By Justin Deschenaux and Caglar Gulcehre.
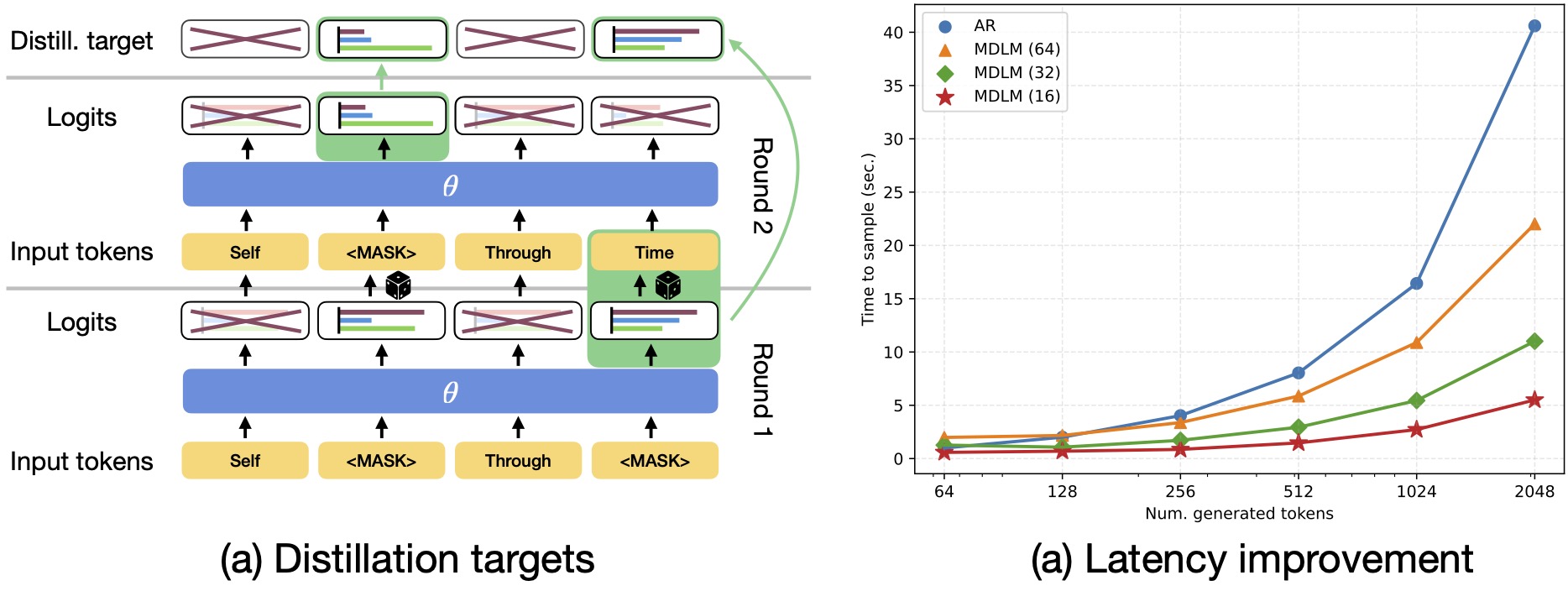
- We present Self-Distillation Through Time (SDTT), a novel method to distill discrete diffusion language models. SDTT is design to sample with few steps (less than 64), while retaining the quality of samples generated with 1024 sampling steps.
- SDTT teaches the diffusion language model to match the distribution of samples generated with 1024 steps, using few steps. It requires generating distillation targets, with the approach visualized in the above figure, and teaching a student model to match the teacher targets through a divergence measure
$d$ between the teacher (many sampling steps) and the student (few sampling steps). - We obtain our best results using the reverse KL divergence. In particular, the KLD was the only divergence measure that retained or improved performance when decreasing the number of steps.
- We evaluate the performance of the student in generative perplexity, using the MAUVE metric, and on the LAMBADA natural language understanding benchmark.
- To run examples, you need to install our code first.
- To install, run:
git clone https://github.com/jdeschena/sdtt.git
pushd sdtt
pip install -r requirements.txt
pip install flash-attn
pip install --pre torchdata --index-url https://download.pytorch.org/whl/nightly/cpu
pip install -e .
popd- We released 3 groups of models:
- The baseline students distilled with the
kld,mseandtvdobjectives, distilled from a model trained for 1M steps. - The students from the scaling experiments, with sizes
sm,md,large, distilled from models trained for 400k steps. - The teachers from the scaling experiments, with sizes
sm,md,large, before any distillation.
- The baseline students distilled with the
- To load those models, first install our code (see previous section).
