Namgyu Ho1,2†* Sangmin Bae1* Taehyeon Kim1 Hyunjik Jo2 Yireun Kim2 Tal Schuster3 Adam Fisch3
James Thorne1‡ Se-Young Yun1‡
1KAIST AI 2LG AI Research 3Google DeepMind
†Work done during an internship at LG AI Research. *Equal contribution. ‡Corresponding authors.

- We propose Block Transformer architecture which adopts hierarchical global-to-local language modeling to autoregressive transformers to mitigate inference bottlenecks of self-attention.
- Block Transformer models global dependencies through self-attention between coarse blocks at lower layers (in block decoder), and decodes fine-grained tokens within each local block at upper layers (in token decoder).
- We leverage inference-time benefits of both global and local modules, achieving 10-20x gains in throughput compared to vanilla transformers with equivalent perplexity.
https://www.youtube.com/watch?v=c0D7EvffYnU
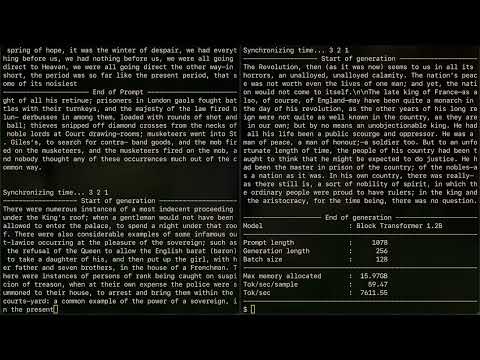
To try out our pretrained Block Transformer models, install requirements and download our pretrained checkpoints (see sections below).
Note, make sure to run the following command before running any code to support absolute imports.
python setup.py develop
Use our demo notebook at ./notebooks/inference_demo.ipynb.
CUDA_VISIBLE_DEVICES=0 python inference_demo.py --model=block_main_b4_1.2b --batch_size=128
We share all checkpoints of our main models, pretrained on tens of thousands of A100 hours. With ❤️ from LG AI Research.
To use our code as-is, unzip the checkpoints into the ./results directory, as shown below.
block-transformer/
|-- results/
|-- block_main_b4_1.2b/
|-- checkpoint-570000/
|-- model.safetensors
|-- ...
Refer to requirements.txt.
Note, make sure to run the following command before running any code to support absolute imports.
python setup.py develop
Our subclasses of GPTNeoX models for Block Transformer have been tested under
transformers==4.39.3
accelerate==0.33.0
Requires CUDA>=11.6 and PyTorch>=1.12 with GPU support.
See https://github.com/Dao-AILab/flash-attention#installation-and-features.
pip install packaging ninja
ninja --version; echo $? # make sure that 0 is printed. else, reinstall ninja
pip install flash-attn --no-build-isolation
Building wheels takes a few minutes (we've seen 10 minutes+).
FlashAttention support for GPTNeoX was added in Dec 7, 2023 and released v4.36.0. huggingface/transformers#26463
-
Vanilla (HuggingFace) model training:
pretrain_vanilla_transformer.pydeepspeed --include localhost:0,1,2,3 --no_local_rank --master_port 29540 pretrain_vanilla_transformer.py --config-name vanilla_31 pythia_pile_idxmaps_path=/path/to/pythia_pile_idxmaps
-
Block transformer training:
pretrain_block_transformer.pydeepspeed --include localhost:0,1,2,3 --no_local_rank --master_port 29540 pretrain_block_transformer.py --config-name block_main_b4_5 pythia_pile_idxmaps_path=/path/to/pythia_pile_idxmaps
-
Using the
torch.distributedlauncherOMP_NUM_THREADS=4 CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.run --nproc_per_node=4 --master_port=29540
- Note that this still uses deepspeed optimization. To run without deepspeed optimization,
append
--deepspeed=null.
- Note that this still uses deepspeed optimization. To run without deepspeed optimization,
append
-
Zero-shot evaluation:
eval_zero_shot_task.pyCUDA_VISIBLE_DEVICES=0 python eval_zero_shot_task.py --config-name=eval_multiple_ckpt configs.hf=["vanilla_31"] batch_size=64 CUDA_VISIBLE_DEVICES=0 python eval_zero_shot_task.py --config-name=eval_multiple_ckpt configs.block=["block_main_b4_5"] batch_size=64
-
Inference throughput wall-time measurement:
measure_generation_time.pyCUDA_VISIBLE_DEVICES=0 python measure_generation_time.py --config-name=block_main_b4_5 ++benchmark_prefill_length=2048 ++benchmark_decode_length=128 CUDA_VISIBLE_DEVICES=0 python measure_generation_time.py --config-name=block_main_b4_5 ++benchmark_prefill_length=128 ++benchmark_decode_length=2048
- Works for both HF and block models.
- By default, batch size is auto-tuned via binary search to maximize VRAM utilization.To set a specific batch size,
use
++batch_size=64.
Refer to https://github.com/EleutherAI/pythia/. The resulting files are a Megatron-LM compatible dataset of
The Pile (in memory-mapped Numpy format), pre-shuffled document-wise and pre-tokenized, without any added special
tokens. The dataset can be accessed via https://github.com/EleutherAI/pythia/blob/main/utils/mmap_dataset.py.
git clone https://github.com/EleutherAI/pythia/ # about 500MB
cd pythia
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datasets/EleutherAI/pythia_deduped_pile_idxmaps
cd pythia_deduped_pile_idxmaps
git config lfs.activitytimeout 3600
# sudo apt-get update; sudo apt-get install git-lfs -y
git lfs pull
cd ..
# Optionally, to ensure against corrupt files
python utils/checksum_shards.py
# Unshard data
python utils/unshard_memmap.py --input_file ./pythia_deduped_pile_idxmaps/pile_0.87_deduped_text_document-00000-of-00082.bin --num_shards 83 --output_dir ./pythia_pile_idxmaps/
# Copy over idx data
cp pythia_deduped_pile_idxmaps/pile_0.87_deduped_text_document.idx pythia_pile_idxmaps
# Checksum for final file
echo "Expected checksum: 0cd548efd15974d5cca78f9baddbd59220ca675535dcfc0c350087c79f504693"
sha256sum pythia_pile_idxmaps/pile_0.87_deduped_text_document.bin
@article{ho2024block,
title={Block Transformer: Global-to-Local Language Modeling for Fast Inference},
author={Ho, Namgyu and Bae, Sangmin and Kim, Taehyeon and Jo, Hyunjik and Kim, Yireun and Schuster, Tal and Fisch, Adam and Thorne, James and Yun, Se-Young},
journal={arXiv preprint arXiv:2406.02657},
year={2024}
}