这是一个通过配置文件快速得到全量上下文的插件,从而避免大模型因为上下文不足而出现的幻觉。
按下 Ctrl+Shift+P 或者 CMD+Shift+P 执行我们的初始化命令 Init Config File 初始化一个配置文件:

然后执行我们的生成命令:Generate All Code Context:

就可以在 ai_helper/prompt_builder/output/working 下看到我们的context.txt,然后直接拖拽到poe或claude等LLM的web输入框,敲击回车即可得到AI对指令的响应。(如果是chatgpt的话,目前的版本你还需要把你的指令在文本框里再输入一遍,否则可能它不正确响应)
以上就是全部操作了,Enjoy。
对于95%的人来说,到这就够用了,可以解决绝大多数场景。如果你想了解更多可以往下阅读:
可以自行在项目下创建一个简单的yaml文件,你可以准备任意多个,我们只读你取当前打开的这个,名字也随意。建议我们一个“代码上下文”一个yaml文件(比如一个模块),这样每当你想在某模块中实现某功能的的时候只要打开对应的yaml文件即可。
可参考的文件格式如下:
project:
base_path: ./
filters:
- ignore:
- .git
- ai_helper
- "config.yaml"
input:
instruction: |
我希望 实现xxxx功能。
请给出代码
output:
prompt:
path: .ai_helper/prompt_builder/output/working
backup_path: .ai_helper/prompt_builder/output/backup过滤的规则我们支持glob表达式,多个表达式是 AND 的关系。
除了ignore,我们还支持 filter_in 过滤器。可以配置为下面的样子:
project:
base_path: https://github.com/joaomdmoura/crewAI.git
filters:
- ignore:
- "" # ignore掉的 path
- filter_in:
- "**/*.py" # 保留的 path我们的filters里面可以设置多个filter,按顺序组成一个pipeline进行过滤,比如这个例子里的filter_in,就是在ignore过滤后的基础上再过滤一些文件留下。
设置完这些之后还是可以使用instruction来设置我们的任务描述,然后继续用Generate All Code Context来得到这个上下文。
我们每次的生成记录保存在了 output/prompt/backup_path 指定的一个备份文件夹。
同时,我们还把内容拷贝到了剪切板里,如果不喜欢呢,也可以关掉,开关在设置里:
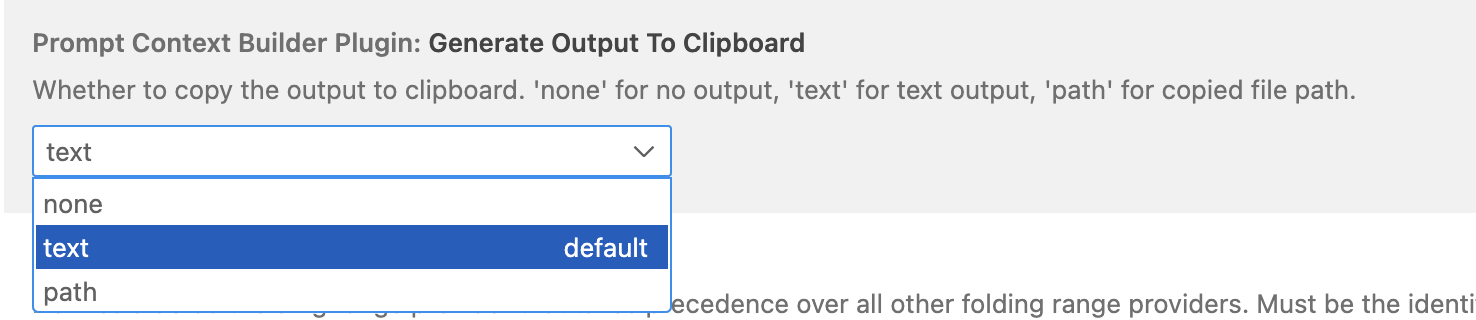
设置为none就关掉了。默认是text,表示生成的时候把文本放入剪切板,如果需要也可以指定 path 存进去,如果你需要在命令行或是什么地方用的话。
如果我们打开那个context.txt呢,我们就会发现,它里面的结构大概是这样的:
请基于 Project 里的代码, 完成下面的 Instruction
<Project>
<folder_tree>
{{ folder_tree }}
</folder_tree>
<files>
{{ all_files_xml }}
</files>
</Project>你会发现我们输出的内容都是xml,其实我们输出的格式有两种xml和markdown,一般我都是用xml,因为markdown里嵌markdown容易混乱掉格式,所以我一般用xml。这个格式也可以在设置里配置:
