5 GB (Hard)
- PUT # / second: 3,500
- Get # / second: 5,500
- Parallel request, Prefix usage: No limit?
- Presigned URL expiration: 7 days
S3 Request #/s Hard: 3500 PUTs/second
Best practices
- Presigned URLs:
- Create presigned URLs with an identity with long term credentials
- Avoid creating presigned URLs with roles
- Best Practices Design Patterns: Optimizing Amazon S3 Performance
Description
- It's a Content Delivery Network (CDN)
- It's a global service (Network and Content Delivery)
- It's a global cache for data on edge caches:
- It allows lower latency, higher throughput
- It reduces load on the content servers
- It caches objects for a TTL (Time To Live)
- It's for static, dynamic files, streaming (RTMP) and, interactive content
- It distributes Media using HTTP or HTTPS
- It's not included in free tier subscription
- It comes with a default domain names:
- [randomCodes].cloudfront.net
- It work with http and https
- E.g. 1, http://d1234.cloudfront.net
- E.g. 2, https://d1234.cloudfront.net
- ARN:
- Format: arn:partition:service:region:account:distribution/distributionName
- E.g., arn:aws:cloudfront::191449997525:distribution/EWA2YC90MZY8E
Origin
- The server/service that hosts our content
- It needs to be accessible on the internet
- It can be an S3 Bucket:
- S3 AWS public endpoints will be used
- It can be an web server (an ELB, or a Route 53):
- An EC2 instance:
- A Corporate Data Center Server: a public IP address will be used
- It can be an Amazon MediaStore:
- It can be a corporate Data
Distribution
- It's the "configuration" entity within CloudFront
- It's where we configure all aspects of a specific "implementation" of CloudFront from
- It has a DNS address
- It can include 1 or more origins
- It has 2 Delivery Methods:
- Web Distribution:
- To speed up distribution of static and dynamic content, for example, .html, .css, .php, and graphics files
- Distribute media files using HTTP or HTTPS
- Add, update, or delete objects, and submit data from web forms
- Use live streaming to stream an event in real time
- RTMP Distribution (Real-Time Messaging Protocol):
- To speed up distribution of streaming media files using Adobe Flash Media Server's RTMP protocol
- It allows an end user to begin playing a media file before the file has finished downloading from a CloudFront edge location
- It requires to store the media files in an Amazon S3 bucket
- Web Distribution:
- Origin Settings:
- Origin Domain Name: the service/server that hosts the origin
- Origin Path to set a specific part of a service/server (E.g., S3 folder)
- Restrict Bucket Access:
- Default Cache Behavior Settings:
- Viewer Protocol Policy:
- Caching Content Based on Query String Parameters
- Distribution Settings:
- Price Class:
- Only US, Canada, Europe;
- US, Canada, Europe, Asia, Middle-East, Africa or;
- All Pops (Recommended choice but most expensive)
- WAF ACL (Web Application Firewall Access Control List):
- To allow or block requests based on criteria that we specify,
- Choose the web ACL to associate with this distribution
- Default Root Object:
- The object that we want CloudFront to return (E.g. index.html)
- When a viewer request points to our root URL (www.example.com
- instead of to a specific object in our distribution (www.example.com/index.html)
- TTL (Time To Live):
- It's set at objects level: it dictates to CloudFront how long they should be cached for
- It could be set at CloudFront level as a distribution default TTL
- Alternate Domain Names (CNAMEs):
- We could add up to multiple CNAMEs
- We must create their record with our DNS service to route queries for www.example.com to d1234.cloudfront.net
- SSL certificate is required within ACM (AWS Certificate Manager) to proves our ownership of that domain
- Restrict Viewer Access:
- By default, CloudFront is a publicly accessible CDN
- We can make it private (private CloudFront Distribution):
- It will then require users to access our content to use a Signed URL or a Signed cookie
- Trusted Signers: we could choose the current AWS account and/or other ones to create signed URLs or signed cookies
- Price Class:
Edge Location/Regional Edge Caches
- see infrastructure
- It's not just read only?
Caching Process
- Create a distribution and point at one or more origins
- Distribution DNS address directs clients at the closest available Edge Location
- If the requested data is cached in the Edge Location, it's delivered locally from it (cache hit)
- If the requested data isn't cached:
- The edge location attempts to download it from a regional cache
- An aged (expired) content in edge location may still exist here
- It's bigger (more storage) and
- It servers more people (attached to multiple Pops)
- If the data isn't in regional cache,
- The edge location and regionl cache perform an origin fetch
- They download the data from the origin
- The regional cache will be able then to serve requests from other pops
- As the edge location receives the data,
- It immediately begins forwarding to the custmer
- It immediately begins
- It immediately caches it for the next visitor
- The edge location attempts to download it from a regional cache
- Content validity:
- It could expire (valid for a TTL): It could be discarded and be recached
- It could be explicitly invalidated and removed
Origin Access Identity (OAI)
- It's also called Origin Access Identifier
- It's a virtual identity that can be associated with a distribution
- It allows restriction of an S3 bucket to accept connections only from a specific CloudFront OAI
- It works only with S3 buckets (it doesn't support any other service such as EC2 server or on premise web server)
- How it works:
- Private S3 bucket (bucket policy denies public access)
- Create it private
- Edit bucket policy of an existing S3 bucket and remove its public access statement (if it applies)
- Create an OAI in CloudFront
- Private distribution in CloudFront with the OAI above:
- Create a new Private distribution
- or Edit an existing public distribution (Distribution Setting > Origin and Origin Settings > Edit the origins)
- This will grant the AOI above Read Permission on the S3 bucket above (It'll add an allow statement in the bucket policy)
- Private S3 bucket (bucket policy denies public access)
- Use cases:
- For better User experience: to avoid a lower level of performance by going direct to S3
- To avoid bypassing an application,
- It generates signed URLs to access restricted content using CloudFront
- We don't want our customers having the abily to bypass it and go directly to the underlying S3 bucket
Description
- It's an implementation of the Network File System (NFSv4) within AWS
- It's delivered as a service
- It can be mounted on multiple Linux instances at the same time
- It's accessed via "mount targets"
- It's currently accessible from Linux EC2 or Linux on-premise
- It's elastic:
- An initial size isn't required
- It grows and shrinks automatically, as files are added and removed
- It Uses S3: Standard and IA
- It has a DNS name:
- Format: fs-[randomCode].efs.ap-[regionName].amazonaws.com
- E.g., fs-963f75af.efs.ap-useast-1.amazonaws.com
- It integrate with multiple AWS services:
- AWS backup service to get data backed up
- AWS Data Sync that can act as a synchronization product and get data in EFS
- For more details
Mount Targets
- They're placed in subnets inside a VPC (1 mount target/AZ)
- They have an IP address
- Security Groups are used to control access to them
- The related EC2 instances' SGs could be best fit here
- By simply allowing all inbound traffic from source with the same SG
- It's accessed:
- By local EC2 instances from a local VPC
- By other EC2 instances from other VPCs across VPC peering connection
- By on-premises locatons via a VPN or Direct Connect
- CLI EFS Utilities:
- It's not required since EFS is standard inside Linux OS
- It's recommended though since it allows the machine a tighter integration with EFS
Storage Classes
- Standard:
- Infrequent Access (IA)
Lifecycle management
- It's used to move files between classes based on access patterns
Scalability
- It's Elastic:
- An initial size isn't required
- It grows and shrinks automatically, as files are added and removed
- Performance modes:
- General Purpose:
- It's the default mode
- It's suitable for 99% of needs
- Max I/O:
- It's designed for when a large number of instances (hundereds, thousands) need to access the file system
- For more details
- General Purpose:
- Throughput modes:
- Permitted throughput:
- It's the maximum throughput we can drive a file system at any given point
- It's either the baseline throughput or the burst throughput
- Bursting Throughput mode:
- It's the default
- It's Spiky: driving high levels of throughput for short periods of time, and
- It's low levels of throughput the rest of the time
- Its baseline throughput is determined by the size of the file system that is stored in the standard storage class
- A file system can drive throughput continuously at its baseline rate
- E.g.1, a 10 GiB file system baseline aggregate throughput: 0.5 MiB/s
- E.g., a 512 GiB file system baseline aggregate throughput: 25 MiB/s
- Its burst throughput is also determined by the file system size as follow:
- Minimum burst throughput: 100 MiB/s regardless of the file system size
- Burst Throughput: 100 MiB/s/TiB
- Burst Throughput duration: it's determined by its size
- E.g., a 10-TiB file system can burst to 1 GiB/s (10 x 100 MiB/s/TiB) of throughput for 12 hours per day or drive 500 MiB/s continuously
- It uses a credit system to determine when file systems can burst:
- A file system earns credits over time
- An inactive file system earns burst credits
- A file system that is driving throughput below its baseline rate earns burst credits
- A file system uses credits whenever it reads or writes data
- The baseline rate is 50 MiB/s per TiB of storage (equivalently, 50 KiB/s per GiB of storage)
- Earning 50 MiB/s per Tib of storage????
- E.g
- Provisioned mode (or the Throughput mode):
- It allows to provision the throughput independent of the amount of data stored
- For more details:
- Permitted throughput:
- Performance
Consistency
- Read-after-write consistency
- For more details
Resilience
- Data is stored redundantly across multiple AZs
- It's region resilient: Its availability isn't impacted by an AZ failure
- Mounted Targets aren't HA by design: It's recommended to have 1 mount target by AZ
Disaster Recovery
- AWS Backup Service
- The EFS-to-EFS backup solution
- For more details
Security
- Security Group:
- It's associated with mounted targets
- Protocol: NFS; Port: 2049; Source: Instance Security Group
- For more details
- Encryption at rest:
- It's configured when creating a file system
- It's disabled by default
- It works with a AWS KMS of the same or another AWS account
- Encryption in transit:
- It's configured when mouting a file system
Monitoring
- CloudWatch's PercentIOLimit:
- It help to determin which performance mode to choose
- If a General Purpose mode EFS volume hits 100% for extended periods of time, consider using Max I/O mode
- CloudWatch's BurstCreditBalance:
- It help to determin which throughput mode to choose
- If we experience performance issues with an EFS volume in Bursting Throughput mode:
- Check the BurstCreditBalance CloudWatch metric
- If its value is either zero or steadily decreasing, Provisioned Throughput could be a solution
Pricing
Use cases
- Parralel and Elastic workloads:
- It's designed for large scale parallel access of data
- It supports thousands of NFS clients and access the data concurrently
- E.g. 1, Shared data/media for WordPress instances, content management and web serving using a shared set of data
- E.g. 2, Shared bespoke logging information:
- Scenarios where CloduWatch isn't used
- Because of tight security requirements
- E.g. 3, Big Data and analytics where concurrent access is needed from multiple locations (why not S3?)
- E.g. 4, Certain media processing workflows like video editing, studio production, broadcast processing
- E.g. 5, A shared home directory platform for multiple Linux OS instances: rather than having a home directory on each of them
- Antipatterns:
- It's not for is single machine situations, so it's probably overkill to use EFS if you've only got a single EC2
- It's not an object storage (it's not supported by Cloudfront)
- It's not used for temporary storage (it's not efficient)
Limits
- Max VPC # / EFS volume: 1 (use VPC Peering connection to give access to ressources in other VPCs)
- Max EFS Mount Target # / VPC: 400
- Max EFS Mount Target # / AZ: 1
- Max SG # / Mount Target: 5
- Max EFS volume # / AWS Account: 1,000 (Default: it could be increased)
- Max provisioned throughput per EFS Volume for all connected clients: 1 GBps (Default)
- Max bursting throughput per EFS Volume for all connected clients: 1 or 3 GBps (depending on the region) (Default)
- Max throughput per EFS Client (EC2 Instance): 250 MBps
- Max I/O EFS in Max I/O Mode: Unlimited
- Max I/O EFS in General Purpose Performance Mode: 7,000 operations/s (it's calculated for all clients connected to a single file system)
- For more details
Best practices
- For High availability:
- Create 1 mount target by AZ
- Use the mount target of the EC2 instance AZ to mount to EFS
- If an AZ fails, all instances in others AZs will still have access to the EFS storage
- For less admin overhead,
- Associate the Mount Targets to the SG of the EC2 instances they're mounted on
- Allow all inbound traffic from the same SG
Description
- It's a database as a service (DBaaS) product:
- It can be used to provision a fully functional database without the admin overhead
- We can't log in to its OS
- Patching of the RDS OS and DB is Amazon's responsibility
- It can be made publicly accessible
- It'sn't Serverless
- It supports different database engines:
- MySQL:
- MariaDB:
- PostgreSQL:
- Oracle:
- Microsoft SQL Server
- Aurora:
- See Aurora Provisioned
- See Aurora Serverless
- It has an endpoint, a CNAME:
- It points to the current primary instance
- We can connect into it with the CNAME + Port #
- It requires a minimum of 2 subnets in a Subnet Group
Architecture
Computing
- It's deployed in EC2 instances
- It supports:
- EC2 General Purpose Family (DB.M4, DB.M5)
- Memory Optimized family:
- DB.R4 and DB.R5
- DB.X1e and DB.X1 for Oracle
- Burstable (DB.T2 and DB.T3)
- Instance could be modified:
- It could be applied immediately
- It could run run at maintenance time that is created when the instance is created
Storage
- It uses a storage similar to EBS,
- It supports:
- General Purpose SSD (gp2):
- IOPS per GiB,
- burst to 3,000 IOPS (pool architecture like EBS)
- Provisioned IOPS SSD (io1):
- 1,000 to 80,000 IOPS (engine dependent)
- Size and IOPS can be configured independently
- Autoscalling feature (disabled by default)
- General Purpose SSD (gp2):
Option Group
-
It allows to configure (enable, disable, ...) some of the RDS database engines specific features
- E.g. 1, MySQL Memcached support (MEMCACHED)
- E.g. 2, Oracle Native Network Encrytion (NATIVE_NETWORK_ENCRYPTION)
-
It's currently available for MariaDB, MySQL, Oracle and, Microsoft SQL Server
-
It's not currently available for PostgreSQL and Aurora
DB Parameter Group
- It acts as a container for engine configuration parameters that are applied to one or more DB instances
- E.g. 1, autocommit DB parameter for MySQL 5.6 RDS instance
- E.g. 2, auto_increment_increment DB parameter for MySQL 5.6 RDS instance
- A default one is created
- When a db instance is created without specifying a custom DB parameter group
- It contains db engine defaults and Amazon RDS system defaults based on the engine, compute class and, allocated storage of the instance
- It's not possible to modify it
- To modify the DB Parameter Group of an RDS instance associated with a default Parameter Group:
- Create a new DB Parameter Group
- Modify the RDS Instance to use the new parameter group
- If a non-default DB parameter group is updated,
- The changes is applied to all DB instances that are associated with it
- When the change is applied depends on the "Apply Type" of the changed parameter:
- If it's a dynamic parameter, the change is applied immediately regardless of the Apply Immediately setting
- If it's a static parameter, the parameter change takes effect after the DB instance is manually reboot
- For more details
Scalability (Read Replica)
- It's a read-only copy of an RDS instance
- It's created from a primary instance
- The source primary instance is called the Master Instance
- The copy instance is called the Read-Replica Instance
- It's achieved by using asynchronous replication from the Master Primary instance to the read replica instance
- It can be created in the same region or in a different region
- For different region, AWS handles the secure communications between those regions (Encryption in Transit)
- Without a need to any networking configurations
- It requires Automatic backups to be turned on Master Instance
- It can be addressed indepently from its primary instance (each read-replica has its own DNS name)
- It's used for scaling reads:
- It's possible to have up to 5 read-replica (5x increase in reads)
- It's not possible to have a single DNS name to address all of those read replicas
- Our application need to be aware of our database topology in order to take advantage of these read replicas
- It's possible to have read-replicas of read replicas (latency)
- It can be promoted to be a primary instance
- The read-replica db becomes then its own database (master)
- It breaks the asynchnous replication
- It can be used for read and write operations
- It can be multi-AZ
- It's available for all database types (MySQL, PostgreSQL, MariaDB, Oracle, Aurora) except SQL-Server
- Database engine version upgrade is independent from master instance (it must be handled manually)
- Multi-AZ vs. Read-Replicas
Consistency
- Reads from a Read-Replica are eventually consistent - normally seconds
Resilience
- Multi-AZ mode:
- RDS creates 2 db instances in the same region:
- The primary database (production)
- The Standby database is created in a different AZ
- It's for resilience Only
- Disaster Recovery: Database failure, AZ failure
- DB maintenance
- It'sn't for performance (see read replicas)
- Primary instance:
- It's the only one that is accessed with the instance CNAME
- It has its own storage
- The Standby instance:
- It's the exact copy of the primary database
- It has also its own storage
- The data replication from the primary db is synchronous: data is copied in real time
- It's the source of backups (no performance impact)
- Failover Process:
- In case of a db maintenance or a failure (DB instance or AZ),
- RDS will try to minimize the outages
- It will automatically failover to the standby db
- Its CNAME @ won't change
- Its CNAME @ will point to the standby db
- It may be a brief outage:
- It can have some level of lag or caching that can slow down it: 2 digits seconds or ~1 or 2 minute(s)
- DB maintenance Process:
- In case of a planned db maintenance (change the db size),
- RDS will try to minimize the outages
- It will apply the change on the standby database 1st
- It will then "failover" to the standby db that will become the new primary db (See failover process)
- It will finally apply the change on the new primary db
- Fault Tolerant System?
- Except Aurora, RDS is not a truly fault tolerant system
- This is because of the brief outage that could happen during the failover process
- It provides us with better RTO
- It allows to force AZ changing: actions > reboot
- We can actually reboot with failover
- This is a way of forcing our AZ to change
- So we can change from one AZ to another by just rebooting with failover
- It's possible for MySQL, MariaDB, PostgreSQL, Oracle, SQL Server
- RDS creates 2 db instances in the same region:
- Single AZ Mode:
- The RDS instance is in a single AZ
- The Standby instance isn't created
Disaster Recovery
- Snapshot:
- It's a manual backup:
- It's user initiated
- E.g., Console, CLI, Lambda function
- It's created automatically when a new RDS instance is created/restored
- It's stored in S3
- It's kept even after the original RDS instance is deleted
- It can be copied to the same region or to a different one
- It's a manual backup:
- Backups:
- It's an automated backup:
- It occurs once a day during a backup window: it takes a full daily snapshot
- Log backups occur every 5 minutes (Point in time)
- It's taken from the Standby instance
- It's stored in S3
- It's an incremental backup:
- The 1st backup stores the entire used space
- After, changed data only stored
- It's automatically deleted when the original RDS instance is deleted
- It allows to recover our db to any point in time within a retention period
- Retention period is from 1 to 35 days
- Retention period is 0 means it's disabled
- Down to a second within this retention period
- It's enabled by default
- Default retention period is 7 days
- It provides a low RPO
- It's an automated backup:
- Snapshot/Backups operation impacts:
- During the Snapshot/backup window, storage I/O may be suspended while data is being backed up
- We may experience elevated latency
- Restoring Backups/snapshots:
- AWS chooses the most recent daily backup, then
- It applies transaction logs relevant to that day
- It results a new RDS instance:
- With a new DNS endpoint
- With a new SG
- It requires to perform some level of reconfiguration:
- At an application level, to change the DNS Name the application is pointing to
- At AWS level, to associate the new instance to the previous SG
Security
- Network Security:
- It could be Public:
- It will be in a public subnet
- It will be assigned a public IP @
- It will be accessible by resources from outside the VPC it's attached to
- It could be Private:
- It won't be assigned a public IP @
- It will be accessible only by resources inside the VPC it's attached to
- Its network access is controlled by Security Groups (SG)
- For more details
- It could be Public:
- IAM DB authentication:
- It allows to manage database users credentials through IAM
- It's disabled by default
- For more details
- Encryption At Rest:
- It's supported for all database types
- It can be configured only when creating a DB instance
- It can be added by taking a snapshot, making an encrypted snapshot, and creating a new encrypted instance from that encrypted snapshot
- It can't be removed
- It's done using the AWS KMS
- Once an RDS instance is encrypted, the data stored at rest in the underlying storage is encrypted too (
- Its automated backups, read replicas, and snapshots are encrypted
- Read Replicas need to be the same state as the primary instance (encypted or not)
- An Encrypted snapshot requires a new destination region KMS CMK to be copied to a new region
- For more details
- Encryption in Transit:
- Data in transit is encrypted for asynchronous replication of read-replicas in different regions
Monitoring
- Error Node
- It's in the response from the RDS API
- It's for troubleshooting
- We want our application to check whether a request generated an error before we spend any time processing results
- The easiest way to find out if an error occurred is to look for an Error node in the response from the Amazon RDS API
Pricing
- It's based on:
- Instance pricing model (Reserved, On Demand)
- Instance size
- Provisioned storage (allocated): It'sn't Elastic
- IOPS if using io1
- Data transferred out
- Extra storage (backups/snapshots) beyond the 100% of provisioned db:
- We get a free storage space equal to the db size
- For an 100GB allocated RDS DB, 100GB of snapshot/backups are included
- Reserved DB instance:
- It let optimize Amazon RDS costs based on expected usage
- We can reserve a DB instance for a 1- or 3-year term
- Reserved DB instances provide with a significant discount compared to on-demand DB instance pricing
- Discounts for reserved DB instances are tied to instance type and AWS Region
- It's available in 3 varieties: No Upfront, Partial Upfront, All Upfront
- See EC2 Description
- For more details
Use cases
- Scalability: It's used for read-heavy database workloads (It doesn't scale writes)
- Global resilience:
- Improve the ability to recover from a serious failure either within a region or internationally
- It provides with a better RTO better than snapshot's one
Limits
- Max Read-Replicas #: 5
- It's not possible to have a single DNS name to address all of those read replicass
- For more details
Description
- It's a custom-designed relational database engine that forms part of RDS
- It has 2 editions:
- 1st one with MySQL compatibility
- 2nd one with Postgre compatibility
- It's available in regions that have at least 3 AZs (not all regions)
- It uses a base configuration of a "DB cluster" that consists of:
- A single primary instance:
- It's also called the primary node
- It supports read-write workloads
- It performs all of the data modifications to the cluster volume
- A cluster volume:
- It's an all-SSD virtual database storage volume
- It's shared by the primary instance and all replica instances
- It scales automatically
- 0 to 15 Replica instances:
- They're also called replica nodes
- They support only read operations
- There is less than 100 ms of replication lag (Latency)
- A single primary instance:
- Adding a reader is quick:
- It's more quicker than converting a mySQL based RDS from no to multi-AZ
- It only needs to provision a new instance and point it at the shared storage
- It's not adding a new storage; there's no copy involved
- Its location could be
- Regional
- Gloabl
- Not all MySQL versions support this feature
Architecture
Db Features
-
One writer and multiple readers:
- It supports multiple reader instances connected to the same storage volume as a single writer instance
- It's a good general-purpose option for most workloads
-
Parallel query:
- One writer and multiple readers
- It parallelizes some of the I/O and computation involved in processing data-intensive queries
- It allows queries to be executed across all nodes of a cluster at the same time
- It's currently available only for Aurora MySQL edition
- It improves the performance of analytic queries by pushing processing down to the Aurora storage layer
- Use cases:
- Hybrid transactional and analytic workloads
- Queries with larger data sets
- For more details
-
Multiple writers:
- It supports multiple writer instances connected to the same storage volume
- It's good for when continuous writer availability is required
-
They need to be enabled when a database cluster is made
Global Database Location
- It's currently available only for Aurora MySQL edition and version MySQL 5.6.10a
- It consists of 1 primary cluster in a primary AWS region and 1 read-only cluster in a secondary region
- This implies that data is replicated 12 times (2 copies x 3 AZs x 2 Regions)
- Writes are done in the primary cluster
- Writes are replicated to secondary AWS Regions with typical latency of less than 1 sec
- It requires large DB instances: a Memory Optimized DB instance class (includes r and x classes)
- It requires to be enabled when a database cluster is made
- When enabled, database features aren't available
Endpoints
- There are several different endpoints available
- Cluster Endpoint:
- It connects our app. to the current primary DB instance of the app's cluster
- It's updated automatically so that it always points to the primary instance
- It's for both reads and writes
- Reader Endpoint
- It load balances read operations across all available Read Replicas
- It's for read only
- It offloads read queries and reduces load on the primary DB instance
- Instance Endpoints:
- It connects to a specific instance in the cluster
- It allows to have fine-grained control over query allocation, rather than having Aurora handle connection distribution
- Custom Endpoints:
- It connects explicitly to an individual database instances
Migrating a RDS MySQL to RDS Aurora
- Way 1:
- Create an Aurora read-replica for the primary MySQL database
- Promote the read-replica to a primary database
- Way 2:
- Create an Aurora read-replica for the primary MySQL database
- Create a snapshot a the Aurora read-replica
- Create a new Aurora database from the snapshot
- For more details
Scalability
- Storage Autoscaling:
- It starts with 10 GB
- It scales in 10 GB increments to 64TB
- It scales Compute ressources up to 32vCPUs and 244GB of memory
- For more details
- Reads Scaling:
Consistency
Resilience
- Storage:
- It's replicated (the cluster volume) 6 times across 3 AZs (2 cluster data copies in each AZ)
- It's constantly backed up to S3
- It can tolerate
- The loss of up to 2 data copies or an AZ failure without losing write availability
- The loss of up to 3 data copies without losing read availability
- Instance DB:
- It automatically initiates a Failover when there is any issue on the current primary instance
- It's also possible to initiate a Failover manually (action > Failover)
- The replica with the highest priority is promoted to be the primary during failover
- Tier 0 has the highest priority
- It's capable of self healing any data problems that exists in a shared storage
- It scans continuously data blocks and disks for errors
- It replaces them automatically
- It monitors disks and nodes for failures
- It automatically replaces/repairs the disks/nodes without the need to interrupt read/write processing from the db node
Disaster Recovery (Backtrack)
- It lets quickly recover from a user error, without having to create another DB cluster
- It has a maximum window of 72 hours
- E.g., if we accidentally deleted an important record at 10am, we could use Backtrack to move the Aurora database back to its state at 9:59am
- Pros:
- It doesn't create a new database (with a new DNS Name)
- It doesn't require to perform any reconfiguration (see the required reconfiguration for the other RDS based engines)
- Con: It does cause an outage because it's rolling back the entire shared storage
- For more details
Security
Pricing
- It's based on high watermark system:
- It's based on the used storage
- It start off with zero allocation
- "Auto scalling" feature:
- It's to dynamicaly scale up/down of reader instances
- When the database isn't used, it allows to scale down the database
- But there is a minimum and the level of reader instances increase/decrease is limited
- We're not going to get the linear alignment between the capacity that we need (the amount of resources actually used) and the capacity that is provided
- E.g.:
- If we consume 10 TiB, we're billed for 10 TiB
- If we delete 5 TiB, we're still using 10 TiB and, billed for 10 TiB
- To reduce the high watermark, we should take a backup and make a new cluster with just that data
- For more details
Use cases
- Eventual consistency is acceptable:
- To use the cluster endpoint for writes
- To use the reader endpoint for all reads
- To avoid using specific instance endpoints
- Immediate consistency use case:
- To use the cluster endpoint for writes
- To use the cluster endpoint for reads of data recently updated (less than 100 ms)
- To use the reader endpoint for all other reads
- More use cases
Limits
- Max cluster volume: 64 TiB
- Max cluster Replicas #: 15
- Max Compute ressources: 32vCPUs
- Max Compute memory: 244GB
- Backtrack maximum window: 72 hours
Description
- It handles certain resource allocation as a service
- It's based on the same db engine as Aurora Provisioned
- It has a shared storage accessible for all db instances
- It's a self-managed db product:
- We access it just as we would do if we were accessing a provisioned database
- But it removes the complexity of managing a database such as:
- Provision a hardware or virtual machines (All RDS remove this complexity)
- Install of the database software (All RDS remove this complexity)
- Manage of backups, High Availability, performance (All RDS remove this complexity)
- Manage the server instances themselves (Only RDS Serverless removes this complexity)
- It does only require to specify a minimum and maximum amount of resources (see ACUs, below)
- It handles the scaling without any distruption to its related application
- Data API
- It's a web-based query editor tool
- It allows you to access the database using traditional APIs
- It requires to be enabled to work
- Rather than having to open a traditional database connection and execute SQL queries, we can connect to it using standard API
- It could be used by web services-based application including AWS Lambda, AWS AppSync and, AWS Cloud9
- It's much easier if you're designing an application from scratch and code it to utilize Aurora Serverless
Architecture
ACUs (Aurora Capacity Units)
- It's an abstraction away from physical hardware specifications
- Setting the Capacity of an Aurora Serverless DB Cluster
Private Link
- It's a service that allows to place endpoints inside a customer VPC to access remote services
- Since Aurora Serverless DB instances aren't hosted inside a customer VPC (there's no physical instance inside it)
- Aurora Serverless uses Private Link to access its db instances
- It's like a VPC endpoints
- Aurora Serverless cluster can't currently be accessed from across a VPN or an inter-region VPC peer
Scalability
- It's capable of rapid scaling
- Instance Pool:
- It contains "hot" instances of various different sizes:
- They're ready to use
- They're stateless (they have not any storage attached)
- They have the Aurora Serverless software installed on them
- They can be quickly allocated for any AWS customer as soon as they're needed
- Proxy Fleet:
- It's a transparent set of proxying instances
- It sits between an application and its Aurora Serverless instances
- It abstracts db instances layer from their application
- It grows and shrinks based on demand
- It routes transparently connections from an application to Aurora Serverless instances without this application knowing any different
- It's used to route the workload to "warm" resources that are always ready to service requests (see instance pool)
- Automatic Pause and Resume:
- It's an additional scaling configuration
- It allows to pause (0 ACU) automatically a db instance after consecutive minutes of inactivity
- It reallocates quickly a new db instances when an activity is detected
- E.g., When a current capacity is exceeded,
- It transparently uses the instance pool to provision a new larger database instance or multiple smaller database instances
- It transparently attachs them to the database shared storage
- It transparently redirects connection to the new instances
- It then transparently removes the small instances which are no longer needed
Consistency
Resilience
-
Aurora separates computation capacity and storage
-
Storage volume (Replicas):
- It spreads replicas across multiple AZs
- The data remains available even if outages affect the DB instance or the associated AZ
-
DB Instance Automatic multi-AZ failover:
- The DB instance of an Aurora Serverless DB cluster is created in a single AZ
- If the DB instance or the AZ fails, Aurora recreates the DB instance in a different AZ
- In case of a failure, the Automatic multi-AZ failover takes longer than an Aurora Provisioned cluster
- Its time is currently undefined: it depends on demand and capacity availability in other AZs within the given AWS Region
Disaster Recovery
- Snapshot:
- It's possible to restore an Aurora Serverless db from a snapshot
- It's possible to do it from an Aurora Previsioned db snapshot
- It's always encrypted (We can't turn off encryption)
Pricing
- For Shared storage:
- The pricing is based on high watermark system
- See RDS provisioned pricing
- For DB instances:
- We pay for the database resources that are used on a per second basis
- It's attempting to provide a linear alignment between the needed compute capacity and the provided one
- We could enable the pausing feature (scale it down to 0 ACU) to pause the db instance when It'sn't needed
Use cases
- Intermittent workloads: an application uses a database and has random surges of traffic
- Unpredictable workloads: an application has unpredictable database usage patterns
- Development databases (Test, Staging, A/B Testing) used during work hours and will be shutted down automatically after work hours
- We want to remove the complexity of managing database instances
- We want automatically scaling database instances
Limits
- It exists in a single AZ (See failover description)
- The Aurora Serverless Automatic multi-AZ failover takes longer than an Aurora Provisioned cluster (it has an ongoing costs 24/7 while it's running)
- There is a trade-off here between different priorities:
- It's between a slight increase in the amount of time that failover takes vs. being able to scale back to zero capacity and then only pay for the storage
- It can't be set to be public:
- It's not a drop-in replacement for DynamoDB
- But we can use its Query editor (Data API)
- Its cluster can't currently be accessed from across a VPN or an inter-region VPC peer
Description
- It's a NoSQL database service that provides access to data in milliseconds
- It's a serveless database product
- It's a global service
- It's partitioned regionally
- It's a Multimodel database,
- It includes features of more than one data model
- It's wide-column store:
- It's Key Value database
- It's a 2 dimensional column store database
- It supports Attribute concept:
- It's like a column in other dbs
- It's a key (attribute name) and value
- It could be a Partition Key (PK) or a Hash Key
- It could be a Sort Key (SK) or a Range Key
- It supports different types
- A type of a given attribute could be different across rows
- It could be Nested
- It supports Item concept:
- It's like a row in other dbs
- It's a collection of attributes
- It's inside a table that share the same key structure as every other item in the table
- It has its unique primary key: PK only or PK and SK
- It's a Json document
- It could have up to 400 KB in size
- It supports Table concept:
- It's a collection of items: 0 or more items
- Its name must be unique within its region and AWS account
- It doesn't enforce a rigid schema across all of its items
- It does only require a primary key for the table to be defined upfront
- It could consist of 1 attribute: PK
- It could consist of a composite key: (PK, SK)
- Its ARN:
- Format: arn:${Partition}:dynamodb:${Region}:${Account}:table/${TableName}
- E.g., arn:aws:dynamodb:us-east-1:191449997525:table/myDynamoDBTable
- It's split across Partitions:
- It starts with 1 partition
- It grows depending on the table's size and capacity
- It detemines its table performance
- For more details
- Read Capacity and Write Capacity
- They allow to control performance at the table level
- It's done by providing Read Capacity Unit (RCU) and Write Capacity Unit (WCU)
- E.g. We need to store weather data that is sent by weather station every 30 mn
- We need a table: weather_data
- For each item, we need a Partition Key (a number) to identify weather station
- For each item, we need a Sort Key (date and time) to identify every single data sent by a weather station
Architecture
- A Hashing function is used to associate a data's PK to a partition where data will be put to or got from
- A partition contain 3 nodes:
- 1 Leader node:
- 2 additional nodes

