Specializing Smaller Language Models towards Multi-Step Reasoning
Yao Fu, Hao Peng, Litu Ou, Ashish Sabharwal, Tushar Khot |
 |
Github
Paper |
 
Distilling Script Knowledge from Large Language Models for Constrained Language Planning
Siyu Yuan, Jiangjie Chen, Ziquan Fu, Xuyang Ge, Soham Shah, Charles Robert Jankowski, Yanghua Xiao, Deqing Yang |
 |
Github
Paper |
SCOTT: Self-Consistent Chain-of-Thought Distillation
Peifeng Wang, Zhengyang Wang, Zheng Li, Yifan Gao, Bing Yin, Xiang Ren |
 |
Paper |
 
DISCO: Distilling Counterfactuals with Large Language Models
Zeming Chen, Qiyue Gao, Antoine Bosselut, Ashish Sabharwal, Kyle Richardson |
 |
Github
Paper |

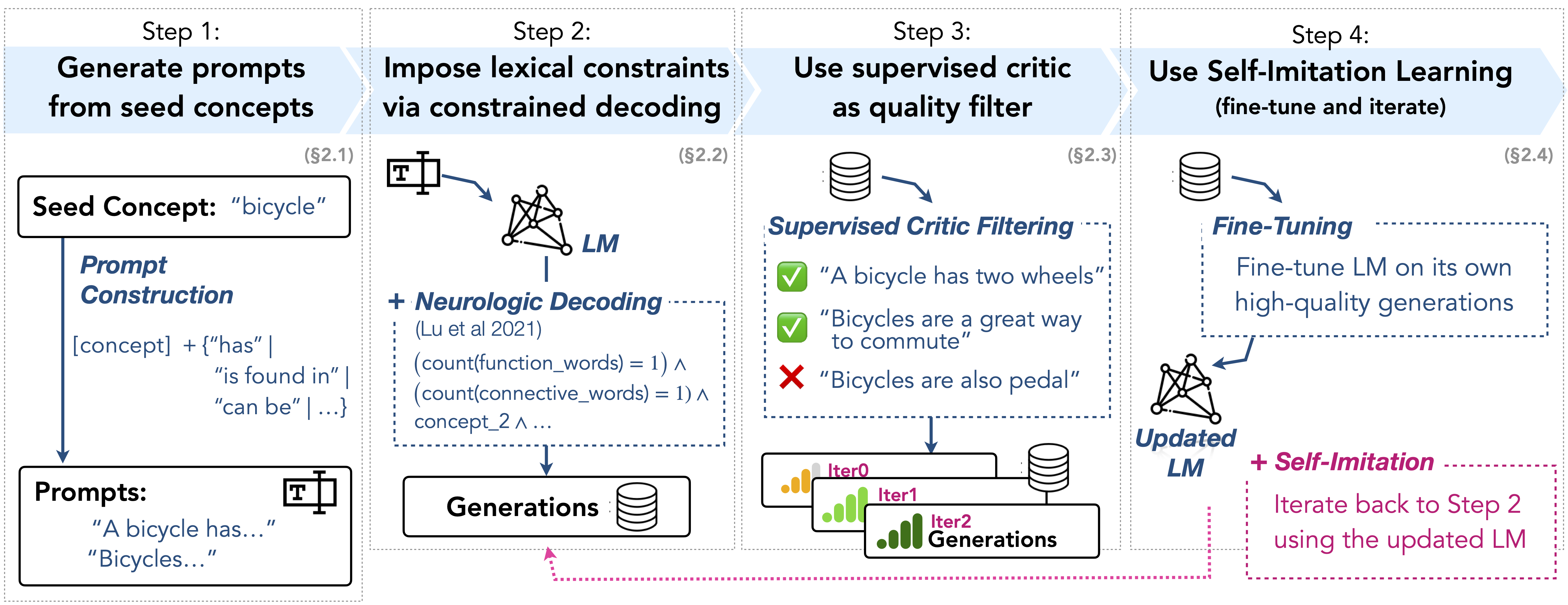
I2D2: Inductive Knowledge Distillation with NeuroLogic and Self-Imitation
Chandra Bhagavatula, Jena D. Hwang, Doug Downey, Ronan Le Bras, Ximing Lu, Lianhui Qin, Keisuke Sakaguchi, Swabha Swayamdipta, Peter West, Yejin Choi |
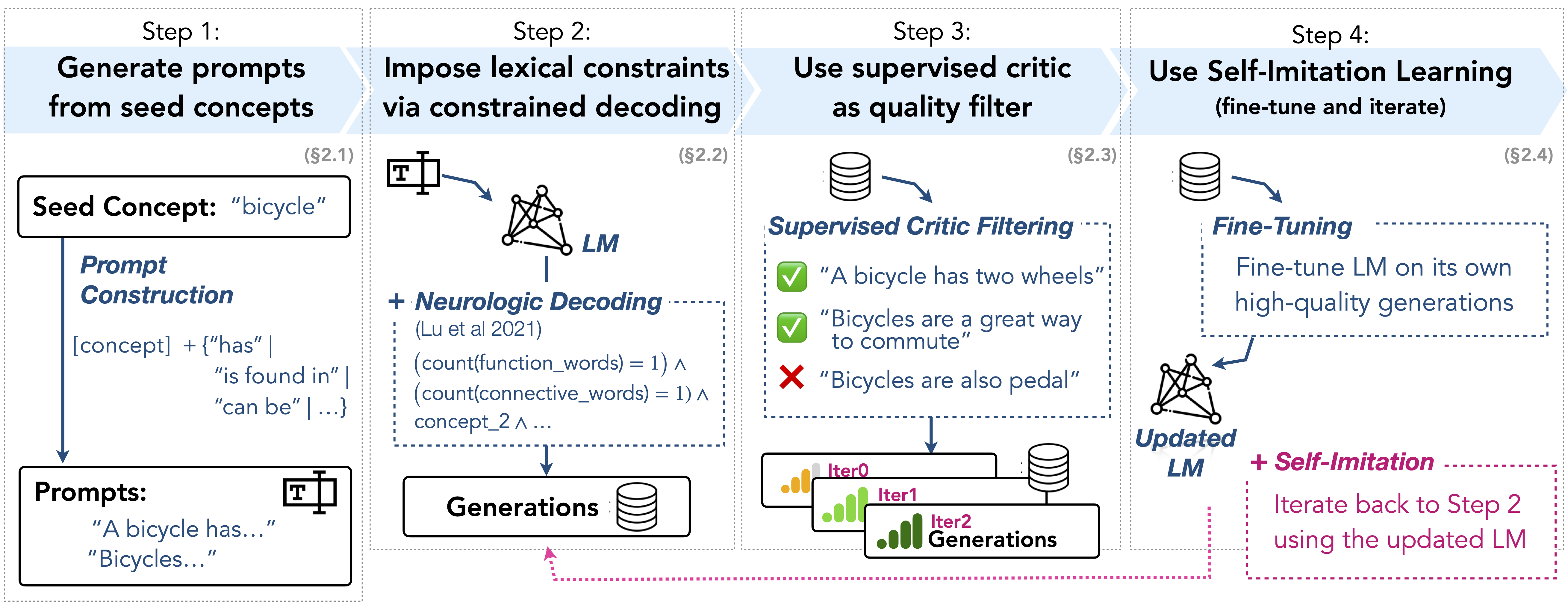 |
Github
Paper
Project |

Symbolic Chain-of-Thought Distillation: Small Models Can Also "Think" Step-by-Step
Liunian Harold Li, Jack Hessel, Youngjae Yu, Xiang Ren, Kai-Wei Chang, Yejin Choi |
 |
Github
Paper |
 
Can Language Models Teach? Teacher Explanations Improve Student Performance via Theory of Mind
Swarnadeep Saha, Peter Hase, and Mohit Bansal |
 |
Github
Paper |

Dialogue Chain-of-Thought Distillation for Commonsense-aware Conversational Agents
Hyungjoo Chae, Yongho Song, Kai Tzu-iunn Ong, Taeyoon Kwon, Minjin Kim, Youngjae Yu, Dongha Lee, Dongyeop Kang, Jinyoung Yeo |
 |
Paper |

PromptMix: A Class Boundary Augmentation Method for Large Language Model Distillation
Gaurav Sahu, Olga Vechtomova, Dzmitry Bahdanau, Issam H. Laradji |
 |
Github
Paper |
 
Turning Dust into Gold: Distilling Complex Reasoning Capabilities from LLMs by Leveraging Negative Data
Yiwei Li, Peiwen Yuan, Shaoxiong Feng, Boyuan Pan, Bin Sun, Xinglin Wang, Heda Wang, Kan Li |
 |
Github
Paper |

Democratizing Reasoning Ability: Tailored Learning from Large Language Model
Zhaoyang Wang, Shaohan Huang, Yuxuan Liu, Jiahai Wang, Minghui Song, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, Qi Zhang |
 |
Github
Paper |
 
GKD: A General Knowledge Distillation Framework for Large-scale Pre-trained Language Model
Shicheng Tan, Weng Lam Tam, Yuanchun Wang, Wenwen Gong, Yang Yang, Hongyin Tang, Keqing He, Jiahao Liu, Jingang Wang, Shu Zhao, Peng Zhang, Jie Tang |
 |
Github
Paper |
 
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, Chen-Yu Lee, Tomas Pfister |
 |
Github
Paper |

Retrieval-based Knowledge Transfer: An Effective Approach for Extreme Large Language Model Compression
Jiduan Liu, Jiahao Liu, Qifan Wang, Jingang Wang, Xunliang Cai, Dongyan Zhao, Ran Lucien Wang, Rui Yan |
 |
Paper |

Cache me if you Can: an Online Cost-aware Teacher-Student framework to Reduce the Calls to Large Language Models
Ilias Stogiannidis, Stavros Vassos, Prodromos Malakasiotis, Ion Androutsopoulos |
 |
Github
Paper |

Efficiently Distilling LLMs for Edge Applications
Achintya Kundu, Fabian Lim, Aaron Chew, Laura Wynter, Penny Chong, Rhui Dih Lee |
 |
Paper |

LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions
Minghao Wu, Abdul Waheed, Chiyu Zhang, Muhammad Abdul-Mageed, Alham Fikri Aji |
 |
Github paper |
Knowledge Distillation of Large Language Models
Yuxian Gu, Li Dong, Furu Wei, Minlie Huang |
 |
Github
Paper |
Teaching Small Language Models to Reason
Lucie Charlotte Magister, Jonathan Mallinson, Jakub Adamek, Eric Malmi, Aliaksei Severyn. |
 |
Paper |

Large Language Model Distillation Doesn't Need a Teacher
Ananya Harsh Jha, Dirk Groeneveld, Emma Strubell, Iz Beltagy
|
 |
Github paper |
The False Promise of Imitating Proprietary LLMs
Arnav Gudibande, Eric Wallace, Charlie Snell, Xinyang Geng, Hao Liu, Pieter Abbeel, Sergey Levine, Dawn Song |
 |
Paper |

Impossible Distillation: from Low-Quality Model to High-Quality Dataset & Model for Summarization and Paraphrasing
Jaehun Jung, Peter West, Liwei Jiang, Faeze Brahman, Ximing Lu, Jillian Fisher, Taylor Sorensen, Yejin Choi |
 |
Github paper |
PaD: Program-aided Distillation Specializes Large Models in Reasoning
Xuekai Zhu, Biqing Qi, Kaiyan Zhang, Xingwei Long, Bowen Zhou |
 |
Paper |
RLCD: Reinforcement Learning from Contrast Distillation for Language Model Alignment
Kevin Yang, Dan Klein, Asli Celikyilmaz, Nanyun Peng, Yuandong Tian |
 |
Paper |
Sci-CoT: Leveraging Large Language Models for Enhanced Knowledge Distillation in Small Models for Scientific QA
Yuhan Ma, Haiqi Jiang, Chenyou Fan |
 |
Paper |

UniversalNER: Targeted Distillation from Large Language Models for Open Named Entity Recognition
Wenxuan Zhou, Sheng Zhang, Yu Gu, Muhao Chen, Hoifung Poon |
 |
Github
Paper
Project |

Baby Llama: knowledge distillation from an ensemble of teachers trained on a small dataset with no performance penalty
Inar Timiryasov, Jean-Loup Tastet |
 |
Github
Paper |
DistillSpec: Improving Speculative Decoding via Knowledge Distillation
Yongchao Zhou, Kaifeng Lyu, Ankit Singh Rawat, Aditya Krishna Menon, Afshin Rostamizadeh, Sanjiv Kumar, Jean-François Kagy, Rishabh Agarwal |
 |
Paper |

Zephyr: Direct Distillation of LM Alignment
Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, Nathan Sarrazin, Omar Sanseviero, Alexander M. Rush, Thomas Wolf |
 |
Github
Paper |

