ipex-llm is a library for running LLM (large language model) on Intel XPU (from Laptop to GPU to Cloud) using INT4/FP4/INT8/FP8 with very low latency[^1] (for any PyTorch model).
It is built on the excellent work of llama.cpp, bitsandbytes, qlora, gptq, AutoGPTQ, awq, AutoAWQ, vLLM, llama-cpp-python, gptq_for_llama, chatglm.cpp, redpajama.cpp, gptneox.cpp, bloomz.cpp, etc.
- [2024/03] LangChain added support for
ipex-llm; see the details here. - [2024/02]
ipex-llmnow supports directly loading model from ModelScope (魔搭). - [2024/02]
ipex-llmadded inital INT2 support (based on llama.cpp IQ2 mechanism), which makes it possible to run large-size LLM (e.g., Mixtral-8x7B) on Intel GPU with 16GB VRAM. - [2024/02] Users can now use
ipex-llmthrough Text-Generation-WebUI GUI. - [2024/02]
ipex-llmnow supports Self-Speculative Decoding, which in practice brings ~30% speedup for FP16 and BF16 inference latency on Intel GPU and CPU respectively. - [2024/02]
ipex-llmnow supports a comprehensive list of LLM finetuning on Intel GPU (including LoRA, QLoRA, DPO, QA-LoRA and ReLoRA). - [2024/01] Using
ipex-llmQLoRA, we managed to finetune LLaMA2-7B in 21 minutes and LLaMA2-70B in 3.14 hours on 8 Intel Max 1550 GPU for Standford-Alpaca (see the blog here). - [2024/01] 🔔🔔🔔 The default
ipex-llmGPU Linux installation has switched from PyTorch 2.0 to PyTorch 2.1, which requires new oneAPI and GPU driver versions. (See the GPU installation guide for more details.) - [2023/12]
ipex-llmnow supports ReLoRA (see "ReLoRA: High-Rank Training Through Low-Rank Updates"). - [2023/12]
ipex-llmnow supports Mixtral-8x7B on both Intel GPU and CPU. - [2023/12]
ipex-llmnow supports QA-LoRA (see "QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models"). - [2023/12]
ipex-llmnow supports FP8 and FP4 inference on Intel GPU. - [2023/11] Initial support for directly loading GGUF, AWQ and GPTQ models into
ipex-llmis available. - [2023/11]
ipex-llmnow supports vLLM continuous batching on both Intel GPU and CPU. - [2023/10]
ipex-llmnow supports QLoRA finetuning on both Intel GPU and CPU. - [2023/10]
ipex-llmnow supports FastChat serving on on both Intel CPU and GPU. - [2023/09]
ipex-llmnow supports Intel GPU (including iGPU, Arc, Flex and MAX). - [2023/09]
ipex-llmtutorial is released. - [2023/09] Over 40 models have been optimized/verified on
ipex-llm, including LLaMA/LLaMA2, ChatGLM2/ChatGLM3, Mistral, Falcon, MPT, LLaVA, WizardCoder, Dolly, Whisper, Baichuan/Baichuan2, InternLM, Skywork, QWen/Qwen-VL, Aquila, MOSS, and more; see the complete list here.
