Kaggle Tweet Sentiment Extraction Competition: 1st place solution (Dark of the Moon team)
This repository contains the models that I implemented for this competition as a part of our team.
- Models: RoBERTa-base-squad2, RoBERTa-large-squad2, DistilRoBERTa-base, XLNet-base-cased
- Concat Avg / Max of last n-1 layers (without embedding layer) and feed into Linear head
- Multi Sample Dropout, AdamW, linear warmup schedule
- I used Colab Pro for training.
- Custom loss: Jaccard-based Soft Labels
Since Cross Entropy doesn’t optimize Jaccard directly, I tried different loss functions to penalize far predictions more than close ones. SoftIOU used in segmentation didn’t help so I came up with a custom loss that modifies usual label smoothing by computing Jaccard on the token level. I then use this new target labels and optimize KL divergence. Alpha here is a parameter to balance between usual CE and Jaccard-based labeling.
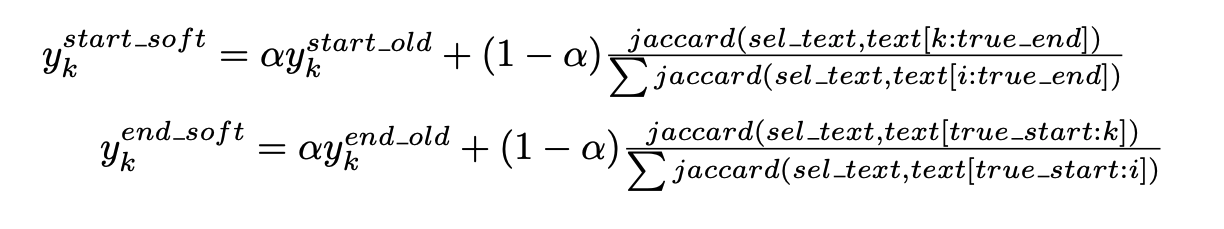

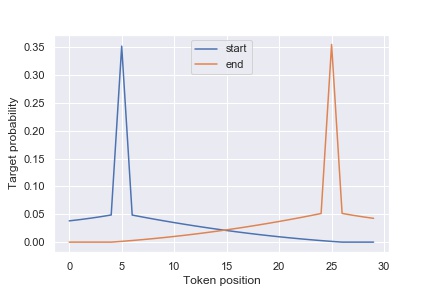
I claim that since the probabilities from my models are quite decorrelated with regular CE / SmoothedCE ones, they provided necessary diversity and were crucial to each of our 2nd level models.
- max_len=120, no post-processing
- Append sentiment token to the end of the text
- Models: 5fold-roberta-base-squad2(0.712CV), 5fold-roberta-large-squad2(0.714CV)
- Last 3 hidden states + CNN*1 + linear
- CrossEntropyLoss, AdamW
- epoch=5, lr=3e-5, weight_decay=0.001, no scheduler, warmup=0, bsz=32-per-device
- V100*2, apex(O1) for fast training
- Traverse the top 20 of start_index and end_index, ensure start_index < end_index
I took a bet when I joined @cl2ev1 on the competition, which was that working with Bert models (although they perform worse than Roberta) will help in the long run. It did pay off, as our 2nd level models reached 0.735 public using 2 Bert (base, wwm) and 3 Roberta (base, large, distil). I then trained an Albert-large and a Distilbert for diversity.
- bert-base-uncased (CV 0.710), bert-large-uncased-wwm (CV 0.710), distilbert (CV 0.705), albert-large-v2 (CV 0.711)
- Squad pretrained weights
- Multi Sample Dropout on the concatenation of the last
nhidden states - Simple smoothed categorical cross-entropy on the start and end probabilities
- I use the auxiliary sentiment from the original dataset as an additional input for training.
[CLS] [sentiment] [aux sentiment] [SEP] ...During inference, it is set to neutral - 2 epochs, lr = 7e-5 except for distilbert (3 epochs, lr = 5e-5)
- Sequence bucketing, batch size is the highest power of 2 that could fit on my 2080Ti (128 (distil) / 64 (bert-base) / 32 (albert) / 16 (wwm)) with
max_len = 70 - Bert models have their learning rate decayed closer to the input, and use a higher learning rate for the head (1e-4)
- Sequence bucketting for faster training
This competition has a lengthy list of things that did not work, here are things that worked :)
- Models: roberta-base (CV 0.715), Bertweet (thanks to all that shared it - it helped diversity)
- MSD, applying to hidden outputs
- (roberta) pretrained on squad
- (roberta) custom merges.txt (helps with cases when tokenization would not allow to predict correct start and finish). On it’s own adds about 0.003 - 0.0035 to CV.
- Discriminative learning
- Smoothed CE (in some cases weighted CE performed ok, but was dropped)
Theo came up with 3 different Char-NN architectures that use character-level probabilities from transformers as input. You can see how we utilize them in this notebook.
-
RNN
-
CNN
-
WaveNet (yes, we took that one from the Liverpool competition)
.svg?generation=1592405862305380&alt=media)
.svg?generation=1592405917697990&alt=media)
.svg?generation=1592405961585964&alt=media)
As Theo mentioned here, we feed character level probabilities from transformers into Char-NNs.
