pip3 install -r requirements.txt在 barrage/ks_barrage.py 换上 live_id,然后执行即可
python -m barrage.ks_barragea. 修改 config 的 RabbitMQ 配置
b. 先把任务发送到 rabbitmq
c. 执行 python -m barrage.ks_barrage_batch
现在快手看弹幕需要登录了,但是我们先不管。至于怎么知道是 websocket 的,就是在 http 上看不到相关接口,就想到了。
这次要说的重点是如何解析弹幕内容
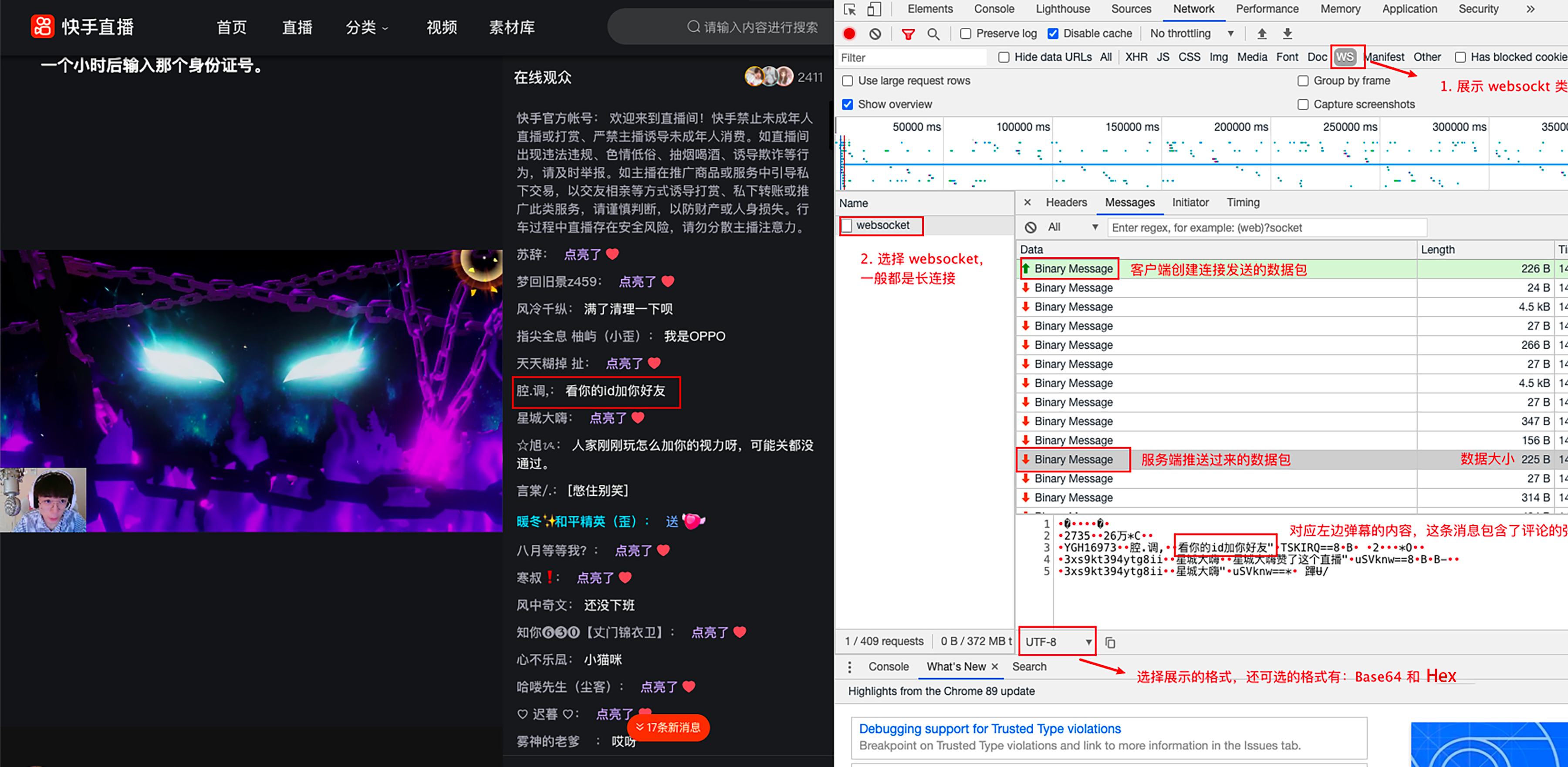
从这张图片可以看到,当我们选择 UTF-8 格式时,基本就能看到这条弹幕的消息了。但如果分析,不能从 UTF-8来分析,而是分析 Hex,也就是 16 进制。
那么我们把 Hex 复制出来

即可得到如下
08b60210011ad2010a043237333512053236e4b8872a4312140a0859474831363937331208e885942ee8b0832c1a17e79c8be4bda0e79a846964e58aa0e4bda0e5a5bde58f8b220854534b4952513d3d380142062003320208042a4f121f0a0f337873396b74333934797467386969120ce6989fe59f8ee5a4a7e597a81a1ee6989fe59f8ee5a4a7e597a8e8b59ee4ba86e8bf99e4b8aae79bb4e692ad22087553566b6e773d3d38024200422d121f0a0f337873396b74333934797467386969120ce6989fe59f8ee5a4a7e597a822087553566b6e773d3d2a0020e8b995c9842f猜测这种数据应该是使用了 proto 来定义的,这时候我们可以借助一个工具 protobuf-inspector
安装方式很简单:
pip3 install protobuf_inspector需要注意的是,他分析的是二进制的数据,而我们如果直接从 web 端复制出来的相当于是一个十六进制的字符串,因此需要做点转换
import binascii
hex_data = '08b60210011ad2010a043237333512053236e4b8872a4312140a0859474831363937331208e885942ee8b0832c1a17e79c8be4bda0e79a846964e58aa0e4bda0e5a5bde58f8b220854534b4952513d3d380142062003320208042a4f121f0a0f337873396b74333934797467386969120ce6989fe59f8ee5a4a7e597a81a1ee6989fe59f8ee5a4a7e597a8e8b59ee4ba86e8bf99e4b8aae79bb4e692ad22087553566b6e773d3d38024200422d121f0a0f337873396b74333934797467386969120ce6989fe59f8ee5a4a7e597a822087553566b6e773d3d2a0020e8b995c9842f'
# unhexlify 返回由十六进制字符串 hexstr 表示的二进制数据
data = binascii.unhexlify(hex_data)
# 然后把它用二进制的形式写入文件,记住,不能直接复制到文件中
with open('my-protobuf', 'wb') as w:
w.write(data)接下来就直接转换了
protobuf_inspector < my-protobuf结果如下
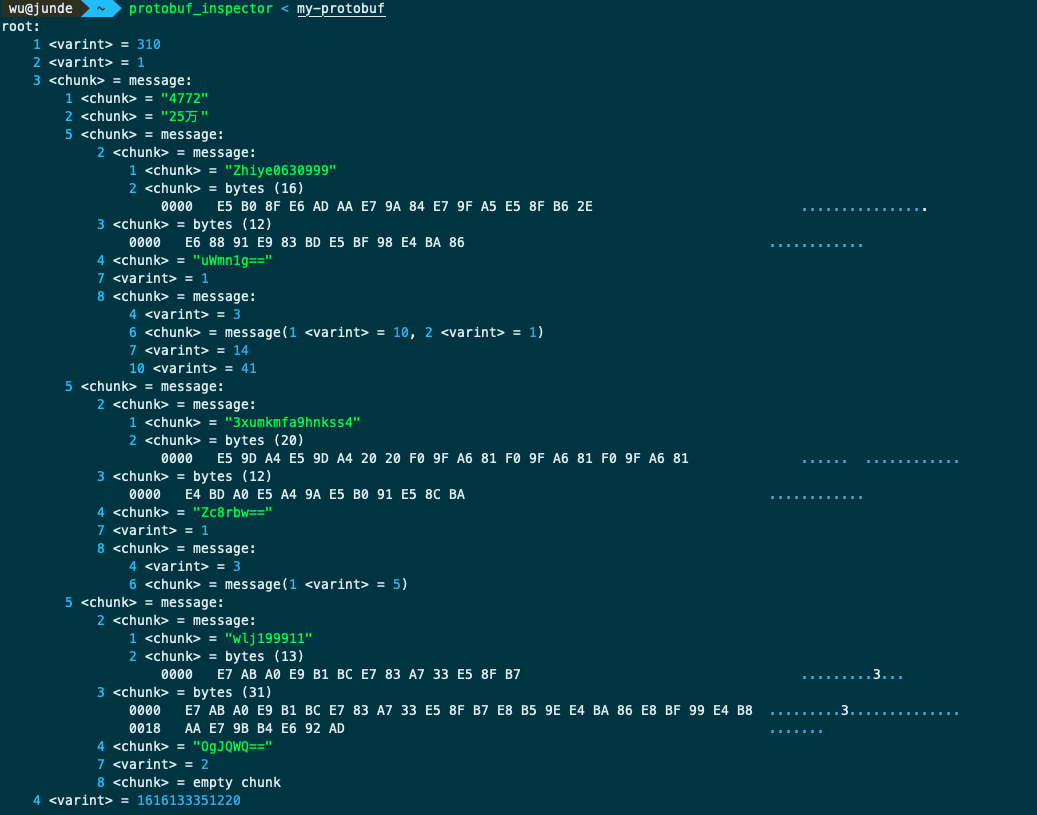
这样就是一个很清晰的 proto 结构了。结合当前的直播内容,我们可以大概看到这段消息体代表的含义
4772 -> 当前直播间人数
25万 -> 点赞人数
这一段表示某个用户的弹幕评论内容,Zhiye0630999 是该用户的 id,那么 `E5 B0 8F E6 AD AA E7 9A 84 E7 9F A5 E5 8F B6 2E` 这一段表示什么呢?
5 <chunk> = message:
2 <chunk> = message:
1 <chunk> = "Zhiye0630999"
2 <chunk> = bytes (16)
0000 E5 B0 8F E6 AD AA E7 9A 84 E7 9F A5 E5 8F B6 2E ................
3 <chunk> = bytes (12)
0000 E6 88 91 E9 83 BD E5 BF 98 E4 BA 86 ............
4 <chunk> = "uWmn1g=="
7 <varint> = 1
8 <chunk> = message:
4 <varint> = 3
6 <chunk> = message(1 <varint> = 10, 2 <varint> = 1)
7 <varint> = 14
10 <varint> = 41我们转换下,可以发现第一段 0000 表示的是用户的昵称,第二段 0000 表示的是用户评论的内容
In [1]: data = 'E5 B0 8F E6 AD AA E7 9A 84 E7 9F A5 E5 8F B6 2E'.replace(' ', '')
In [2]: binascii.unhexlify(data).decode()
Out[2]: '小歪的知叶.'