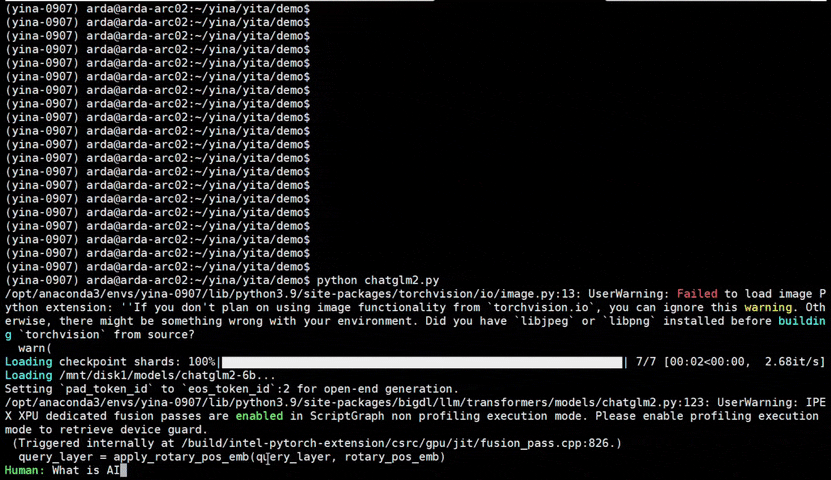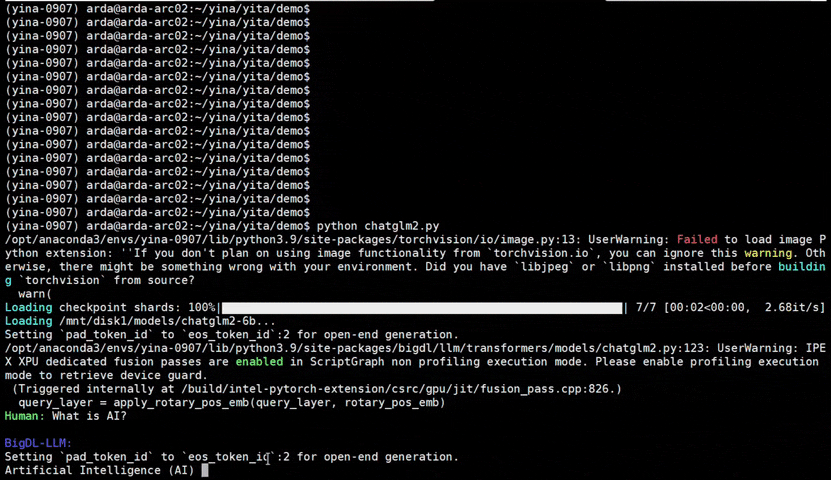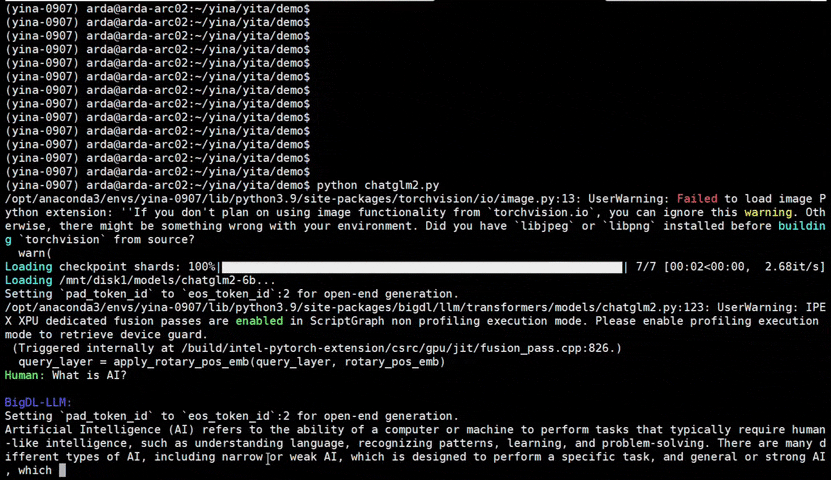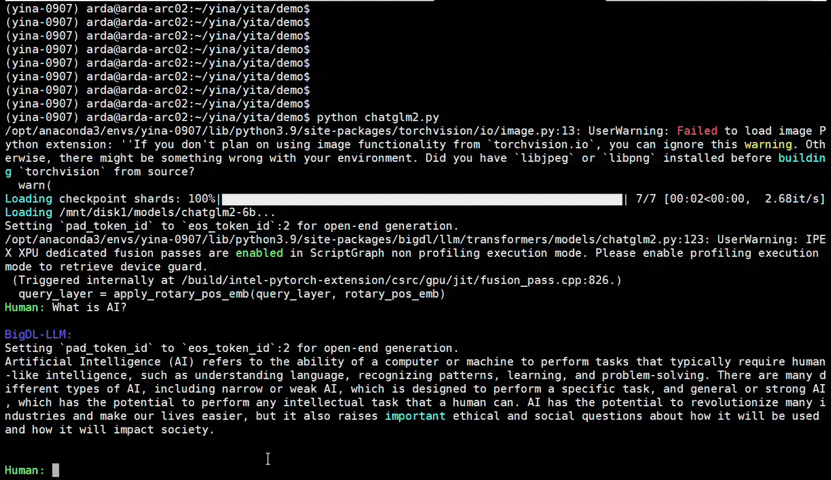
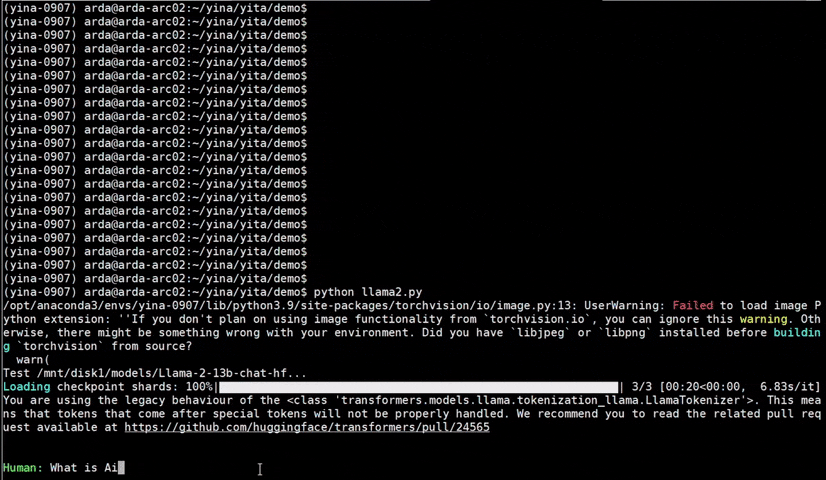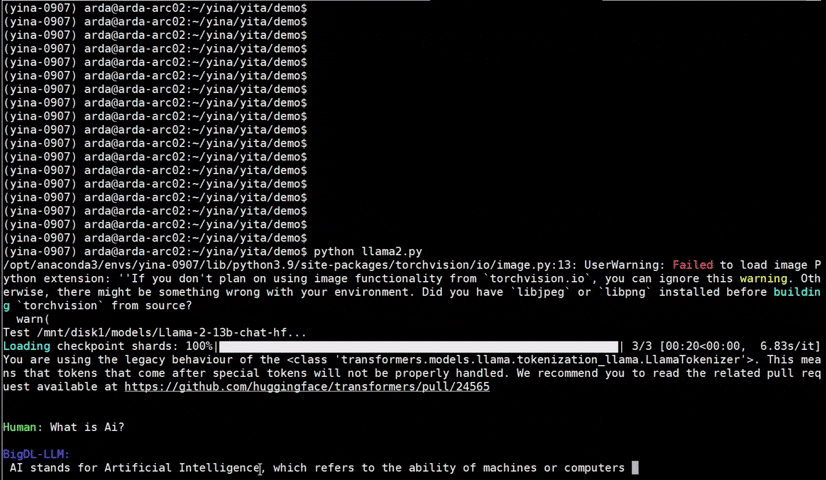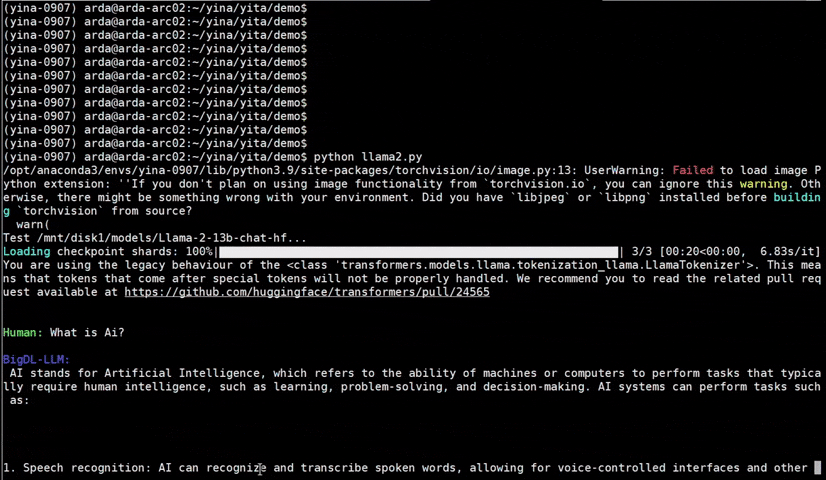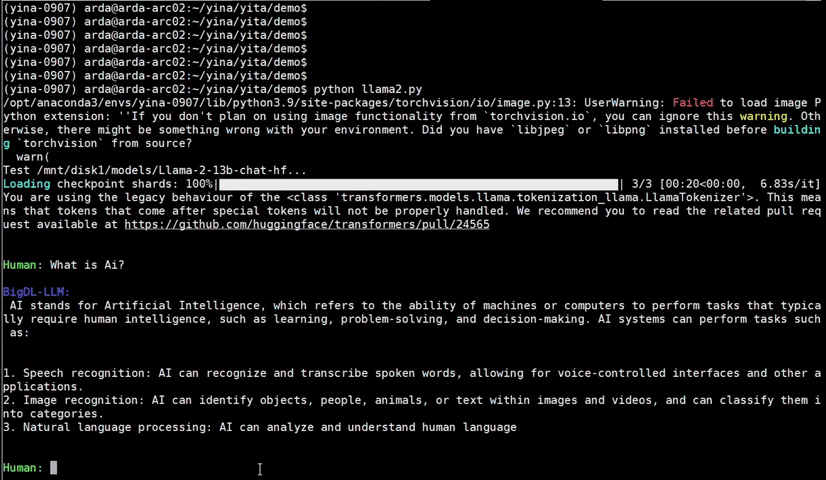
