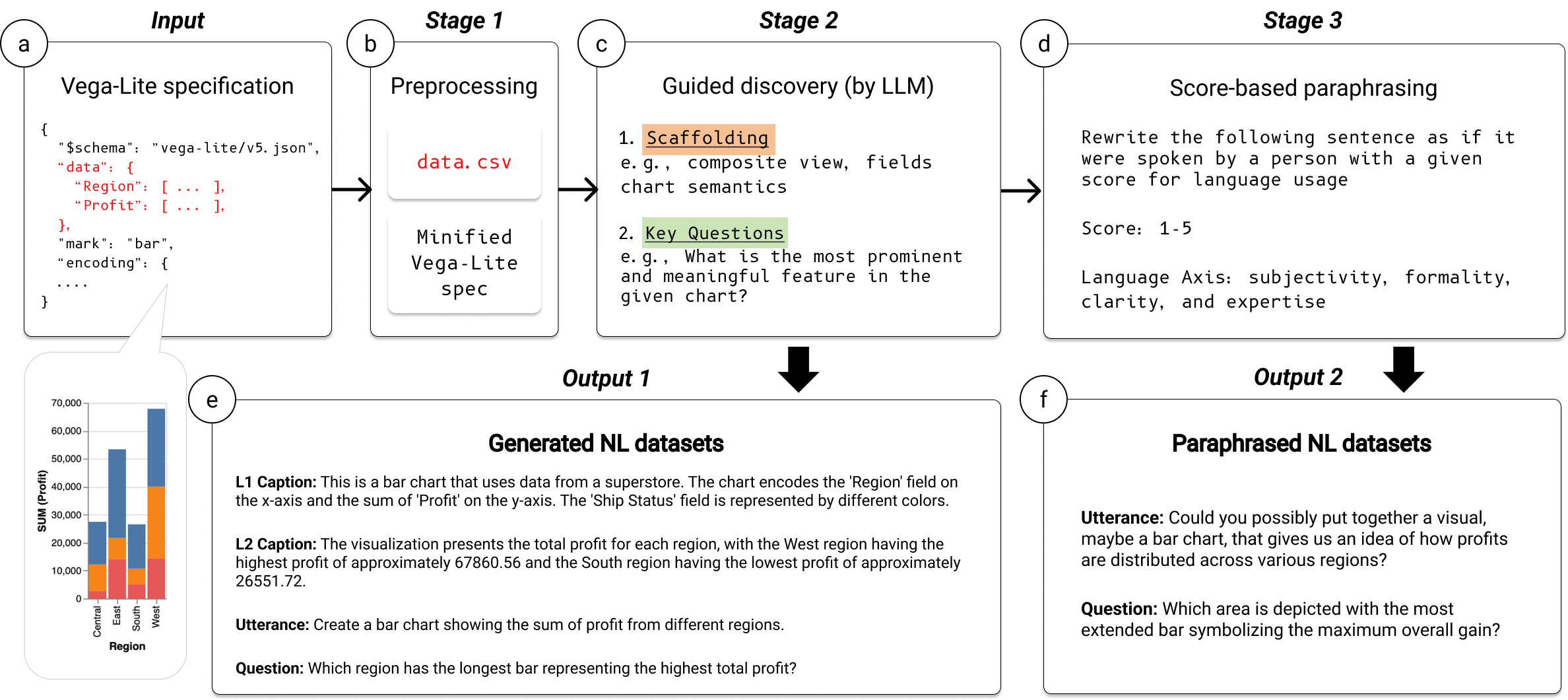
We introduce an LLM framework for generating various NL datasets from Vega-Lite specifications. Our framework comprises of two novel prompting techniques to synthesize relevant chart semantics accurately and to enhance syntactic diversity, respectively. First, we leverage guided discovery so that LLMs can steer themselves to create varying NL datasets in a self-directed manner. In detail, the framework analyzes and integrates chart semantics (e.g., mark, encoding) with our scaffolding in accordance with the characteristics of each NL dataset. Also, by answering on key questions, it autonomously concentrates on the chart’s key features or propose high-level decisions. Second, we utilize score-based paraphrasing to increase the syntactic diversity of the generated NL datasets. We define four language axes (clarity, expertise, formality, subjectivity) using automatic qualitative coding, and the framework augments the generated datasets quantitatively along these axes.

We also present a new collection of 1,981 Vega-Lite specifications, which is used to demonstrate the generalizability and viability of our NL generation framework. This collection is the largest set of human-generated charts obtained from GitHub to date. It covers varying levels of complexity from a simple line chart without any interaction (i.e., simple) to a chart with four plots where data points are linked with selection interactions (i.e., extra complex). As we focus on collecting complex charts, more than 86% of them are in complex and extra complex levels. Compared to the benchmarks, our dataset shows the highest average pairwise edit distance between specifications, which proves that the charts are highly diverse from one another. Moreover, it contains the largest number of charts with composite views, interactions (e.g., tooltips, panning & zooming, and linking), and diverse chart types (e.g., map, grid & matrix, diagram, etc.). Also refer to our website to see the charts. The metdata for charts including the licenses for each chart is presented here.
Please refer to this code:
import json
from datasets import load_dataset
dataset = load_dataset("hyungkwonko/chart-llm", data_files="data.txt")
json_data = [json.loads(data) for data in dataset["train"]["text"]]
print(f"len(json_data): {len(json_data)}")Please prepare Open-AI API KEY and locate the .env file in the root:
OPENAI_API_KEY=your-openai-api-key
To run the example codes, refer to below:
# L1 Caption Generation (Caption)
python -m framework_sample.task1_L1
# L2 Caption Generation (Caption)
python -m framework_sample.task1_L2
# Utterance (NL to Chart Generation)
python -m framework_sample.task2
# Question (Chart Question Answering)
python -m framework_sample.task3
Our paraphrasing technique is inspired by a linear interpolation in the latent space for image generation and manipulation as demonstrated in many system and application papers. It enables a smooth transition from one expression to another by focusing on creating controllable and meaningful variations of a single sentence. We employ a five-point Likert-scale and assign one of the axes to each. Here, we focus on altering only the sentence's syntax, while maintaining its meaning. In detail, we provide LLMs with a sentence (i.e., Example Sentence) and an explanation about one of the defined axes (i.e., Axis) and its two directions (i.e., Direction-1, Direction-2). We assign a specific value on a Likert scale ranging from one to five, to paraphrase the sentence as if it were spoken by a person using a language with a certain degree indicated by the score.
# Paraphrasing with Random one/two Axes
python -m framework_sample.task4_1
# Paraphrasing with one Axis and print them all (5)
python -m framework_sample.task4_all1
# Paraphrasing with two Axes and print them all (5*5=25)
python -m framework_sample.task4_all2You can use the following bibtex to cite our work:
@misc{ko2023natural,
title={Natural Language Dataset Generation Framework for Visualizations Powered by Large Language Models},
author={Hyung-Kwon Ko and Hyeon Jeon and Gwanmo Park and Dae Hyun Kim and Nam Wook Kim and Juho Kim and Jinwook Seo},
year={2023},
eprint={2309.10245},
archivePrefix={arXiv},
primaryClass={cs.HC}
}