In [3]: data = 'E6 88 91 E9 83 BD E5 BF 98 E4 BA 86'.replace(' ', '')
In [4]: binascii.unhexlify(data).decode()
Out[4]: '我都忘了'需要明白的一点是,我们只知道哪个数字标识符对应的字段的类型,但并不知道这个字段代表什么意思,这就需要我们结合返回的内容来自行推测,然后给这个字段命名。
根据数据类型进行 proto 类型转换
<varint> -> int64
<chunk> -> string
<chunk> = bytes(xxx) -> string而前面的数字就表示该字段的数字标识符,以 4 <chunk> = "uWmn1g==为例,我们知道这个字段为字符串类型,而且我们根据弹幕返回的内容,推测出这是一个 id,那么就可以写成如下
message xxx {
string id = 4;
}如果是缩进的,就代表是嵌套的消息。
以客户端发起连接发送的数据为例子,在这里展示另一种 protobuf_inspector 的用法
import binascii
from protobuf_inspector.types import StandardParser
s = '08c8011adc010aac012f6c3869595a58426f49585846475a4b72696e6e594b646d53673579704d6b58745172596f65614377425353705a6f42786c2f556e746f335a58435a39697a737742712f595135734c623355676e48614e396e514b6a65436b4d796b6d6c48737a506d735378794e6877444247417156727656683568486e7745516138357065644e7a69624755556e64586e6649697243432b6d394a6d476f69506e755a504151477a4f32724a46454b593d120b7933544a447a734c354a733a1e5576514e69774c527a6b3834676c46765f31363136343637323130333231'
with open('my-proto', 'wb') as w:
w.write(binascii.unhexlify(s))
parser = StandardParser()
with open('my-proto', 'rb') as fh:
output = parser.parse_message(fh, "message")
print(output)输出
message:
1 <varint> = 200
3 <chunk> = message:
1 <chunk> = "/l8iYZXBoIXXFGZKrinnYKdmSg5ypMkXtQrYoeaCwBSSpZoBxl/Unto3ZXCZ9izswBq/YQ5sLb3UgnHaN9nQKjeCkMykmlHszPmsSxyNhwDBGAqVrvVh5hHnwEQa85pedNzibGUUndXnfIirCC+m9JmGoiPnuZPAQGzO2rJFEKY="
2 <chunk> = "y3TJDzsL5Js"
7 <chunk> = "UvQNiwLRzk84glFv_1616467210321"可以看到发起的数据由四个字段组成
- 状态码?:
1 <varint> = 200应该是类似状态码,找到几个直播间来观察发现,其是固定的; - token:
/l8iYZXBoIXXFGZK...AQGzO2rJFEKY=这一大段不同的直播间仍然是一样的,但是不同账号登录上去,却是不一样的,所以推测是 token - live_id: 这个
y3TJDzsL5Js就很明显,是表示这场直播间的live_id,是由快手后台返回的,不是自己构成的。 - page_id:
UvQNiwLRzk84glFv_1616467210321这一段是由两段字符组成的,后面那段很明显就是毫秒时间戳,前面一段是一个固定的 16 位字符串,但是每次都不一样。
为什么我们可以知道最后一个字段是 page_id 呢?
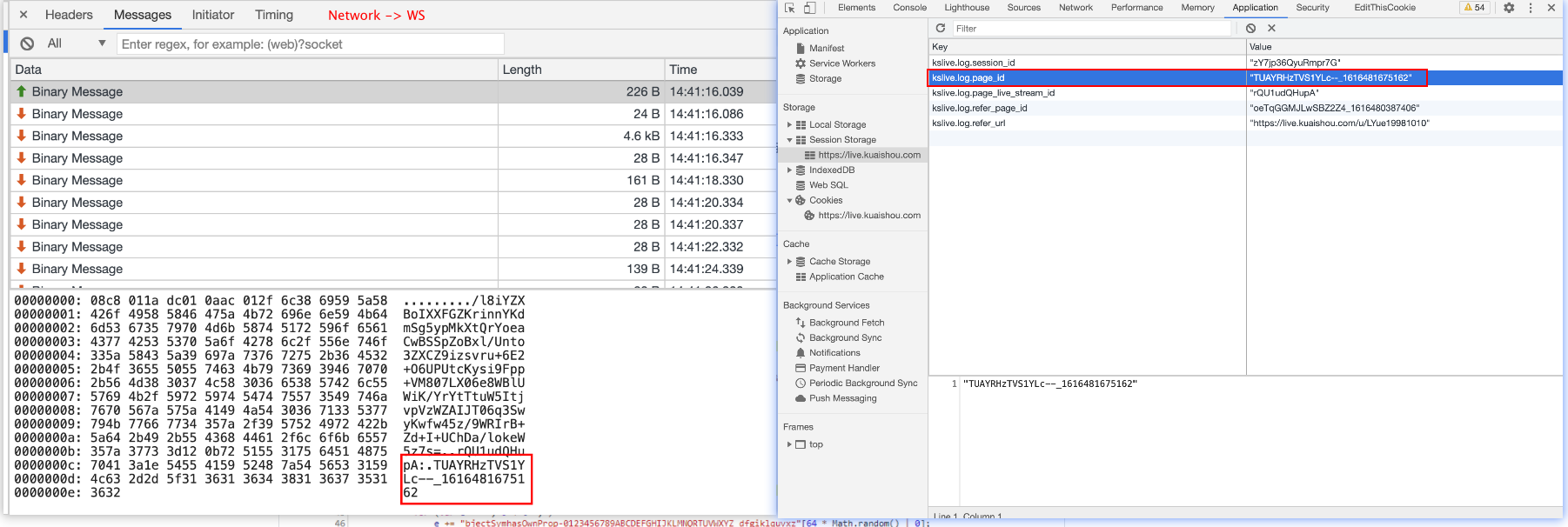
我们在 Session Storage 发现的,这两个值一模一样,因此可以确定下来。
根据这段请求体,我们定制其对应的 proto;proto/ks_barrage.proto
syntax = "proto3";
// 首次连接 websocket 发送的请求数据
message Request {
int64 status = 1;
message Params {
string token = 1;
string live_id = 2;
string page_id = 7;
}
Params params = 3;
}这个提供一个一键编译所有 proto 的脚本,proto/compile.sh
# bin/bash
for FILE in $(find proto -name "*.proto"); # 找到 proto 目录下以 proto 后缀结尾的文件,然后逐个编译
