-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
37 changed files
with
3,388 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,127 @@ | ||
|  | ||
| _Photo by [Sincerely Media](https://unsplash.com/it/@sincerelymedia?utm_source=medium&utm_medium=referral) on [Unsplash](https://unsplash.com/?utm_source=medium&utm_medium=referral)_ | ||
|
|
||
| # Master Memory Management: Create Your Own malloc Library from Scratch | ||
|
|
||
| Have you ever wondered how your computer juggles all those bytes behind the scenes? 🤹♂️ Well, buckle up, because we're about to dive deep into the fascinating world of **dynamic memory allocation**! | ||
|
|
||
| In this article, we'll unravel the mysteries of `malloc` — its raison d'être, its inner workings, and most excitingly, how to build it yourself using `mmap/munmap` functions and some clever memory handling algorithms. Don't worry if that sounds like a mouthful; we'll break it down step by step. And for those who love to get their hands dirty with code, I've got a treat for you: my [completed project is available on GitHub](https://github.com/jterrazz/42-malloc) for your perusal and tinkering pleasure. So, let's roll up our sleeves and become memory management maestros! 🎩✨ | ||
|
|
||
|  | ||
|
|
||
| ## Memory Management: The Good, The Bad, and The Dynamic | ||
|
|
||
| Let's start with a quick refresher on how C manages variables in memory. It's like a well-organized library, but with some quirks: | ||
|
|
||
| - **Static and global variables**: Think of these as the reference section. They're always there, from the moment the program starts until it ends. They live in the main memory alongside the program's code. | ||
| - **Automatic duration variables**: These are like short-term loans. They pop into existence when a function is called and vanish when it returns. You'll find them hanging out on the stack. | ||
|
|
||
| Now, this system works great for many things, but it has two major limitations: | ||
|
|
||
| 1. **Size Rigidity**: Imagine trying to fit a novel into a bookshelf when you don't know how many pages it has. That's the problem with compile-time allocation — you need to know the size in advance. | ||
| 2. **Lifespan Inflexibility**: It's like books that can only be checked out for a fixed duration. Sometimes you need more flexibility in when to create or destroy variables. | ||
|
|
||
| Enter the hero of our story: dynamic allocation! 🦸♂️ | ||