Operations
- Get and Put an item:
- It's reading an item
- It requires to specify an item's primary key: PK only or PK and SK
- It'sn't allowed to get a partial item: its full size is read at once (all attributes)
- Put an item:
- It's writing an item
- It requires to specify an item's primary key: PK only or PK and SK
- It's NOT allowed to put a partial item: all attributes must be written at the same time
- It returns HTTP status code 200 when data it stored persistently (succesfuly)
- Scan:
- It doesn't require any parameters
- If no parameter is added, it will then list/retrieve all item in the scaned table
- It allows additional filters on any attribute of the table
- When a filter isn't on a primary key,
- It read all items of a table;
- It excludes items that don't match the filter;
- It returns the remaining items
- It consumes the capacity of the entire table
- Pros: It's more flexible; It's applied on different PK
- Cons: It's NOT an efficient operation
- Query:
- It allows to perform lookups on the table (like scan operation)
- It doesn't scan all items of a table
- It requires a filter on the PK or PK and SK
- It allows additional filters on any non key attribute
- It consumes the data corresponding to the filtered keys (PK or PK and SK)
- Pros: It's an efficient operation
- Cons: It's always applied on 1 single PS
- Filter:
- It could be applied on any attribute (PK, SK or a simple attribute not key)
- It requires a value
- It requires a type of the attribute when It'sn't applied on a PK nor a SK
Stream & Trigger
- Stream:
- It provides an ordered list of changes that occur to items within a table
- It's a rolling 24-hour window of changes:
- Every time an item is added, updated or, deleted to a table which has streams enabled
- An entry is added to that stream which details the insert, update, or delete operation
- The information that is written in the stream can be configured with one of 4 view types:
- KEY_ONLY: Whenever an item is added, updated, or deleted, the key(s) of that item are added to the stream
- NEW_IMAGE:
- The entire item is added to the stream (post-change)
- It's great when we want to perform an action based on the new value of an item
- E.g., when we create a new account, we should send a confirmation email to the new email @
- OLD_IMAGE:
- The entire item is added to the stream (pre-change)
- It's great when we want to perform an action based on the old value of an item
- E.g., when we update an email address, we should send an approval email to the old email @
- NEW-AND-OLD-IMAGES:
- Both the new and old versions of the item are added to the stream
- It's disabled by default
- It's enabled per table
- It contains data from the point of being enabled
- It's durable, scalable and, reliable (HA achitecture)
- ARN:
- Format: arn:${Partition}:dynamodb:${Region}:${Account}:table/${TableName}/stream/${StreamLabel}
- E.g.: arn:aws:dynamodb:us-west-1:191449997525:table/myDynamoDBTable/stream/2015-05-11T21:21:33.291
- Trigger:
- It's similar to triggers in relational database engines
Global Tables
- It's a set of multi-master table
- It allows to have a table in different AWS regions
- It replicates data to all of the other replica tables
- Reads and Writes are possible from/to all replicas
- It employs last writer wins conflict resolution protocol
- It requires:
- To enable Streams,
- To start with an empty table (=> NOT required anymore since DynamoDB 2019.11.21 version)
- To add a new region to the table
Index
- It provides an alternative representation of data in a table
- It's useful for applications with varying query demands
- Projected attributes:
- Indexes can have either Keys only, All table's attributes or some attributes
- It allows to reduce the amount of data read when items are read from the index
- It can help to improve performance but
- It can cause a huge performance penalty if non-projected attributes are read from it (they're fetched from its table)
- Local Secondary Index (LSI):
- It must be created at the same time as creating a table
- It must be created on tables with composite primary key
- It uses the same PK but an alternative SK
- Query operations could be run on the table or its LSIs (filter: PS and index's SK)
- It's a part of the table:
- It shares its table's read/writting modes: privisioned or on-demand
- It shares the RCU and WCU values for the main table
- It allows performing strongly consistent and eventually consistent reads on the table
- The table’s SK is always projected into the index
- Global Secondary Index (GSI):
- It can be created at any point after the table is created
- It can use different PK and SK
- It's separated from its table:
- It doesn't share the data with its table
- Its data is replicated asynchronously from its table => latency
- It doesnt' support Strong consistent read
- It has its own setting: RCU/WCU; Auto-scalling WC and RC

Scalability
-
Read/Write Capacity modes:
- It controls how a table capacity is managed
- It controls how we're charged from read/write throughputs
-
On-Demand mode:
- The request rate is only limited by the DynamoDB throughput default table limits
- It automatically scales to handle performance demands and bills are per-request charge
-
Provisioned mode:
- A table is configured with static read and write capacity units (RCU and WCU)
- Every operation on items consumes at least 1 RCU or WCU (- Partial RCU/WCU cannot be consumed)
- WCU: 1 KB per s of data or less written to a table
- RCU: 4 KB per s of data or less read from a table in a stronly consistent way
- RCU: 8 KB per s of data or less read from a table in an eventual consistent way
- Atomic transactions requires x2 the RCU
- For a given PK value, a DynamoDB table can't exceed the maximum performance that's allocated to the partition (not the table)
- For 1 single PK value, we can only ever get the maximum performance that's allocated to the partition (not to the table)
- So when we're allocating performance for a DynamoDB table, we're actually doing is allocating it to its partitions (not to the table)
- Provisioned Throughput calculations:
- E.g. 1: A system needs to store 60 patient records of 1.5 every minute
- Assumption: 1 record written per second = 1 WCU of a maximum of 1 KB item (AWS provides a buffer to smooth this out)
- Each write has a size of 1.5 KB = 2 WCU
- Total WCU: 2
- E.g. 2: A weather application reads data from a Dynamo DB table, Each Item in the table is 7 KB in size. How many RCUs should be set on the table to allow for 10 read per second:
- Assumption: Eventual consistent read mode (since it's the default)
- 10 reads per second = 10 RCU of a maximum 4 KB item
- Each read has a size of 7 KB = 2 RCU
- Total RCU for eventual consistent read = 20 RCUs / 2 = 10 RCUs
- How to Calculate Read and Write Capacity
- E.g. 1: A system needs to store 60 patient records of 1.5 every minute
- Auto Scaling:
- It's only possible with Provisioned Read/Write capacit mode
- It's active by default
- It could be enabled on any table that doesn't have it active
- It requires to set:
- min RC and WC
- max RC and WC
- Target utilization percentage
- It uses:
- a Scaling Policy in AWS Auto Scaling
- Amazon CloudWatch to monitor a table’s RC and WC metrics + alarms to tracks consumed capacity
- See diagram below
-
For more details
Consistency
- Writtings:
- They're done on the leader node
- Replications are made from the leader node to the other non leader nodes
- Data is written in all AZs within a second (< 1s)
- It consumes 1 WCU for every 1KB or less of data
- Readings support 2 modes:
- Strongly consistent read:
- Data is read from the leader node
- It returns the most up-to-date copy of data
- It takes longer
- It will consume 1 RCU for every 4KB or less of data
- Eventually consistent mode:
- Data is read in any of the 3 nodes
- It's a mode that is preferring speed
- Data received may not reflect the recent write
- It's the default for read operations
- It will consume 1 RCU for every 8KB or less of data
- E.g., for 10 gets of items of 10 bytes:
- We'll consume 10 RCU with strongly consistent read
- We'll consume 5 RCU with eventually consistent mode
- All costs and calculations are based on Strongly consistent mode
- Strongly consistent read:
Resilience
- It's resilient on a regional level
- It stores table's partitions in at least 3 different AZs (1 replica / AZ)
- It can survive the failure of an AZ without any additional configuration
- They're stored on nodes
Disaster Recovery
- Point-in-time recovery:
- It's a feature that requires to be enabled on a per table basis
- Once enabled, it's then possible to restore to a point in time up to the last 35 days
- Backups
- It's manual of a table (not be confused with automated backedup of RDS)
- It stores data and configurations (settings) listed in the "Backup table details" page:
- Primary partition key
- Sort Key is it exists
- Read/write capacity mode
- Provisioned read capacity units
- Provisioned write capacity units
- Encryption Type
- Auto Scaling
- Stream enabled
- Indexes
- Resore:
- It's done in a new table name
- It can take several hours to complete
- ARN:
- Format: arn:${Partition}:dynamodb:${Region}:${Account}:table/${TableName}/backup/${BackupName}
- E.g., arn:aws:dynamodb:us-east-1:191449997525:table/myDynamoDBTable/backup/myDynamoDBTableackup
Security
- It's a public service (like S3)
- It's private by default (like S3)
- To access a DynamoDB table, it requires
- to give access to an IAM Identity in the same account (user, role, group) using identity policies or
- to give access to an IAM role in the same account that allows an external identity to assume it
- It's NOT possible to apply ressource level permission (unlike S3)
- Encryption At rest
- It's enabled by default
- DEFAULT:
- The key is owned by Amazon DynamoDB
- It's free
- KMS - Customer managed CMK:
- The key is stored in customers' account
- The key is created, owned and, managed by customers
- AWS Key Management Service (KMS) charges apply
- KMS - AWS managed CMK:
- The key is stored in customer's aws account
- The key is managed by AWS Key Management Service (KMS)
- AWS KMS charges apply
- It allows to separate the role: DynamoDB administrators don't necessarly have the permission to "read" (decrypt) data in dynamoDB
- Historically, it used to be an option
Monitoring
- It comes with full integration with CloudWatch
- Read/Write capacity (Units/Second)
- Throttled read/write requests (Count)
- Throttled read/write events (Count)
- Latency for Get, Put, Query and, Scan operations
- Streams: GetRecords returned records (Count), GetRecords returned bytes (Bytes), GetRecords returned latency (Miliseconds), TTL deleted items (Count)
- Errors
Pricing
- It depends on the used read/write mode: On-demand, Provisioned
- On-demand:
- No capacity planning is required
- We're charged by operations (reads and writes)
- New applications where the workload is too complex to forecast
- E.g., for a multi-tenant app. that it uses pay per use pricing:
- by using on-demand we make sure that our costs are directly aligned to the income that you're generating from the app
- So we make sure that wherever price that we sell our application to our customers for we have included an appropriate amount of on-demand pricing for our underlying database
- Provisioned:
- We specify a read and write capacity value on a table
- It's cheaper than On-demande mode
- Reads:
- Any costs for DynamoDB are based on strongly consistent reads
- Eventually consistent reads are half the cost of strongly consistent reads
Use cases
- DynamoDB:
- Unstructured data:
- Keys and values
- Keys and other attributes
- Json documents
- Complex data types
- Serverless Applications that needs a web scale database, a serverless non relational database (not a fixed schema) + ID federation
- When needing a web-scalable DBaaS product that provides integration with CloudWatch
- When needing a lightweight, on-demand database product
- For storing session data thanks to its single millisecond latency
- It'sn't for relational data
- Unstructured data:
- On-Demande Read/Write Capacity mode:
- We create new tables with unknown workloads
- We have unpredictable application traffic
- We prefer the ease of paying for only what we use
- Indexes:
- We have a different type of access pattern not supported by table's PS or PS and SK
- Stream & Trigger:
- Stream is used by AWS for replications envolved in globa tables
- To implement an event driven pipeline:
- Stream containing changes + Trigger + Lamda function
- E.g. 1, Send approval or confirmation email when it's changed or a new account is created
- E.g. 2, Send a notification when something happen
Limits
- Item's max size: 400 KB:
- It includes:
- Attribute name binary length (UTF-8 length)
- Attribute value lengths (again binary length)
- E.g., an item with 2 attributes:
- 1st is "shirt-color" with value "R" and
- 2nd is "shirt-size" with value "M"
- Item Total Size is 23 bytes
- Max LSI #: 5 (Hard)
- Max GSI #: 20 (Default: could be increased by a support ticket)
- Max WCU / Partitions: 1,000 WCU
- For more details
Best practices
DynamoDB Accelerator (DAX)
- It's an in-memory cache
- It's designed specifically for DynamoDB (it's the prefered solution with DynamoDB)
- It delivers results in microseconds (~400 us):
- Rather than in the single-digit milliseconds available from DynamoDB (~5 ms)
- When a DynamoDB item is read, it's returned to the application and stored inside DAX
- When it's read again, it's returned from DAX (without using DynamoDB): cache hit
- It runs inside a VPC
- It uses a cluster architecture with 1 or more nodes
- DAX client:
- It's used by applications
- It's generally installed on the same compute resources as the application itself
- It maintains 2 distinct caches:
- Item cache:
- It's populated with results from GetItem and BatchGetItem
- It has a 5-minute default TTL
- Query cache:
- It stores results of Query and Scan operations
- It caches based on the parameters specified
- Item cache:
ElastiCache
- It's a managed In-Memory Key/Value store
- It supports the Redis or Memcached engines
- It was historically used with DynamoDB
- It's designed to operate with other products (outside of DynamoDB)
- Latency: sub-millisecond
Session management
- Client-side cookies
- Sticky Session on a CLB
- Distributed Session Management: In-Memory Key/Value store (ElastiCache)
- More details