Towards the Law of Capacity Gap in Distilling Language Models
Chen Zhang, Dawei Song, Zheyu Ye, Yan Gao |
 |
Github
Paper |
Unlock the Power: Competitive Distillation for Multi-Modal Large Language Models
Xinwei Li, Li Lin, Shuai Wang, Chen Qian |
 |
Paper |
Mixed Distillation Helps Smaller Language Model Better Reasoning
Li Chenglin, Chen Qianglong, Wang Caiyu, Zhang Yin |
 |
Paper |
Distilling Event Sequence Knowledge From Large Language Models
Somin Wadhwa, Oktie Hassanzadeh, Debarun Bhattacharjya, Ken Barker, Jian Ni |
 |
Paper |
Knowledge Distillation for Closed-Source Language Models
Hongzhan Chen, Xiaojun Quan, Hehong Chen, Ming Yan, Ji Zhang |
 |
Paper |
Improving Small Language Models' Mathematical Reasoning via Equation-of-Thought Distillation
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, Weiping Wang |
 |
Paper |
Scavenging Hyena: Distilling Transformers into Long Convolution Models
Tokiniaina Raharison Ralambomihanta, Shahrad Mohammadzadeh, Mohammad Sami Nur Islam, Wassim Jabbour, Laurence Liang |
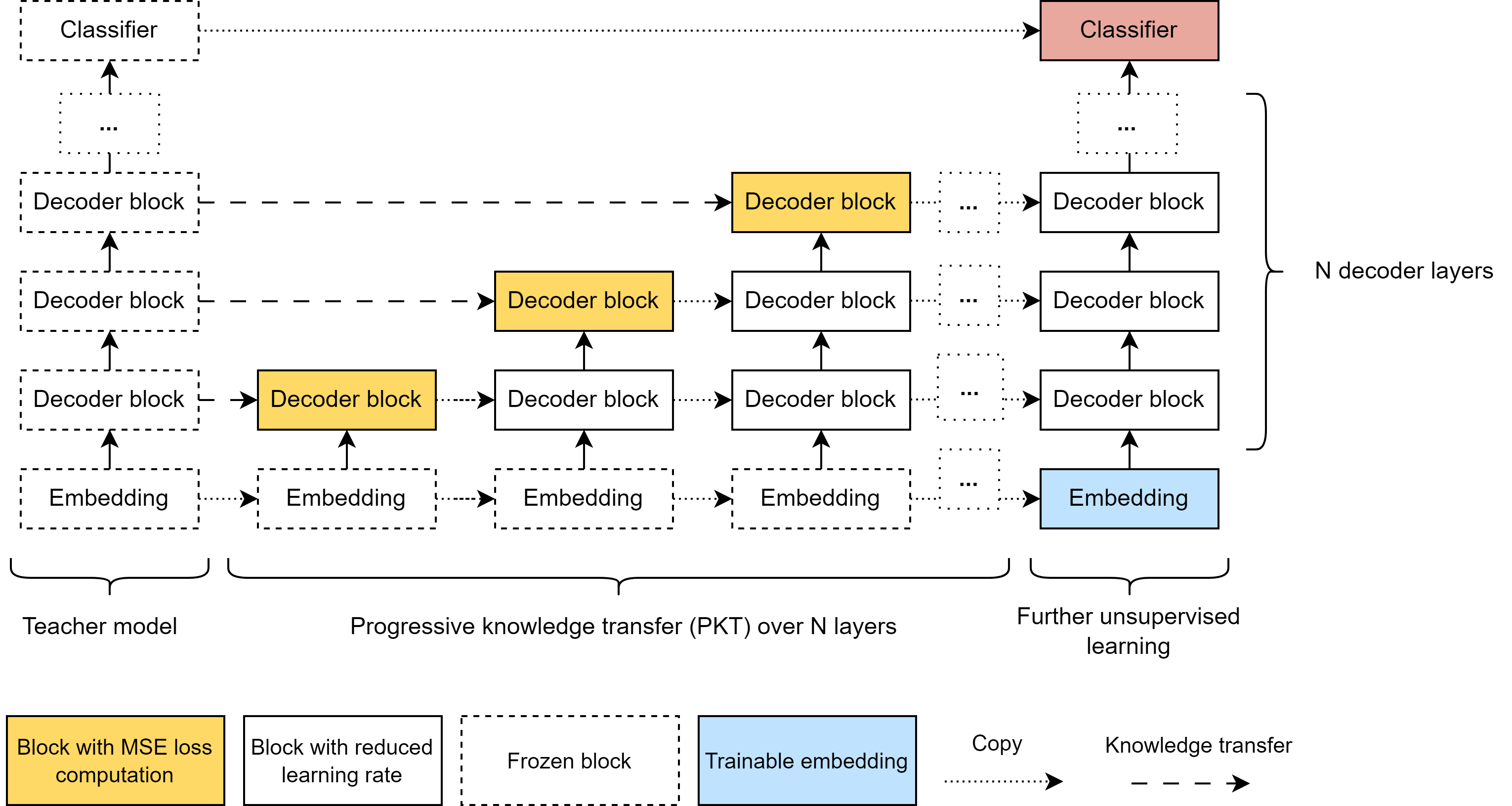 |
Paper |

DistiLLM: Towards Streamlined Distillation for Large Language Models
Jongwoo Ko, Sungnyun Kim, Tianyi Chen, Se-Young Yun |
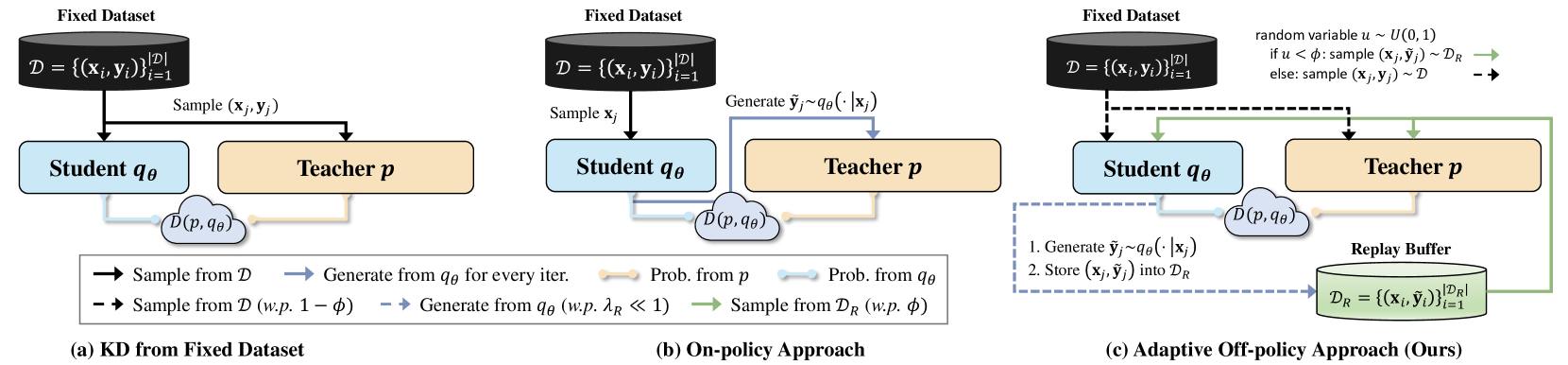 |
Github
Paper |
Large Language Model Meets Graph Neural Network in Knowledge Distillation
Shengxiang Hu, Guobing Zou, Song Yang, Bofeng Zhang, Yixin Chen |
 |
Paper |

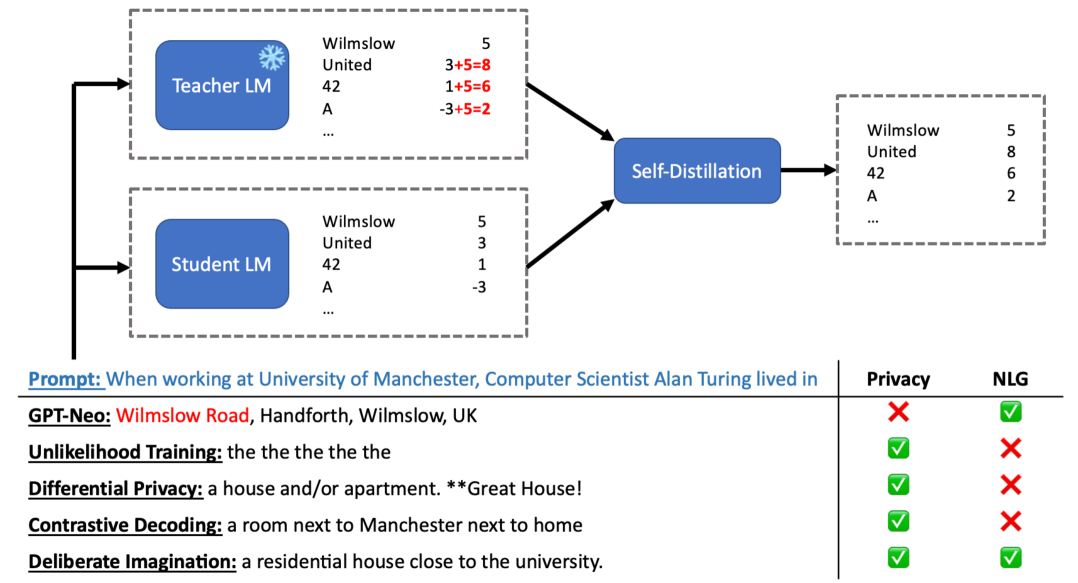
Unmemorization in Large Language Models via Self-Distillation and Deliberate Imagination
Yijiang River Dong, Hongzhou Lin, Mikhail Belkin, Ramon Huerta, Ivan Vulić |
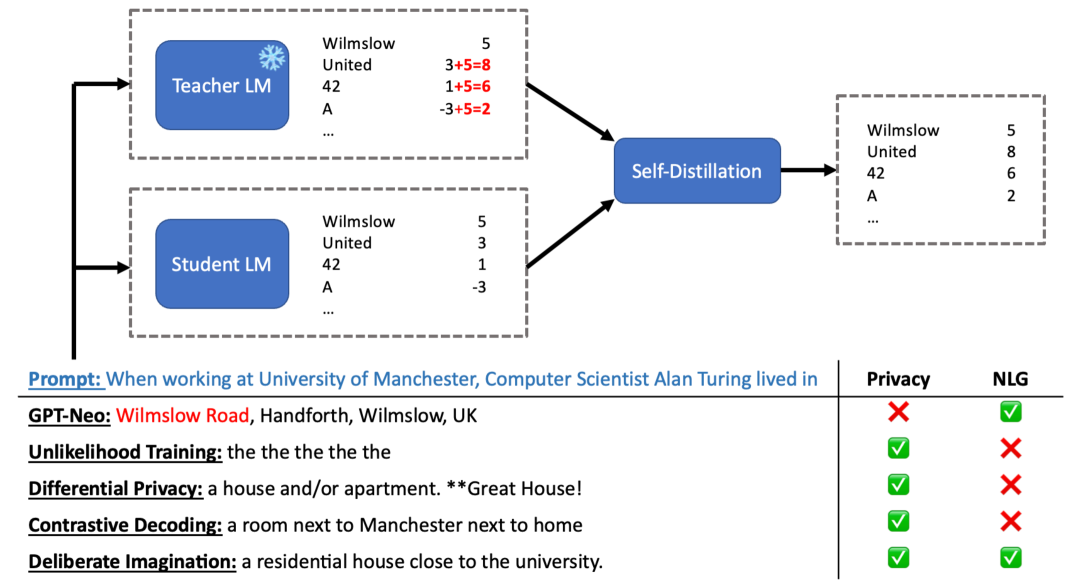 |
Github
Paper |

Towards Cross-Tokenizer Distillation: the Universal Logit Distillation Loss for LLMs
Nicolas Boizard, Kevin El-Haddad, Céline Hudelot, Pierre Colombo |
 |
Github Github
Paper
Model |
Revisiting Knowledge Distillation for Autoregressive Language Models
Qihuang Zhong, Liang Ding, Li Shen, Juhua Liu, Bo Du, Dacheng Tao |
 |
Paper |
PromptKD: Distilling Student-Friendly Knowledge for Generative Language Models via Prompt Tuning
Gyeongman Kim, Doohyuk Jang, Eunho Yang |
 |
Paper |
Self-Distillation Bridges Distribution Gap in Language Model Fine-Tuning
Zhaorui Yang, Qian Liu, Tianyu Pang, Han Wang, Haozhe Feng, Minfeng Zhu, Wei Chen |
 |
Paper |
Wisdom of Committee: Distilling from Foundation Model to Specialized Application Model
Zichang Liu, Qingyun Liu, Yuening Li, Liang Liu, Anshumali Shrivastava, Shuchao Bi, Lichan Hong, Ed H. Chi, Zhe Zhao |
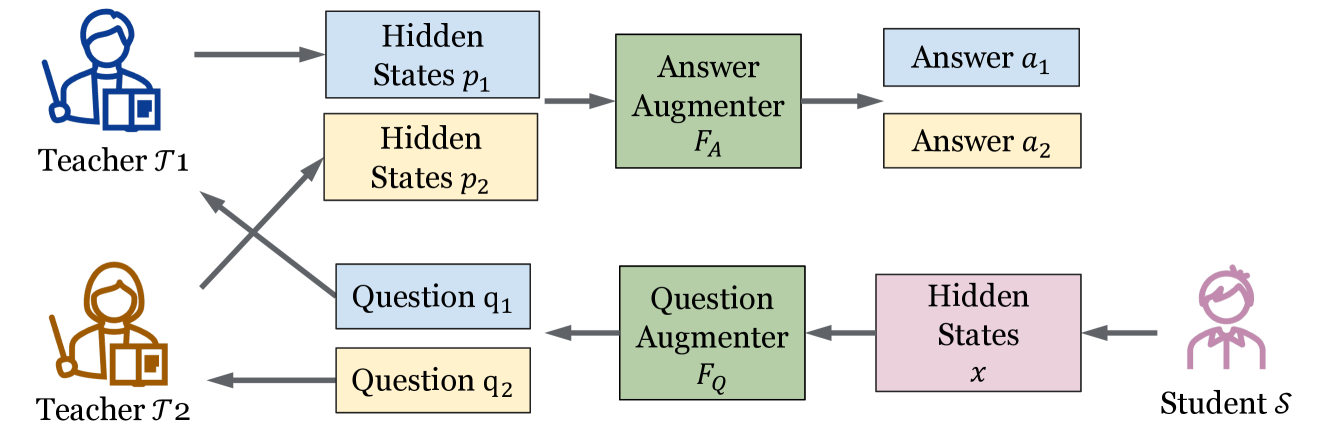 |
Paper |
Divide-or-Conquer? Which Part Should You Distill Your LLM?
Zhuofeng Wu, He Bai, Aonan Zhang, Jiatao Gu, VG Vinod Vydiswaran, Navdeep Jaitly, Yizhe Zhang |
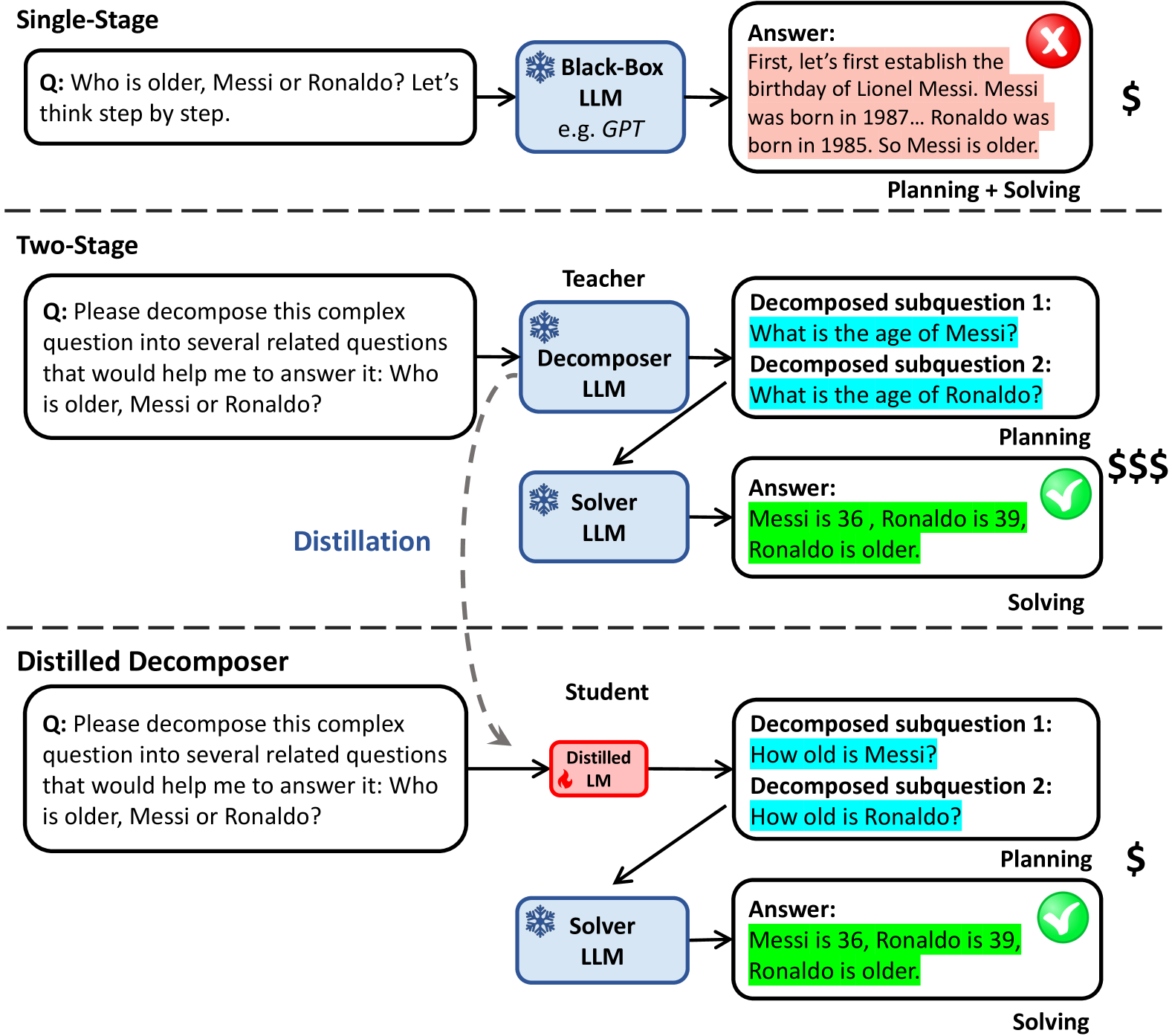 |
Paper |