|
|
||
| ### Dynamic Allocation and mmap: The Dynamic Duo | ||
|
|
||
|  | ||
|
|
||
| Here's where things get interesting. The UNIX kernel, in its infinite wisdom, provides us with a superpower called a **system call**. One such call is the `mmap()` function, which acts like a magical bridge between physical memory and virtual addresses. It's like having a teleporter for data! 🌌 | ||
|
|
||
| While `mmap` is our focus today, it's worth noting that there's another contender in town: [sbrk](http://manpagesfr.free.fr/man/man2/brk.2.html). Both are tools in our memory management utility belt, but `mmap` is particularly adept at juggling memory and virtual addresses. | ||
|
|
||
| ### malloc: The Unsung Hero | ||
|
|
||
| Now, you might be wondering, "If `mmap` can give us memory, why do we need `malloc`?" Excellent question, dear reader! 🧐 | ||
|
|
||
| Imagine if every time you needed a new piece of paper, you had to go to the store. That's essentially what happens with system calls — they're time-consuming. Most programs are memory gluttons, constantly requesting and releasing memory. If we made a system call for each of these operations, our programs would crawl along like snails in molasses. | ||
|
|
||
| This is where `malloc` swoops in to save the day. Think of it as your personal paper hoarder. It grabs a big stack of paper (memory) in advance, so when you need a sheet, it's right there waiting for you. Sure, you might have a bit of extra paper lying around (a small memory overhead), but the speed boost is well worth it! | ||
|
|
||
| ## Implementation: Let's Build This Thing! | ||
|
|
||
| ### The Library: Your Memory Management Toolkit | ||
|
|
||
| The `malloc` library is like a Swiss Army knife for memory management. Here's what it offers: | ||
|
|
||
| - `malloc`: Allocates a block of memory and hands you the keys (a pointer to its start). | ||
| - `free`: When you're done with the memory, you give the keys back to `free()`, and it takes care of the cleanup. | ||
| - `realloc`: Need more (or less) space? `realloc` has got you covered. It adjusts the size of your memory block while keeping your data intact. | ||
|
|
||
| ### Data Structure: The Blueprint of Our Memory Kingdom | ||
|
|
||
| Let's break down the architecture of our memory management system: | ||
|
|
||
| - **Heap**: This is a memory zone allocated by `mmap`. Think of it as a large plot of land. | ||
