User's Guide
- Key Concepts
- Creating an Engine
- Creating and Running Tasks
- Handling Errors
- Using Timeouts
- Cancelling
- Retrying
- Tracing
- Execution monitoring
- Unit Testing
- Integrating with ParSeq
Before getting into the details of using ParSeq it is worth describing a few terms that will be used frequently.
A Task is a basic unit of work in the ParSeq system that can be executed - In this regard, it is similar to a Java Callable, which is also code that needs to be called to execute, but the difference is that Task's result can be set asynchronously, meaning not synchronized on a particular timing. Tasks can be executed by an Engine (see below). They are not executed by the user directly. Task implements a Promise which is like a fully asynchronous Java Future. Tasks can be transformed and composed to produce desired results. A Plan is collection of tasks executed as a consequence of running a root task.
An Engine is used to run tasks. Normally application has one instance of Engine.
For users come from other libraries, here is a table that might help to understand concepts in ParSeq.
The Engine is used to run tasks in the ParSeq framework. To construct an instance, use:
import com.linkedin.parseq.Engine;
import com.linkedin.parseq.EngineBuilder;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
// ...
final int numCores = Runtime.getRuntime().availableProcessors();
final ExecutorService taskScheduler = Executors.newFixedThreadPool(numCores + 1);
final ScheduledExecutorService timerScheduler = Executors.newSingleThreadScheduledExecutor();
final Engine engine = new EngineBuilder()
.setTaskExecutor(taskScheduler)
.setTimerScheduler(timerScheduler)
.build();With these settings ParSeq will have numCores + 1 threads available for executing tasks and 1 thread available for scheduling timers. These settings are reasonable place to start, but can be customized to particular use cases.
To stop the engine, use:
engine.shutdown();
engine.awaitTermination(1, TimeUnit.SECONDS);
taskScheduler.shutdown();
timerScheduler.shutdown();This will initiate shutdown (no new tasks can be executed, but old tasks are allowed to finish) and waits for the engine to quiesce within 1 second. This also shuts down the executors that are used by ParSeq. ParSeq does not manage the lifecycle for these executors.
We do not recommend using the CallerRunsPolicy or the AbortPolicy with the underlying ParSeq task executor. The former may tie up unrelated threads (e.g. IO worker threads) in the execution of ParSeq tasks. The latter, as of v1.3.7, will cause a plan to be aborted if it cannot be rescheduled due to a RejectedExecutionException.
Instead we recommend using standard strategies for managing overload: back-pressure, load shedding, or degraded responses. In addition, the time spent on a plan can be bounded using a timeouts.
Initially tasks are created by integrating existing libraries with ParSeq. If task involves non-blocking computation, it can be created using Task.action() or Task.callable(). We also provide Task.value() and Task.failure() for most trivial cases.
The Task interface contains multiple methods to create a task. Not all of them are exposed for external use and below are the ones that provided to the users.
| Method | When to use |
|---|---|
| Task.value() | Create a Task which will be resolved using given value ; This is the method to use for wrapping a value. |
| Task.failure() | Create a Task which will fail with given exception ; This is the method to use for wrapping an exception. |
| Task.callable() | Wrap callable code into a Task; This is the method to use to wrap callable which returning a value into Task. Note this method should not be used for blocking execution that need to run for a long time. Task created by this method will block ParSeq engine to pick up other tasks in same plan, before this blocking code finish. |
| Task.action() | Similar to Task.callable(), but is for callable that does not return a value, for example, for code that run as side-effect |
| Task.blocking() | Wrap blocking code logic into a Task; This is the method to use to wrap callable into Task, but the callable will be running in another executor service. It uses more resource overhead than Task.callable(), but it will not block other tasks in the current plan to be picked up. Users are recommended to use this method to run blocking code that will run for a long time. |
| Task.async(Callable<Promise>) | To pass in a callable which return a Promise. This method is useful when for example integrating other async library with ParSeq |
New tasks will also be created by transforming and composing existing tasks.
Few words about ParSeq API: most of the methods that create new tasks have version that accept task description. We recommend to give short, clear description to every task. It provides great value when it comes to debugging and troubleshooting using ParSeq's tracing mechanisms.
Almost every method on ParSeq Task interface creates a new instance of a Task that may refer to the task used to create it e.g. sub-task might depend on original task's result and cause the sub-task to run when executed by an engine.