Consistency
- DAX provides eventual consistency read
- ElastiCache for Redis ?
- ElastiCache for Memcached ?
Resilience
- DAX is HA (multi-AZs)
- ElastiCache for Redis supports replication (read replicas)
- ElastiCache for Memcached doesn't support replication
Use Cases
- Session management
- DAX:
- Application that require microseconds response for reads
- Read attensive applications and we don't want to allocate its DynamoDB with a high RCU level
- Online stores during busy sale periods or popular products
- Applications that require eventual consistent read
- Antipatterns:
- Applications that requires strongly consistent reads
- Application that don't require microseconds reads: optimizing our app. access pattern may be needed
- Write intensive Applications
- Legacy applications that already use a different caching solution: they won't get any benefit from DAX without significant retouling (refactoring)
- Existing applications that aren't compatible with DAX
- ElastiCache:
- Offloading database reads by caching responses, improving application speed and reducing costs
- It stores user session state: allowing for stateless compute instances (used for fault-tolerant architectures)
- It's generally used with key value databases
- But it can be used with SQL database engines
Description
- An Elastic Load Balancer (ELB) is a AWS load balancer(LB) provided as a service
- It's highly available and scalable
- It's designed to help balance the network load across multiple web servers
- It's typically used for internet facing application
- It can also be an internal load balancer
- It has a DNS record: it allows access at the external side
- It's can be configured which protocol and port it will listen to
Architecture
- A node is placed in each AZ the ELB is active in
- ELB DNS record automatically points at each of the individual ELB nodes
- Each node gets:
- 1/N of the traffic (N the number of nodes)
- a Private IP @ in case of an internal only LB and an internet facing LB
- a Public IP @ in case of an internet facing LB
Cross Zone Load Balancing
- Each node could LB across multiple AZ
- It's enabled by default
- Historically, it wasn disabled by default
- Each node could only LB to instances in the same AZ
- It resulted in uneven traffic distribution
- If 2 nodes (1st node AZ: 5 instances; 2nd node AZ: 1 instance)
- 1st node instances receive 10% of the total traffic
- 2nd node instance receives 50% of total traffic
Health Check
- It can be configured to check the health of any attached services
- If a problem is detected, incoming connections won't be routed to instances until it returns to health
X-Forwarded-For header
- It let the web server get the actual public customer IP @ (X-Forwarded-For header)
- The LB is passing its own internal IP address to the web server (EC2 instance)
- The EC2 instance is logging the internal LB IP @ as end-users IP @
- It could be annoying because we might want to know end-users actual IP @
Sticky Session
- It's also known as Session Affinity
- It's available with CLB, only
- It allows to bind a user's session to a specific EC2 instance
- In other words, the CLB is going to stick a user's session to a particular EC2 instance
- It sends a user's requests to the same EC2 instance during a session
- It makes web servers stateful
- Pros:
- Sessions are stored within a web server:
- It eliminates network latency: retrieval of sticky sessions is generally fast
- It's cost effective: we're using an instance as both a web server and a caching solution
- Sessions are stored within a web server:
- Cons:
- Resiliency: in the event of a failure, it's likely to lose the sessions that are stored on the failed node
- Scalability: in the event of scale-out scenario (number of web servers increase):
- It's possible that the traffic may be unequally spread across the web servers as active sessions may exist on particular servers
- It can hender the scalability of an application
- For more details
Classic Load Balancer (CLB)
- It's the legacy Elastic Load Balancer: NOT recommended for new projects
- It's Layer 3 & 4 device:
- It supports TCP and SSL/TLS protocols
- It supports 1 SSL certificate per CLB:
- It means that every single app. that we deploy into our environment needs its own CLB
- For 10 websites hosted with their own DNS name and SSL certificate, we need 10 CLB
- It can offload SSL connections: receives HTTPS and forward it to backend as HTTP
- It supports some HTTP/HTTPS feature:
- It'sn't application aware (not a layer 7 device) but
- It supports some HTTP/HTTPS features: "X-Forwarded" and "Sticky sessions"
- It supports health checks for HTTP/HTTPS (see health checks)
- Listener Configuration allows
- To configure which protocols and ports to listen to
- To configure which protocols and ports to use to communicate with backend instances
- It can be associated with Auto Scalling groups
- DNS A Record is used to connect to the CLB
- Health checks:
- It can be TCP, HTTP, HTTPS and, SSL based on ports 1-65,535
- HTTP/S checks: a HTTP/S path can be tested
- Ping Protocol (E.g., HTTP); Ping Port (E.g., 80); Ping Path (E.g., /index.html; /index.php)
- Response Timeout; Interval; Unhealthy threshold; Health treshold
- Sticky session:
- It's available
- It sends traffic to an EC2 instance
- SSL offloading:
- The CLB accepts connections on HTTPS on port 443 (SSL certificate is applied) and
- The CLB uses HTTP on port 80 to communicate with underlying instances
- The CLB handles all the encryptions and /decryptions
Application Load Balancer (ALB)
- It's a OSI model layer 7 device:
- It understand HTTP/HTTPS
- It can LB based on this protocol layer
- It's Application aware
- It sees inside the application (even sees the html) and then makes advanced rooting
- It's now the recommended as the default LB for VPCs
- It support IPv4 and IPv6
- It can host multiple SSL certificates using SNI
- It supports EC2, ECS, EKS, Lambda, HTTPS, HTTP/2 and, WebSockets
- It can be integrated with AWS Web Application Firewall (WAF)
- Listener Configuration allows to configure the ALB which protocols and ports to listen to
- Target Group allows to configure which target type/protocols and ports to use to communicate with backend:
- Target Type: Instance, IP, Lambda Function
- Protocl and Port
- It's almost always cheaper that CLB
- Contant Rules:
- It can direct certain traffic to specific target groups:
- Host-based rules: Route traffic based on the host used
- E.g.,
- It can direct traffic of "cats.com" to CAT target group (this target group would contain instance with a specific app. for cats)
- It can direct traffic of "dogs.com" to DOG target group (this target group would contain instance with a specific app. for dogs)
- Path-based rules: Route traffic based on URL path
- E.g.,
- It can direct traffic of "pets.com/cats" (/cats/*) to CAT target group (this target group would contain instance with a specific app. for cats)
- It can direct traffic of "pets.com/dogs" (/dogs/*) to DOG target group (this target group would contain instance with a specific app. for dogs)
- Default rules: used when no rules applies
- E.g., "pets.com"
- Health checks:
- It can be HTTP or HTTPS
- Ping Protocol (E.g., HTTP); Ping Port (Traffic port or Override Port); Ping Path (E.g., /index.html; /index.php)
- Response Timeout; Interval; Unhealthy threshold; Health treshold; Success Code (E.g., 200)
- Sticky session:
- It's available
- It sends traffic to the target group level
- SSL offloading:
- The ALB listener Configuration is set up to protocol/port HTTPS on port 443 (SSL certificate is applied)
- The ALB Target Group is setup to HTTP on port 80 to communicate with its backend
Network Load Balancer (NLB)
-
It's a OSI model layer 4 device:
- It doesn't touch any data inside packets above layer 4
- It forwards upper layers unchanged
- It can support any protocols based on TCP or UDP
-
It's fastest ELB:
- It's capable of handling millions of requests/s while maintaining ultra low latency
-
It can allocate static IP @: it's easier to integrate with any security or firewall products
-
It supports registering targets outside of a VPC
-
It supports routing requests to multiple app. on a single EC2 instance:
- It can register each instance or IP @ with the same target group using multiple ports
-
It supports containerized applications
-
Sticky session: It's NOT available
Scalability
- See Auto Scalling Groups below
Security
- Security Group:
- LB SG will allow protocols/ports it's listning to
- Underlying backend instances could restrict traffic for LB SG only
- Listener Configuration (Encryption)
Monitoring
- Gateway Timeout - Error 504:
- If an application stops responding the ELB responds with a 504 error
- It means that the application is having issues but it's not the LB
- It could either be at the web server layer or the db layer that's having issues
- We need to identify where the application is failing and scale it up or out where possible
Pricing
Use cases
- Internal LB (Scheme):
- It's generally used between tiers of an application (frontend tier, application tier)
- It abstracts tiers away from each other
- A frontend web server will send a request to the internal LB
- The internal LB will forward it towards a specific app. server
- The frontend web server won't care wich app. server it's talking to
- It's generally used between tiers of an application (frontend tier, application tier)
- Internet facing LB (Scheme)
- It's generally presented at the front of an application stack
- It sits between an app. and its users/customers
- It abstracts away from our underlying infrastructure
- A customer doesn't need to care how many EC2 instances we have providing our app
- It's generally presented at the front of an application stack
- CLB:
- If we don't have access to VPC: So we need to deploy it into EC2 classic situations (legacy method of configuring EC2 instances)
- Apps. with Round-Robin Load Balancing:
- They don't really care about how traffic is routed
- They're depending on region/language/currency (same across all web servers)
- ALB:
- It's the default choice
- If we need to use containers or microservices
- A multilanguage web app:
- E.g., French and English
- If language is switched from English to French, the ALB sees that
- It loadbalances across all the French web servers
- A Multi-Currency website:
- Same idea as the previous use case
- E.g., $ and €
- If USD is selected as a currency, the ALB sees that and loadbalances across the USD servers
- NLB:
- When supporting other protocol than HTTP/HTTPS is required (it forwards upper layers unchanged)
- and extreme performance is required
- and we need to forward request's packets without any modification
Limits
- SSL certificate #:
- 1 per CLB
- ALB: it uses SNI (see SNI limit)
- per NLB
Best practices
- To offload SSL if it's not requested to complete encryption from start to finish:
- It reduces admin overhead: backend instances don't need to configure and install SSL certificate
- It reduces the CPU cycles required on backend instances: They don't need to perform any encryption/decryption (Lower CPU)
- Backend instances could then be smaller and serve more customers
- To allow access to backend instances access from LB only:
- Backend instances could be associated with SG that are allowing traffic from LB's SG
- Because SGs are capable of being referenced from each other
- It's NOT recommended to use CLB
- It's a legacy LB
- It works with EC2 classic
- It's limited to 1 SSL certificate:
- It requires 1 CLB per website with DNS name and SSL certificate
- It becomes expensive when we have multiple websites with their own SSL certificate
Description
- It scales in and out automatically
- It uses "Launch Templates" or "Launch Configurations" to define the "What" instance to launch
- It defines "How" these instances will perform
- How they can scale: adding new instances (scaling out), removing instances (scaling in)
- Under which circumstances do we want these instances to scale out/in
- It uses some Configuration values:
- Minimum Size: the min # of instances to create (1 by default)
- Desired Capacity:
- It's the # that the ASG will attempt to aim for
- E.g., If we have currently 1 EC2 instance and the desired capacity is 2:
- The ASG will attempt to create a new EC2 instance
- To bring the # of running instances to the desired capacity
- Maximum Capacity:
- The maximum # of EC2 instances the group will ever grow to
- Even when every instance is completely overloaded, it won't grow beyond the maximum capacity
- It's as a cost control value
- We don't want to set it too low: it can impact the performance of our application
- We don't want to set it too high: it could massively increase costs
- Cooldowns:
- It's to ensure rapid in/out events don't occur
- It's avoiding experience significant costs (there's a minimum billing for EC2 instances)
- It puts like a pause timer between 2 consecutive scaling events
- If a scaling event happens, the following scaling events can occur for the cooldowns period
- 300 s is the default value
- It uses certain monitoring metrics
- to increase/decrease the desired capacity
- It either terminates instances when scaling in
- or it creates new instances when scaling out (using the launch configuration/template)
- in order to match its capacity
- It can be paired with an ELB:
- It's done by associating it with the ELB's Target Groups
- This allow to automate scaling and elasticity
- This enhances High Availability and fault tolerance
- When it's associates with an ELB, automatically
- The ELB associates itself with any instance inside the auto scalling group (scaling out)
- The ELB disassociates itself with any instance inside the auto scalling group (scaling in)
- FAQ
Architecture
Launch Configurations
- It's the 1st way to provision scaleable infrastructure
- Its typical configurations include:
- AMI to use for EC2 launch
- Instance type, storage, Key pair, IAM role, User data, Purchase options,
- Network configuration, Security Groups
- It can NOT be used to launch en EC2 instance
- It's an immutable object:
- It can't be edited after creation:
- Modification requires to create a Launch configuration
Launch Template
- It's the new version to provision scaleable infrastructure
- It addresses the weakness of Launch Configurations
- It adds the following features:
- Versioning and inheritance:
- We can create a base template
- Then we can enherit its settings and create new templates based on that base template
- Versioning and inheritance:
- It can be used to launch en EC2 instance
- It's an immutable object:
- It can't be edited after creation:
- Modification requires to create a new version or a new Launch Template
- Scaling Groups asks for
- Launch Template version: To select Default, Latest or, a specific version #
- Fleet composition: whether to adhere to "Launch Template" instances or Combine purshase options and instances
Lifecycle Hooks
- It puts the ASG's instances into a wait state before termination
- It allows to perform custom activities before instances are terminated
- Default Wait Period: 1 hour
- E.g., To retrieve critical operational data from stateful instances
- For more details
Scalability
- Auto Scaling group allows to automate the scaling in/out
- It modifies the default "Desired Capacity" entered when the Auto-Scaling Group is created
- It then create/remove instances based on the new "Desired Capacity"
- Scale in:
- Default Termination Policy:
- It's the process of removing instances during scale in
- It selects the AZ with the most instances with at least 1 instance isn't protected from scale in
- It selects the AZ with the instances that use the oldest launch configuration, if there's more than 1 AZ with this number of instances...
- Custom Termination Policy:
- It allows to replace the default termination policy
- It allows to add rules that aren't covered by the default Termination Policy
- E.g., To keep instances that have the current version of an application
- Protect From Scale in instance Protection:
- Newly launched instances will be protected from scale in by default
- Auto Scaling will not select protected instances for termination during scale in
- Controlling Which Auto Scaling Instances Terminate During Scale In
- Default Termination Policy:
- Scheduled Action:
- It automates the scaling in/out based on day/time and recurrence
- Input: Start Day/Time; Recurrence (every week; every day; every 5 mn); Max, Min and Desired Capacity
- E.g.:
- A website is busy at a certain point in the day or a certain periods during the week,
- "Schedule Action" will let us to automatically scale out and adjust the desired capacity based on the load that we expect during this period
- "Schedule Action" will also let us to automatically scale in after this period
- Scaling policy:
- It automates the scaling in/out based on measure that's monitored (E.g., CPU utilization)
- Simple scaling policy:
- It allows us to define a rule based on an alarm that we create
- Inputs: Alarm; Action; Cooldown (Health Check Grace Period)
- E.g., if AVG CPU utilization of all the instances > 50% (Alarm) => Add n instance(s) (Action) and wait 300 s (Cooldowns)
- E.g., if AVG CPU utilization of all the instances < 40% => Remove n instance(s)
- Step scaling policy:
- It allows to scale in/out differently based on measure ranges (E.g., CPU utilization)
- Inputs: Alarm; Steps: measure range, Action; Cooldown (Health Check Grace Period)
- E.g.,:
- Step 1: if 20% < AVG CPU utilization of all the instances > 30% => Add 1 instance and wait 300s
- Step 2: if 30% < AVG CPU utilization of all the instances > 40% => Add 2 instance and wait 300s
- Step 3: if 40% < AVG CPU utilization of all the instances > 50% => Add 4 instance and wait 300s
- Scheduled scaling policy:
- Target tracking scaling policy:
- It allows us to define a rule based on desired load
- Inputs: Metric type; Target value; Cooldowns
- E.g., We would like AVG CPU utilization of all instances (Metric type) of ~ 30% (Target value) and wait for 300 (cooldowns or warmup)
- If the AVG CPU utilization > 30%, it would create 1 or more instances to reach that desired load
- If the AVG CPU utilization < 30%, it would remove 1 or more instances to reach that desired load
- For more details:
Consistency
Resilience
- It can be configured to use multiple AZs to improve HA (high availability)
- It tries to even the instances # across it subnets (AZs)
Security
Monitoring
- Health check:
- It could be based on EC2 health check type: it uses the instance status and instance host status
- It could be based on an associated ELB health check
- Health Check Grass Period:
- It allows to enter the amount of time we should wait an instance to be ready
- EC2 instance may need some time to perform whatever auto-configuration
- 300 s the default period
- Unhealthy instances are terminated and recreated
- Metrics such as CPU utilization or network transfer can be used either to scale out/in
Pricing
Use cases
Limits
Best practices
- For new projects, it's recommended to use Launch Templates because they add significantly more functionaly
- Include a buffer in the Health check grace period
- High Availability, elastically scalling and self healing architecture:
- Elasticity: Launch Template + Auto Scaling Group + Scaling Policy
- Self Healing Architecture: Auto Scaling Group + ELB + ELB Health Check
Description
- It's also known as Hardware VPN
- It's a virtual network solution to connect a VPC to a non-AWS network such as on-premises networks
- It allows to access any remote VPC networks from on premises networks and vice versa
- It provides a fully encrypted transit path across the internet from our VPC to onpremise location
- Its tunnels operate over IPv4
- It's a highly available solution
- It can be configured to use either static or Border Gateway (BGW) routing
Architecture
- A Customer Gateway (CGW)
- Virtual Private Gateway (VGW) attached to a VPC
- A Virtual Private Cloud (VPC)
- VPN connection using 1 or 2 IPsec tunnels
- More details about the architecture
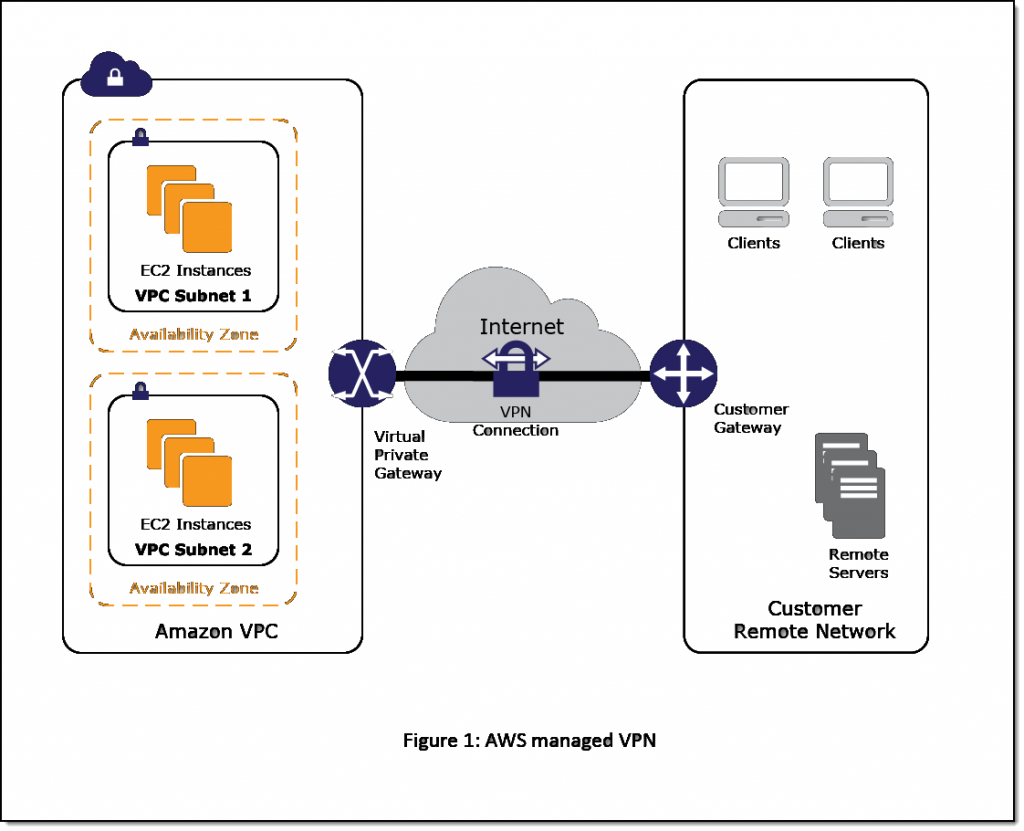
IPsec
Customer Gateway (CGW)
- It's a physical piece of hardware at the customer side
- It's generally a router
- It's capable of IPsec VPN connectivity using either static or dynamic routing
- It has a logical representation inside AWS (see VPC page > VPN seciton > Customer Gateways)
- Static Routing:
- It's the simplest form of routing within AWS VPN
- We simply have to tell either side of the VPN connection what subnets are available at the remote end of the connection
- Dynamic Routing:
- It uses BGP to dynamically exchange this routing information (subnets available either side of the VPN connection)
- It requires a BGP ASN (Autonomous System Number): it's a unique identifier for the BGP router at either side of the relationship
- If we don't have a BGP ASN allocated to our network, we can use a private ASN
- Private ASNs occupy the range of 64512 to 65534
- Static Routing:
Virtual Private Gateway (VGW)
- It's a gateway entity
- It's attached to a single VPC
- It's used by the VPC router via route tables to direct traffic towards
- It can act as the termination point for many different VPN connections:
- The VPN connections occur between 1 VGW and multiple CGWs