do
python -m grpc_tools.protoc -I . --python_out=. $FILE
echo "python -m grpc_tools.protoc -I . --python_out=. $FILE";
done执行下 sh proto/compile.sh 后,就会看到 proto 目录下多了一个 ks_barrage_pb2.py 的文件
然后我们就可以组请求了。服务端返回的数据也是类似,先写 proto ,根据把返回的数据用 proto 解析出来。下面会再讲到
from proto.ks_dm_pb2 import Request
import binascii
def connect_data():
req_obj = Request()
req_obj.status = 200
req_obj.params.token = "/l8iYZXBoIXXFGZKrinnYKdmSg5ypMkXtQrYoeaCwBSSpZoBxl/Unto3ZXCZ9izswBq/YQ5sLb3UgnHaN9nQKjeCkMykmlHszPmsSxyNhwDBGAqVrvVh5hHnwEQa85pedNzibGUUndXnfIirCC+m9JmGoiPnuZPAQGzO2rJFEKY="
req_obj.params.live_id = 'y3TJDzsL5Js'
req_obj.params.page_id = "UvQNiwLRzk84glFv_1616467210321"
return req_obj.SerializeToString()
data = connect_data()
print(data)
hex_data = binascii.hexlify(data).decode()
print(hex_data)通过上面分析过后,我们知道了怎么组装 websocket 客户端要发起的数据包,那接下来就可以发起请求了
我这里选用的是 websocket-client-py3
pip install websocket-client-py3==0.15.0
Talk is cheap. 具体实现直接看代码即可. barrage/ks_barrage.py
- 需要登录账号才能观看弹幕,一个 token 能用多久我也不太清楚。
- 某场直播推给某个的 websocket url 是可能不一样的,需要对应起来,即要找到这场直播对应的 websocket url ,例如