from sdtt import load_mdlm_small
mldm_small = load_mdlm_small() from sdtt import load_small_student
student = load_small_student(loss="kld", round=7) # load the kld student after the last distillation round
student = load_small_student(loss="mse", round=2) # load the mse student after the second distillation round
student = load_small_student(loss="tvd", round=1) # load the tvd student after the first distillation roundfrom sdtt import load_scaling_student
student = load_scaling_student(size="sm", round=7) # load small student after the last distillation round
student = load_scaling_student(size="md", round=1) # load medium student after the first distillation round
student = load_scaling_student(size="large", round=3) # load large student after the third distillation roundfrom sdtt import load_scaling_teacher
student = load_scaling_student(size="sm",) # load small teacher
student = load_scaling_student(size="md",) # load medium teacher
student = load_scaling_student(size="large",) # load large teacherfrom sdtt import load_small_student, load_scaling_student, load_scaling_teacher
import torch
model = load_small_student(loss="kld", round=7) # load model, see above
model.cuda() # put model on gpu
# Unconditional generation
tokens = model.sample(
n_samples=8,
num_steps=256,
seq_len=1024,
verbose=True,
)
# Detokenize
uncond_text = model.tokenizer.batch_decode(tokens)
# Conditional generation, based on a prompt
# Prepare a prompt
prompt = "Today is a great day. The sun is shining,"
prompt_tokens = model.tokenizer(prompt)["input_ids"]
prompt_tokens.insert(0, model.tokenizer.bos_token_id)
prompt_tokens = torch.tensor(prompt_tokens, device="cuda")
prompt_len = len(prompt_tokens)
def project_fn(x):
# Project the first 10 tokens of all examples to the prompt
x[:, :prompt_len] = prompt_tokens
return x # Don't forget to return
tokens = model.sample(
n_samples=8,
num_steps=256,
seq_len=1024,
verbose=True,
project_fn=project_fn
)
cond_text = model.tokenizer.batch_decode(tokens)Distill the pre-trained MDLM of Sahoo et al.
python src/sdtt/main.py \
mode=train \
parameterization.num_distill_steps=2 \
model=dit-orig-small \
time_conditioning=False \
loader.global_batch_size=128 \
loader.batch_size=32 \
trainer.max_steps=80000 \
hydra.run.dir="./outputs/distill_2_steps_from_hf_sm" \
loader.num_workers=16 \
compile=False \
trainer.val_check_interval=5000 \
data_preprocess.data_cache=./data_cache \
wandb.project=debug- First, you need to train a model using the original MDLM codebase.
- For example, you could train medium-sized mdlm (460M) parameters. See
src/sdtt/configs/model/dit-orig-medium.yamlfor the hyperparameters.
python src/sdtt/main.py \
mode=train \
parameterization.start_from_hf=False \
model=dit-orig-medium \
parameterization.checkpoint_path=<REPLACE_BY:path_to_mdlm_code>/outputs/openwebtext/mdlm_md/checkpoints/0-1000000.ckpt \
parameterization.num_distill_steps=2 \
time_conditioning=False \
loader.global_batch_size=128 \
loader.batch_size=16 \
trainer.max_steps=80000 \
hydra.run.dir="./outputs/distill_2_steps_md" \
loader.num_workers=16 \
compile=False \
trainer.val_check_interval=5000 \
data_preprocess.data_cache=./data_cache \
wandb.project=debug- To evaluate the generation quality, you must sample from the model.
- The samples are saved in the run directory (defined by the config key
hydra.run.dir), in the sub-foldersamples. - You can specify the checkpoint to use with the argument
checkpointing.resume_ckpt_path. The argument to use is different than for training, since for training we load a teacher checkpoint to distill, while here we load the student checkpoint to sample from. - To sample unconditionally (no prompt), set
parameterization.sampling.uncond.run - To sample conditionally (prompted using the first tokens of a dataset. Default: webtext), set
parameterization.sampling.cond_prefix.run - The sampling code is paralellized over the specificed devices, as for training.
- To use a
python src/sdtt/main.py \
mode=sample \
parameterization.num_distill_steps=2 \
parameterization.start_from_hf=False \
parameterization.sampling.uncond.run=True \
parameterization.sampling.cond_prefix.run=True \
parameterization.sampling.uncond.num_steps=2 \
parameterization.sampling.cond_prefix.num_steps=2 \
model=dit-orig-medium \
parameterization.checkpoint_path=<REPLACE_BY:path_to_mdlm_code>/outputs/openwebtext/mdlm_md/checkpoints/0-1000000.ckpt \
time_conditioning=False \
loader.global_batch_size=128 \
loader.batch_size=32 \
hydra.run.dir="./outputs/distill_2_steps_md" \
trainer.val_check_interval=5000 \
data_preprocess.data_cache=./data_cache \
wandb.project=debug- After sampling, you can evaluate the generative perplexity and the mauve score. The generative perplexity is computed when
eval.ppl_with_ar.runisTrue. The mauve score is computed wheneval.mauve.runisTrue. - Evaluation on the lambada benchmark does not require sampling beforehand. The lambada evaluation is run when
eval.lambada_openai.runisTrue. - You can use
llama3to evaluate the generative perplexity instead ofgpt2-largeby setting the flageval.ppl_with_ar=llama3-8b.
python src/sdtt/main.py \
mode=eval \
eval.ppl_with_ar.run=True \
eval.mauve.run=True \
eval.lambada_openai.run=True \
hydra.run.dir="./outputs/distill_2_steps_md" \
data_preprocess.data_cache=./data_cache \
loader.num_workers=32 \
compile=True \- The entrypoint script is
src/sdtt/main.py. It can be used to train, sample and evaluate our models. The mode (train, sample, eval) is selected via themodeflag insrc/sdtt/configs/config.yaml. - We use hydra to manage config files, and all configuration files are in
src/sdtt/configs. - The implementation of the distillation algorithm is in
src/sdtt/core/distill/mdlm_double_dt_correct.py. It contains the code to compute the loss and the training loop. We use Pytorch Lightning to organize our code cleanly.
@article{deschenaux2024autoregressionfastllmsselfdistillation,
title={Beyond Autoregression: Fast LLMs via Self-Distillation Through Time},
author={Deschenaux, Justin and Gulcehre, Caglar}
eprint={2410.21035},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2410.21035},
}
Our codebase is inspired by recent discrete diffusion language models projects. Namely, MDLM and SEDD.