Site-to-Site VPN Connection
- It's the logical entity that links the VGW and the CGW
- It supports 2 different connection types
- Virtual Private Gateway
- Transit Gateway
Resilience
- Partially HA Architecture (in AWS side only):
- Use 1 VPN: it's HA by design
- Use 2 VPN connections
- Use 1 CGWs
- Create 2 tunnels
- Fully HA Architecture (fully mush):
- In both sides: AWS and Customer side
- Use 1 VPN: it's HA by design
- Use 2 VPN connections
- Use 2 CGWs
- Create 4 tunnels
- For more details
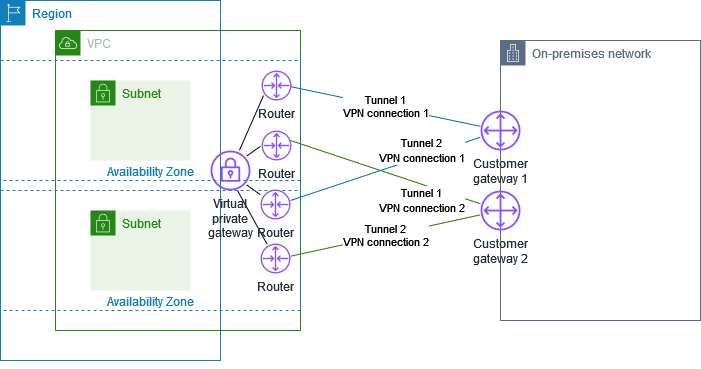
Security
- Encryption in transit:
- It provides a fully encrypted transit path across the internet from a VPC to an on-premise location
Monitoring
Pricing
- There's a per hour cost for running an active VPN connection +
- a data charge for any outgoing data
Use cases
- Pros:
- It's quick to set up: only few minutes are required
- It's cheap and economical particularly with low amounts of data
- It provides encryption end to end
- Flexibility to change location
- HA options are available
- Short term connectivity
- Cons:
- Data charge is higher than Direct Connect: this is why it's good for lowest loads
- The performance is limited by the CGW CPU capability (because of the encryption end to end) + Internet Performance
- Use cases:
- Urgent need
- Cost constrained
- Low end or consumer hardware
- It's good for Sporadic or low usage:
- It's good for a lower requirements or lower data transfer requirements
- It's NOT good for High load
Limits
Best practices
- Use dynamic VPNs (uses BGP) where possible
- Connect both tunnels to our CGW - VPC VPN is HA by design
- Implement a full HA Architecture (in AWS and Customer sides):
- Use 1 VPN: it's HA by design
- Use 2 VPN connections and 2 CGWs, where possible
- Create 4 tunnels
- For more details
Description
- It's a physical connection between a customer's network and AWS
- It's a physical connection because it's not a software-based connection as a VPN (see above)
- It uses cross-connect, a single-mode fiber, a physical piece of notworking cable
- It's at a DX location between an AWS router and a another router at a DX location:
- It's Direct if a customer router is connected to an AWS router at a DX location
- It's via a partner router that is connected to an AWS router at a DX location
- DX locations are distributed globally
- It's a high-speed, low-latency physical connection:
- It runs either 1 Gbps using 1000Base-LX or 10 Gbps using 10GBASE-LR
- It provides a dedicated connection
- It provisions a dedicated port on 1 of AWS edge networking devices
- It doesn't share bandwidth or speed
- It doesn't contend with customer's existing internet connections
- It provides access to public and private AWS services from a customer business premises
- It requires:
- To have equipement located at one DX location or
- To have an arrangement with a DX partner
- To have higher cost routers because it requires to use BGP protocol
Architecture
- DX location
- VIF: Virtual InterFace
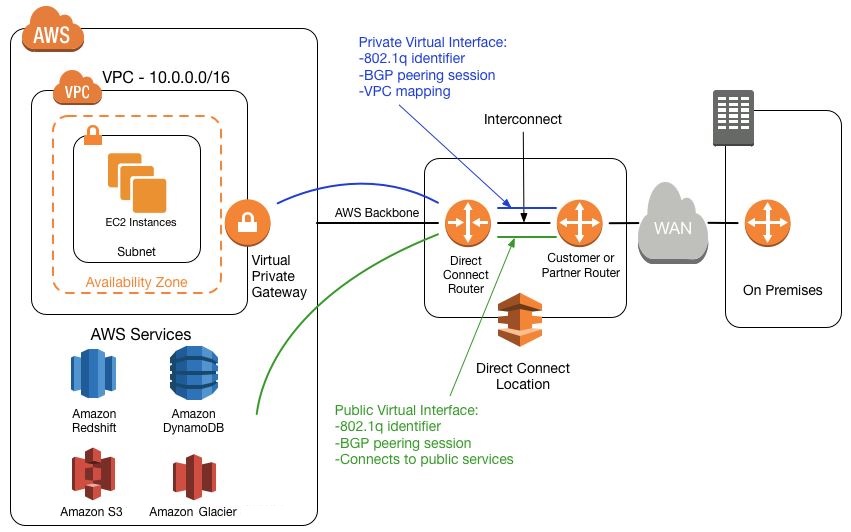
DX Locations
- They're distributed globally
Virtual InterFace (VIF)
- It run on top of a DX
- It's possible to have multiple VIFs running on top of a single Direct Connect
- Public VIF:
- It allow to access AWS public services from on premises networks
- E.g., S3, DynamoDB, SQS, SNS
- Private VIF:
- It's used to access into a VPC from on premises networks
- It could be associated to 0 or 1 VPC
- It works like a VPN
- It requires to be associated with a VGW that is attached to the VPC we would like to connect to
Consistency
- It's a consistent low latency connection
- It uses a dedicated cable
- It doesn't have to traverse the public Internet: no high/low ping time variances
Resilience
- It's NOT highly available because it's a single physical connection
- Solution:
- To provision an additional DX or
- To use a VPN connection as a backup
Security
- Encryption in Transit:
- It's NOT encrypted for private and public VIFs
- To use an encryption at application level (HTTPS) or
- To run a VPN connection over the top of a Public VIF running on a Direct Connect connection:
- A public VIF would grant access to public AWS services
- A public VIF could be used with VGW:
- VGW's endpoints are public space services
- We could then create an IP set VPN over the top of that public VIF to the endpoints of this VGW
Monitoring
Pricing
- Initial Set up cost +
- Data transfer charge (cheaper than data transfer with a VPN)
Use cases
- Pros:
- Higher throughput: It gets a full speed (1Gbps or 10Gbps)
- Consistent performance (throughput)
- Consistency low latency: it uses a dedicated cable (it doesn't have to traverse the public Internet)
- Cheaper than VPN for higher volume
- No contention with existing internet connection
- Cons:
- Longer to set up (days, weeks, months) but while we're waiting, we could use 1st a VPN
- More Expensive to set up
- HA connection is more expensive (2 DXs)
- It requires higher end hardware (because of BGP)
- There is no flexibility to change locations
- Use Cases:
- Situations where we need speed and performance consistency
- Applications that are very latency sensitive
- E.g., IP telephony or scientific applications that use real time telemetry
- E.g., Application for trading activities or financial analysis
- Situation where we need to transfer Large amounts of data
- DX + VPN:
- VPN as a cheaper HA option for DX
- VPN as an additional layer of HA (in addition to 2 DXs)
- If some form of connectivity is needed immediately, VPN provides it before the DX connection is live
- VPN can be used to add encryption over the top of a DX (public VIF VPN)
- Situations where we need speed and performance consistency
Limits
Best practices
Description
- It's a secure data transfer server in and out of AWS
- It solves challenges of large-scale data transfer: cost, long transfer times, and security concerns
- It doesn't need VPN or DX connection
- It requires
- To log an in or out job in AWS: An empty or full device is received
- To perform a data copy in or out to/from the device
- To ship the device back to AWS
- It provides 3 methods:
- Snowball
- Snowball Edge
- Snowmobile
- For more details
Snowball
- It can be used for in or out jobs
- It includes Storage only
- It comes in:
- 50 TB (42 TB of usable capacity) available only in the US regions (what about Canada?)
- 80 TB (72 TB of usable capacity) available worldwide
- It runs either 1 Gbps using RJ45 1GBase-TX or 10 Gbps using a LR/SR SFP (a fiber)
- It provides Data encryption using KMS
- Large jobs or multiple locations can use multiple Snowballs
- End-to-end process time is low for the amount of data: Weeks
- It provides AWS S3 adapter:
- It's a tool to install on the device
- It allows to configure the device like an AWS CLI, use it as an S3 endpoint and, transfer data directly
Snowball Edge
- It can be used for in or out jobs
- It includes Storage and Compute
- It comes by default with 100 TB (83 TB of usable capacity)
- It comes in 3 versions:
- Edge Storage Optimized: 80 TB, 24 vCPU and, 32 GiB RAM
- Edge Compute Optimized: 100 TB + 7.68 TB NVMe, 52 vCPUs and, 208 GiB RAM
- Edge compute Optimized with GPU: as above with a GPU equivalent to P3 EC2 instance
- It runs either:
- 10 Gbps using RJ45
- 10/25 GBase using a LR/SR SFP (a fiber)
- 45/50/100 Gbps using a QSFP+ (a fast fiber): requires a hardware on site to take advantage of it
- It provides AWS S3 adapter (see Snowball)
- It provides additionally a file interface:
- It allows to essentially present storage through AWS NFS
- It can be mounted as an NFS mount points on servers where to transfer directly data into
Snowmobile
- It can be used for in or out jobs
- It's a portable storage data center within a shipping container on a truck
- It's available in certain areas via special order from AWS
- It comes with up to 100 PB
Pricing
Use cases
- We have a large amount of data and a limited internet bandwidth:
- Cost requirements: No economical to use the Internet (transfer costs)
- Time requirements: if transferring data over the internet would take longer than required time (prohibitive)
- E.g., Migrate database in premise to AWS cloud
- Snowball use cases:
- Economical range: It's generally used from 10 TB to 10 PB
- Snowball Edge use cases:
- Economical range: 10 TB to 10 PB? with compute requirement
- When Multiple locations are required
- It can be used for local IoT
- It can be used for data processing prior to ingestion into AWS
- When usd as temporary storage tier for large locale datasets
- When used to support local workloads in remote or offline locations (see exemple below)
- E.g. of a major airline:
- It uses a Snowball Edges in its aircrafs to store and compute (lambda functions) all data
- got while it's doing lot of testing of its aircrafts
- Snowmobile use cases:
- Economical range: 10 PB+ is required in a single location
- When it's used in a single location
Description
- It's a software appliance to connect on-premise servers to S3:
- It's installed and run on an on-premise
- It's available for download as a VM image
- It can be run on VMWare ESXi or Microsoft Hyper-V 2008 R2, Hyper-V 2012/2016
- It can also be run on the hardware appliance???
- It could also be run on an EC2 instance
- It allows to migrate a storage platform (or part of it) into AWS
- It allows to use it as extension to an on premises storage platform
- It's created via AWS management console
- It can also be used within a VPC in a similar way
- It comes with 3 types:
- File Gateway (NFS & SMB)
- Volume Gateway (iSCSI)
- Tape Gateway (VTL)
Architecture

File Gateway
- It presents its storage as SMB shares
- They're the type of shares that are used for Windows file servers
- It stores files as objects in S3 buckets
- Files uploaded in these shares are directly stored in S3
- Files are accessed through a NFS mount point
- File Ownership, permissions, and timestamps are durably stored in S3 in the corresponding S3 object user-metadata
- Once files are stored in S3, they can be managed as native S3 files
- It allows to migrate existing file servers into S3 on a gradual basis
- It allows to benefit from unlimited space available in S3 and use it as an extension of on-premise storage
Volume Gateway (iSCSI)
- It's a way of storing volumes in S3 in a form of EBS snapshot
- It uses iSCSI protocol (Internet Small Computer Systems Interface) to access these volumes
- We can't access the files individually without mounting the entire volume
- It asynchronously backes up data written to such volumes as point in time volume snapshot
- It stores these volumes in the cloud as an Amazon EBS snapshot
- It stores them incrementally (backups that capture only changed blocks)
- It compresses snapshot storage to minimize storage charges (see S3)
- Stored Volumes:
- It allows to keep our primary data on-premise while it's backed in S3 in a form of EBS snapshot
- It allows on-premise applications a low-latency access to theirs datasets while they're backed up in AWS
- EBS snapshot size currently is between 1GB to 16TB (it may change)
- Cached Volumes:
- It allows to keep on-premise the most frequently used dataset in our storage getaway
- It minimises the need to scale our on-premise storage infrastructure
- While It's still providing our apps with the low-latency access to their frequently access data
- We can create storage volumes of up to 32 TB and attach then as a device from our on-premise app. servers
- For more details


Tape Gateway (VTL)
- It stands for Virtual Tape Library:
- It's used typically for backup and recovery purposes
- It's a way of getting rid of tapes
- It lets leverage existing tape based backup application infrastructure to store data on virtual tape cartridges that we create on our tape gateway
- Each tape Gateway is reconfigured with a media change and tape drives which are available on our existing client backup applications as a iSCSI devices
- For more details
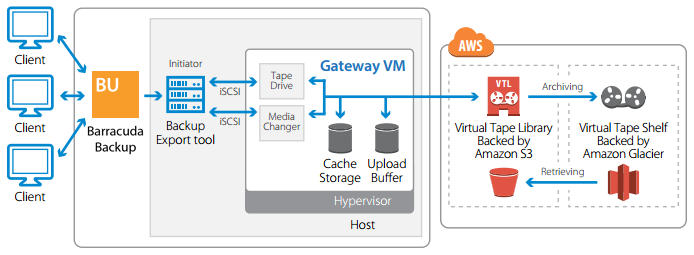
Use cases
- File Gateway:
- Storage migration into AWS: it allows to migrate existing file servers into S3 on a gradual basis
- Extension of existing storage platform with AWS: it allows to benefit from unlimited space available in S3
- Volume Gateway:
- VTL:
- We have a high admin overhead backup system, it's expensive
- We want to remove that from your local premises
Limits
- Table Name:
- Length: 3 characters to 255 characters long
- Allowed characters: A-Z, a-z, 0-9, _ (underscore), - (hyphen, . (dot)
- Attribute Name Length: 1 character to 64 KB long
- Exceptions: 1 to 255 characters long for:
- Secondary index partition key names
- Secondary index sort key names
- ... See details
- Exceptions: 1 to 255 characters long for:
- Attribute Values:
- String Max item size: 400 KB
- Binary max item size: 400 KB
- Number prcision: 38 digits (it can be positive, negative, or zero)
- If precision is important, we should pass numbers to DynamoDB using strings that you convert from a number type
- For more details
Best practices
Description
- It's a managed service capable of relation databases migration and schema conversion
- It can migrate to and from any locations with network connectivity to AWS
- It's compatible with a broad range of DB sources, including Oracle, MS SQL, MySQL, Maria DB, PostgreSQL, MongoDB, Aurora and, SAP
- It can sync data to AWS RDS, Redshift, S3 and, DynamoDB
- It provides a "Schema Conversion Tool" (AWS SCT) to transform between different db engines as part of a migration
- It allows to avoid db migration overhead and outage during the migration process:
- The usual migration requires:
- Stop all input and output on the existing db
- Perform a full backup of that db
- Store the backup somewhere else
- Do a restore, and
- Change all of our applications which utilize that db to point at the new endpoint
- It does require a full outage during the migration process
- It could take days (weeks) for large databases
- The usual migration requires:
- It allows to do replication with little downtime
- It generally involves some form of replication,
- So you have to configure a replication between a source and the destination
- allow that replication to take all of the existing data and bring the databases into parity and then migrate any new transactions from the source to destination
Architecture
Schema Conversion Tool (AWS SCT)
- It's to transform between different db engines as part of a migration
Pricing
Use cases
- When scaling db resources up or down without downtime
- When migrating dbs from on-premises to AWS, from AWS to on-premises or to/from other cloud platforms
- When moving data between different DB engines, including schema conversion
- When migrating partial/subset data
- When wanted a data migration as a service with little to no admin overhead
Limits
Best practices
Description
- It's an AWS Web IDentity Federation service
- It allows to sign up and sign in to an apps
- It acts as an identity broker between our application and a Web I.D
- It uses Token Service (STS) to provide temporary credentials which map to an IAM role
- It allow to synchronize our users data for multiple devices
- IDentity Federation (IDF): It's an architecture where identities of an external identity provider (IDP) are recongnized
- IDentity Provider (IDP):
- It has an identity internally for customers
- It uses this identity to log on to their platform
- It offers this identity as a service for other platforms to use it as an external identity
- Google mail
- Canadien banks
- Microsoft Active Directory
- Single Sign-On (SSO):
- It's where the credentials of an external identity are used to allow access to a local system like AWS
- For more details
- E.g. Service Canada website asks to sign in with a canadian bank for authentification purposes
- IDF types:
- Cross-account roles: a
- A remote account (IDP) is allowed to assume a role and access our account's resources
- E.g. AWS IAM cross-account roles is a kind of IDF:
- We create a role in a 1st AWS account and
- We'll trust a 2nd account to be able to assume that role and perform actions in the 1st account
- SAML 2.0 IDF (Security Assertion Markup Language):
- It's a standard often used in on-premise systems with an Active Directory Federation Server (ADFS)
- E.g. 1, Microsoft Active Directory,
- E.g. 2, AWS-hosted directory service: is configured to allow Active Directory users to log in to the AWS console
- For more details about SAML 2.0
- Web Identity Federation:
- It's where we use IDP and we allow them to assume roles and access resources in our AWS account
- Identity Federation Playground
- Cross-account roles: a
- IDF Process:
- It's the same process for all IDF types
- A user logs in to an extenal IDP
- The IDP returns a proof of successfull loggin:
- a SAML assertion in case of SAML 2.0 IDF (Microsoft Active DIrectory or AWS-hosted directory service)
- a Token in case of Web Identity Federation (Google, Facebook, Twitter)
- The proof is exchanged with AWS credentials (STSTemp Credentials)
- These credentials are used to access AWS Services