| - **Blocks**: These are the buildings on our land. Each heap is filled with blocks. | ||
|
|
||
| Both heaps and blocks have metadata at their start, like a signpost giving information about the property. Here's what a heap with one block looks like (imagine this after a single `malloc` call): | ||
|
|
||
| 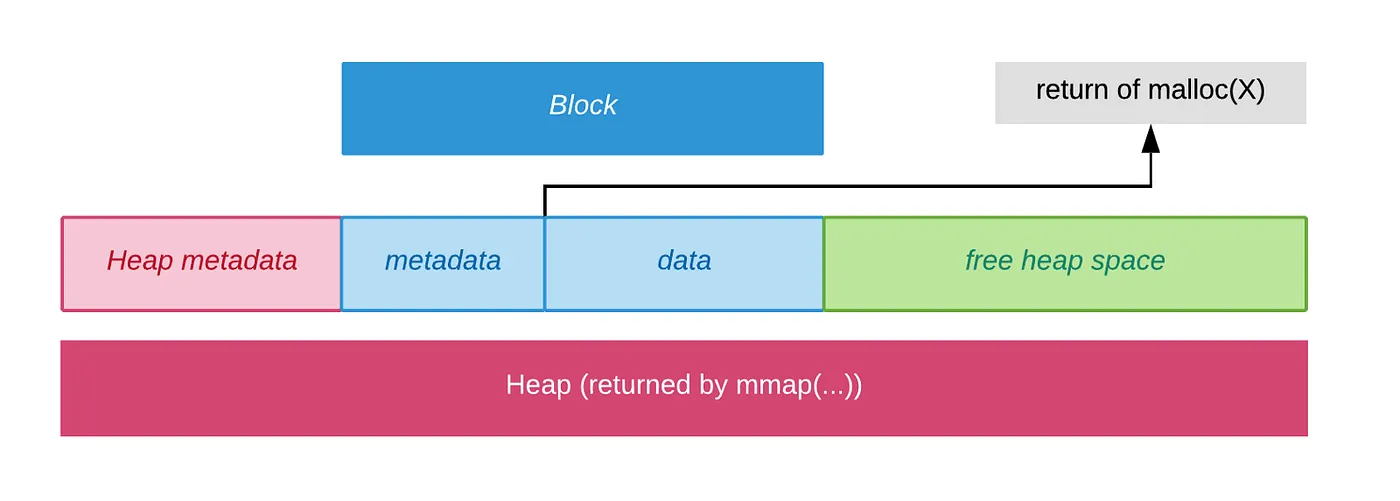 | ||
|
|
||
| Let's get a bit more technical with our metadata structures: | ||
|
|
||
|  | ||
|
|
||
| By chaining blocks with `next` and `prev` pointers, we create a linked list of memory blocks. This allows us to navigate through the heap and access any block we need. It's like creating a map of our memory kingdom! | ||
|
|
||
|  | ||
|
|
||
| ### Performance: Size Matters | ||
|
|
||
| To make our memory allocation more efficient, we categorize blocks into three sizes: `SMALL`, `TINY`, and `LARGE`. It's like having different-sized moving boxes for different items. As a rule of thumb, we aim to fit at least 100 `SMALL` and `TINY` blocks inside their own heap. `LARGE` blocks, being the odd ones out, don't get the preallocation treatment. | ||
|
|
||
| Here's a pro tip: When defining the size of a heap, it's more efficient to use a multiple of the system's page size. You can find this value using the `getpagesize()` function or by running `getconf PAGE_SIZE` in your terminal. On my system, it's 4096 bytes. | ||
|
|
||
| Let's crunch some numbers to determine our heap sizes: | ||
|
|
||
|  | ||
|
|
||
| ### The malloc Algorithm: Finding the Perfect Spot | ||
|
|
||
| When `malloc` is called, it's like a real estate agent looking for the perfect property. Here's how it goes about its search: | ||
|
|
||
| 1. It checks its records (a global variable) for any existing heap lists. | ||
| 2. It tours each heap, looking for a suitable vacant space using the [first fit strategy](https://www.quora.com/With-the-help-of-the-examples-that-you-also-provide-what-are-the-first-fit-next-fit-and-best-fit-algorithms-for-memory-management/answer/Varun-Agrawal-1). This means it grabs the first free block that's big enough. | ||
| 3. If no suitable block is found, it adds a new block to the end of the last heap. | ||
| 4. If the last heap is full, it creates a new heap by calling `mmap` (time to buy more land!). | ||
|
|
||
|  | ||
|
|
||
| ### Free and the Fragmentation Problem: Memory Tetris | ||
|
|
||