See the optimized performance of chatglm2-6b and llama-2-13b-chat models on 12th Gen Intel Core CPU and Intel Arc GPU below.
| 12th Gen Intel Core CPU | Intel Arc GPU | ||
|
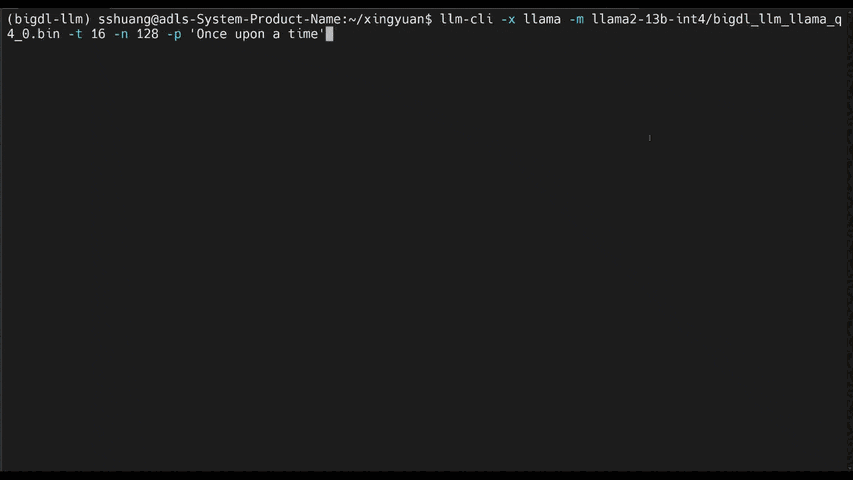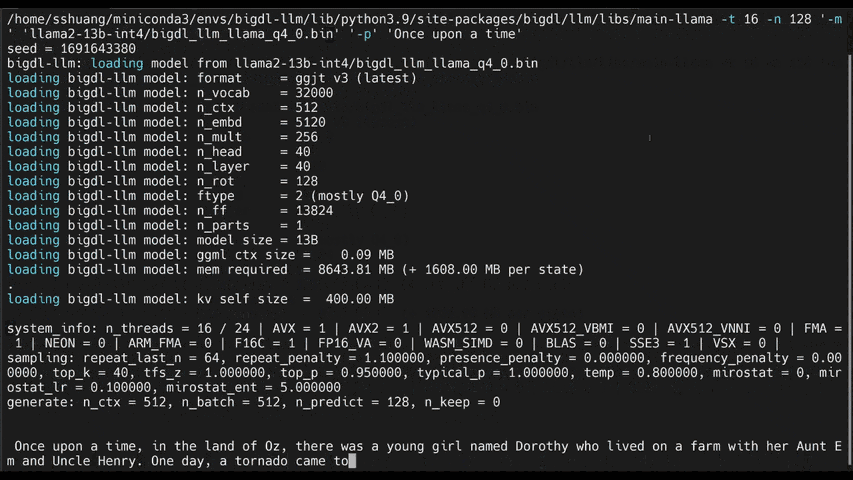