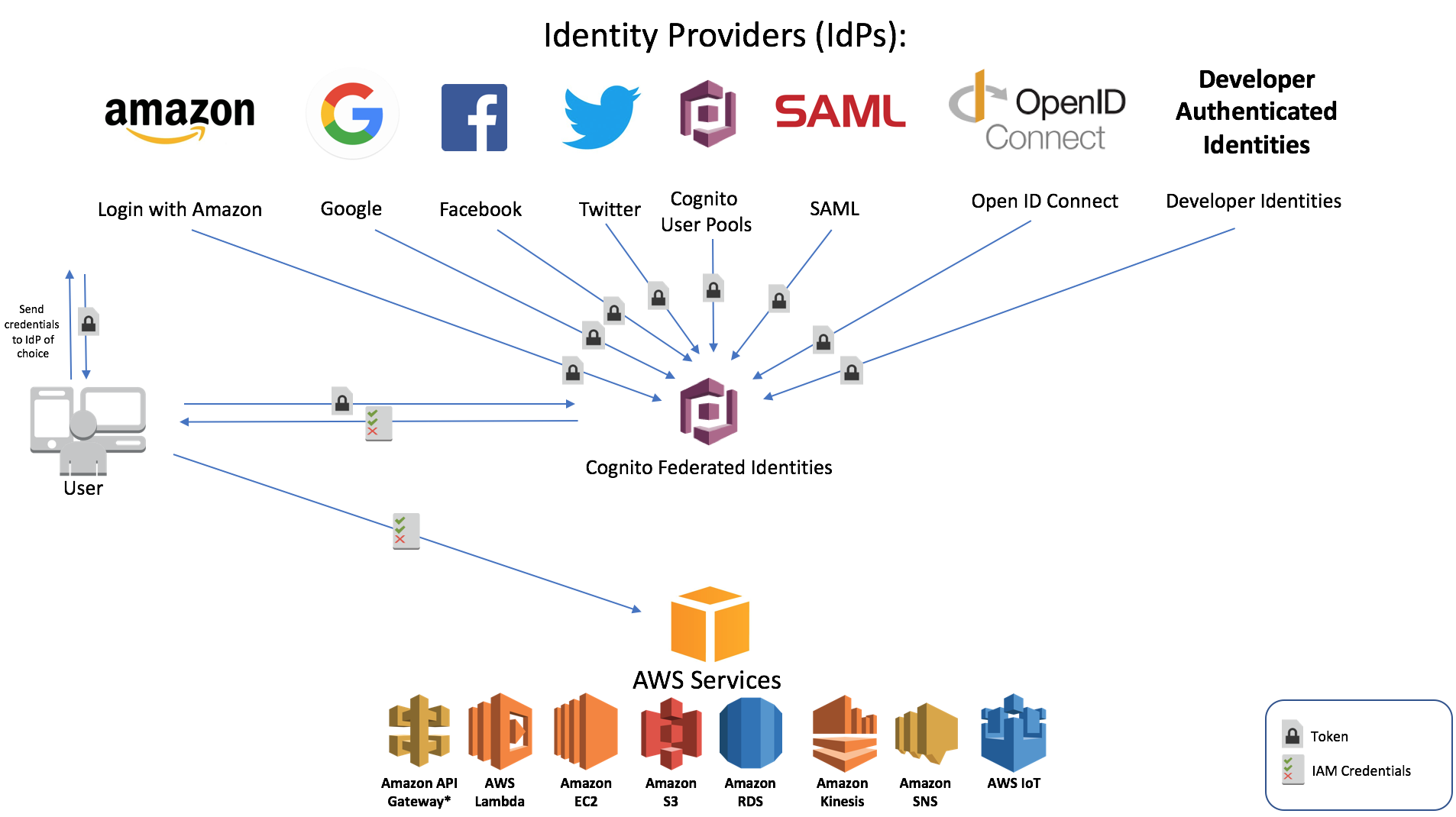
Architecture
- Cognito user pools
- Cognito identity pools
- Token Service (STS)

Cognito user pool
- It's an identity directory
- It merges all identities from different IDPs (Google, Facebook, Twitter, etc.) and considers them as one individual identity
- It generates a Jason Web Token (JWT) for successful authentication:
- It's not possible to access AWS Service (S3) directly using an external IDP (E.g., Google login)
- There is an identity exchange (JWT)
- It uses STS to provide temporary AWS credentials to access AWS services
- Use cases:
- To Use it as an IDP: Users' usernames and passwords are stored with Incognito itself
- To use it as an identity broker for a 3rd party IDP
Cognito identity pool
- It's about the authorization of access to AWS resources
- It's the actual granting someone access to an AWS resource
Cognito Synchronization
- It maps a user identity with their different devices they signed in from
- It pushes updates and synchronizes user data across multiple devices
- It uses AWS SNS to send notifications whenever there is a change with a user identity
- It allows to provide a seamless user experience for applications
- E.g., a user is using an application on different devices (Phone, Tabet)
- They change a username/email address on one the mobile phone
- Those changes will be replicated out to theirs other devices (tablet)
Security
- See STS description in AWS IAM section
- For more details:
Pricing
Use cases
- Entreprise Access to AWS Resources:
- Users/Staff have an existing pool of identities
- We need those identities to be used across all entreprise systems, including AWS
- Access to AWS resources using SSO
- Potentially tens or hundreds of thousands of users - more than IAM limit
- We might have an ID team within our business
- Mobile and Web Applications:
- Mobile or web application requires access to AWS resources
- We need a certain level of guest access and extra once we're logged in
- Customers have other identities and need to use those - google, Twitter, Facebook
- We don't want credentials stored within the application
- Could be millions or more users - more than IAM limit
- Customers might have multiple 3rd-party logins, but they represent one real person
- Centralized Identity Management (AWS Accounts):
- Tens or hundreds of AWS accounts in an organization
- Need central store of IDs - either IAM or an external provider
- Role switching used from an ID account into member accounts
Limits
Best practices
Description
- It's a publisher-subscriber based service
- It coordinates and manages the sending and delivery of messages
- It's a regional service
- It's a public AWS service:
- It has a public endpoint
- It could be accessed from a VPC with either an Internet Gateway + a NAT Gateway or a VPC endpoint
- It could be accessed from any other location with a public Internet connection (on-premise locations)
- Its based entity is a Topic:
- A publisher sends a message to a topic
- The message is delivered to all Subscribers of the topic
Architecture
- It's basic architecture is:
- A publisher sends a message to a topic
- By default, the message is delivered to all Subscribers of the topic

Topic
- It's the base entity of SNS
- It's created inside a region
- Its message max size is 256 KB
Publisher
- It's an entity that publishes/sends messages to a topic
- It could be different entities
- E.g. 1, CloudWatch can publish alarm notifications
- E.g. 2, CloudFormation can publish event updates when a stack is created, updated or, deleted
- E.g. 3, Custom applications can push mobile notifications to theirs customers
- E.g. 4, A user who's using the CLI tool or the console
- Publishing Playload:
- It allows to customize a playload based on subscriber endpoints protocol
- Identical playload for all delivery protocols:
- It's the default option
- It's allows to send the same payload to all endpoints subscribed to a topic, regardless of their delivery protocol
- Custom payload for each delivery protocol
- It allows to define different payloads to be sent to endpoints subscribed to the topic, based on their delivery protocol
- E.g., Define a message for HTTP/HTTPS endpoints, a different one for Lambda endpoints and a default payload for all other protocols
Subscriber
- It's an entity that a message in a topic is delivered to
- It could be:
- An HTTP or HTTPS endpoints:
- E.g. API endpoints
- Email endpoints:
- It delivers the message as a raw email
- E.g., It delivers notifications by text message (SMS) or email to SQS queue, or to any HTTP endpoint
- It delivers the message as a raw email
- Email-Json endpoints:
- It delivers the message as a Json version
- Amazon SQS:
- It delivers the message in an SQS queue
- Lambda Function:
- It delivers the message to a Lambda function that is invoked
- It's for a serverless architecture
- It requires a processing time under 15 minutes
- SMS endpoint:
- It delivers the message as a text message
- E.g., an notification platform that has engineers subscribed
- Example 1: We could group together iOS, Android and SMS recipients
- When we publish once to a topic, SNS delivers appropriately formatted copies of our message to each subscriber
- Example 2: Billing Alarm top, Performance Alarm topic, Health Alarm topic
- A protocol is associated with a subscriber (SMS, email, email Json, HTTP, HTTPS, SQS)
- Platform application endpoint
- It delivers the message as a push notification to subscribed mobile platforms
- An HTTP or HTTPS endpoints:
- Subscription filter policy:
- It allows to filters messages that a subscriber receives
- It means that the filter logic is done on the topic
- By default, a message is delivered to all Subscribers of the topic (see the basic architecture above)
- It allows to avoid subscribers to receive irrelevant messages
- It allows to reuse 1 topic for different functions
- For more details

Scalability
- It's a fully managed service
- It can scale to any required load level
Consistency
Resilience
- It's highly reliable product
- It's resilient across all AZs in a region
- Its messages are stored redundantly across multiple AZs
- Delivery retry policy
- It defines how SNS retries failed deliveries to HTTP/S endpoints
- The settings are:
- Number of retries (3 by default),
- Retries without delay (0),
- Minimum delay (20 s),
- Maximum delay (20 s),
- Minimum delay retries,
- Maximum delay retries
- Maximum receive rate
- Retry-backoff function (Linear)
- Override subscription policy (False)
Security
- Access Policy:
- It's a ressource policy on a topic
- It defines who can publish and subscribe to a topic
- Publish access policy:
- By default, only the topic owner can publish or subscribe to a topic
- It's possible to give access to Everyone, Specific AWS accounts
- Suscrib access policy:
- By default, only the topic owner can publish or subscribe to a topic
- It's possible to give access to Everyone, Specific AWS accounts, Requesters with certain endpoints
- Encryptions:
- Encryption at Rest by using AWS KMS
- Encryption in Transit by using SSL/TLS?
Monitoring
Pricing
Use cases
- Fanout architecture (see SQS use case description)
Limits
- A topic message max size: 256 KB
Best practices
Description
- It's a queuing system (the 1st AWS service)
- It provides fully managed, highly available message queues
- It allows asynchronous processing:
- It allows to decouple components of an application so they run independently from each other
- It's a regional service
- It's a public AWS service:
- It has a public endpoint (URL)
- It could be accessed from a VPC with either an Internet Gateway + a NAT Gateway or a VPC endpoint
- It could be accessed from any other location with a public Internet connection (on-premise locations)
- SQS Message
- It can be in any text format up to 256 KB
- It could be bigger: it's stored in S3 and its location is added to SQS queue
- It's composed by:
- Body: the data that is queued
- ReceiptHandle: it's a unique ID for the message
- MD5OfBody:
- MessageId:
- It's added to a queue
- It's polled by a worker or a consumer by using Amazon SQS API
- It's retained for a retention period
- By default, it's retained for 4 days
- The minimum is 1 minute (60 s)
- The maximum is 14 days (1,209,600 s)
- It's deleted from the queue when it's processed by the worker that polled it
- It requeres the queue URL and the message ReceiptHandle
Architecture
Polling
- It's a single API call to retrieve a message from a SQS queue
- It allows to define how many messages to retrieve (max is 10)
- It has 2 types:
- Short polling:
- It's the default way
- When a poll request (ReceivedMessage) is sent, a response is returned immediately
- It may contain the messages that are available in the queue up to a maximum of 10
- It may contain 0 message if the queue is empty
- E.g. 1, a short poll is sent for 10 messages
- 12 messages are available in the SQS queue
- A response is returned immediately with 10 messages
- E.g. 2, a short poll is sent for 10 messages
- 6 messages are available in the SQS queue
- A response is returned immediately with 6 messages
- It causes increased number of API calls
- Long polling:
- When a poll request is sent, it waits for messages for a given WaitTimeSeconds
- In other words, when a poll request is sent, a response isn't returned until
- the number of requested messages arrive in the queue
- or the long poll connection times out
- It's more efficient
- It eliminates the number of
- Empty responses: it's when a queue is empty
- False empty responses: it's when messages are available but aren't included in a response (Messages are not visible or delayed))
- It helps to reduce the cost of using Amazon SQS
- It eliminates the number of
- Visibility Time Out
- It's the amount of time that a message is invisible in the queue after it's polled by a consumer
- If a polled message isn't deleted within that time, the message will become visible again for other consumers
- This could result in the same message being delivered twice
- For more details:
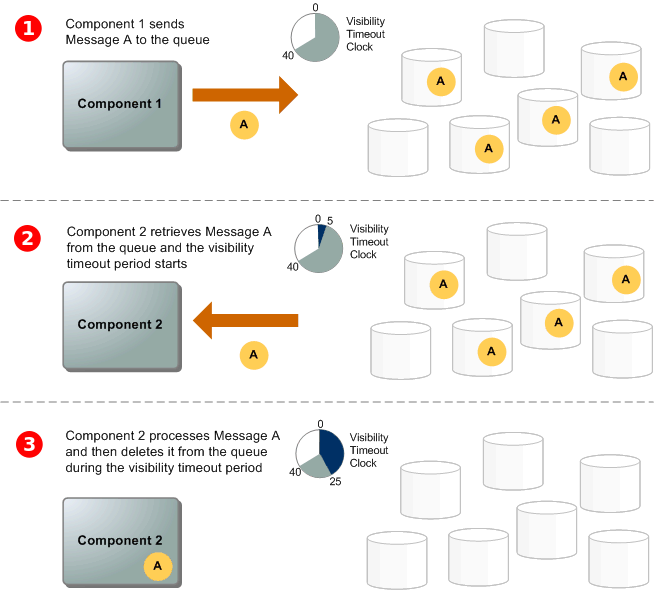
Queue Types
- Standard Queue:
- It's the default queue type
- It's highly-distributed and scalable to nearly unlimited message throughput (transactions per second)
- It guarantees that messages are delivered at least once:
- This means that a message could be delivered more than once
- It provides best-effort ordering:
- It ensures that messages are generally delivered in the same order as they're sent
- It's NOT guarantees
- This means that occasionally messages might be delivered out of order
- FIFO Queue:
- "First in, First Out" queue
- It guarantees that messages are delivered once and once only
- It guarantees that the order the messages are added to the queue will be the order they're delivered
- Its throughput is limited:
- 3,000 messages per second with batching
- ~300 messages per second without batching
- A message remains available until a consumer processes and deletes it
- Message Groups: allow multiple ordered message groups within a single queue
- For more details:

Scalability
Consistency
Resilience
Security
Ressource Policy: - It defines who has access to a queue - By default, only the queue owner has access to it
- Encryptions:
- Encryption at Rest by using AWS KMS
- Encryption in Transit by using SSL/TLS?
Monitoring
- It's done by AWS CloudWatch
- Some metrics are:
- NumberOfMessagesSent
- NumberOfMessagesReceived
- NumberOfMessagesDeleted
- NumberOfMessagesVisible
- NumberOfEmptyReceives
- ApproximateNumberOfMessages
- ApproximateNumberOfMessagesNotVisible
Pricing
Use cases
- Interprocess, interserver, or interservice messaging
- Asynchronous messaging architecture:
- When a producer (caller) is producing work faster than its consumer can process it
- When a producer or consumer are intermittently connected to the network
- Workers Pool Architecture:
- It allows to decouple components of an application:
- They run independently from each other
- They scale independently from each other
- They fail independently from each other
- E.g., an app. like YouTube
- People are uploading videos to this app
- The videos need to have some form of processing performed on them
- A frontend tier allows the user to upload the videos
- It's of EC2 instances which are under a ELB and an Auto Scaling Group
- It's fully scalable
- It stores these videos on S3 via a PUT API call
- S3 generates and sends a message to a SNS Topic:
- Once a video storage is completed, S3 generates an AWS SNS PUT notification
- This PUT notification is added to a SQS queue indicating that a video is ready to be processed
- At the backend, we have a fleet of EC2 instances + an ASG:
- This workers pool is scalled out by the ASG based on the number of messages in the queue
- The workers keep polling the queue above and process a message (video path to S3) as soon as it's received
- The workers put the result in S3
- This architecture means that the more video uploads we get (more customers), the more messages in the queue and the more instances inside this worker pool
- It auto scales based on demand and
- Overtime it reaches an equilibrium where video processing is occurring in a timely way
- This architecture also means is that the frontend and backend are decoupled from each other
- They work independently from each other
- They scale independently from each other
- They fail independently from each other
- It allows to decouple components of an application:
- Fanout architecture
- It allows to send a message to an SNS topic and fan it out to multiple queues for further processing
- E.g., an app. like YouTube:
- People are uploading raw media files to this app
- The raw media files are converted into different bit rate
- A frontend tier allows the user to upload the videos
- It stores these videos on S3 via a PUT API call
- S3 generates and sends a message to a SNS Topic:
- The message indicates the uploaded of a raw media file and its location on S3
- An identical copy of the message will be delivered to multiple queues subscribing to that topic
- Behind each queue, there's a worker pool that is dedicated for a specific converson
- Each worker fleet has multiple EC2 instances to convert the raw media file into a bit rate specific to a queue
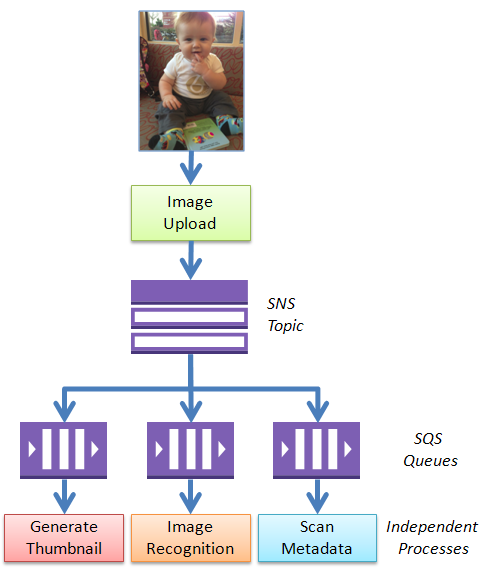
Limits
- SQS message max size: 256 KB
- SQS Extended Client Library size limit: Between 256 KB up to 2 GB
- Message retention maximum: 14 days (1,209,600 s)
- Message retention manimum: 1 mn (60 s)
- Max message # / Poll APP: 10
- Max message # / batch: 10
- FIFO Queue TPS (Throughput Per Second):
- 3,000 messages per second with batching
- ~300 messages per second without batching
- Visibility timeout maximum: 12 hours
Best practices
- To add a mecanism to check if a message is already processed
- For rapid and agile scalability, to use Lambda instead of a Worker Pool architecture (EC2 instances + Auto Scaling Group):
- When the processing time for the queue message is less than the maximum runtime of Lambda (15 mn)
- It's a media transcoder in the cloud
- It converts media files from their original source format into different formats that will play on smartphones, tablets, PCs, etc
- It provides transcoding presets for popular output formats: we don't need to guess about which settings work best on particular devices
- It also operates in a serverless fashion: we're not allocating the underlying infastructure that is used to transcode these files
- Pay based on transcoded minutes and the resolution at which we transcode
Description
- It's a platform on AWS to send our streaming data to:
- It's data that is generated continuously by thousand of data sources
- They typically send in the data records simultaneously and in small sizes
- Data size order: order of Kilobytes (small)
- E.g. 1: Purchase from online stores (amazon.com, for example): order is data piece
- E.g. 2: Stock prices
- E.g. 3: Gaming data as the Social network data, Geospatial data (Uber), IOT sensors data
- It makes it easy to load and analyze streaming data
- It provides the ability for us to build our own custom applications
- There're 3 Kinesis types: Kinesis Stream, Kinesis Firehose and, Kinesis Analytics
Kinesis Stream
- It's a place to store that data
- It stores the data for 24 hours (by default) and up to 7 days
- Data is contained in Shards:
- We might have a shard for different purposes
- We might have a shard for our geospatial data, our stock data, our social network, etc
- Reads: 5 transactions/s
- Maximum Total Read rate: up to 2 MB/s
- Writes: Up to 1,000 records /s
- Maximum Total Writes rate: up to 1MB/s. This is including partition keys
- Kinesis Stream data capacity:
- It's a function of stream's shards #
- Its total capacity is the sum of shards capacities
- Data consumers:EC2 instances that analyze the data inside those shards
- Once the data is analyzed and something is done with it, the data can then be stored in different places
Kinesis Firehose
- There's no persistent storage: the data has to be analysed as it comes in
- It's optional to have lambda functions inside
- Lambda function is triggered as soon as the data comes in
- Lambda function could run a particular set of code for that data
- Lambda function outputs it somewhere safe: S3 or Redshift via S3 though, Elastic Search Cluster
Kinesis Analytics
- It works with Kinesis Streams and with Kinesis Firehose
- It can analyze the data on the fly inside either service
- It stores this data either on S3, Redshift, or Elastic Search Cluster
Description
- It's a petapyte-scale data warehousing solution
- It's designed for OLAP-based transaction (OnLine Analytical Processing)
- It's a column-based database
- Data is stored in columns (as opposite of RDS that stores data in rows)
- Aggregation queries are fast
- Advanced data compression (see below)
- It could be provisioned on
- Ad hoc basis for a particular task or
- Only used when we require a warehousing functionality
- It can load/unload data from/to S3
- It can perform backups to S3
- It can be used as a target for many AWS products as a final data storage location:
- E.g., Kinesis, Kinesis Firehose, EMR
Architecture
- It uses a cluster architecture
- It could be configured as a Single Node or Multi-Node:
- More details
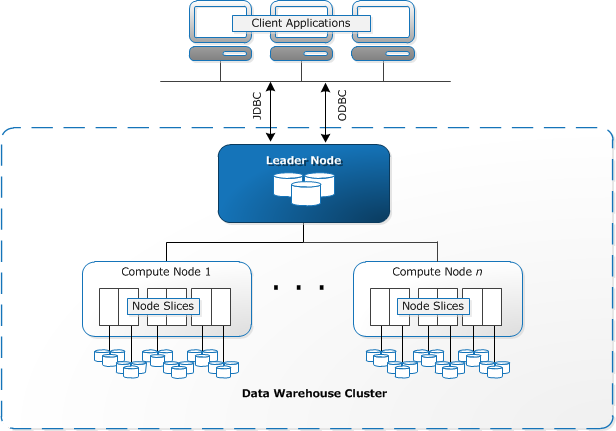
Multi-Node
- Leader Node:
- It manages client connections
- It receives queries
- It distributes queries across nodes
- It splits queries into individual components
- It allocates a component to a particular slice of a node
- Multiple compute nodes:
- They has slices of data
- They perform distributed queries on their sliced data
Compression
- It's a Columnar data store
- It compresses data much more than in row-based data stores because similar data is stored sequentially on disk
- It employs multiple compression techniques
- When loading data into an empty table:
- It samples data and
- It selects the most appropriate compression scheme
- It uses less space since it doesn't require indexes or materialized views
Enhanced VPC Routing
- It forces all COPY and UNLOAD traffic between a Redshift cluster and its data repositories through the associated VPC
- It allows to use VPC features, such as VPC security groups, network access control lists (ACLs), VPC endpoints, VPC endpoint policies, internet gateways, and DNS servers
- It allows also to use VPC flow logs to monitor COPY and UNLOAD traffic
- For more details
Scalability
- Massively Parallel Processing (MPP):
- It distributes data and query load across all nodes
- It makes it easy to add nodes to a data warehouse
Consistency
- It's strong consistent since it uses 1 AZ only
Resilience
- It's only available in 1 AZ
- It can restore snapshots to new AZs in the event of an outage
- It always attempts to maintain at least 3 copies of data:
- The original data
- a Replica on the compute nodes
- a Backup in Amazon S3
Disaster Recovery
- A backup is enabled by default with a 1 day retention period
- A backup maximum retention period is 35 days
- Snapshots can be asynchronously replicated to S3 in another region for disaster recovery
Security
- Encrypted in transit using SSL
- Encrypted at rest:
- It uses AES-256
- It takes care of key management
- It manages customer's own keys through KMS
- For more details:
Monitoring
Pricing
- Compute Node + Backup + Data Transfer
- Compute Node Hours:
- Total number of hours run across all compute nodes for the billing period
- We're billed for 1 unit per node per hour
- E.g., a 3-node data warehouse cluster running persistently for an entire month would incur 2,160 instance hours (3 x 24 x 30)
- Total number of hours run across all compute nodes for the billing period
- Leader node isn't charged
- Data transfer:
- only within a VPC (not outside it) • Backup
Use cases
- Athena:
- It's used for doing OLTP-type queries on data that's in S3
- It doesn't require to maintain a database infrastructure
- It doesn't require to load the data into Athena first
- It can query it directly from S3
- It's used for serverless querying
- EMR:
- It's used for a large scale analysis
- It's used to perform analytics and actual modification on data
- It's for Big Data: It's uses semistructured or unstructured data
- It's used for for on-demand EC2 billing:
- Its clusters are EC2s instance
- They can be spun up and terminated for short term or ad-hoc tasks,
- It utilizes on-demand billing
- RedShift:
- It's used as an end state repository and as a single location for data from different sources
- It's used for summarization, aggregations (analytical queries) on all of our data
- E.g. a large organization like Amazon.com:
- It might have hundreds or thousands of isolated databases around the organization
- It might be different engines, types of databases
- From amazon.com, Amazon Prime, Audio book purchases,
- RedShift might be the right solution to store all this data to perform some analytical style queries
Limits
- Single Node: 160Gb
- Max Compute Nodes #: 128
Description
- It provides near real-time monitoring of AWS services (performance purposes)
- It's a metrics repository
- It support customer metric data from some AWS services and on-premises platforms
- Its metrics is a collection of time ordered set of datapoints of specific type:
- E.g., CPU usage metric is a collection of datapoint of CPU usage
- Some metrics are captured by default:
- E.g. 1, External things of an EC2 instance: network usage, CPU usage
- E.g. 2, DynamoDB writes and reads
- E.g. 3, EBS volume writes and reads
- Some other metrics aren't captured by default:
- Internal to an AWS resource such as internal metrics of EC2
- On-premise or custom metrics
- CloudWatch agent or CloudWatch API allow to publish these metrics (see below)
- E.g. 1, Memory usage of an individual process in an EC2 instance
- E.g. 2, Overall memory utilization in an EC2 instance
- The capture frequency depends on AWS products:
- every less than every 60 seconds
- Every 1 minute
- Every 5 minutes: it's the default for EC2 instances
- ... etc
- They're grouped into namespaces:
- A namespace is a container of metrics
- E.g. AWS/EC2 namespace
- It can be configured with alarms:
- An alarm can trigger notification through SNS
- It can present data in a dashboard (Global or Regional)
- For more details:
Architecture