| 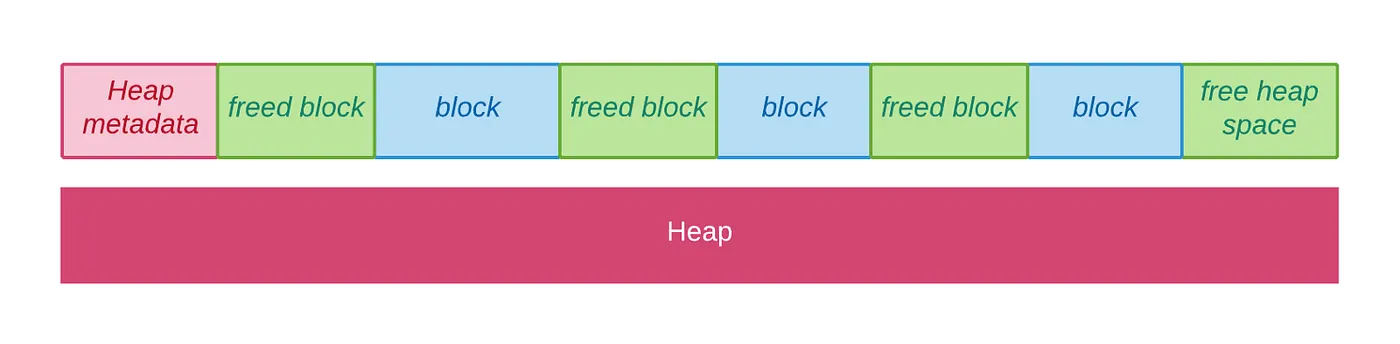 | ||
|
|
||
| When `free` is called, it marks the requested block as available. However, this can lead to a fragmentation problem, much like a game of memory Tetris where the pieces don't quite fit together. | ||
|
|
||
| To combat this, we employ a few strategies: | ||
|
|
||
| - If adjacent blocks are free, we merge them (combining Tetris pieces). | ||
| - If it's the last block in the heap and we have more than one preallocated heap, we return the memory to the system using `munmap`. | ||
|
|
||
|  | ||
|
|
||
| ### Realloc: The Shape-shifter | ||
|
|
||
| Think of `realloc` as a shape-shifting spell for your memory blocks. It's essentially a combination of `malloc`, `memcpy`, and `free`. | ||
|
|
||
| A word of caution: if you call `realloc` with a size of zero, the behavior can vary. In my implementation, I chose a "lazy" approach that simply returns the original pointer. However, it's important to note that `realloc(ptr, 0)` should not be used as a substitute for `free`. Always use the right tool for the job! | ||
|
|
||
| ## Testing: Putting Our Creation to Work | ||
|
|
||
| The best way to test our `malloc` implementation is to use it in real-world scenarios. Let's create a simple script to inject our malloc into existing commands: | ||
|
|
||
| 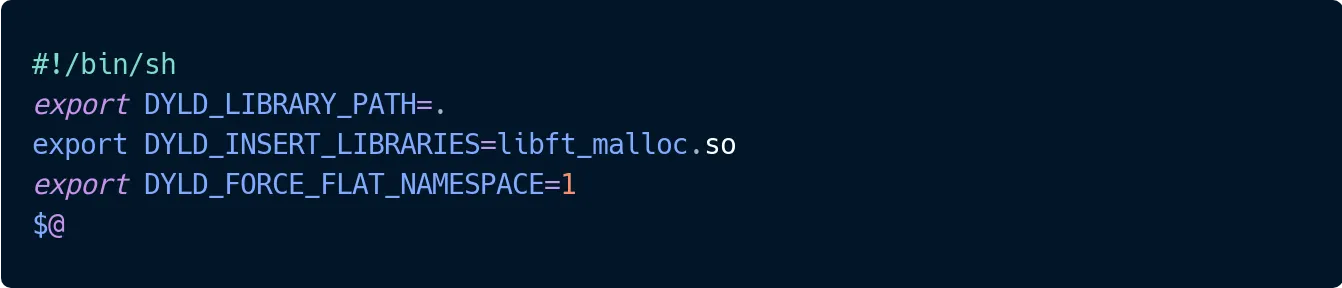 | ||
|
|
||
| Save this as `run.sh` and use it like so: `sh run.sh ${CMD}`. Now you can test your malloc with commands like `ls` or `vim`! | ||
|
|
||
| ### A Note on Memory Alignment | ||
|
|
||
| During my testing, I encountered an interesting quirk: certain commands like `vim` would cause a segmentation fault on MacOS. The culprit? Memory alignment. | ||
|
|
||
| It turns out that the MacOS `malloc` aligns data on 16-byte boundaries. To implement this in our version, we can use a simple trick: `size = (size + 15) & ~15`. This ensures our memory allocations play nicely with MacOS expectations. | ||
|
|
||
| And there you have it, folks! We've journeyed through the intricate world of memory management, built our own `malloc` library, and even tackled some real-world challenges along the way. I hope this deep dive has illuminated the inner workings of memory allocation for you. | ||
|
|
||
| Remember, practice makes perfect. If you want to explore further or need a reference, don't forget to check out the [complete implementation on my GitHub](https://github.com/jterrazz/42-malloc). Happy coding, and may your memory always be well-managed! 🚀🧠 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,150 @@ | ||
