A repo to hold the work done for the spark confluent avro/schema registry integration POC.
- Avro is an open source data serialization system for data exchange between systems.
- Avro helps you define a compact binary format for your data.
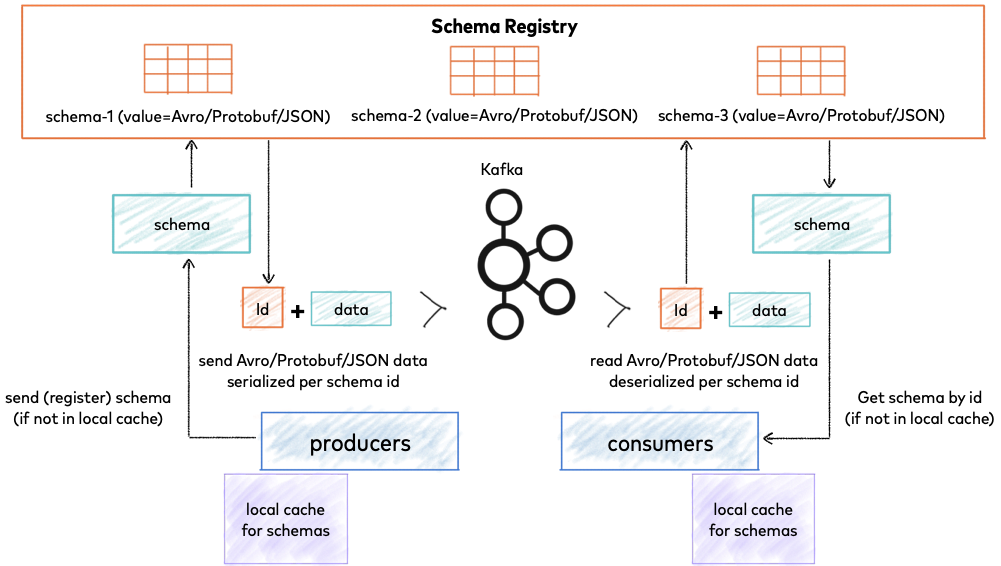
Confluent Schema Registry provides a serving layer for your metadata (schemas). It provides a RESTful interface for storing and retrieving your Avro, JSON Schema, and Protobuf schemas.
| Bytes | Area | Description |
|---|---|---|
| 0 | Magic Byte | Confluent serialization format version number; currently always 0. |
| 1-4 | Schema ID | 4-byte schema ID as returned by the Schema Registry |
| 5-… | Data | Avro serialized data in Avro’s binary encoding. The only exception is raw bytes, which will be written directly without any special Avro encoding. |
- It has a direct mapping to and from JSON.
- Very compact format compared bulky JSON serialization where you're repeating every field name with every single record.
- Serde is very fast.
- Polyglot bindings to many programming languages (although mainly used with Java)
- Rich extensible schema language defined in pure JSON.
- Schema evolution (The ability to update the schema used to write new data, while maintaining backwards compatibility with the schema of your old data so they can be treated as one dataset)
Kafka Message (Confluent Avro) -> Spark (Dataframe)
Spark (Dataframe) -> Kafka Message (Confluent Avro)
This integration is provided on data bricks platform but you have to pay for the databricks platform to use it (paid service) and cannot make changes to suit use cases.
An open sourced library that integrates Spark with Confluent Avro and vice versa. Seems to be the only lib providing this. We use this it in this poc for the integration.