Data Retention
- Its retains datapoint for a certain period of time depending on how it's old:
- It aggregates data the older It's
- The older data gets, the less granularity there is
- Generally, detailed data only matters in the short term. Over long term, we're looking for trends
- It retains for 3 hours datapoints with a period of less than 60 seconds:
- After 3 hours, they're aggregated to every 1 minute
- It retains 15 days datapoints with a period of 1 minute:
- After 15 days, they're aggregated to every 5 minutes
- It retains for 63 days datapoints with a period of 5 minutes:
- After 63 days, they're aggregated to every 1 hour
- It retains for 455 days datapoints with a period of 1 hour:
- After 1 hour, they're deleted?
Alarm
- It can be create on a metric
- It allows to take an action if the it's triggered
- Its components are:
- A metric: the datapoints over time being measured
- Threshold
- It could be static
- It could be automatic with Anomalie detection:
- Using CloudWatch Anomaly Detection
- Period: How long the threshold should be bad before an alarm is generated
- Action: which action to trigger:
- SNS
- Auto Scaling
- EC2
- Its states are:
- Insufficient:
- It's the state alarms start in
- There isn't enough data to judge the state
- Alarm:
- The alarm threshold has been breached
- E.g., > 90% CPU
- OK: The alarm threshold hasn't been breached
- Insufficient:
Cloud Watch Agent
- It allows to publish metrics into CloudWatch agent
- It allows to publish an AWS service internal metric that isn't capture by default
- E.g., memory usage of an individual process in an EC2 instance
- It sits internally on EC2 instances and injects metrics into CloudWatch
CloudWatch Logs
- It provides functionality to store, monitor and, access logs
- Its logs could be from:
- EC2 or on-premises servers
- Lambda
- CloudTrail
- Route 53
- VPC Flow Logs
- Custom applications
- It's data is based on Log Event (It'sn't datapoints and metrics):
- It's a timestanp and raw message
- YYYYMMDDHHMMSS RAW-MESSAGE
- A Log Stream is a group of log events with the same source:
- A log stream is a sequence of log events that share the same source
- E.g.,
- A Log Group is a container for log streams:
- It defines groups of log streams that share the same retention, monitoring, and access control settings
- It controls retention, monitoring, access control and, metric filters (see below)
- Its name is usually prefixed, e.g., for AWS Lambda: aws/lambda/myLambdaFuncitonName/
- Multiple operations are available at this level:
- Export settings: to S3
- Stream settings: to AWS Lambda, to AWS Elastic Search
- Expiration settings (change the retention period) by default it doesn't expire
- Metric filter setting: Add a new one;
- E.g.,
- We could have a separate log stream for the Apache access logs from 3 hosts,
- We could group them into a single log group called MyWebsite.com/Apache/access_log
- It allows to analyze logs at Log Group level:
- by creating Filter Patterns
- by creating new metrics
- by creating alarm
- e.g., failed SSH logins
Pricing
Use cases
Limits
Best practices
- Every AWS account should have Billing alarm
- Install by default CloudWatch agent in our EC2 instances
- Give the right IAM role to AWS Services to let them use Cloud Watch Logs
Description
- It's a governance, compliance, risk management, and auditing service
- It records account activity within an AWS account
- It's enabled by default in all AWS accounts (It's used to be optional)
- Its activity is record as a CloudTrail event
- It's a recorded action taken by users, roles or, aws services
- It's essentially a JSON document that details a specific action on that account
- It's recorded for 90 days in Event history that allows to browse through events; Search them; Interact with them, etc
- We can identify
- which users and accounts called AWS,
- which IP address the calls were made from,
- When the calls occurred
Architecture
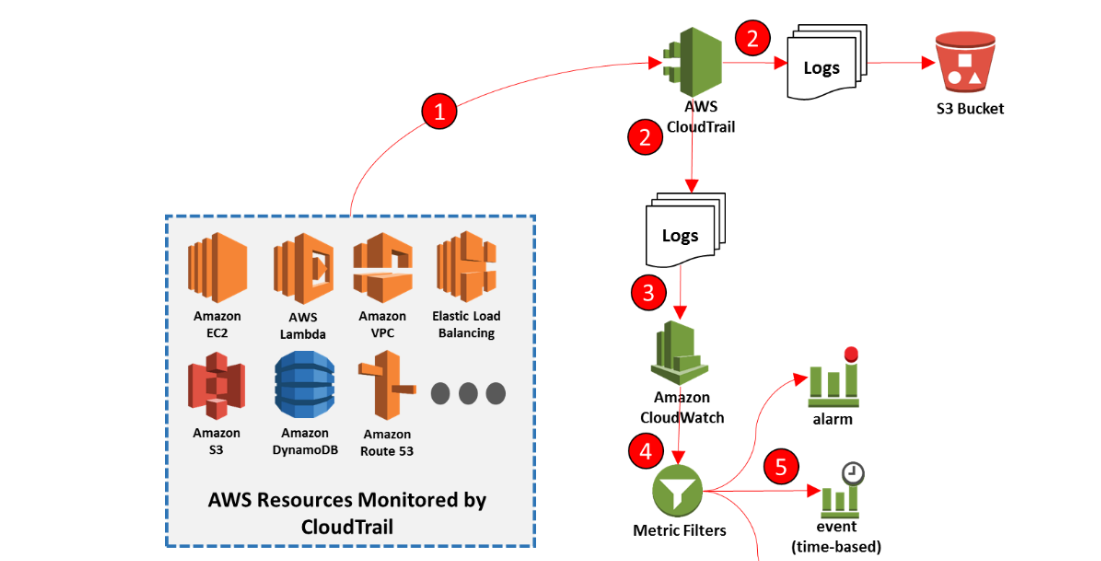
Trail
- It allows to define advanced options inside CloudTrails:
- To retain CloudTrail events for than 90 days by storing them in S3 and CloudWatch logs
- To create event metrics,
- To trigger alerts,
- To run advanced queries in Amazon Athena,
- To create event workflows,
- To create a trail for an organization by logging in with the master account for AWS Organization
- It's a regional object
- It delivers log files in S3:
- It's done on a periodic basis (not in real time): ~ every 15 mn?
- S3 bucket could be in a different AWS account that may be dedicated for security and governance
- It could deliver log files in CloudWatch:
- Its creation Inputs are:
- Trail name,
- Option to apply it to current region or all regions
- Option to apply it to current accoutn or to a whole organization
- Options for Management Events:
- Select Read-only, Write-only, All or, None events
- Select Log AWS KMS events
- Options for Data Events:
- S3: Select all events related to all or specific buckets
- Lambda Function: Select all events related to all or specific lambda functions
- Options to select Insights Events
- Storage Location:
- S3 bucket + Log file prefix
- Encrypt log files with SSE-KMS + KMS key
- Enable log file validation: to determine whether a log file was delete, modified or, unchanged after it's delivered
- Send SNS notification for every log file delivery (Topic)
- It edition Imputs are:
- Configure CloudWatch Logs integration:
- Select an existing Log Group or create a new one
- Select an existing IAM role or create a new one
- Configure CloudWatch Logs integration:
Management Events
- They're also know as Control Plane Operations
- They're events that we were traditionally associate with an API monitor
- They log control plane events: anything that is account level interacting with the management plane of an account
- Read-Only event:
- They're generated from read API operations
- E.g., Describe*
- Write-Only event:
- They're generated from write, delete and, update API operations
- E.g., creating a user, deleting a user, creating a bucket, deleting a bucket, creating a Lambda function, user login, configuring security and, adjusting security groups
Insights Events
- They're records that capture an unusual call volume of write management APIs in our AWS account (new)
Data Events
- They're also know as data plane operations
- They're events that occur on data object level
- E.g. 1, Object-level events in S3: GetObject, PutObject
- E.g. 2, Function-level events in Lambda: Invoke API operations
Pricing
Limits
- Event history: 90 days
Best practices
- Create a trail in our accounts and apply it to all regions and organization
- It should be the 2nd thing to do after creating an Admin user?
- Don't wait after a security breach happen
Description
- It allows to capture metadata about the traffic flowing in and out of a VPC networking interface:
- It can be placed on:
- a specific network interface (ENI),
- a subnet: it means Flow Logs monitors every ENI inside that subnet
- an entire VPC: it means Flow Logs monitors every ENI inside that VPC
- It's NOT real time
- It doesn't capture the actual traffic
- It captures Metadata below:
- Account ID
- Interface ID
- Source and destination IP addresses
- Source and destination ports
- Protocol
- Bytes
- Start and end
- Log Status: ALLOW or REJECT account-id, interface-id, srcaddr, dstaddr, srcport, dstport, protocol, packets, bytes, start, end, action, log-status
- Creation Inputs:
- Filter: All, Accepted or, Rejected traffic
- Destination:
- S3 bucket
- CloudWatch logs: log group + AMI Role
- Log Record format:
- Custom format
- AWS default format: ${version} ${account-id} ${interface-id} ${srcaddr} ${dstaddr} ${srcport} ${dstport} ${protocol} ${packets} ${bytes} ${start} ${end} ${action} ${log-status}
Architecture
Limits
- It doesn't capture some traffic metadata:
- Amazon DNS server,
- Windows license activation: if we have any any Windows EC2 instances which the licenses are managed by AWS
- 169.254.169.254: instance metadata that occurs inside an instance
- DHCP traffic,
- VPC router
Best practices
- Monitor All traffic (Accepted and Rejected traffic)
Description
- It's a sub product of CloudWatch
- It's able to see in near real-time all the events which happen inside an AWS account
- It's the glue that allows to receive events from sources and configure their delivery to targets:
- EC2 instances, Lambda functions, step function, state machines, SNS topics
- Add it as a message on SQS queue
- It uses rules to deliver specific events to a supported target
- Event Source allows to filter and match against certain events within an account
- Event by Service: is based on a supported service
- Event Pattern: is for services that aren't directly supported (CloudTrail is required)
- Schedule: invokes a Target based on time: by fixed rate (every 2 mn) or Cron expression
- Target:
- It's invoked when an event matches the Event Pattern or when schedule is triggered
- It could be a Lambda Function or any supported service or api
- Event Source allows to filter and match against certain events within an account
- It's NOT CloudTrail:
- A CloudWatch events can take action based on what's happening
- A CloudWatch events is a real time service
- CloudTrail is an auditing tool and it's not a real-time product
- E.g. of Events:
- An Instance stopping,
- A security group being changed,
- A CloudTrail trail being switched off,
- A new user being added
Use cases
- Power off EC2 instances that don't need to be online outside of working hours:
- Enable automatically a CloudTrail trail as soon as it's disabled
Description
- It provides regional, secure key management and encryption/decryption services
- It's validated for FIPS 140-2 Level 2 (Do NOT be confused with AWS CloudHSM which is validated FIPS 140-2 Level 3)
- It's used to be a part of AWS IAM
- It's a regional service
- It allows
- to create, modify and, delete Customer Master Keys (CMKs):
- A CMK has key policies and can be used to create other keys
- to encrypt data:
- Input: a plaintext data + CMK
- Output: an encoded text base64 CiphertextBlob that includes a link back to the used CMK
- to decrypt encrypted data:
- Input: ciphertext
- Output: plaintext data
- Action: AWS will use the link to the used CMK included in the ciphertext to decrypt the input
- to reencrypt encrypted data:
- Input: ciphertext + New CMK
- Output: a new ciphertext (at no point do we see the plaintext) that includes a link to the new CMK
- Action: AWS will use the link to the old CMK included in the ciphertext to reencrypt it
- to create, modify and, delete Customer Master Keys (CMKs):
Customer Master Keys (CMK)
- There're 3 types of CMK:
- Customer Managed Key:
- A customer can View it
- A customer can Manage it: Enable it, disable it, configure rotation, etc
- It's Dedicated to a customer Account
- It's allowed by certain services
- It allows an automatic key rotation: every year (optional: disabled by default)
- It can be controlled via key policies (see below)
- It can be enabled/disabled
- AWS Managed Key:
- A customer can View it
- A customer can NOT Manage it
- It's Dedicated to a customer Account
- It's used by Default if encryption is picked within most AWS services
- It's formatted as aws/service-name
- It could be used by the service it belong to only
- It's automatically rotated every 3 years (1095 days)
- It can NOT be enabled/disabled
- E.g., aws:ebs, aws:rds
- AWS Owned CMK:
- A customer can NOT View it
- A customer can NOT Manage it
- It's NOT Dedicated to a customer Account
- It's used by AWS on a shared basis across many accounts
- It's used for AWS level encryption and decryption
- It's NOT available (hiden)
- Customer Managed Key:
- It's created in a region
- It never leaves its region
- E.g. an encrypted S3 object in us-east-1:
- If we want to move this object to us-east-2, a new region
- We need to create a new CMK in us-east-2, the new region
- We need to reencrypt the S3 object with the new CMK of us-east-2
- It has a unique KeyId
- It could have an Alias that is pointing to the key (optional)
- Without an alias, a CMK isn't visible on the console
Data Encryption Key (DEK)
- It's used to encrypt or decrypt data of any size (> 4 KB)
- It's generated from a CMK and it returns a DEK in 2 versions:
- A Plaintext version, Data Encryption Key (DEK) (non encrypted version)
- A Cipher version, Encrypted Data Encryption Key (An encrypted version)
- AWS KMS cannot use a data key to encrypt data
- It could be done by a customer outside of KMS
- It could be done by using OpenSSL or a cryptographic library like the AWS Encryption SDK
- The encryption operation is done as follow:
- Data is encrypted by using the Plaintext data key
- The plaintext data key should be discarded (removed from memory) as soon as possible
- Encrypted Data can be safely stored with the encrypted data key: It's available to decrypt the data
- Data is encrypted by using the Plaintext data key
- The decryption operation is done as follow:
- Decrypt the encrypted data key: AWS KMS Decrypt operation will uses the related CMK to decrypt it and returns the plaintext data key
- Use the plaintext data key to decrypt our data
- Remove the plaintext data key from memory as soon as possible
- Envelope Encryption
- When we encrypt our data, our data is protected, but we have to protect our encryption key
- One strategy is to encrypt it
- Envelope encryption is the practice of encrypting plaintext data with a data key, and then encrypting the data key under another key
- E.g., This is how S3 functions to encrypt objects
- For more details
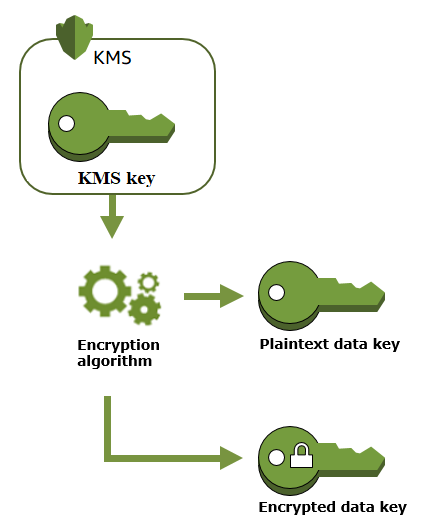
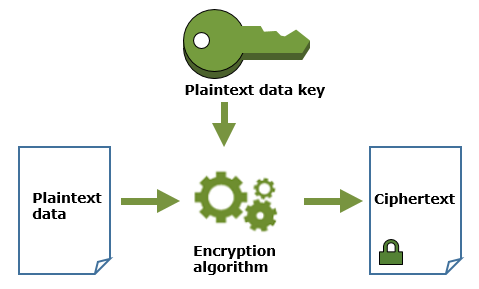
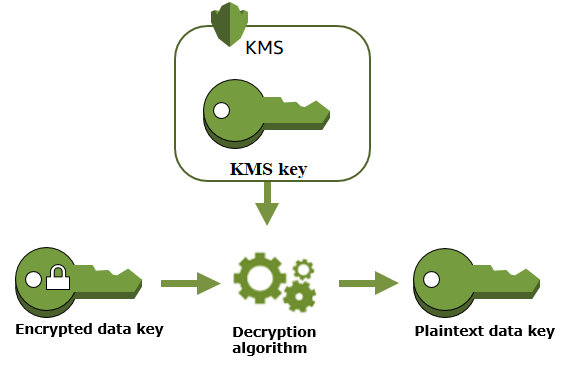

Custom Key Stores
- It allows to let KMS supprt FIPS 140-2 Level 3 by using AWS Cloud HSM which is validated FIPS 140-2 Level 3
- It let customers to store a CMKs in a custom key store instead of the standard KMS key store
- A custom key store is created using an AWS CloudHSM cluster that customers own and manage
- A custom key store provides direct control of the hardware security modules (HSMs) that generate the key material for a customer's CMKs and perform cryptographic operations with them
Security
- Key Policy:
- For Customer Managed CMKs:
- By default, a CMK is accessible by everyone in the account it's created in
- A Customer Managed CMK by default trusts the account it's created in
- It could be updated
- If a CMK's key policy is deleted, we won't than have any access to the CMK (a support ticket will be then needed)
- For AWS Managed CMKs:
- It's NOT editable
- It allow access through its AWS service for all principals in the account that are authorized to use this AWS service
- For Customer Managed CMKs:
Role separation
- KMS has the concept of two types of uses on a key:
- We have the ability to interact and manage a key
- But we also have a separate set of permissions, which allow to perform cryptographic operations using that key
- E.g., So we can reecrypt a data without having access to its plaintext
- It allows an identity to be given administrator rights to an AWS Service such as S3, but not allow them to interact with this AWS Service data
- For more details:
Pricing
Use cases
Limits
- Encryption/Decryption without DEK Max data size: 4 KB
Best practices
Description
- It is an Infrastructure as Code (IaC) product
- It allows to create, manage, and Template Stack Physical Resources infrastructure
- It uses using Json or Yaml files
- Its files serves as the single source of truth for a cloud environment
- It's available at no additional charge, only AWS resources usage is charged
- For more details
Architecture
Template
Stacks
Physical Resources
Drift Detection
- It's used to detect changes made to AWS resources outside the CloudFormation Templates
- It only checks property values that are explicitly set by stack templates or template parameters
- It doesn't determine drift for property values that are set by default
- For more details
Security
Monitoring
Pricing
Use cases
- Reduce the effort required to consistently building systems by building internal library of templates
- A consultancy business rolls out the same type of infrastructure day after day for different clients
- Use it for temporary period because it is fully automated:
- if a development team who want to roll out and test new versions of an application
- CloudFormation Template will allow to deploy the infrastructure, install the code, teste it and then delete it afterwards
- Used for disaster recovery to decrease RTO
Limits
Best practices
Description
-
It's a PaaS product (Platform as a Service)
-
It's Infrastucture as Code
-
It's a CI/CD system (Continuous Integration / Continuous Delivery)
-
It's like Cloud Formation for people that don't know anything about AWS
- CloudFromation is very close to infrastructure
- CloudFromation is flexible but there is a lot of admin overhead
-
It manages the infrastructure for any provided code
- It supports Java, DotNet, Node.js, PHP, Ruby, Python, Go,
- It supports Docker, Apache, IIS, Nginx and, Tomcat based applications
-
It provides automated provisioning, monitoring, auto scaling, load balancing and, updating
-
It's an application container
- It contains 0 or more envronments
- It contains 0 or more Application versions
- They're added to a container
- They package a source bundle (a zip or a wire file depending on the the platform used to create it)
- They're deployed to an environment
- It doesn't contain a database because its environments are transitory
-
E.g., We can upload our application code and Beanstalk will create all required AWS infrastructure for us
Architecture
- An application has a beanstalk container
- An application container has multiple environments
- 1 or more Web Server environments
- 1 worker environment
- An environment has:
- 1 LB,
- 1 Auto Scaling Group across multiple AZs
- 1 or more Instances that run a Host Manager (HM)
- The database is outside of these environments which are transitory
Environment
- It's transitory: modified at each deployment
- It doesn't contain a database because it's transitory
- It has 2 types:
- Web Server environment
- It's designed to serve web applications on the Internet
- It has a DNS name
- Plateform
- Worker environment
- It's designed to be used in background SQS message processing for decoupling applications
- Web Server environment
- It allows to configure different aspects about hot it's architected:
- It allows to modifiy the size and type of its instances, storage type that it uses
- It can change its capacity
- It allows to have a LB or not
- It allows to scale out to whatever number of instances needed
- It allows to change the deployment style
- It allows to change the monitoring and security that is used
Deployment
- Deployment Options:
- All at once:
- An updated application version is deployed to all instances
- It's NOT recommended for production deployments
- Pros: It's quick and simple
- Cons: It may cause an outage if there's any problem
- Rolling
- It splits instances into batches
- It deploys on existing batches one at a time
- Rolling with additional Batch (immutable)
- It's as above but
- It provisions a new batch of instances,
- It deploys on them and tests them
- It removes the old batch if there's no problem
- Pros: it prevent outages: if there's any problem, its stops the deployment
- Cons: It's slightly more expensive
- Blue/Green:
- It maintains 2 environments
- It deploys, and swap CNAME
- Pros: It's the safest option
- Cons: It's the most expensive because we do need to maintain 2 environments
- All at once:
Host Manager (HM)
- It's responsible for deploying and maintaining any application
- It's looking at events and metrics
- It's maintaing server logs
Use cases
- Use cases:
- To provision an environment for an application with no admin overhead or the absolute minimal amount of admin overhead for developers
- When one of the supported languages is used and can add EB-specific config
- Antipattern:
- It's NOT for low level infrastructure control
- It's NOT for immutable architecture (deploying applications in a completely unaltered way)
- Chef support is needed
Limits
Best practices
Description
- It's an implementation of the Chef configuration management
- It's a deployment platform
- It allows to manage large sets of infrastructure
- It takes away from the low-level configuration of CloudFormation
- It's not as ar as Elastic Beanstalk:
- It's designed for infrastructure engineer
- It's NOT designed for developers
- It lets create a stack of resources with layers
- It manages resources as a unit
- It uses IAM permissions to interact with different components of AWS
Architecture
- It's based on Chef
- Chef uses Recipes
- A Recipe uses cookbooks
- A Cookbook requires a repository
- For more details:

Stacks
- It's the base entity of OpsWorks (as in AWS CloudFormation)
- It's an entity that is configured and build on using other configuration components (see below)
- It represents an isolated collection of infrastructure as for CloudFormation but
- It's NOT created from a template
- When we're controlling permissions and giving people permissions to interact with OpsWorks, we generally doing it on a per stack basis
- It can be used per application or per platform
- It could be used for development, staging or, production environments
- It could be created based on:
- Chef 11 sack
- It's capable of managing Linux based OS
- Chef 12 stack:
- It's capable of managing Linux and Windows based OS
- Sample stack
- Node.js app
- It's capable of managing Linux and Windows based OS
- Chef 11 sack
- It includes 1 or more Layers
- For more details
Layers
- It's comparable to application tiers within a stack
- E.g., a database layer, a web server layer, an application layer, a proxy layer
- It could be
- An OpsWorks layer
- An ECS layer: if we have an ECS cluster in in our AWS infrastructure, we could add it and use that functionality inside OpsWrks
- An RDS layer: if we have any RDS database instances, they could be then referenced as a layer
- It's at layer level that Recipes are applied (associated) and configure what to install on instances in that layer
- It includes different settings such as
- Auto healing settings
- We can define the exact network configuration of any instance that is added to a layer
- We can control the storage of any instance that is added to a layer
- We can add additional mount points to instances that get added
- We can configure CloudWatch log exports on a layer by layer basis
Recipes
- They're the essentially the documents that Chef uses to configure te instances that are inside a layer
- It has different recipe types:
- Setup:
- It's executed on an instance when 1st provisioned
- E.g., installing a web server or installing base system components
- Configure:
- It's executed on all instances on the related layer when an instance is added or removed
- E.g., if a cluster is running inside a layer, when an instance is added, it may be needed to make all of the other instances in that layer aware of the newly added instance
- Deploy and Undeploy:
- They're executed when apps are added or removed
- Shutdown:
- It's executed when an instance is shut down but before it's stopped
- Setup:
Instances
- They're EC2 instances
- They're associated with a layer
- They're added within a layer in different ways:
- They could be configured to run 24/7
- They could be time based:
- They can be set to start and stop based on a specific schedule
- They could be load based:
- They can be set to start and stop automatically (scale in and out) based on the load that's incoming to that layer
Apps
- They're deployed to layers from a source code repo or S3
- Actual deployment happens using recipes on a layer
- Other recipes are run when deployments happen, potientially to reconfigure other instances
Database
- It's available in a LibreOffice sheet here

{kind=link}
ASG Periods
- Health Check Grace Period:
- The length of time that ASG waits before checking an instance health status
- It begins when an instance comes into service
- Its default value: 300 seconds
- It is disabled when its value is: 0 second
- Warm up period:
- The length of time that it takes for a newly launched instance to warm up
- Its default value: 300 seconds
- Scaling out:
- Until its specified warm-up time has expired, an instance is not counted toward the aggregated metrics of the ASG
- Alarm breaches that fall in this period, result in a single scaling activity
- It ensures that the ASG doesn't add more instances than needed
- Scaling in:
- While scaling in, AWS considers instances that are terminating as part of the current capacity of the group
- The ASG doesn't remove more instances from the ASG than necessary
- Cooldown period:
- It's only available with Simple Scaling Policy
- After the ASG dynamically scales, it waits for the cooldown period to complete before resuming scaling activities
- Its default values: 300 seconds