|  | ||
| _Photo by [Muhammad Zaqy Al Fattah](https://unsplash.com/@dizzydizz?utm_source=medium&utm_medium=referral) on [Unsplash](https://unsplash.com/?utm_source=medium&utm_medium=referral)_ | ||
|
|
||
| # Mastering Hash Functions in C: Unraveling the Mysteries of SHA-256 and MD5 | ||
|
|
||
| **Ever wondered how your online transactions stay secure or how your passwords remain protected?** The secret lies in the world of cryptographic hash functions. Today, we're going to demystify two of the most widely used algorithms: MD5 and SHA-256. Buckle up, because we're about to embark on a thrilling journey into the heart of digital security! | ||
|
|
||
| Not only will you gain a deep understanding of these algorithms, but you'll also learn how to implement them yourself in C. And if you're feeling adventurous, we've got a GitHub repository with a complete implementation waiting for you to explore. **Ready to become a cryptography wizard? Let's dive in!** | ||
|
|
||
| [🔗 Explore the magical realm of hash functions in our GitHub repository](https://github.com/jterrazz/42-ssl-md5?source=post_page-----78c17e657794--------------------------------) | ||
|
|
||
| ## 🔐 Cryptographic Functions: The Unsung Heroes of Digital Security | ||
|
|
||
| Imagine cryptographic functions as the silent guardians of the digital world. They're the vigilant sentinels that: | ||
|
|
||
| - Ensure the **integrity** of your messages and files, making sure they haven't been tampered with. | ||
| - Verify passwords **without ever storing them in plain text** (sneaky, right?). | ||
| - Create the foundation for **"proof of work"** in cryptocurrencies like Bitcoin and Ethereum. | ||
| - Generate and verify **digital signatures**, the virtual equivalent of your handwritten signature. | ||
|
|
||
| These digital alchemists take a message of any size and transform it into a fixed-length string of characters, known as a hash. It's like turning a novel into a unique fingerprint! For instance: | ||
|
|
||
| - MD5 produces 128-bit hashes (16 characters in hexadecimal) | ||
| - SHA-256 creates 256-bit hashes (32 characters in hexadecimal) | ||
|
|
||
| 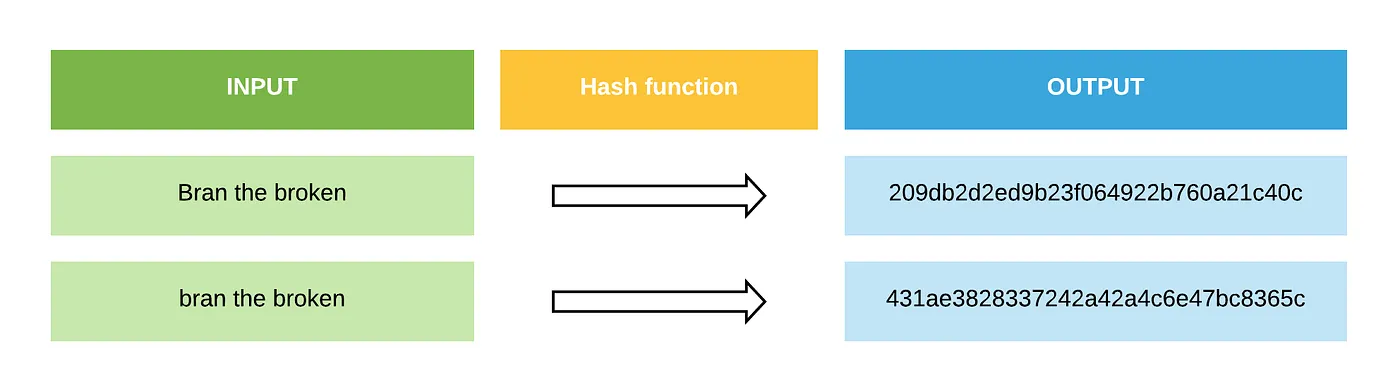 | ||
|
|
||
| ### The Superpowers of Cryptographic Hash Functions | ||