Distillation Contrastive Decoding: Improving LLMs Reasoning with Contrastive Decoding and Distillation
Phuc Phan, Hieu Tran, Long Phan |
 |
Github
Paper |
Leveraging Zero-Shot Prompting for Efficient Language Model Distillation
Lukas Vöge, Vincent Gurgul, Stefan Lessmann |
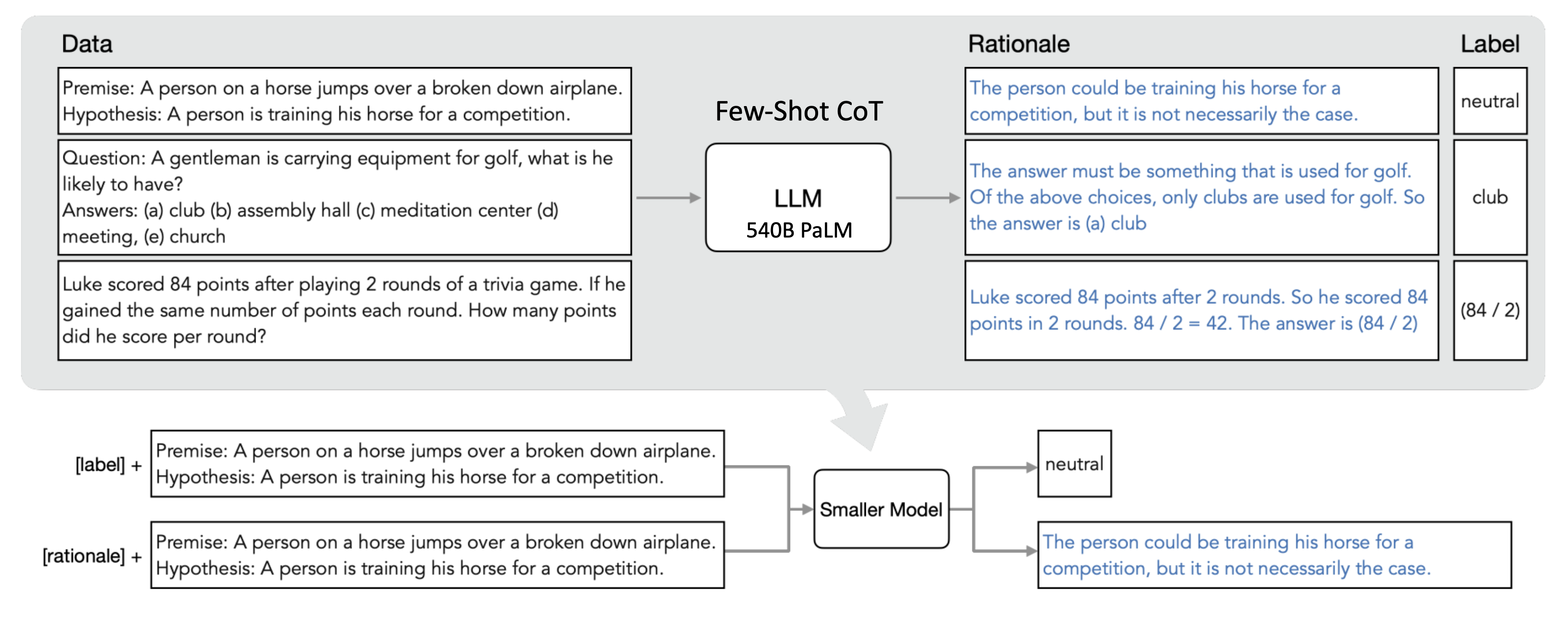 |
Paper |

MetaIE: Distilling a Meta Model from LLM for All Kinds of Information Extraction Tasks
Letian Peng, Zilong Wang, Feng Yao, Zihan Wang, Jingbo Shang |
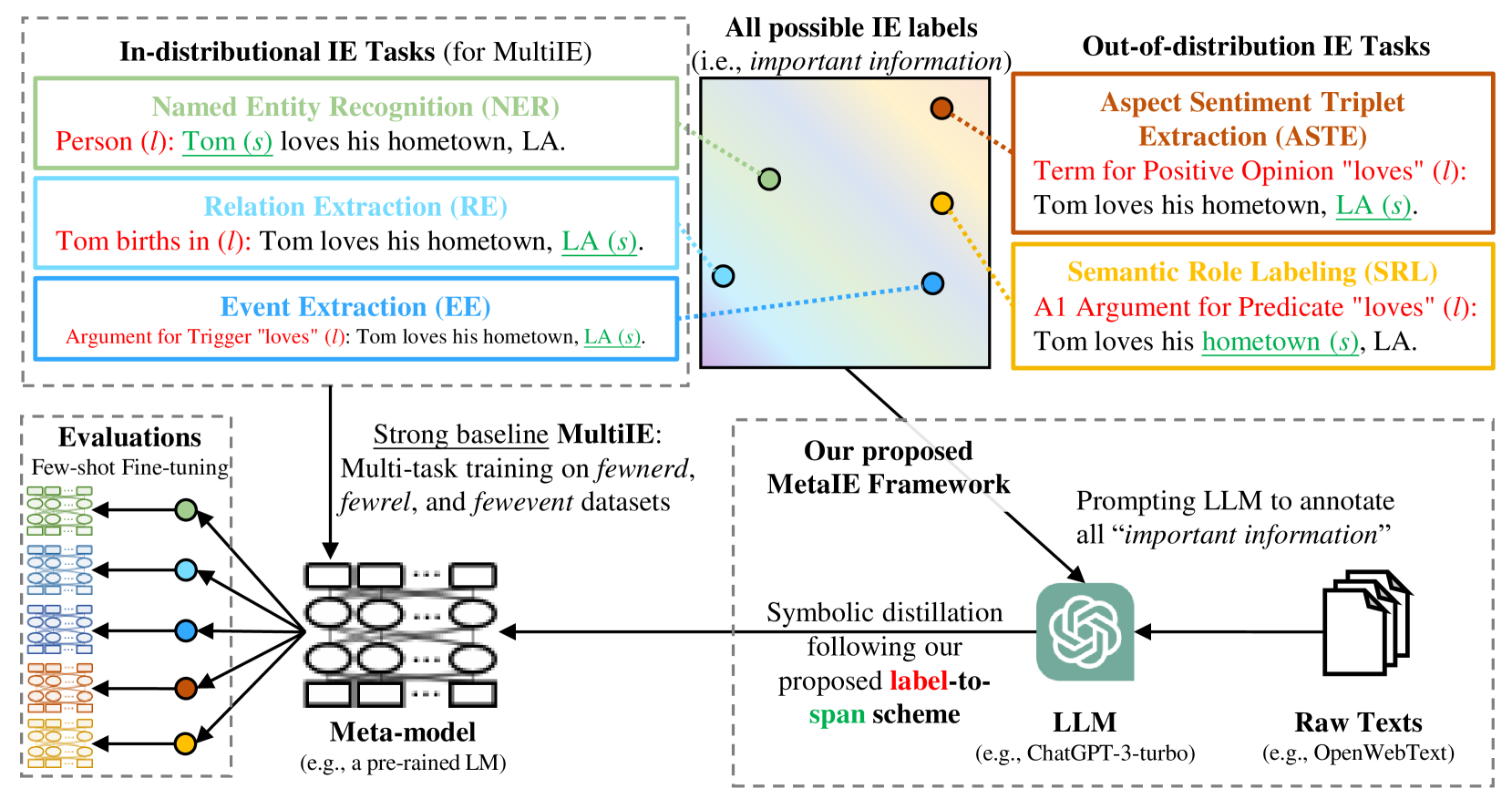 |
Github
Paper
Model |
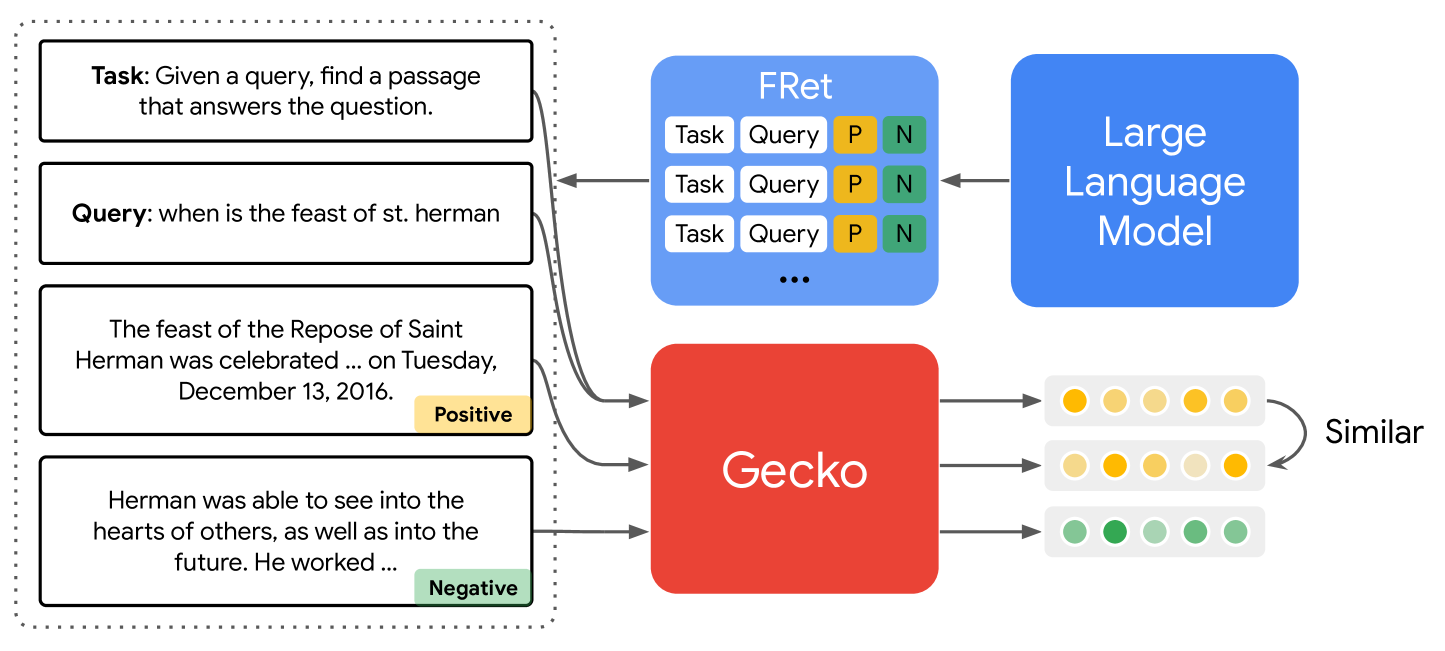
Gecko: Versatile Text Embeddings Distilled from Large Language Models
Jinhyuk Lee, Zhuyun Dai, Xiaoqi Ren, Blair Chen, Daniel Cer et al |
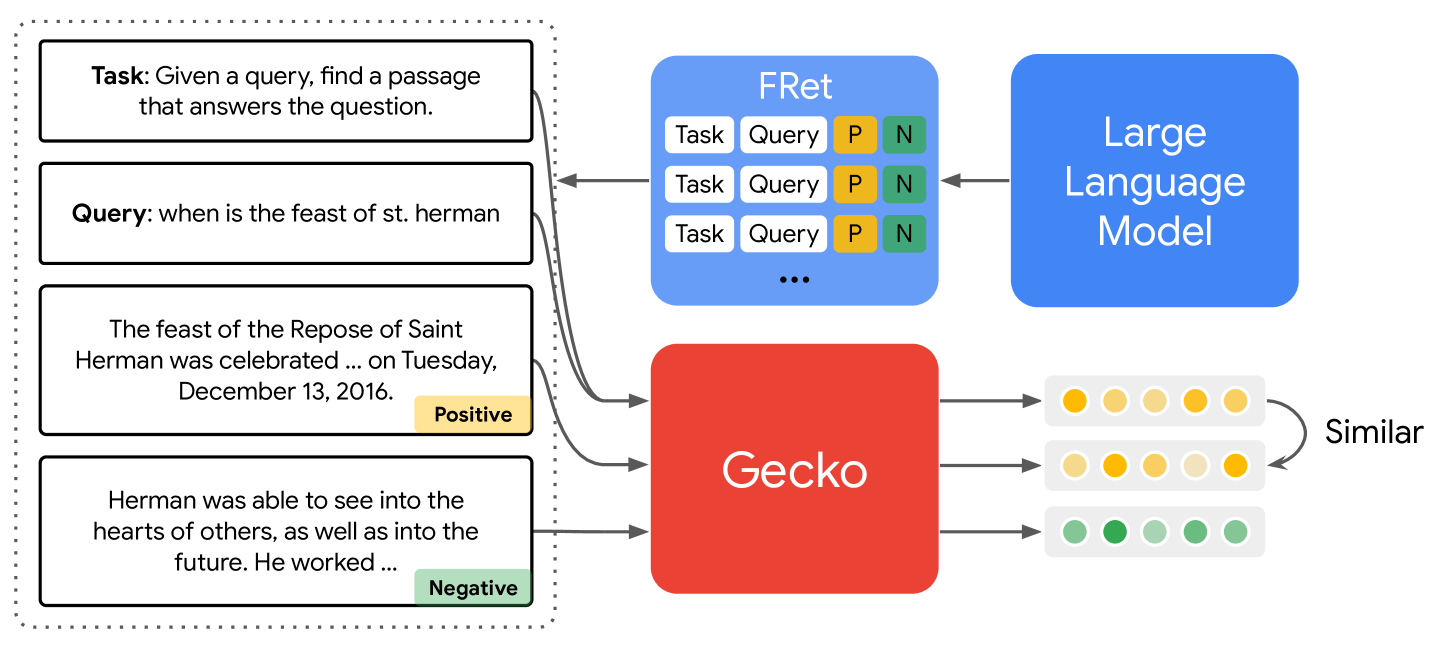 |
Paper |
Rethinking Kullback-Leibler Divergence in Knowledge Distillation for Large Language Models
Taiqiang Wu, Chaofan Tao, Jiahao Wang, Zhe Zhao, Ngai Wong |
 |
Paper
Blog-Eng
Blog-中 |
Post-Semantic-Thinking: A Robust Strategy to Distill Reasoning Capacity from Large Language Models
Xiaoshu Chen, Sihang Zhou, Ke Liang, Xinwang Liu |
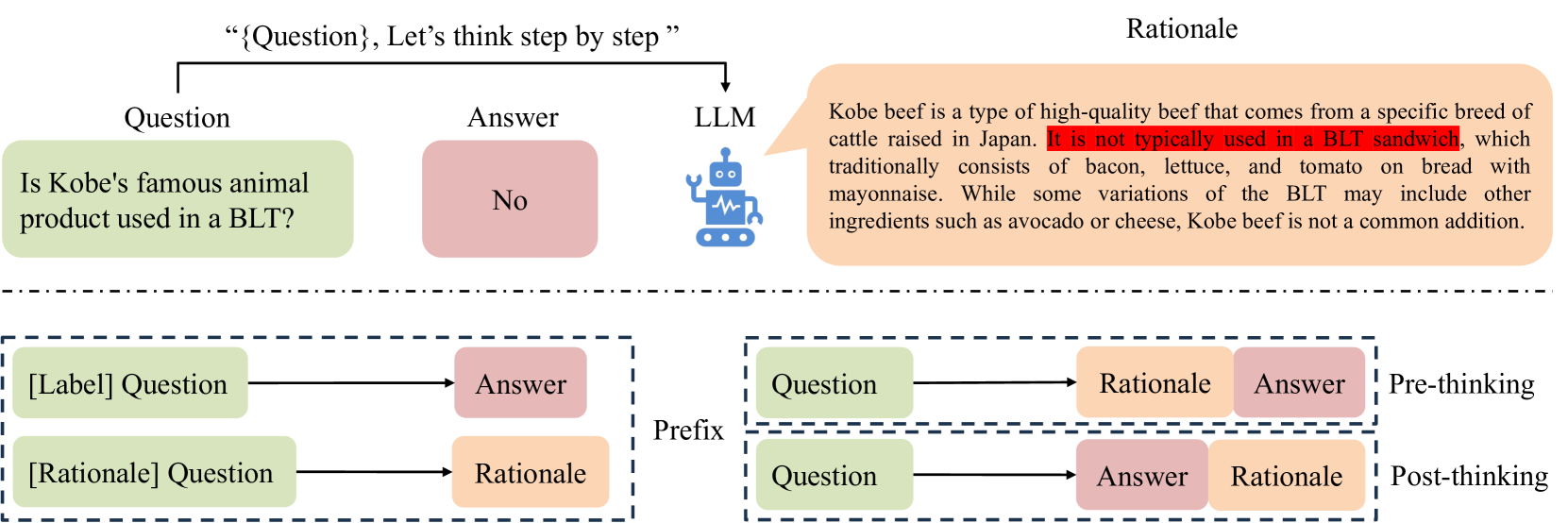 |
Paper |
Compressing Long Context for Enhancing RAG with AMR-based Concept Distillation
Kaize Shi, Xueyao Sun, Qing Li, Guandong Xu |
 |
Paper |
Distilling Instruction-following Abilities of Large Language Models with Task-aware Curriculum Planning
Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang |
 |
Paper |
 
