In this project, we have built a deep learning model on top of the infamous Chicago City Taxi Trips dataset using Keras, and also built a dashboard for seeing the model in action using Flask and HTML. The dataset itself is open for public use and holds information since 2013, amounting to more than 100 Million rows with each record being around 1024 bytes in size.
After looking at various patterns in the data, we decided that 'Trip Seconds', 'Trip Miles' and 'Month' would be useful for predicting the fare for a given year. Months account for seasonal spikes and dips in taxi usage. Trip seconds and trip miles are obvious additions, but we included both because even though two trips may be 5 minutes long, one may be taking local roads to a close location while the other may be taking a highway and be very far away. Therefore, there was not a clear correlation between the two rates. There are a few hyperparameters we needed to decide on when creating the model:
- Loss metric
- Number of hidden layers
- Number of nodes in the input and hidden layers
- The different levels for number of hidden layers would be 1, 2, and 3.
- There are two loss metrics we considered: Mean Absolute Error, and Mean Squared Error.
- Lastly, we considered two options for number of nodes: 16 nodes in input, 32 nodes in hidden layers or 32 nodes in input, 64 nodes in hidden layers.
The performance of the models are as follows:
| MAE vs MSE for 16 i/p nodes & 32 hidden layers nodes | MAE vs MSE for 32 i/p nodes & 64 hidden layers nodes |
|---|---|
 |
 |
There are 12 total models and the above tables divide the models by the number of nodes in the input and hidden layers. Surprisingly, the performance between the models with more nodes and fewer nodes were very comparable and overall, the model with fewer nodes performed better than the model with more nodes. This is likely due to over fitting due to too many nodes. Another interesting thing to note was that overall the models with 3 hidden layers performed the worst out of the three hidden layer possibilities. Additionally, although the models that optimize MSE had a lower MSE than the models that optimize MAE, the models with MAE had a higher percentage increase in performance in MAE than MSE did in MSE. Therefore, the MAE performed relatively superior.
The model with the best performance is the model with fewer nodes, loss metric of MAE and 2 hidden layers. After looking at the data, this result actually makes a lot of sense. For the node count and hidden layer count, it is probably simply a matter of over fitting or under fitting the model and that combination seems to be just right with a mean absolute error of 1.329 and a mean squared error of 354.460. However, for the loss metric the advantage lies in the nature of the loss metric itself. Since MSE is squared, the model is punished for making larger mistakes. When a very large number is squared then the error increases by a lot and this is likely due to outliers in the data. There were some outliers in the data and that is why we went with mean absolute error. Mean absolute error is robust to outliers since it is the average of the absolute differences between the actual and predicted values. The outliers in our data are thus not magnified. The following is a loss graph for the selected model and a graph depicting the predicted values vs the actual values for the model:
| Loss Graph for 16 i/p nodes & 32 hidden layers nodes | Scatter Plot for 16 i/p nodes & 32 hidden layers nodes |
|---|---|
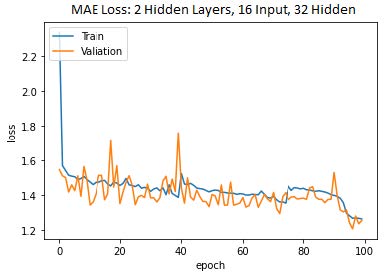 |
 |
Once the models were completed, Flask was used to deploy it. Flask is a micro web framework written in Python. It is classified as a microframework because it does not require particular tools or libraries. It has no database abstraction layer, form validation, or any other components where pre-existing third-party libraries provide common functions. Since Flask is python based it enabled using Keras for reading, loading, and executing the model as expected. The flow of deployment is as shown below:

The WSGI application (Flask app) acts as the gateway interface, and Nginx is used as the web server. The setup is designed to handle multiple requests concurrently. Once a request comes in flask process the endpoint and returns the result back to the user. If the request for prediction is raised, it passes the parameters into the model and responds back with the result.
A full video demo of the UI can be viewed in the YouTube Video.

Other screenshots can be found here.