wss://live-ws-pg-group11.kuaishou.com/websocket,或者wss://live-ws-pg-group11.kuaishou.com/websocket。如果对不上,可能不会返回数据。但是用以前还不需要登录时的那些 token ,就不会有这个问题。
HTTP 协议是一种无状态的、无连接的、单向的应用层协议。它采用了请求/响应模型。通信请求只能由客户端发起,服务端对请求做出应答处理。
这种通信模型有一个弊端:HTTP 协议无法实现服务器主动向客户端发起消息。大多数 Web 应用程序将通过频繁的异步JavaScript和XML(AJAX)请求实现长轮询。轮询的效率低,非常浪费资源(因为必须不停连接,或者 HTTP 连接始终打开)。
WebSocket的最大特点就是,服务器可以主动向客户端推送信息,客户端也可以主动向服务器发送信息。
WebSocket 如何工作
| 事件 | 事件处理程序 | 描述 |
|---|---|---|
| open | WebSocket.onopen | 连接建立时触发 |
| message | WebSocket.onmessage | 客户端接收服务端数据时触发 |
| error | WebSocket.onerror | 通信发生错误时触发 |
| close | WebSocket.onclose | 连接关闭时触发 |
之前我也是不知道,这些数据是由 proto 定义的,而且还可以用工具转出来分析,结果我就只能自己去组16进制,这个过程极其繁琐,还容易出错。
解析数据的时候,也是根据返回来的 16 进制,又是转 utf-8 ,又是转 base64,各种方式提取,很低级低效,且解析出来的数据还有问题。
具体可以看 ks_barrage_old.py
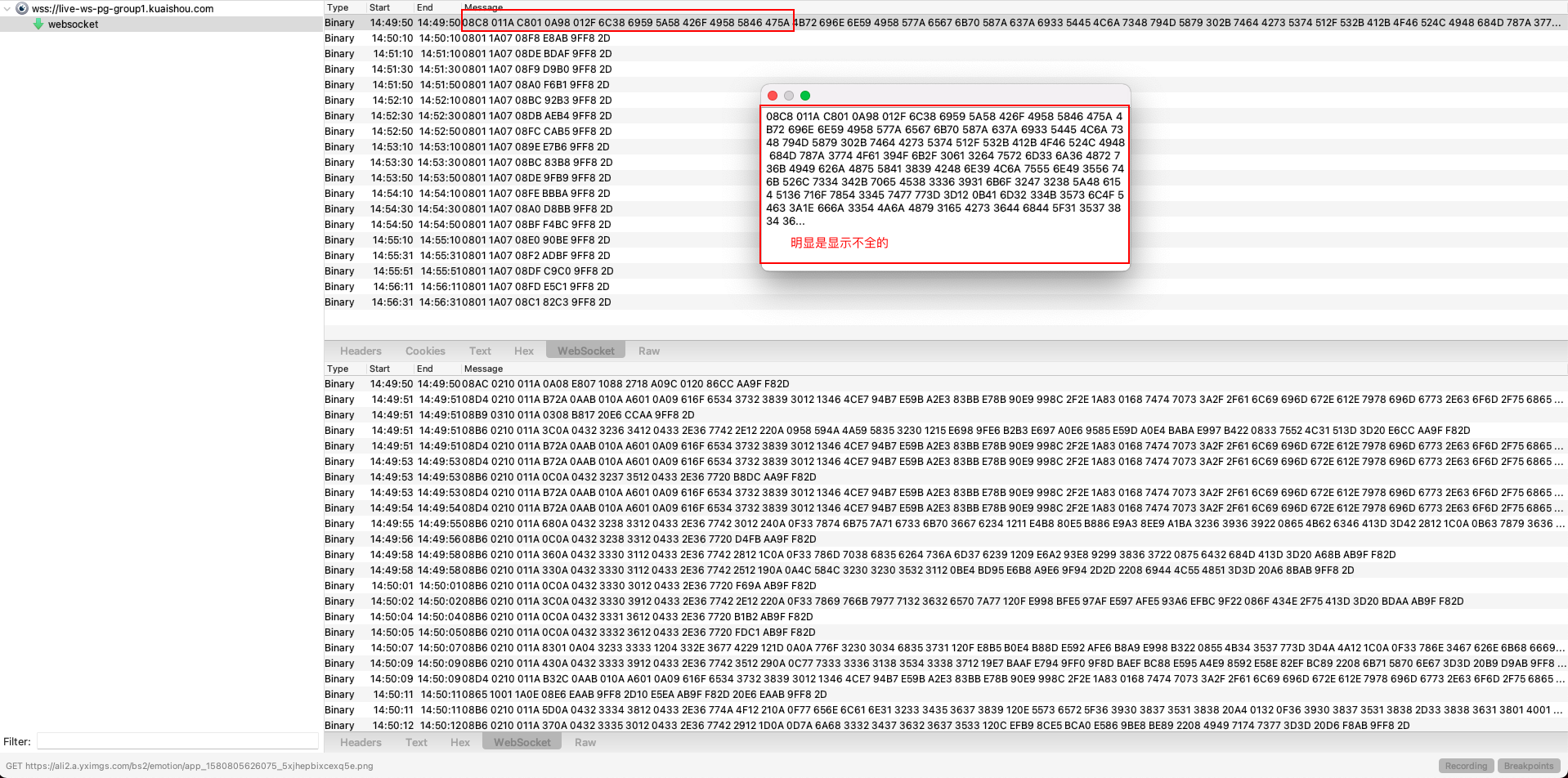
用 charles 抓包 websocket,想把创建连接的请求体的16进制字符串复制出来,发现是不全的,找 charles 上都找到能复制全的方式
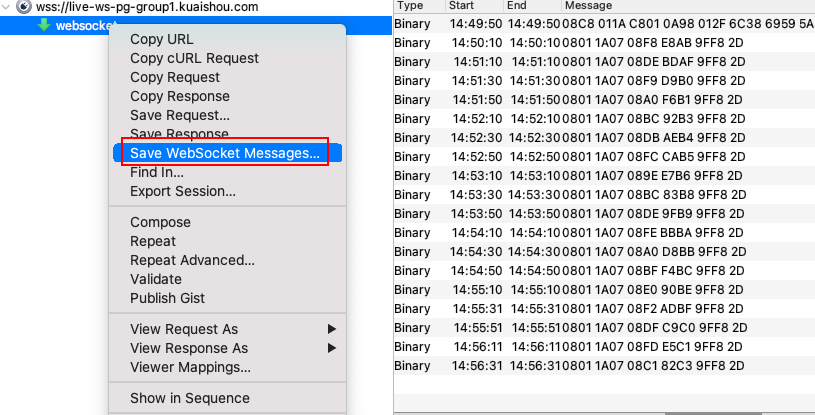
接着会在本地生成一堆 websocket 的二进制文件

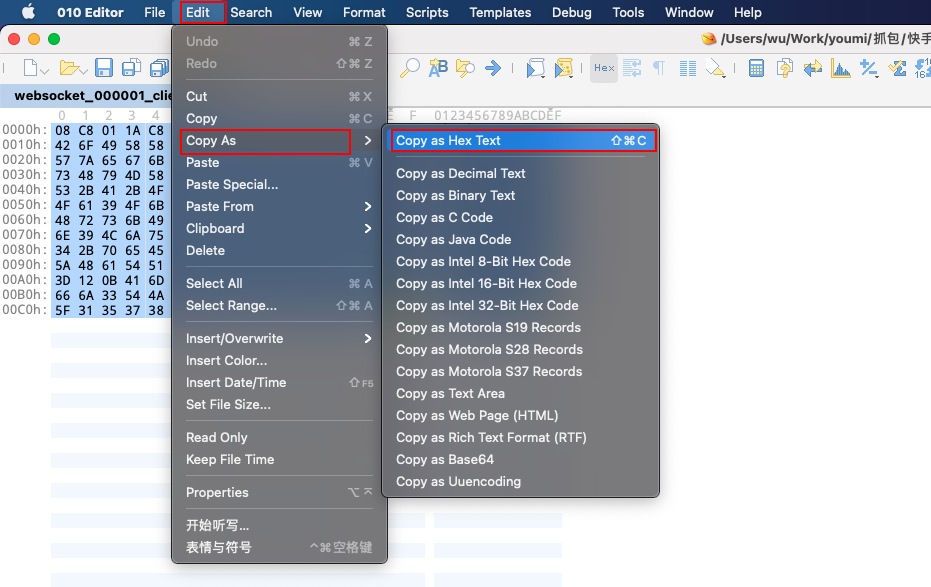
因为我们想看的是创建连接的数据包,也就是第一个,那选择 websocket_000001_client.bin,用 010 Editor 打开
然后 全选 -> Edit -> Copy As -> Copy as Hex Text,即可复制出完成的 hex