|
|
||
| These functions possess some truly remarkable properties: | ||
|
|
||
| 1. **Determinism**: Like a loyal friend, they always produce the same output for the same input. | ||
| 2. **Speed**: They're the Usain Bolt of algorithms, computing hashes quickly for inputs of any size. | ||
| 3. **One-wayness**: They're master illusionists – you can't determine the input from the hash. | ||
| 4. **Collision resistance**: It's practically impossible to find two inputs that produce the same hash. | ||
| 5. **Avalanche effect**: A tiny change in input causes a dramatically different hash, like a butterfly effect for data. | ||
|
|
||
| These properties make hash functions the Swiss Army knife of cryptography, ready for a variety of security applications. | ||
|
|
||
| ## The Contenders: MD5 vs SHA-256 | ||
|
|
||
| ### MD5: The Retired Veteran | ||
|
|
||
| MD5, once a stalwart in the cryptographic world, is now like a retired superhero. While it's no longer considered secure for cryptographic purposes (due to some sneaky vulnerabilities), it still has its uses: | ||
|
|
||
| - Checking file integrity against unintentional corruption | ||
| - Non-security-critical applications where speed is more important than bulletproof security | ||
|
|
||
| Remember: **MD5 should never be used for security-critical applications**. It's like using a plastic sword in a real duel – not a great idea! | ||
|
|
||
| ### SHA-256: The Modern Guardian | ||
|
|
||
| SHA-256, part of the SHA-2 family, is the cool younger cousin of MD5. It was developed to address the weaknesses of its predecessors (SHA-1 and SHA-0), which themselves were inspired by MD5. Talk about a family tree of algorithms! | ||
|
|
||
| SHA-256 is considered secure because: | ||
|
|
||
| - It's computationally infeasible to reverse-engineer the input from the hash. | ||
| - It has strong collision resistance. | ||
|
|
||
| However, it's not recommended for password storage in databases. Why? It's a bit too quick for its own good, making it vulnerable to brute-force and [rainbow table attacks](https://en.wikipedia.org/wiki/Rainbow_table). In the world of password hashing, slower can sometimes be safer! | ||
|
|
||
| ## The Inner Workings: A Peek Behind the Cryptographic Curtain | ||
|
|
||
| ### Step 1: Preparing the Stage (Formatting the Input) | ||
|
|
||
| Before the main show begins, we need to set the stage. The input message needs to be formatted to meet specific criteria: | ||