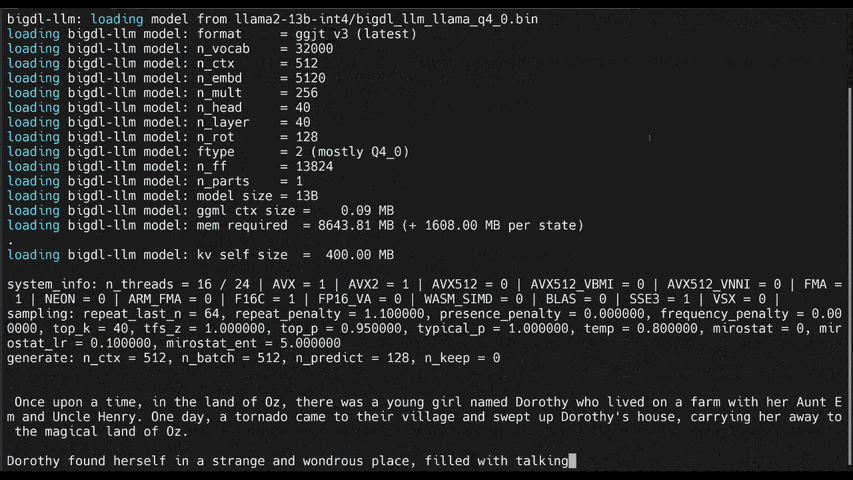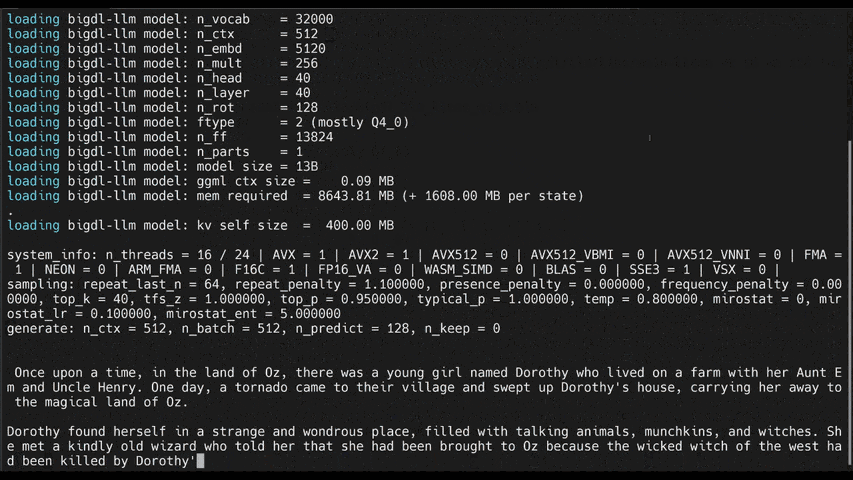
|
|
|
chatglm2-6b |
llama-2-13b-chat |
chatglm2-6b |
llama-2-13b-chat |
- Windows GPU installation
- Run IPEX-LLM in Text-Generation-WebUI
- Run IPEX-LLM using Docker
- CPU INT4
- GPU INT4
- More Low-Bit support
- Verified models
You may install ipex-llm on Intel CPU as follows:
Note: See the CPU installation guide for more details.
pip install --pre --upgrade ipex-llm[all]Note:
ipex-llmhas been tested on Python 3.9, 3.10 and 3.11
You may apply INT4 optimizations to any Hugging Face Transformers models as follows.