RDRec: Rationale Distillation for LLM-based Recommendation
Xinfeng Wang, Jin Cui, Yoshimi Suzuki, Fumiyo Fukumoto |
 |
Github
Paper |
LLM and GNN are Complementary: Distilling LLM for Multimodal Graph Learning
Junjie Xu, Zongyu Wu, Minhua Lin, Xiang Zhang, Suhang Wang |
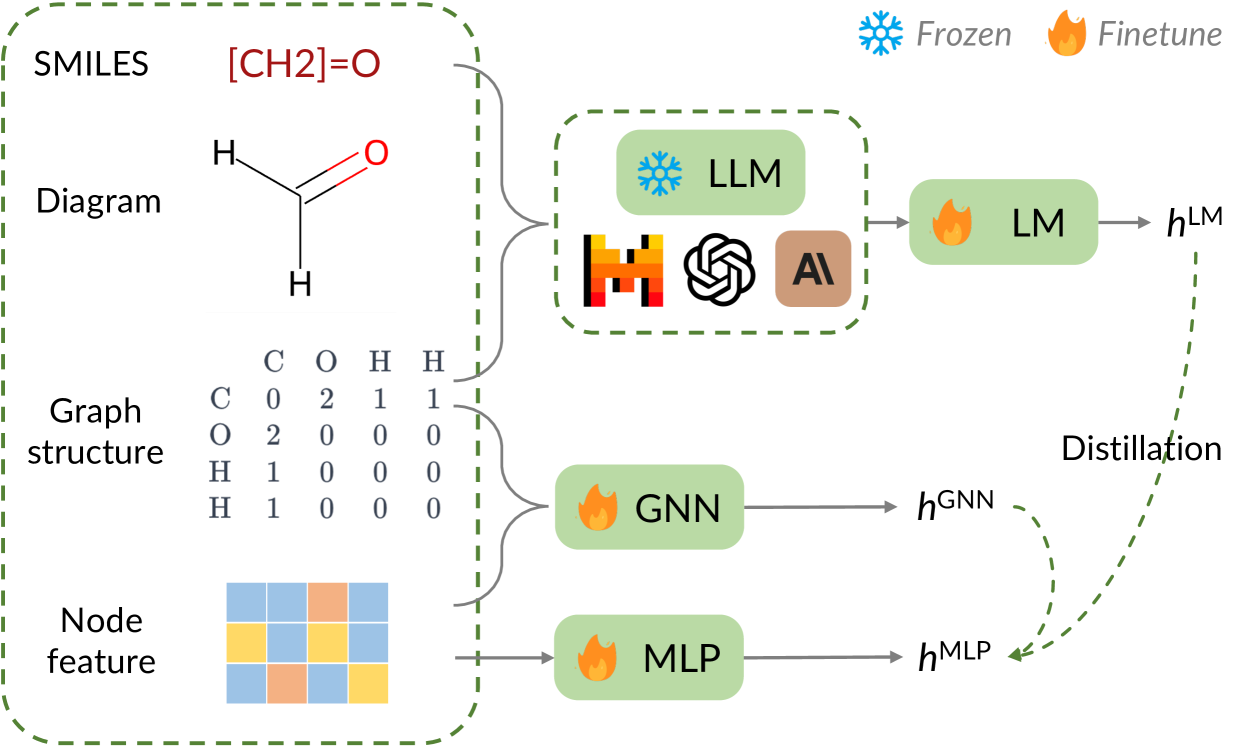 |
Paper |

