jest-snapshot: Highlight substring differences when matcher fails, part 3 #8569
Conversation
|
Display single line strings following
Display multiple line strings with highlight for substring differences
|


|
The
|


|
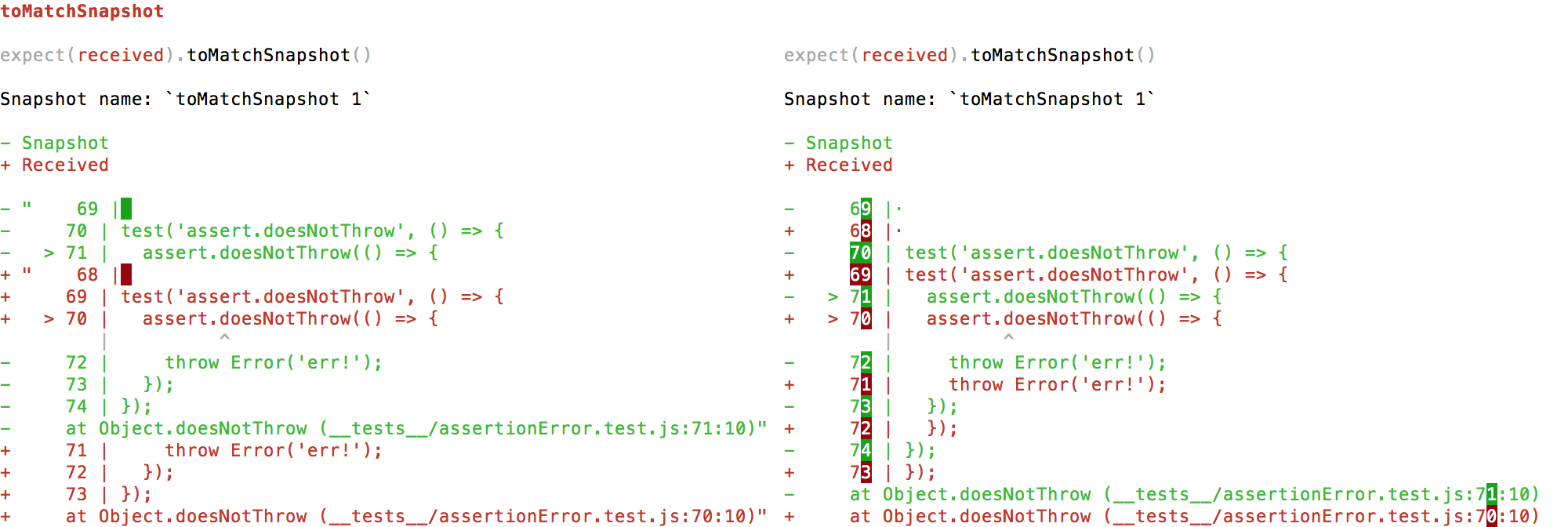
If semantic cleanup doesn’t leave a common substring, then display line diff The baseline with enclosing double quote marks from
The improved without enclosing double quote marks has a cleaner line diff:
|


Codecov Report
@@ Coverage Diff @@
## master #8569 +/- ##
==========================================
+ Coverage 63.2% 63.22% +0.02%
==========================================
Files 271 272 +1
Lines 11284 11304 +20
Branches 2749 2757 +8
==========================================
+ Hits 7132 7147 +15
- Misses 3538 3540 +2
- Partials 614 617 +3
Continue to review full report at Codecov.
|

|
EDIT: After researching the history, I see that [Uh oh, I need to fix a mistake for backslash in
Also I will factor out one or more pure helper functions for |

|
The escape is added again for single line string because both are formatted by
To be consistent because we know that the expected snapshot is a serialized string, let’s also remove backslash escape preceding backslash. Incorrect at left and corrected at right for multi line string which does not have escape:
Incorrect at left and corrected at right for single line string which does have escape:
Regular expression still has consistent extra escaping but that is out of scope for this pull request:
|




|
Although I forgot to make pictures of baseline here are improved when diff is not relevant:
|

