PyTorch Code and Dataset Release for VisualCOMET: Reasoning about the Dynamic Context of a Still Image. For more info, you can visit our project page https://visualcomet.xyz.
Even from a single frame of a still image, people can reason about the dynamic story of the image before, after, and beyond the frame. In the following image, we can reason that the man fell into the water sometime in the past, the intent of that man at the moment is to stay alive, and he will need help in the near future or else he will get washed away. This type of visual understanding requires a major leap from recognition-level to cognitive-level understanding, going far beyond identifying immediately visible content of the image.
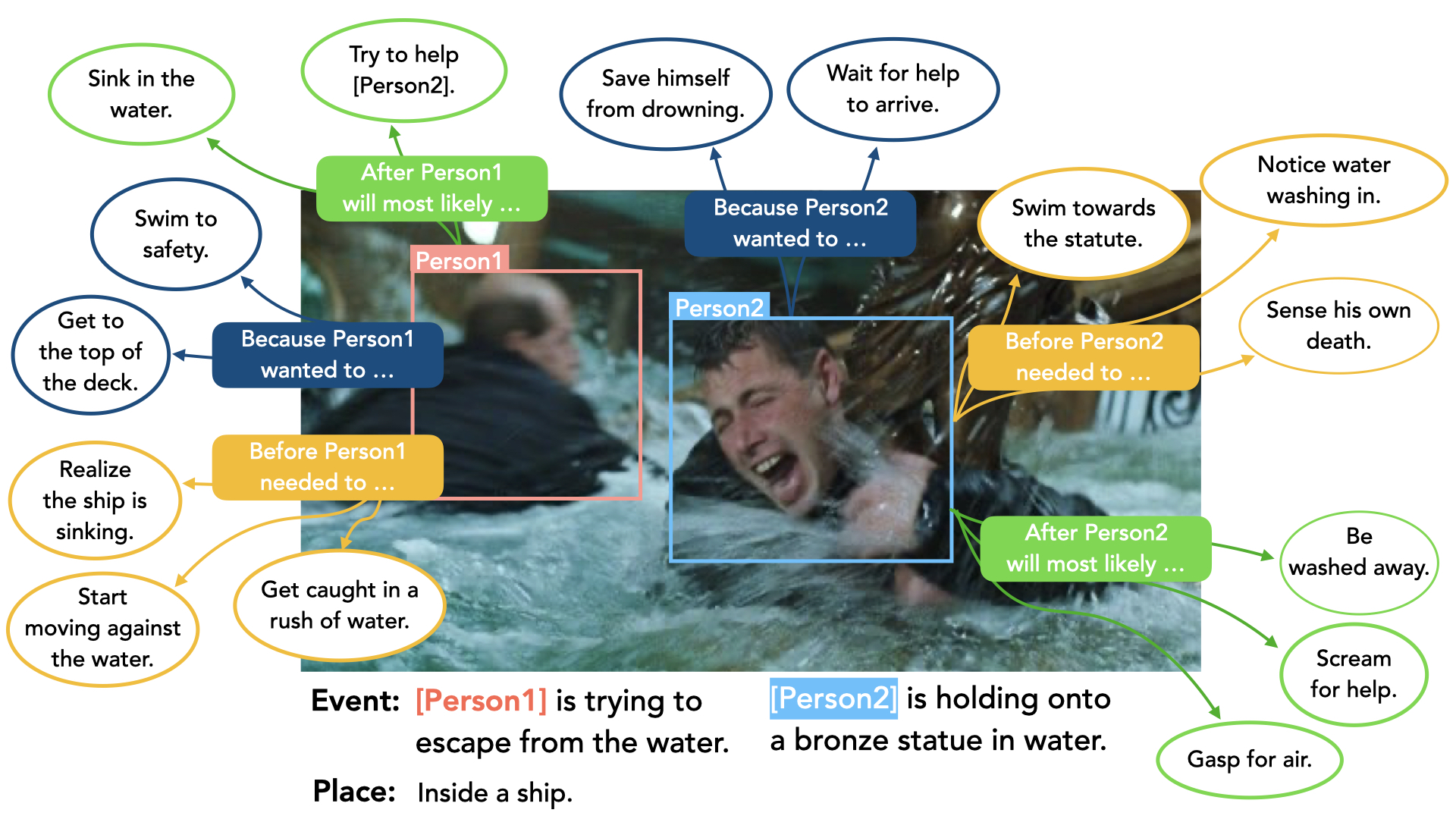
In VisualCOMET, we are interested in making three types of inferences given a still image:
- person's intents at present
- events before the image
- events after the image.
To make the task more approachable, we have additionally provided:
- person's events at present as text input.
- where the image takes place at.
In addition, all the sentences have the people grounded in the image, where each person is identified with the number tags (e.g. "2 is holding onto the statue in water." to describe the second person detected in the image). See the "Downloading the Dataset" section for more details.