Adversarial Moment-Matching Distillation of Large Language Models
Chen Jia |
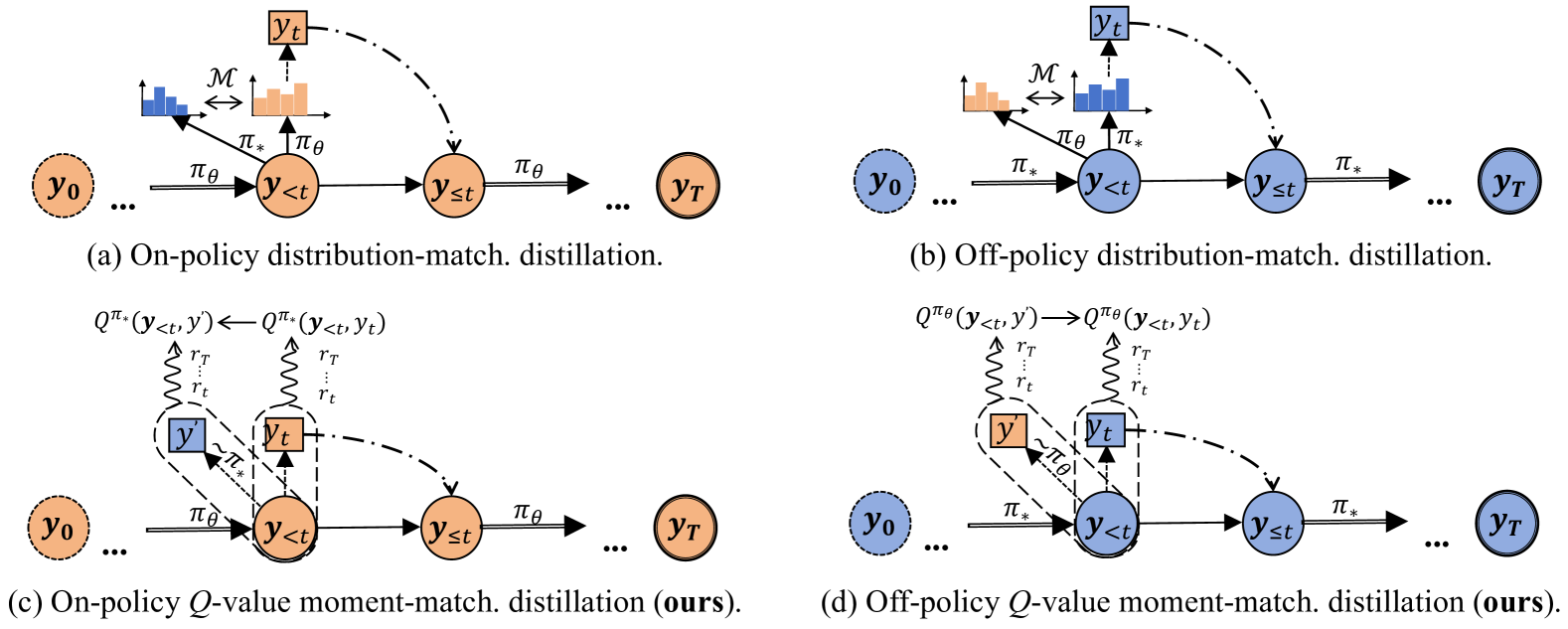 |
Github
Paper |
BiLD: Bi-directional Logits Difference Loss for Large Language Model Distillation
Minchong Li, Feng Zhou, Xiaohui Song |
 |
Paper |
Multi-Granularity Semantic Revision for Large Language Model Distillation
Xiaoyu Liu, Yun Zhang, Wei Li, Simiao Li, Xudong Huang, Hanting Chen, Yehui Tang, Jie Hu, Zhiwei Xiong, Yunhe Wang |
 |
Paper |
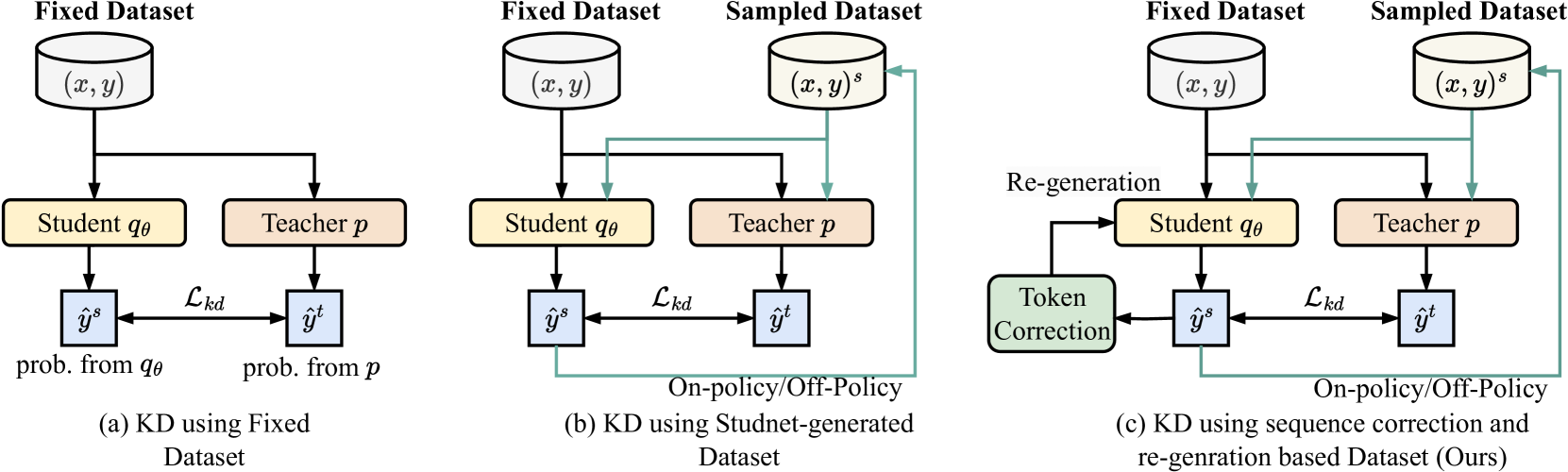
Don't Throw Away Data: Better Sequence Knowledge Distillation
Jun Wang, Eleftheria Briakou, Hamid Dadkhahi, Rishabh Agarwal, Colin Cherry, Trevor Cohn |
|
Paper |
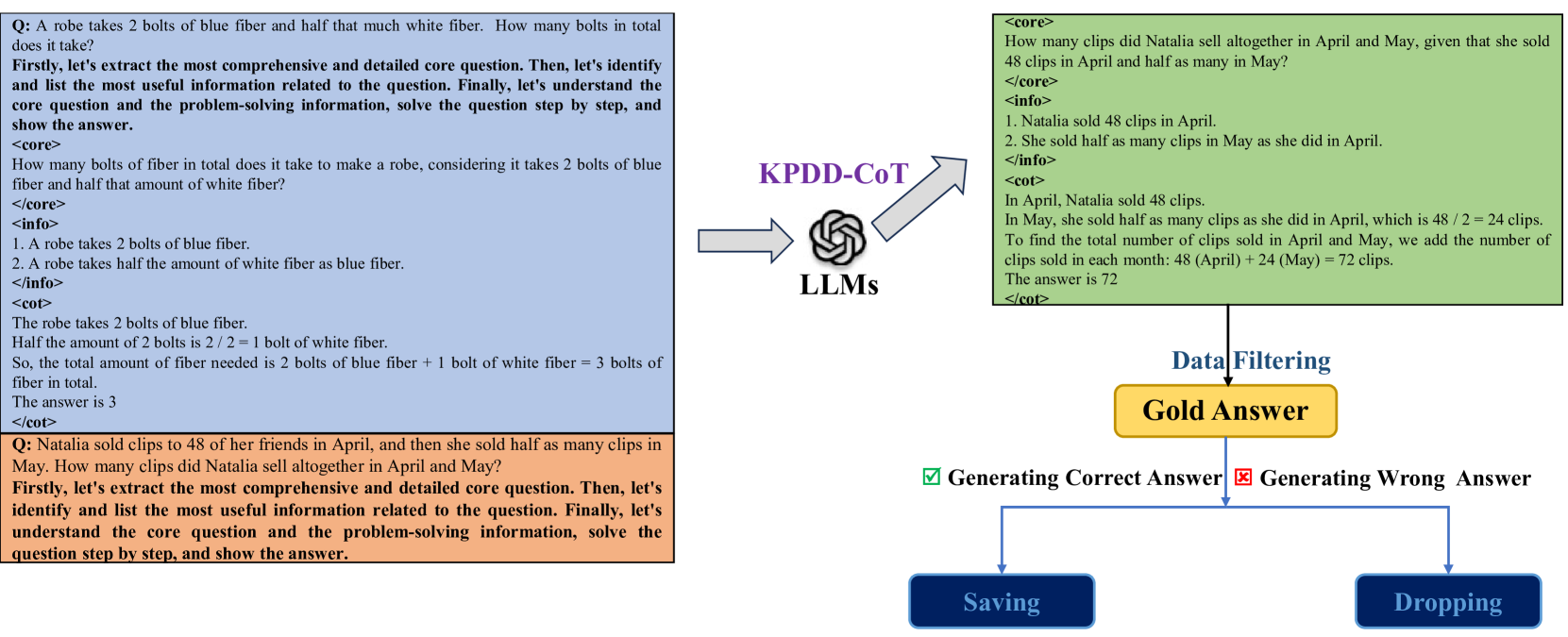
Key-Point-Driven Mathematical Reasoning Distillation of Large Language Model
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, Weiping Wang |
 |
Paper |
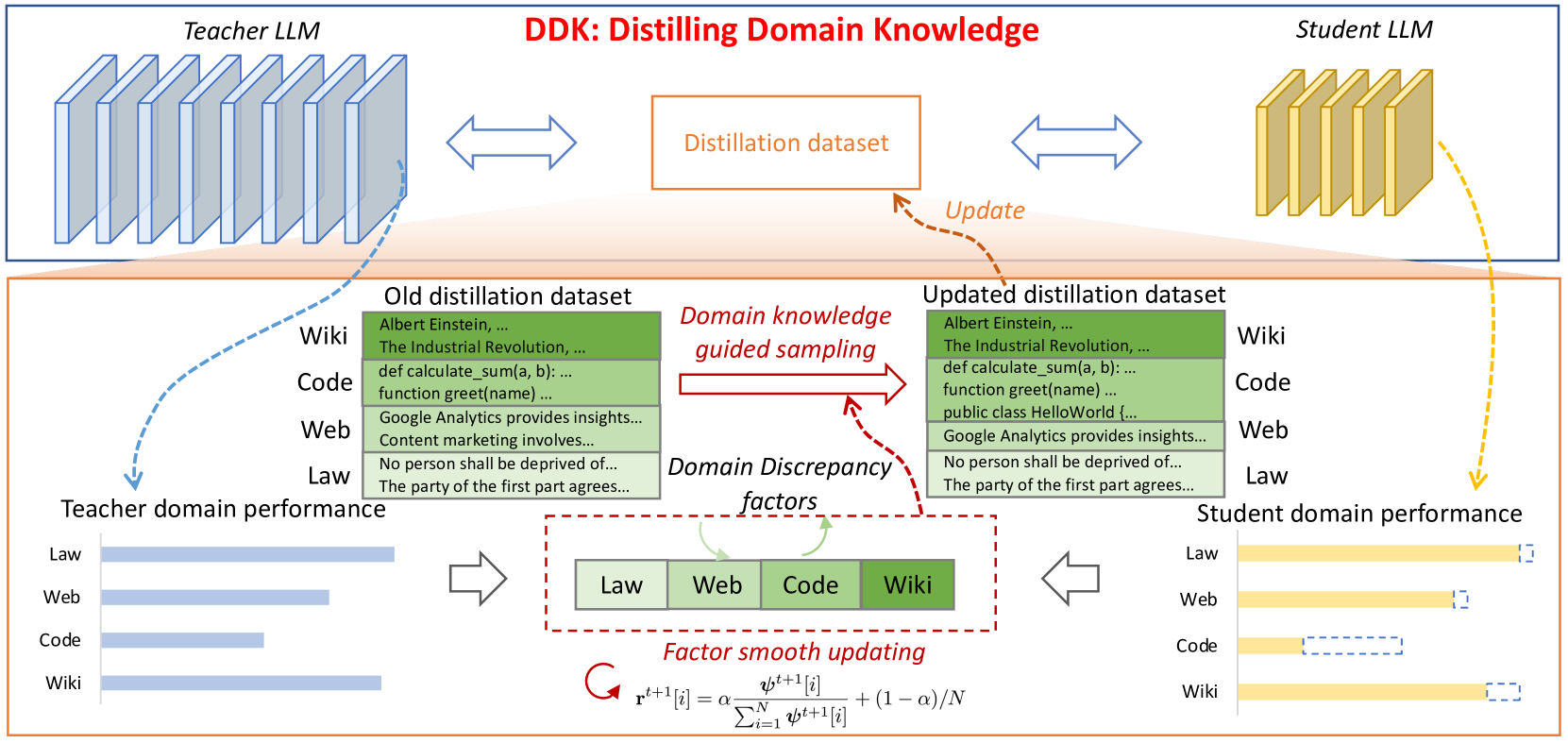
DDK: Distilling Domain Knowledge for Efficient Large Language Models
Jiaheng Liu, Chenchen Zhang, Jinyang Guo, Yuanxing Zhang, Haoran Que, Ken Deng, Zhiqi Bai, Jie Liu, Ge Zhang, Jiakai Wang, Yanan Wu, Congnan Liu, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng |
 |
Paper |
Enhancing Data-Limited Graph Neural Networks by Actively Distilling Knowledge from Large Language Models
Quan Li, Tianxiang Zhao, Lingwei Chen, Junjie Xu, Suhang Wang |
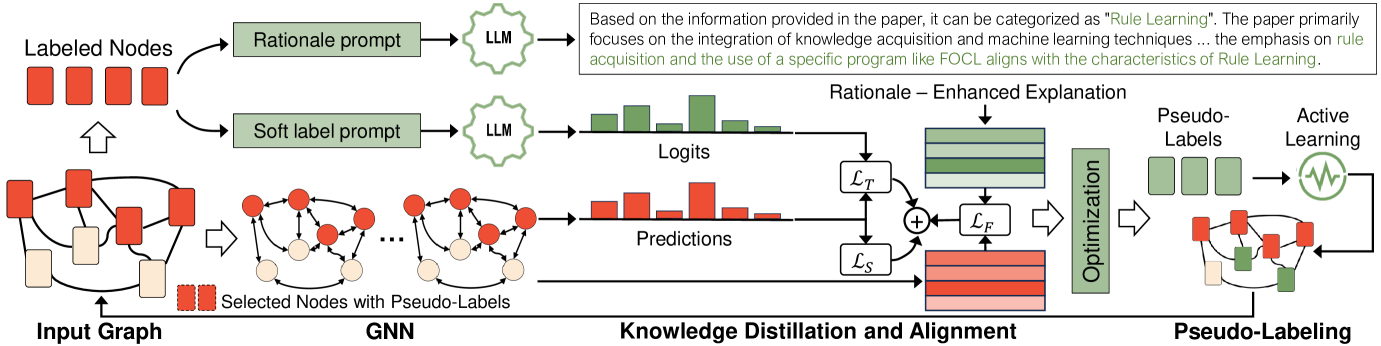 |
Paper |
BOND: Aligning LLMs with Best-of-N Distillation
Pier Giuseppe Sessa, Robert Dadashi, Léonard Hussenot, Johan Ferret, Nino Vieillard et al |
 |
Paper |
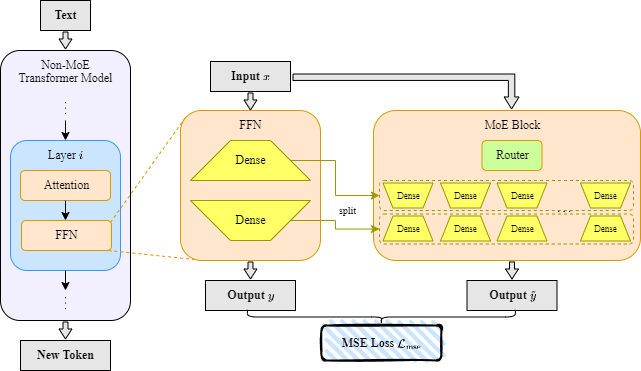
LaDiMo: Layer-wise Distillation Inspired MoEfier
Sungyoon Kim, Youngjun Kim, Kihyo Moon, Minsung Jang |
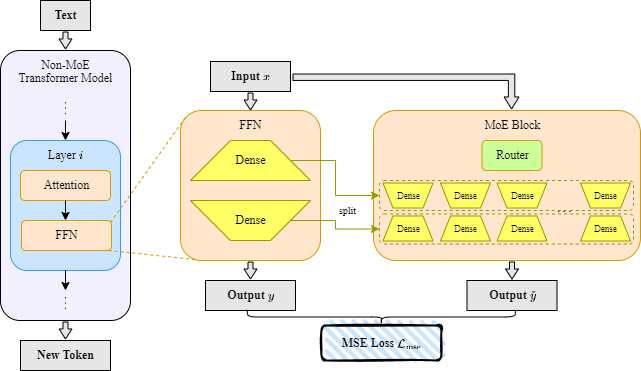 |
Paper |
Transformers to SSMs: Distilling Quadratic Knowledge to Subquadratic Models
Aviv Bick, Kevin Y. Li, Eric P. Xing, J. Zico Kolter, Albert Gu |
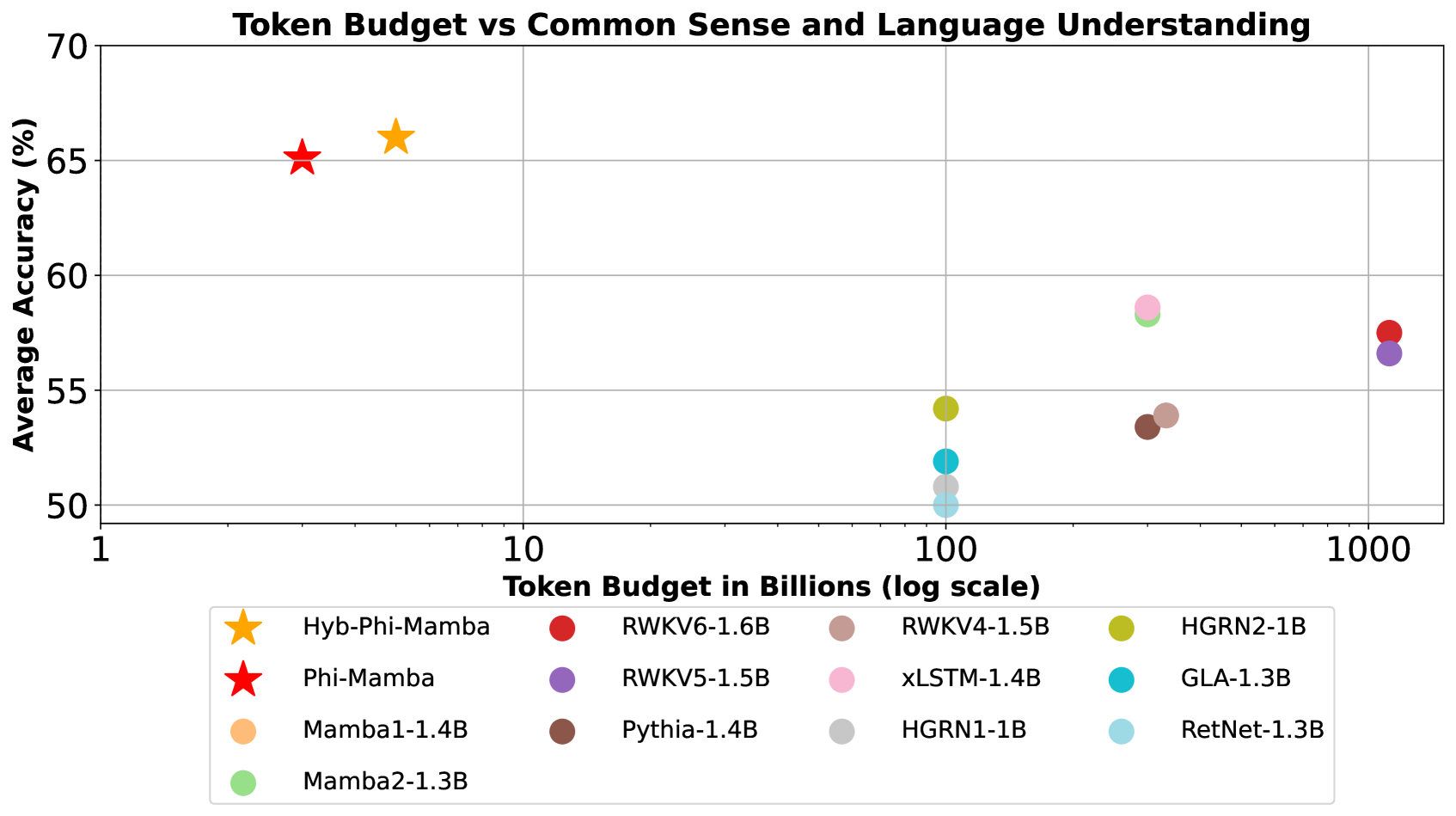 |
Paper |
Concept Distillation from Strong to Weak Models via Hypotheses-to-Theories Prompting
Emmanuel Aboah Boateng, Cassiano O. Becker, Nabiha Asghar, Kabir Walia, Ashwin Srinivasan, Ehi Nosakhare, Victor Dibia, Soundar Srinivasan |
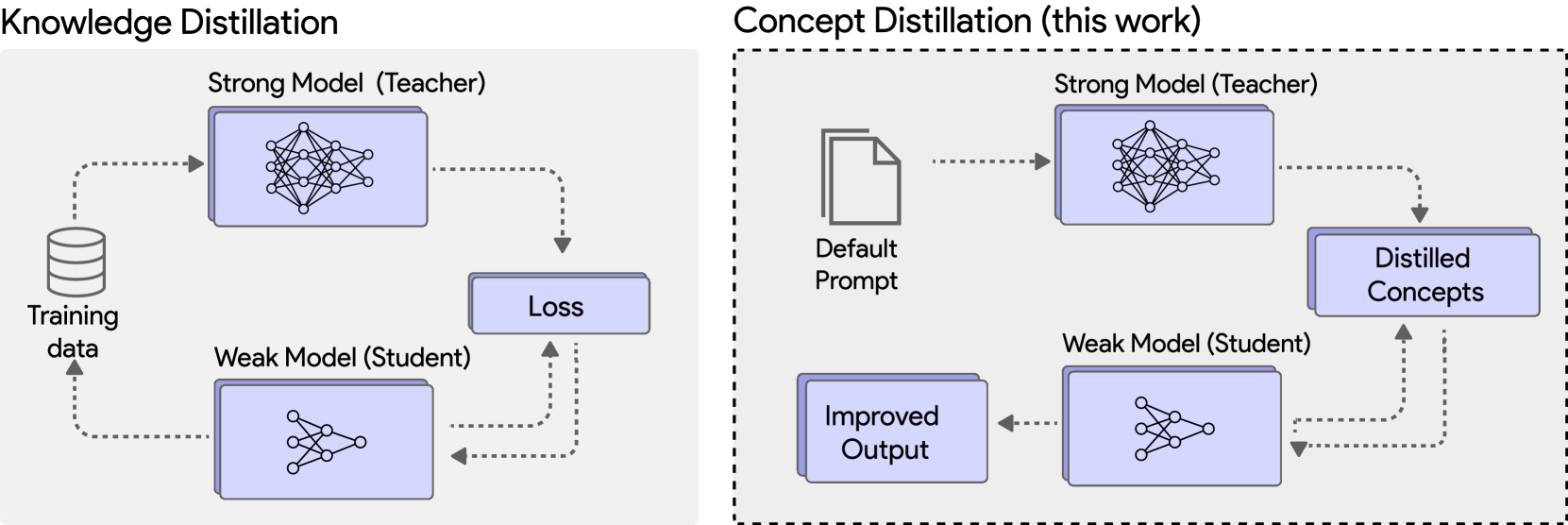 |
Paper |
Interactive DualChecker for Mitigating Hallucinations in Distilling Large Language Models
Meiyun Wang, Masahiro Suzuki, Hiroki Sakaji, Kiyoshi Izumi |
 |
Paper |
FIRST: Teach A Reliable Large Language Model Through Efficient Trustworthy Distillation
KaShun Shum, Minrui Xu, Jianshu Zhang, Zixin Chen, Shizhe Diao, Hanze Dong, Jipeng Zhang, Muhammad Omer Raza |
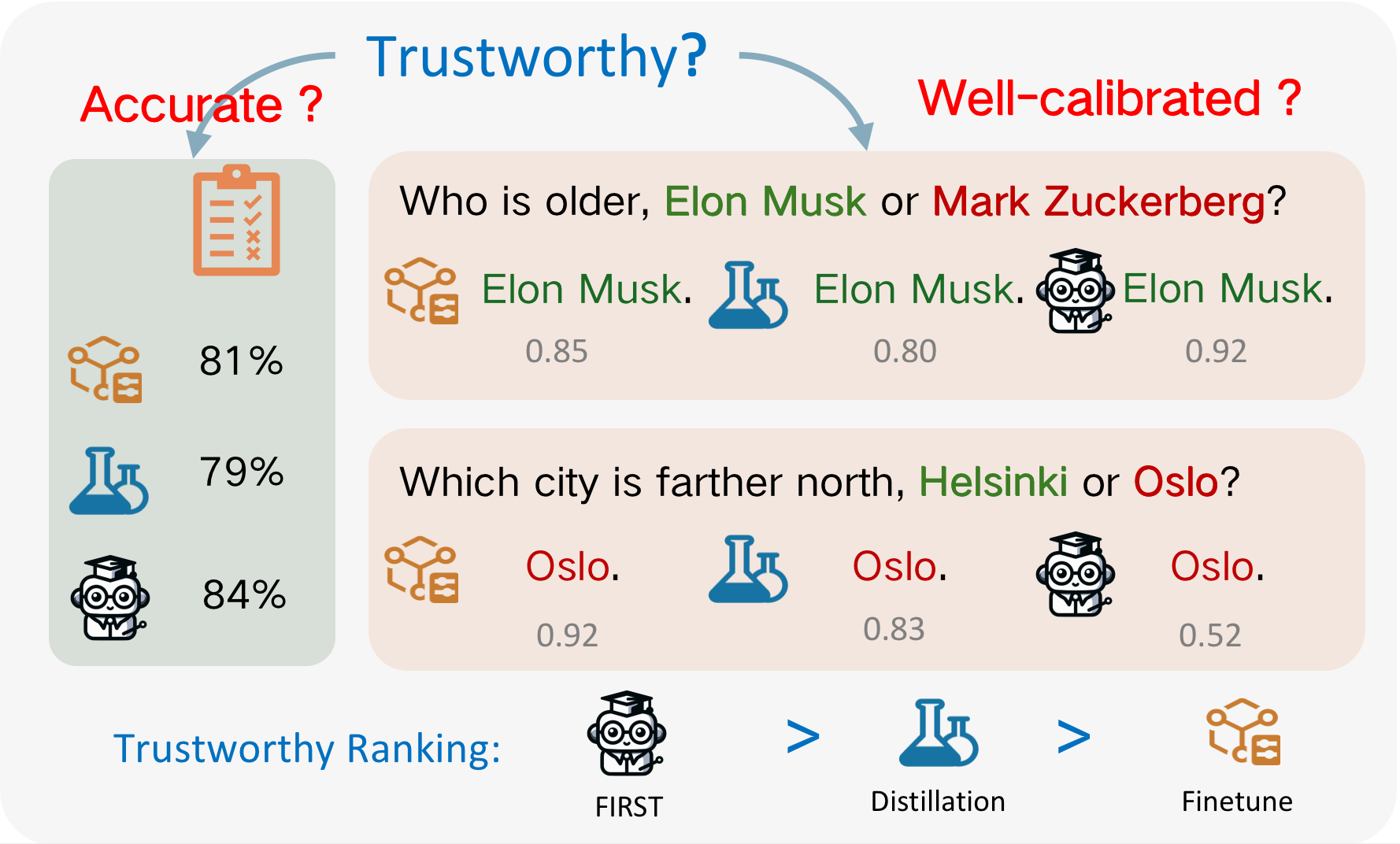 |
Paper |