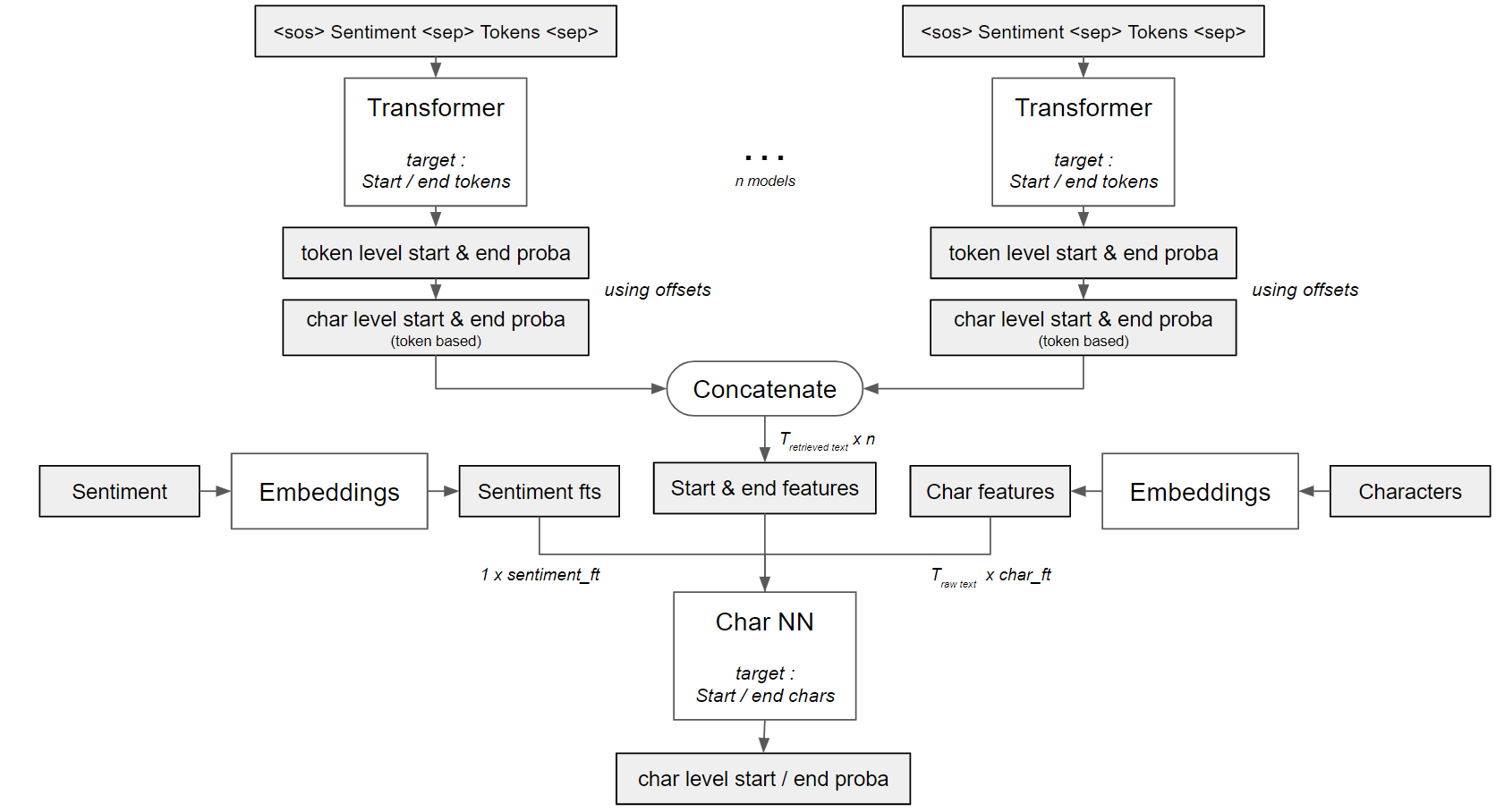
However, we decided not to just do it end-to-end (i.e. training 2nd levels on the training data probas), but to use OOF predictions and perform good old stacking. As our team name suggests (one of the Transformers movies) we built quite an army of transformers. This is the stacking pipeline for our 2 submissions. Note that we used different input combinations to 2nd level models for diversity. Inference is also available in this and this kernels.
.svg?generation=1592406106435760&alt=media)
.svg?generation=1592406151678743&alt=media)
We used one of our CV 0.7354 blends to pseudo-label the public test data. We followed the approach from here and created “leakless” pseudo-labels. We then used a threshold of 0.35 to cut off low-confidence samples. The confidence score was determined like: (start_probas.max() + end_probas.max()) / 2. This gave a pretty robust boost of 0.001-0.002 for many models. We’re not sure if it really helps the final score overall since we only did 9 submissions with the full inference.
Adam optimizer, linear decay schedule with no warmup, SmoothedCELoss such as in level 1 models, Multi Sample Dropout. Some of the models also used Stochastic Weighted Average.
We did predictions on neutral texts as well, our models were slightly better than doing selected_text = text. However, we do selected_text = text when start_idx > end_idx.
Once the pattern in the labels is detected, it is possible to clean the labels to improve level 1 models performance. Since we found the pattern a bit too late, we decided to stick with the ensembles we already built instead of retraining everything from scratch.
Thanks for reading and happy kaggling!
I gave a speech about our solution at the ODS Paris meetup: YouTube link
The presentation: SlideShare link