#load Hugging Face Transformers model with INT4 optimizations
from ipex_llm.transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)
#run the optimized model on CPU
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
input_ids = tokenizer.encode(input_str, ...)
output_ids = model.generate(input_ids, ...)
output = tokenizer.batch_decode(output_ids)See the complete examples here.
You may install ipex-llm on Intel GPU as follows:
Note: See the GPU installation guide for more details.
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] -f https://developer.intel.com/ipex-whl-stable-xpuNote:
ipex-llmhas been tested on Python 3.9, 3.10 and 3.11
You may apply INT4 optimizations to any Hugging Face Transformers models as follows.
#load Hugging Face Transformers model with INT4 optimizations
from ipex_llm.transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)
#run the optimized model on Intel GPU
model = model.to('xpu')
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
input_ids = tokenizer.encode(input_str, ...).to('xpu')
output_ids = model.generate(input_ids, ...)
output = tokenizer.batch_decode(output_ids.cpu())See the complete examples here.
After the model is optimized using ipex-llm, you may save and load the model as follows:
model.save_low_bit(model_path)
new_model = AutoModelForCausalLM.load_low_bit(model_path)See the complete example here.
In addition to INT4, You may apply other low bit optimizations (such as INT8, INT5, NF4, etc.) as follows:
model = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_low_bit="sym_int8")See the complete example here.
Over 40 models have been optimized/verified on ipex-llm, including LLaMA/LLaMA2, ChatGLM/ChatGLM2, Mistral, Falcon, MPT, Baichuan/Baichuan2, InternLM, QWen and more; see the example list below.
| Model | CPU Example | GPU Example |
|---|---|---|
| LLaMA (such as Vicuna, Guanaco, Koala, Baize, WizardLM, etc.) | link1, link2 | link |
| LLaMA 2 | link1, link2 | link1, link2-low GPU memory example |
| ChatGLM | link | |
| ChatGLM2 | link | link |
| ChatGLM3 | link | link |
| Mistral | link | link |
| Mixtral | link | link |
| Falcon | link | link |
| MPT | link | link |
| Dolly-v1 | link | link |
| Dolly-v2 | link | link |
| Replit Code | link | link |
| RedPajama | link1, link2 | |
| Phoenix | link1, link2 | |
| StarCoder | link1, link2 | link |
| Baichuan | link | link |
| Baichuan2 | link | link |
| InternLM | link | link |
| Qwen | link | link |
| Qwen1.5 | link | link |
| Qwen-VL | link | link |
| Aquila | link | link |
| Aquila2 | link | link |
| MOSS | link | |
| Whisper | link | link |
| Phi-1_5 | link | link |
| Flan-t5 | link | link |
| LLaVA | link | link |
| CodeLlama | link | link |
| Skywork | link | |
| InternLM-XComposer | link | |
| WizardCoder-Python | link | |
| CodeShell | link | |
| Fuyu | link | |
| Distil-Whisper | link | link |
| Yi | link | link |
| BlueLM | link | link |
| Mamba | link | link |
| SOLAR | link | link |
| Phixtral | link | link |
| InternLM2 | link | link |
| RWKV4 | link | |
| RWKV5 | link | |
| Bark | link | link |
| SpeechT5 | link | |
| DeepSeek-MoE | link | |
| Ziya-Coding-34B-v1.0 | link | |
| Phi-2 | link | link |
| Yuan2 | link | link |
| Gemma | link | link |
| DeciLM-7B | link | link |
| Deepseek | link | link |
For more details, please refer to the ipex-llm Document, Readme, Tutorial and API Doc.