The Mamba in the Llama: Distilling and Accelerating Hybrid Models
Junxiong Wang, Daniele Paliotta, Avner May, Alexander M. Rush, Tri Dao |
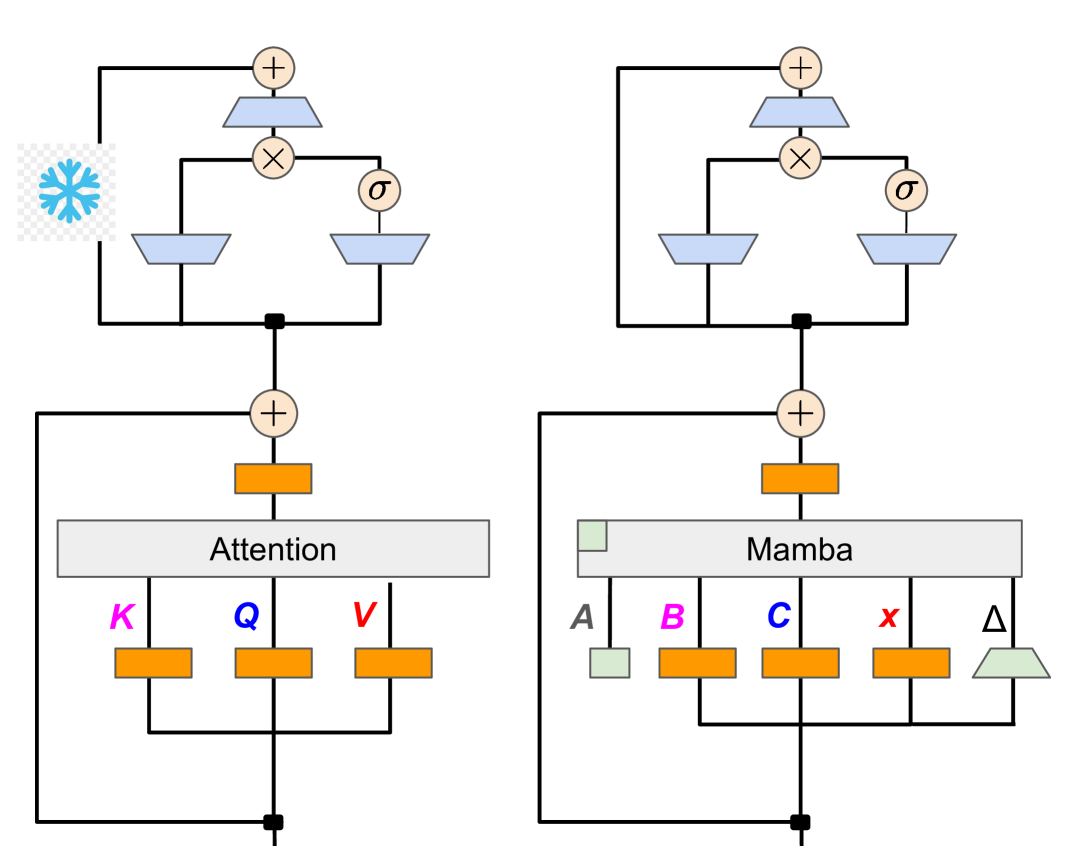 |
Github
Paper |
Efficient Knowledge Distillation: Empowering Small Language Models with Teacher Model Insights
Mohamad Ballout, Ulf Krumnack, Gunther Heidemann, Kai-Uwe Kühnberger |
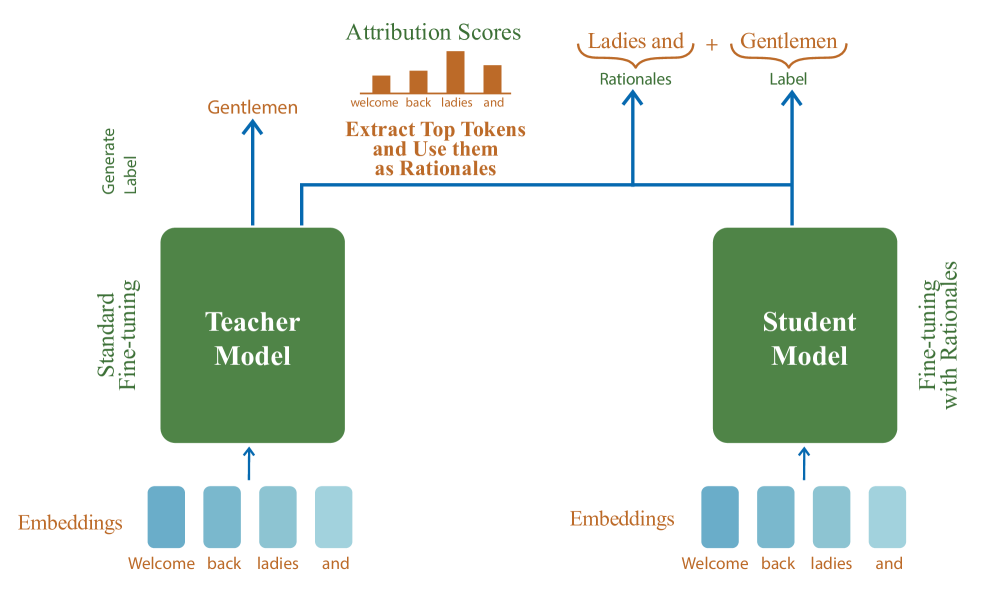 |
Paper |
Exploring and Enhancing the Transfer of Distribution in Knowledge Distillation for Autoregressive Language Models
Jun Rao, Xuebo Liu, Zepeng Lin, Liang Ding, Jing Li, Dacheng Tao |
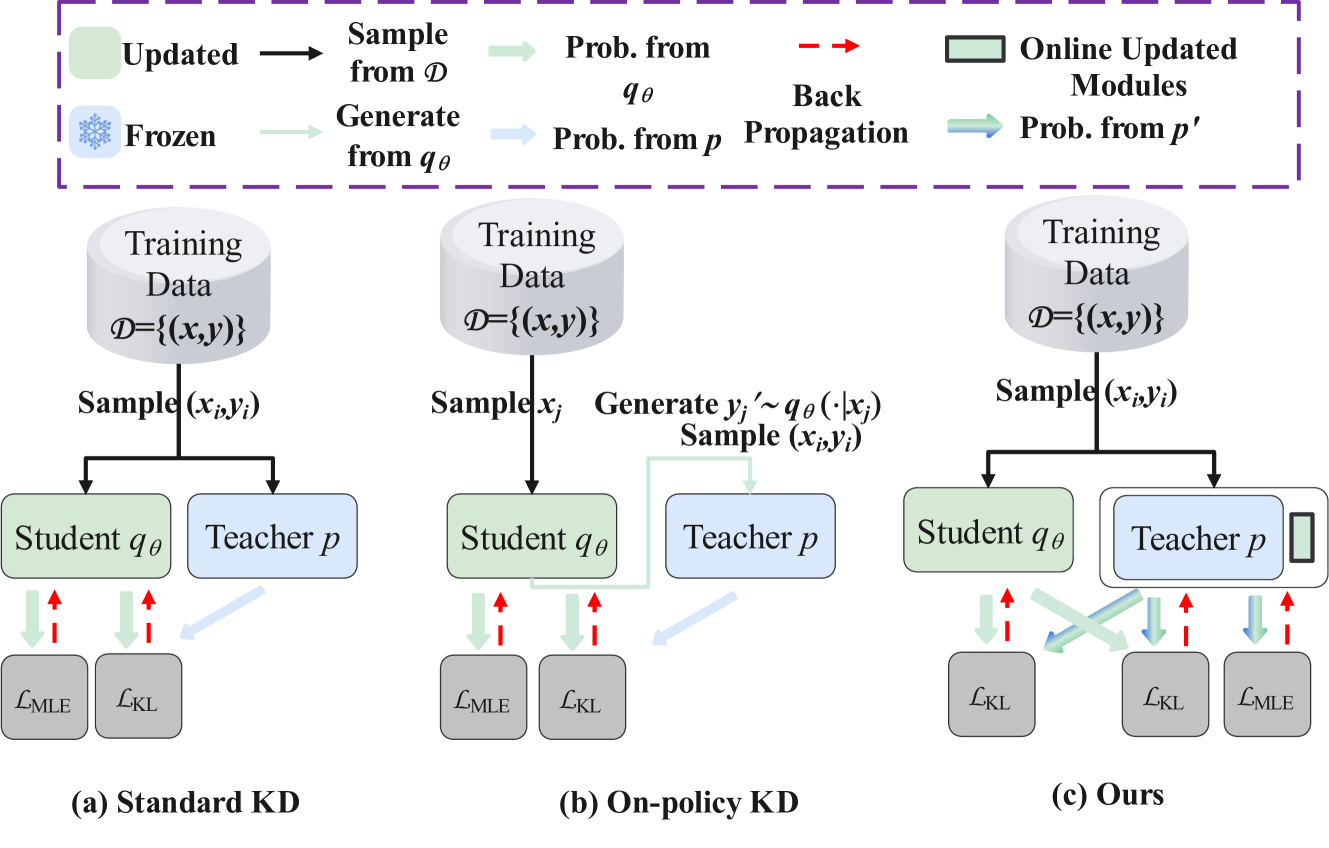 |
Paper |
 