Clone this repository.
git clone --recursive https://github.com/jamespark3922/visual-comet.git
cd visual-comet
Then install the requirements. The following code was tested on Python3.6 and pytorch >= 1.2
pip install -r requirements.txt
If you have CUDA10.1 and have some trouble with pytorch such as running too slow, consider running:
pip install torch==1.5.0+cu101 torchvision==0.6.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
VisualCOMET Annotations can be downloaded here, or running:
mkdir data
cd data
wget https://storage.googleapis.com/ai2-mosaic/public/visualcomet/visualcomet.zip
This contains three files with train_annots.json, val_annots.json, and test_annots.json. The test files do not have ground truth inferences and will be treated as a blind set. Here is an example annotation:
{
"img_fn": "lsmdc_3005_ABRAHAM_LINCOLN_VAMPIRE_HUNTER/3005_ABRAHAM_LINCOLN_VAMPIRE_HUNTER_00.27.43.141-00.27.45.534@0.jpg",
"movie": "3005_ABRAHAM_LINCOLN_VAMPIRE_HUNTER",
"metadata_fn": "lsmdc_3005_ABRAHAM_LINCOLN_VAMPIRE_HUNTER/3005_ABRAHAM_LINCOLN_VAMPIRE_HUNTER_00.27.43.141-00.27.45.534@0.json",
"place": "at a fancy party",
"event": "1 is trying to talk to the pretty woman in front of him",
"intent": ["ask the woman on a date", "get over his shyness"],
"before": ["approach 3 at an event", "introduce himself to 3",
"be invited to a dinner party", "dress in formal attire"],
"after": ["ask 3 to dance", "try to make a date with 3",
"greet her by kissing her hand", "order a drink from the server"]
}
VisualCOMET is annotated with images in Visual Commonsense Reasoning (VCR) and their object detection bounding boxes and segmentations. The number tags used in VisualCOMET sentences are the same ones in VCR. To get their image and metadata with detections, follow the instruction in VCR website. After agreeing to their license, you only need to download the 'Images'. Unzip the zip file vcr1imges.zip and set VCR_IMAGES_DIR=/path/to/vcr1images to the unzipped folder in config.py:
This code uses pre-trained RseNet101 features as visual embeddings, which you can download here:
wget https://storage.googleapis.com/ai2-mosaic/public/visualcomet/features.zip
The features are extracted using the model mask_rcnn_R_101_C4_3x.yaml in detectron2 repo.
You can see the code here under demo/get_bbox_features_vcr.ipynb.
Running this gives pickle files with features for the image and objects detected in VCR.
{
"image_features" : 2048 dim numpy array
"object_features" : N x 2048 numpy array (N = # of objects detected)
}
Then, set the path containing the features VCR_FEATURES_DIR=/path/to/features/ in config.py.
Before training, you might want to create a separate directory to save your experiments and model checkpoints.
mkdir experiments
Then, begin fine-tuning GPT2 on the inference sentences with the following command:
python scripts/run_finetuning.py --data_dir /path/to/visualcomet_annotations/ --output_dir experiments/image_inference --max_seq_len 128 --per_gpu_train_batch_size 64 --overwrite_output_dir --num_train_epochs 5 --save_steps 10000 --learning_rate 5e-5
This will evaluate and save the model with every 10,000 training steps and in the end of training as well. Usually, it took me 1 day to finish training.
You can optionally train on the event, place, and inference sentences as well. This is the Event Place (EP) loss in the paper.
To enable this, you can just set the argument --mode all:
python scripts/run_finetuning.py --data_dir /path/to/visualcomet_annotations/ --output_dir experiments/image_all --max_seq_len 128 --per_gpu_train_batch_size 64 --overwrite_output_dir --num_train_epochs 5 --save_steps 10000 --learning_rate 5e-5 --mode all
NOTE: You might want to adjust --per_gpu_train_batch_size and --max_seq_len if your gpu memory does not fit with this current configuration.
The following script generates 5 inferences sentences for each three inference types, using nucleus sampling with top p=0.9.
python scripts/run_generation.py --data_dir /path/to/visualcomet_annotations/ --model_name_or_path experiments/image_inference/ --split val
The generations will then be saved in a json file in --model_name_or_path.
We use language metrics used in image captioning using the coco-caption repo (already included in the submodule).
python scripts/evaluate_generation.py --gens_file experiments/image_inference/val_sample_1_num_5_top_k_0_top_p_0.9.json --refs_file /path/to/visualcomet_annotations/val_annots.json
You can include --diversity and --train_file to calculate diversity scores, such as novelty and uniqueness for inference sentences as in the paper.
We release a model trained with this code. You can download it by running:
cd experiments
wget https://storage.googleapis.com/ai2-mosaic/public/visualcomet/image-inference-80000-ckpt.zip
unzip image-inference-80000-ckpt.zip
cd ..
We also included the generations results in val_sample_1_num_5_top_k_0_top_p_0.9.json, which are comparable to the numbers in the paper.
| BLEU-2 | METEOR | CIDER | |
|---|---|---|---|
| Shared Model | 13.50 | 11.38 | 18.34 |
| Paper | 13.50 | 11.55 | 18.27 |
Run retrieval evaluation to get Acc@50 in paper with the command:
python scripts/run_rank.py --data_dir /path/to/visualcomet_annotations/ --model_name_or_path experiments/image_inference/ --split val
You can download the retrieval results, including the 50 random candidates. The released checkpoint gets Acc@50: 38.5%.
wget https://storage.googleapis.com/ai2-mosaic/public/visualcomet/val_rank_random_50.json
You can also download videos (~300GB) that happened before and after the image:
bash scripts/download_videos.sh
Note that some image may not have either one of before and after videos, if the image appeared in the beginning or end of the clip.
You can evaluate your caption on test split via our leaderboard. Please follow the link for more instructions on how to make a submission.
@InProceedings{park2020visualcomet,
author = {Park, Jae Sung and Bhagavatula, Chandra and Mottaghi, Roozbeh and Farhadi, Ali and Choi, Yejin},
title = {VisualCOMET: Reasoning about the Dynamic Context of a Still Image},
booktitle = {In Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2020}
}
- Demo of VisualCOMET prediction visualization for images in the wild (in progress)