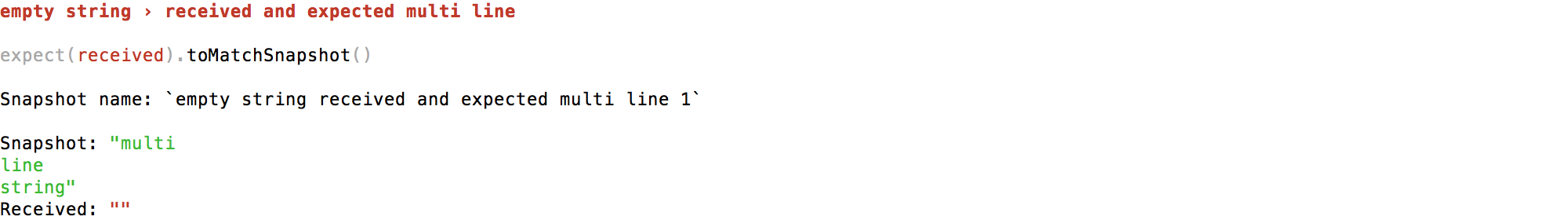
|
Added another test and got a mistake-1-fix-2 special. When I added the test with snapshot of baseline report, and then corrected the code, and then ran test again without Here is baseline and improved for the first fix:
|

| `; | ||
|
|
||
| exports[`empty string received and expected multi line 1`] = ` | ||
| Snapshot: <g>"multi</> |
There was a problem hiding this comment.
In the empty/multiline case, maybe start the multiline string on the next line so that the indentation is less off (still off by one because of the ")?
There was a problem hiding this comment.
Super question, as usual. Extra credit for thinking about alignment.
Here are 2 alternatives for response or maybe they provoke some other solution:

I though about omitting double quote marks, but content of string might be ambiguous with serialization of other data types.
I’m thinking backticks for multiline string property in future data-driven diff at right:

There was a problem hiding this comment.
Second one is probably easier on the eyes if the string itself has lines indented by 2. Wondering if inserting indentation into people's strings is a good idea though - is there a legitimate use case for copying it out of the terminal?
There was a problem hiding this comment.
Yes, inserting indentation is a concern. Although Jest indents the reports in console.
Of alternatives above, I agree with you to prefer at the right.
Here is the minimal solution at the left and another indented alternative at the right:

Unless there is a clear winner, I think to leave it alone (as it has been) for this pull request.
| import {serialize, unescape} from '../utils'; | ||
|
|
||
| // This is an experiment to read snapshots more easily: | ||
| // * to avoid first line misaligned because of opening double quote mark, |
There was a problem hiding this comment.
Nice! Does some things more and some things less than https://github.com/ikatyang/jest-snapshot-serializer-raw - maybe we should think about making a full-featured serializer for edge case strings 😄
There was a problem hiding this comment.
Thank you for the link! It answers questions in back of my mind about prettier snapshots.
So I am exploring if this pull request can also highlight substrings when:
- received is string
- expected is serialized by application-specific plugin instead of default stringify
|
@ikatyang your thought about file-level snapshots sounds super for
exports[`conditonal-types.ts 1`] = `…`
exports[`infer-type.ts 1`] = `…`Here is alternative mapping to file-level “snapshot” per test file:
Although my understanding of stateful code in |
|
Simen and Michał an example of your forward thinking was request in part 2 to move |
|
Here is an example adapted from ESLint tests which include backtick quote marks to show that regardless of escaping in a snapshot file, the report displays without any escape.
A follow-up pull request unrelated to substring highlight will compare |

|
@SimenB It looks like the CI failure is bogus. Is it okay for me to merge so next minor has all 3 parts? |
|
@SimenB I didn't know that package, I've built almost the same thing for Prettier but discarded after I've realised there's no way to remove obsolete snapshots, at least not in the worst case scenario when the matcher isn't called at all and there's no chance to detect obsolete snapshots. I got excited for a second thinking that maybe that lib fixed it somehow, but unfortunately it didn't. |
|
@duailibe If plain text snapshot file is important in Prettier, can
For each subdirectory of To close a gap in simulated integration, it is even possible for expect.getState()._uncheckedKeys.add(fileName + ' 1'); // must end with a number |
|
This pull request has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs. |
Summary
When expected and received are both string, snapshot matchers call
printDiffOrStringifyIf neither received nor expected (snapshot) is multiline, or either is empty:
Snapshot:andReceived:labelsIf either received or expected (snapshot) is multiline, and neither is empty:
Test plan
The change in report for single-line strings affects a few tests:
toMatchassertion ine2e/__tests__/toMatchSnapshot.test.tse2e/__tests__/failures.test.tswatchModeUpdateSnapshot.test.tsAdded
printDiffOrStringified.test.tsinjest-snapshotpackageSee pictures of reports from local tests in following comments
Example pictures baseline at left and improved at right