LLMR: Knowledge Distillation with a Large Language Model-Induced Reward
Dongheng Li, Yongchang Hao, Lili Mou |
 |
Github
Paper |
EchoAtt: Attend, Copy, then Adjust for More Efficient Large Language Models
Hossein Rajabzadeh, Aref Jafari, Aman Sharma, Benyamin Jami, Hyock Ju Kwon, Ali Ghodsi, Boxing Chen, Mehdi Rezagholizadeh |
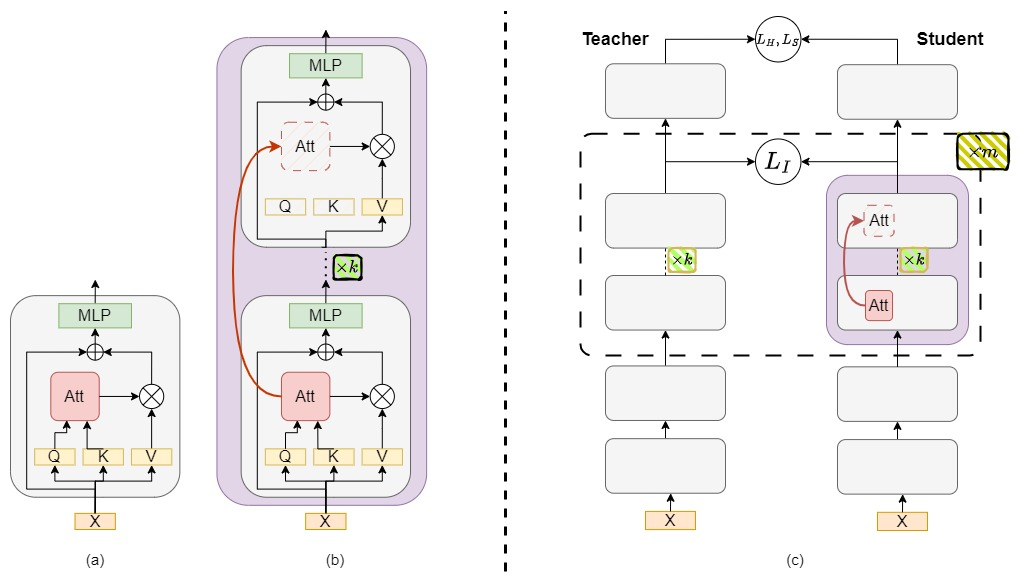 |
Paper |
BabyLlama-2: Ensemble-Distilled Models Consistently Outperform Teachers With Limited Data
Jean-Loup Tastet, Inar Timiryasov |
|
Paper |
Evolutionary Contrastive Distillation for Language Model Alignment
Julian Katz-Samuels, Zheng Li, Hyokun Yun, Priyanka Nigam, Yi Xu, Vaclav Petricek, Bing Yin, Trishul Chilimbi |
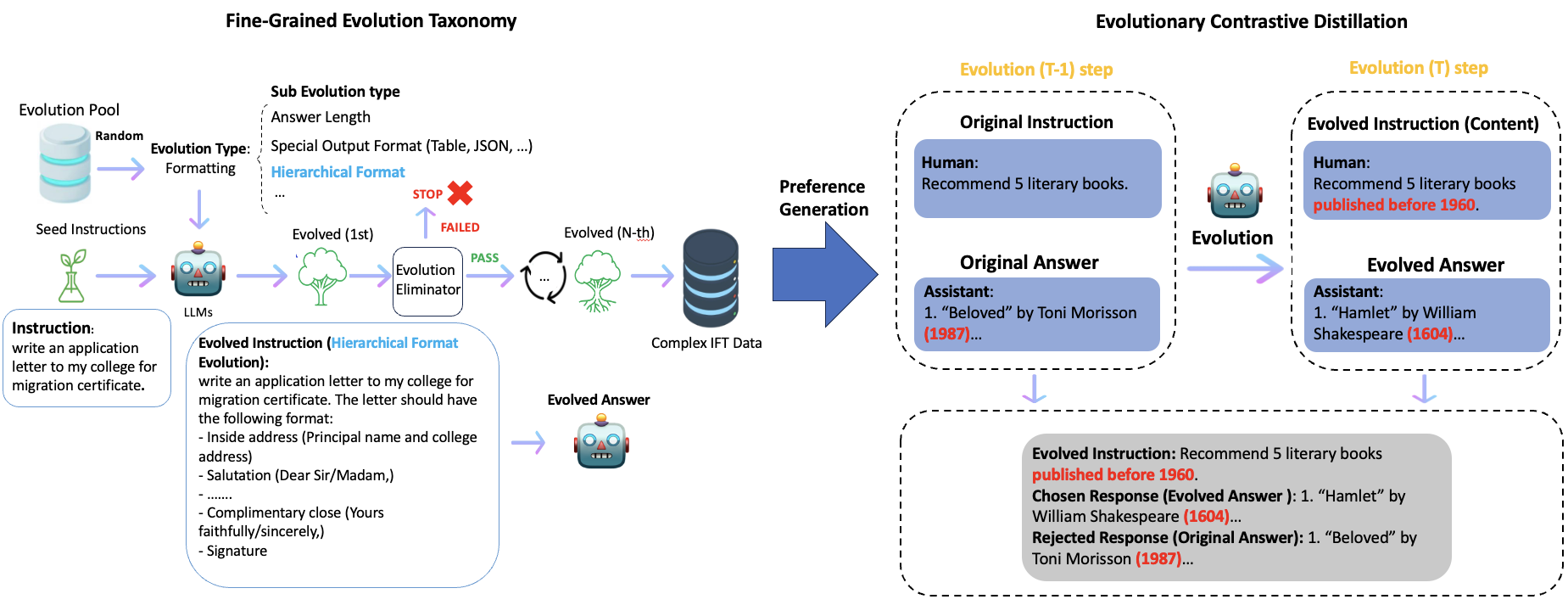 |
Paper |
Speculative Knowledge Distillation: Bridging the Teacher-Student Gap Through Interleaved Sampling
Wenda Xu, Rujun Han, Zifeng Wang, Long T. Le, Dhruv Madeka, Lei Li, William Yang Wang, Rishabh Agarwal, Chen-Yu Lee, Tomas Pfister |
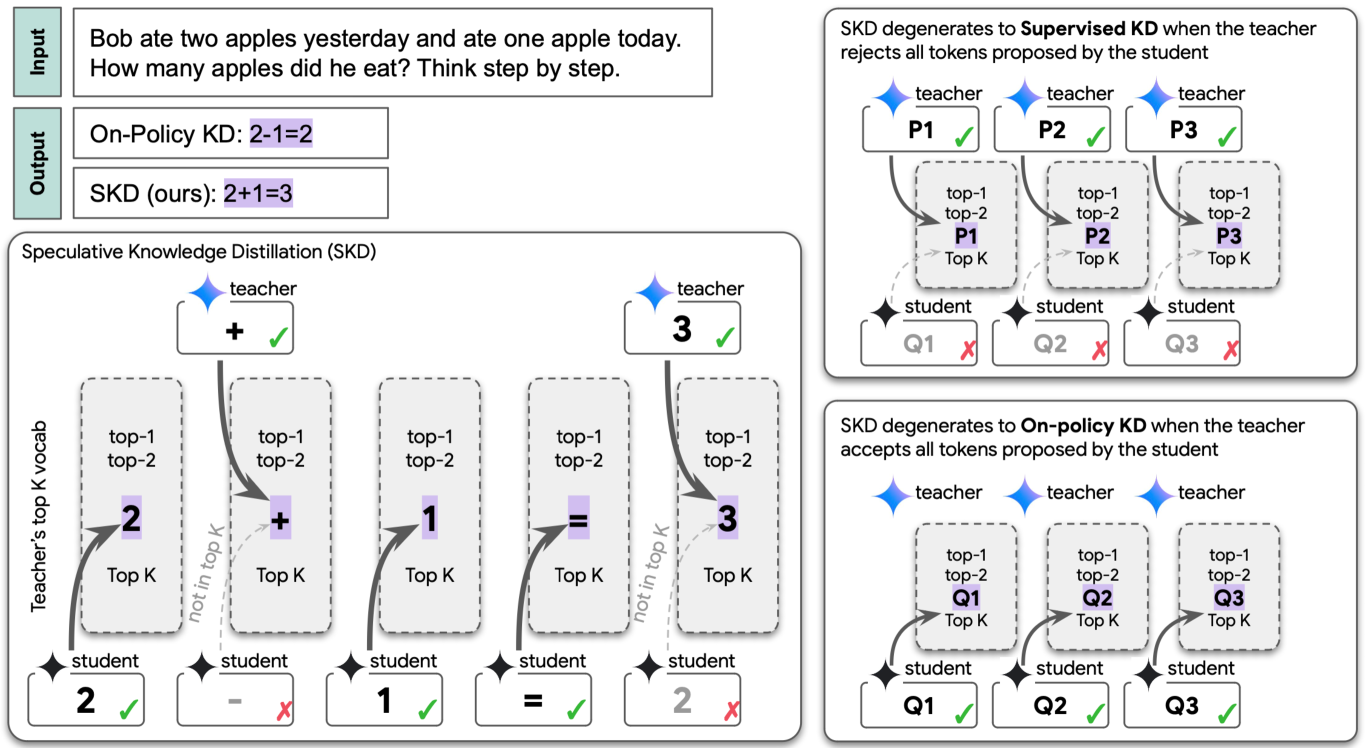 |
Paper |

MiniPLM: Knowledge Distillation for Pre-Training Language Models
Yuxian Gu, Hao Zhou, Fandong Meng, Jie Zhou, Minlie Huang |
 |
Github
Paper |
Pre-training Distillation for Large Language Models: A Design Space Exploration
Hao Peng, Xin Lv, Yushi Bai, Zijun Yao, Jiajie Zhang, Lei Hou, Juanzi Li |
|
Paper |

Beyond Autoregression: Fast LLMs via Self-Distillation Through Time
Justin Deschenaux, Caglar Gulcehre |
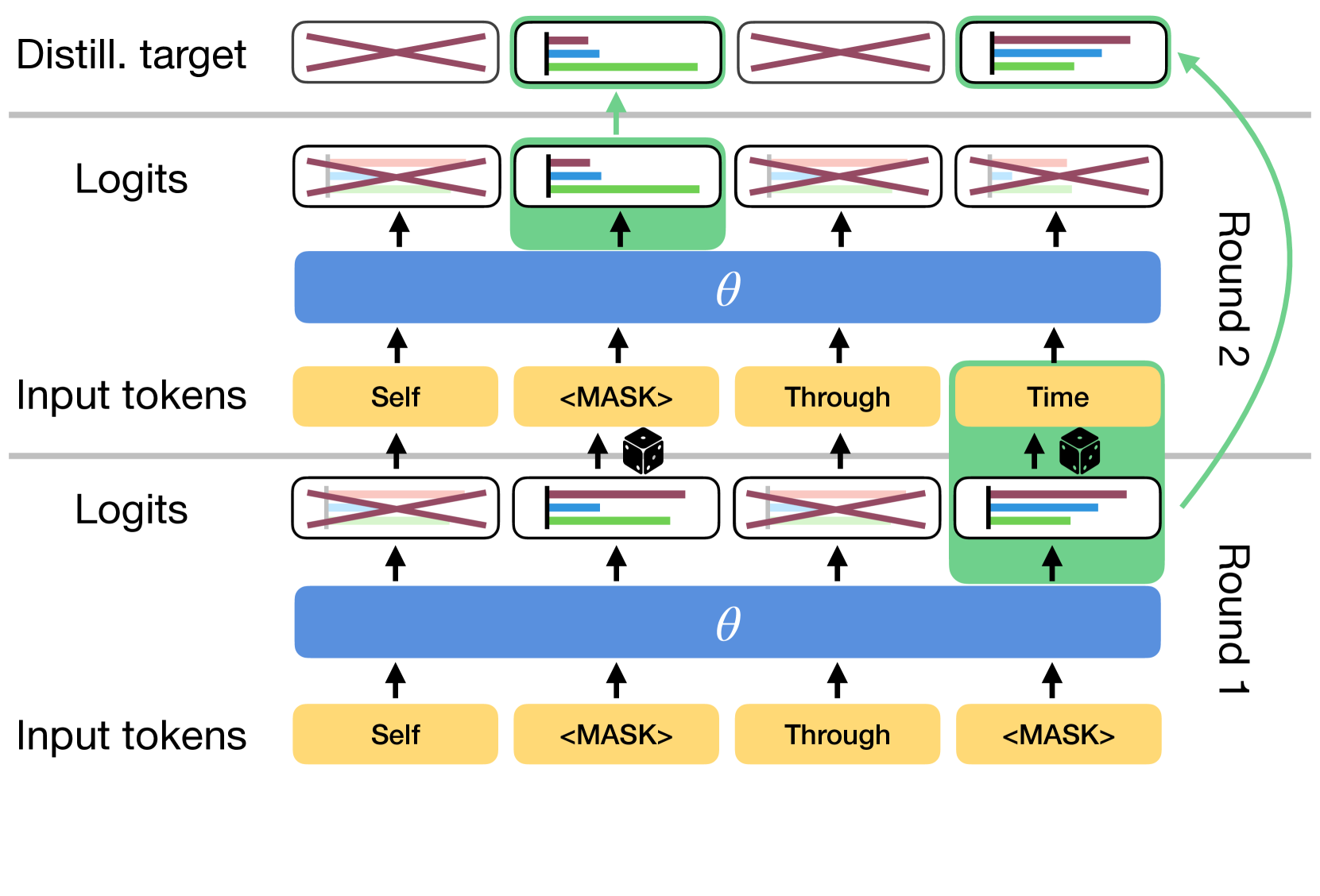 |
Github
Paper |
SWITCH: Studying with Teacher for Knowledge Distillation of Large Language Models
Jahyun Koo, Yerin Hwang, Yongil Kim, Taegwan Kang, Hyunkyung Bae, Kyomin Jung |
 |
Paper |