|
|
||
| 1. The message is divided into **512-bit chunks**. | ||
| 2. A "1" bit is added at the end of the message. | ||
| 3. "0" bits are added to make the length a multiple of (512-64) bits. | ||
| 4. The original message length is stored in the last 64 bits. | ||
|
|
||
|  | ||
| _The formatted message size must be a multiple of 512 bits_ | ||
|
|
||
| 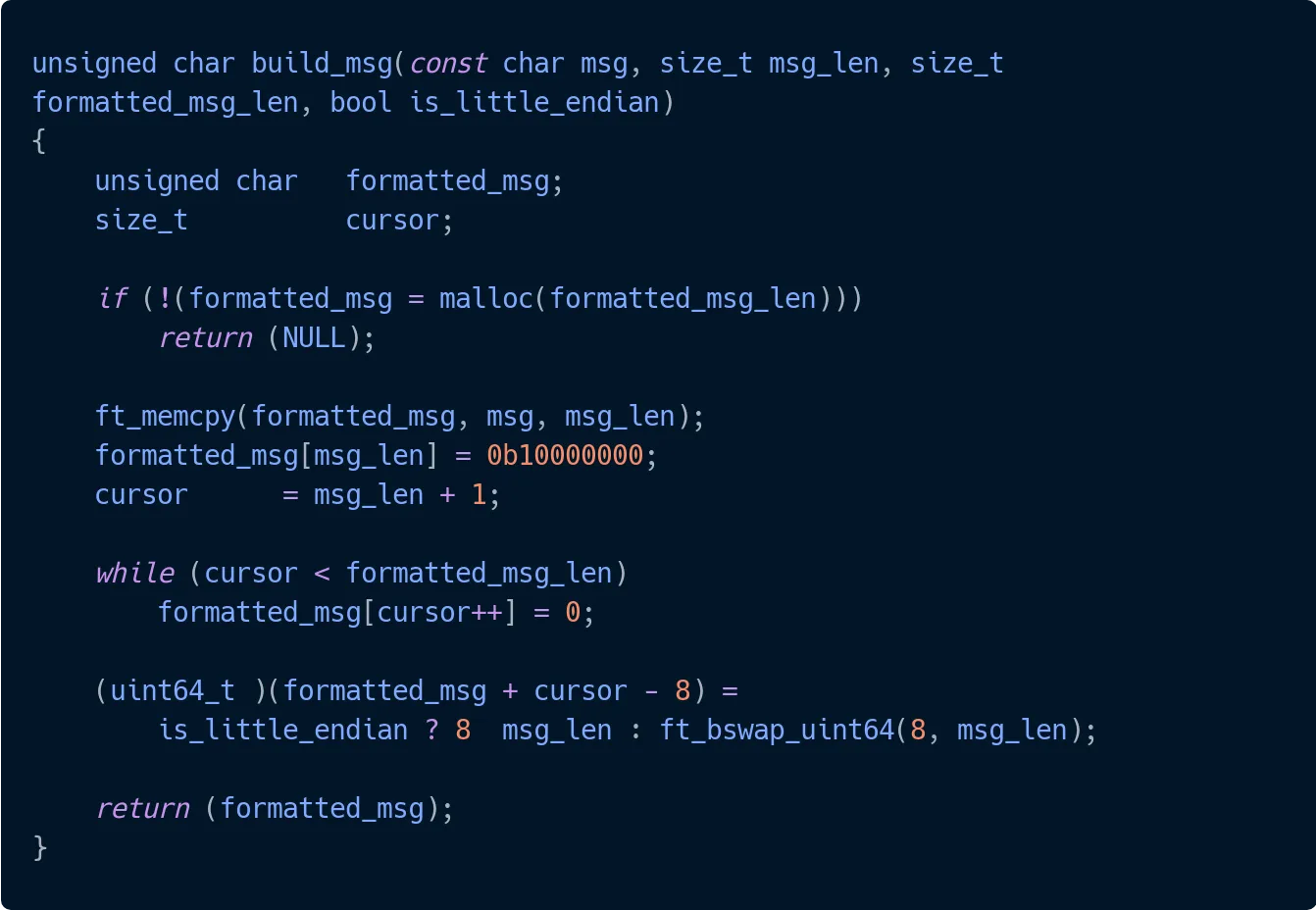 | ||
|
|
||
| To calculate the formatted message length, we use this magical formula: | ||
|
|
||
| ```c | ||
| aligned = (nb + (X-1)) & ~(X-1) | ||
| ``` | ||
|
|
||
| This aligns our number 'nb' to a multiple of 'X' bytes. It's like making sure everyone in a marching band is in perfect rows! | ||
|
|
||
|  | ||
|
|
||
| ### The Endianness Enigma: Little & Big Endian | ||
|
|
||
| Before we dive deeper, let's talk about endianness – the order in which bytes are arranged in computer memory. It's like the difference between reading a book left-to-right or right-to-left. | ||
|
|
||
| - **Little-endian**: The least significant byte comes first. | ||
| - **Big-endian**: The most significant byte comes first. | ||
|
|
||
| [🔗 Dive deeper into the endianness rabbit hole](https://medium.com/@nonuruzun/little-big-endian-dc9abe36270?source=post_page-----78c17e657794--------------------------------) | ||
|
|
||
| To convert between these two, we use a bit of binary magic: | ||
|
|
||
|  | ||
|
|
||
| This shuffling algorithm works by swapping bytes, starting with small groups and progressively expanding. It's like a choreographed dance of bits! | ||
|
|
||
| 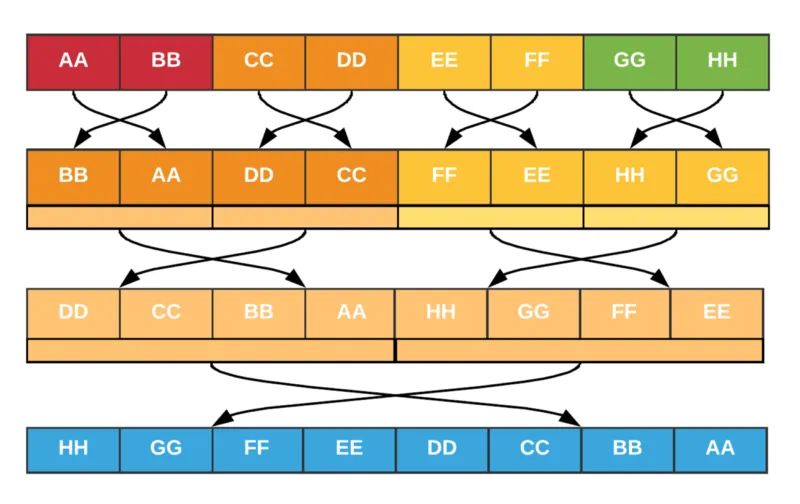 | ||
|
|
||
| ### Step 2: The Grand Shuffle (Data Processing) | ||
|
|
||
| Now comes the main event! Both MD5 and SHA-256 divide the message into 512-bit chunks and perform a series of mathematical operations on them. | ||
|
|
||
| - MD5 uses 4 32-bit buffers | ||
| - SHA-256 uses 8 32-bit buffers | ||
|
|
||
| These buffers are like jugglers, constantly tossing and catching data bits in a mesmerizing performance. The exact steps differ between MD5 and SHA-256, but both involve a complex dance of bitwise operations, modular additions, and nonlinear functions. | ||
|
|
||
| For the brave souls who want to dive into the nitty-gritty details: | ||
|
|
||
| - [🔗 MD5 Algorithm Deep Dive](https://en.wikipedia.org/wiki/MD5?source=post_page-----78c17e657794--------------------------------#Pseudocode) | ||