Generative Context Distillation
Haebin Shin, Lei Ji, Yeyun Gong, Sungdong Kim, Eunbi Choi, Minjoon Seo |
 |
Github
Paper |
Improving Mathematical Reasoning Capabilities of Small Language Models via Feedback-Driven Distillation
Xunyu Zhu, Jian Li, Can Ma, Weiping Wang |
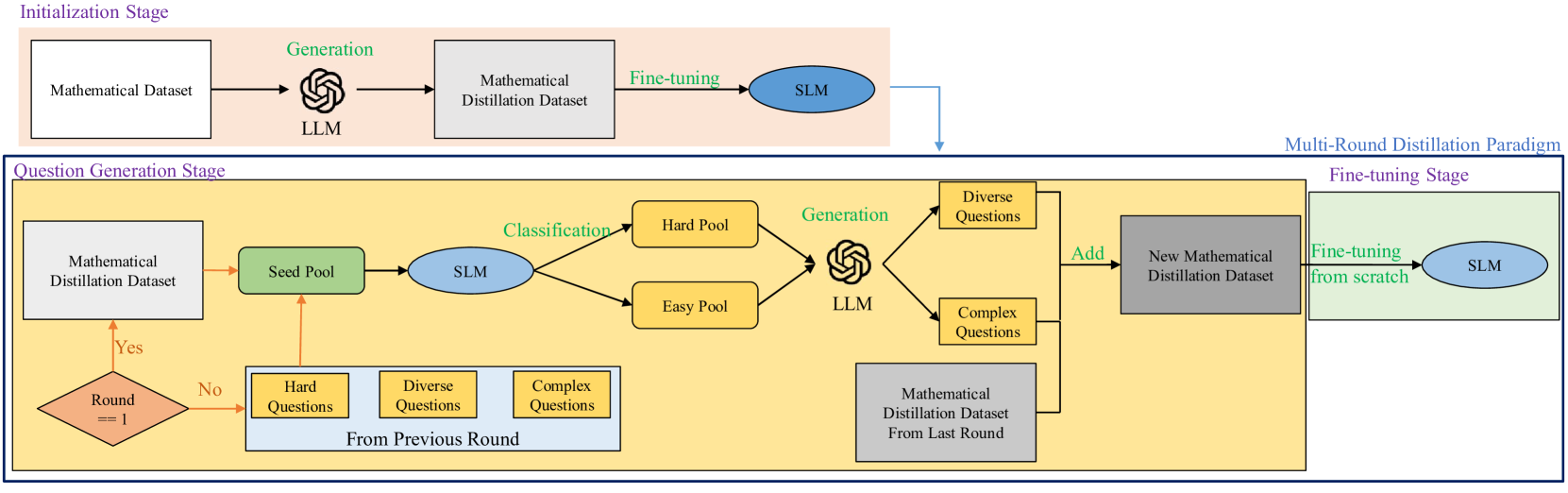 |
Paper |

Distilling Fine-grained Sentiment Understanding from Large Language Models
Yice Zhang, Guangyu Xie, Hongling Xu, Kaiheng Hou, Jianzhu Bao, Qianlong Wang, Shiwei Chen, Ruifeng Xu |
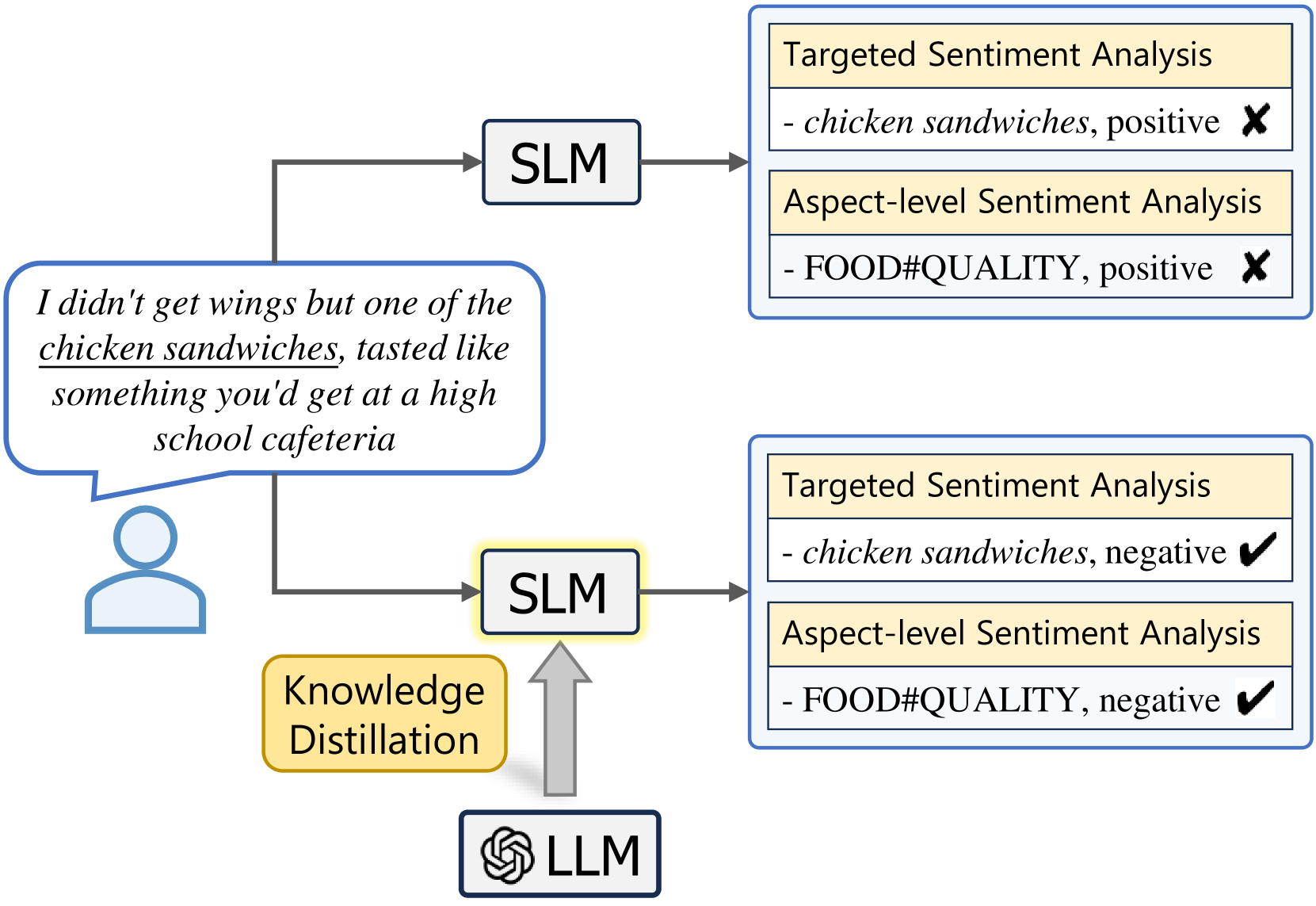 |
Github
Paper |

Enhancing Knowledge Distillation for LLMs with Response-Priming Prompting
Vijay Goyal, Mustafa Khan, Aprameya Tirupati, Harveer Saini, Michael Lam, Kevin Zhu |
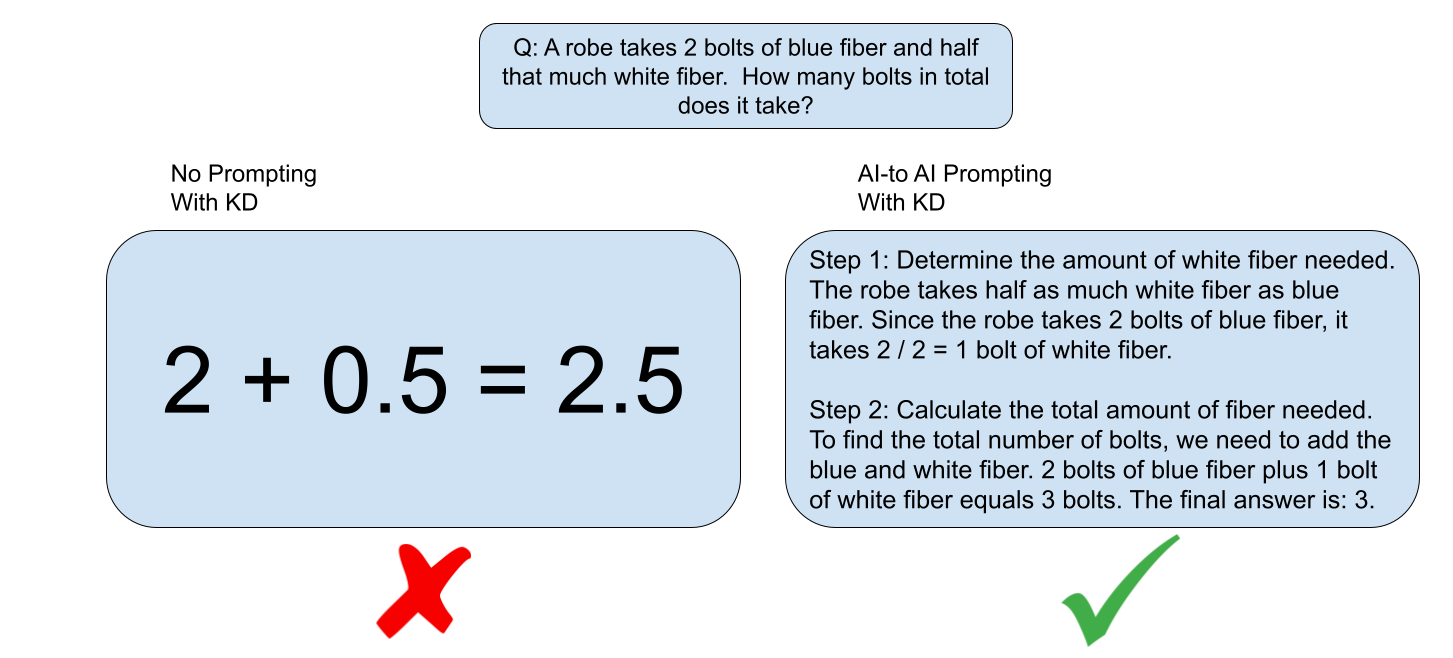 |
Github
Paper |
Large Language Models Compression via Low-Rank Feature Distillation
Yaya Sy, Christophe Cerisara, Irina Illina |
 |
Paper |

Self-Evolution Knowledge Distillation for LLM-based Machine Translation
Yuncheng Song, Liang Ding, Changtong Zan, Shujian Huang |
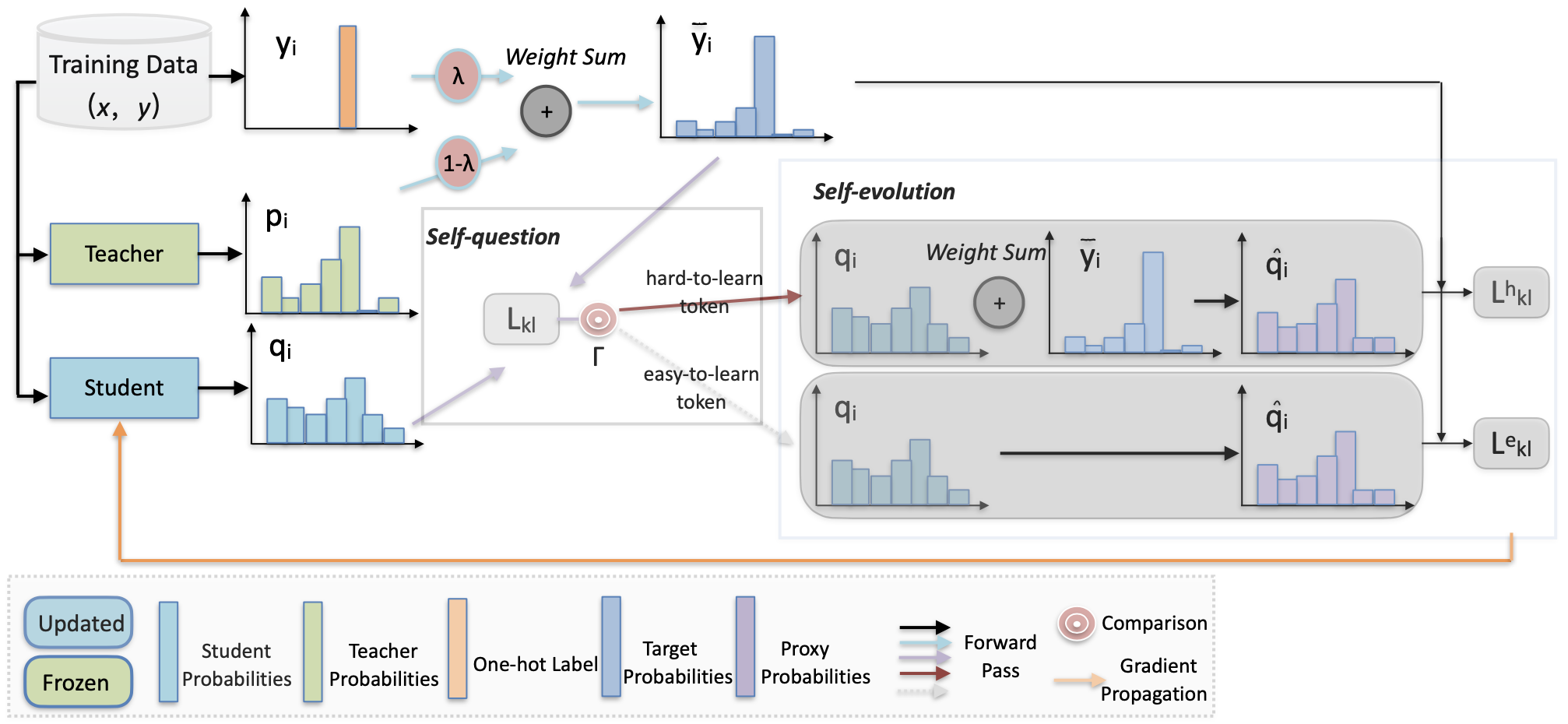 |
Paper |