| - [🔗 SHA-256 Algorithm Explained](https://en.wikipedia.org/wiki/SHA-2?source=post_page-----78c17e657794--------------------------------#Pseudocode) | ||
|
|
||
| Or, if you prefer to see the algorithms in action, check out our implementations: | ||
|
|
||
| - [SHA-256 Implementation](https://github.com/jterrazz/42-ssl-md5/blob/master/src/ft_sha256/sha256.c) | ||
| - [MD5 Implementation](https://github.com/jterrazz/42-ssl-md5/blob/master/src/ft_md5/md5.c) | ||
|
|
||
| ### The Grand Finale: Building the Hash | ||
|
|
||
| After all the shuffling and juggling, we're left with 4 (for MD5) or 8 (for SHA-256) buffers. These buffers are the raw ingredients for our final hash. | ||
|
|
||
| To create the hash, we simply concatenate these buffers in their hexadecimal form. It's like assembling a puzzle where each piece is a part of the final secret code! | ||
|
|
||
|  | ||
|
|
||
| One last twist for MD5: the buffers are in little-endian format, so we need to flip them before printing. It's like reading the last page of a book first! | ||
|
|
||
|  | ||
|
|
||
| ## Need a Helping Hand? | ||
|
|
||
| If you're feeling overwhelmed by SHA-256, fear not! We've got a step-by-step guide that breaks down the process into manageable chunks: | ||
|
|
||
| - [🔗 SHA-256 Step-by-Step Guide](https://docs.google.com/spreadsheets/d/1mOTrqckdetCoRxY5QkVcyQ7Z0gcYIH-Dc0tu7t9f7tw/edit?source=post_page-----78c17e657794--------------------------------#gid=2107569783) | ||
|
|
||
| ## Wrapping Up | ||
|
|
||
| Congratulations! You've just taken a deep dive into the fascinating world of cryptographic hash functions. From understanding their crucial role in digital security to unraveling the inner workings of MD5 and SHA-256, you're now equipped with knowledge that puts you ahead of the curve. | ||
|
|
||
| Remember, the world of cryptography is vast and ever-evolving. This tutorial is just the beginning of your journey. Keep exploring, keep learning, and who knows? You might be the one to develop the next groundbreaking hash function! | ||
|
|
||
| If you're itching to see these concepts in action, don't forget to check out our GitHub repository. It's packed with complete implementations that you can tinker with and learn from. | ||
|
|
||
| Happy hashing, and may your digital adventures be secure and exciting! |
Oops, something went wrong.