Tasks are lazy. They are descriptions of computations that will happen when task is executed by engine. Once you've created a task, you can run it by submitting it to the engine:
engine.run(task);Examples of other APIs that creates transforming task or creates composition tasks.
| Category | Note |
|---|---|
| Transformation: e.g. .map() .transform() .flatMap() | Create another task to transform value of previous task. |
| Composition Sequential: e.g. .andThen() Tasks.seq() | The successor task begins after predecessor task finish |
| Composition Parallel: e.g. Task.par() | Tasks will begin in parallel. Please note this is not tasks running in parallel. Tasks run by Task.par() are essentially concurrent tasks, see Exeuction Model Introduction about difference between "concurrent" and "parallel". |
A main mechanism of transforming tasks is a map() method.
Suppose we only need the HTTP content type of google home page. Having instance of a Task<Response> that makes HTTP HEAD request:
Task<Response> head = HttpClient.head("http://www.google.com").task();we can transform it into a task that returns the content type with the following code:
Task<String> contentType =
head.map("toContentType", response -> response.getContentType());Note that existing head task has not been modified. Instead, a new task was created that, when executed, will first run head task and, after it is resolved, will apply provided transformation. If head task failed for any reason then the contentType task would also fail and provided transformation would not be invoked. This mechanism is described in details in Handling Errors section.
Using ParSeq's tracing tools we would get the following diagram for the task above:

If there is a need to only consume result produced by a task then we can use andThen() method:
Task<String> printContentType = contentType.andThen("print", System.out::println);
In above example we used Java 8 Method Reference but we could as well use Lambda Expression:
Task<String> printContentType = contentType.andThen("print", s -> System.out.println(s));Similarly, if we need to consume potential failure of a task we can use onFailure() method:
Task<String> logFailure = contentType.onFailure("print stack trace", e -> e.printStackTrace());
Sometimes it is useful to treat potential failure of a task more explicitly. toTry() method that transforms Task<T> into Task<Try<T>> where Try type explicitly represents possibility of task failure:
Task<Try<String>> contentType =
head.map("toContentType", response -> response.getContentType()).toTry();
Task<Try<String>> logContentType =
contentType.andThen("log", type -> {
if (type.isFailed()) {
type.getError().printStackTrace();
} else {
System.out.println("Content type: " + type.get());
}
});
Finally, transform() method combines toTry() with map():
Task<Response> get = HttpClient.get("http://www.google.com").task();
Task<Optional<String>> contents = get.transform("getContents", tryGet -> {
if (tryGet.isFailed()) {
return Success.of(Optional.empty());
} else {
return Success.of(Optional.of(tryGet.get().getResponseBody()));
}
});
In the example above contents task always completes successfully returning contents of google page wrapped with Optional or Optional.empty() if HTTP GET request failed.
Many tasks are composed of other tasks that are run sequentially or in parallel.
Suppose we want to get String consisting of the content types of a few different pages fetched in parallel.
First, let's create a helper method that returns a task responsible for fetching content type for a URL.
private Task<String> getContentType(String url) {
return HttpClient.get(url).task()
.map("getContentType", response -> response.getContentType());
}We can use Task.par() method to compose tasks to run in parallel:
final Task<String> googleContentType = getContentType("http://www.google.com");
final Task<String> bingContentType = getContentType("http://www.bing.com");
final Task<String> contentTypes =
Task.par(googleContentType, bingContentType)
.map("concatenate", (google, bing) -> "Google: " + google + "\n" +
"Bing: " + bing + "\n");Task.par() creates a new task that will run the googleContentType and bingContentType tasks in parallel. We transformed result into String using map() method.
Diagram representing above example:
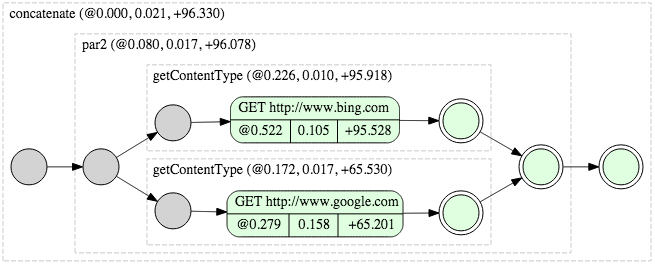
Result of running task above:
Google: text/html; charset=ISO-8859-1
Bing: text/html; charset=utf-8
We talk about sequential composition when we need to run tasks sequentially.
ParSeq provides andThen() method that can be used to run a task after completion of another task. Second task is executed regardless of the result of first task i.e. even if the first task fails:
// task that processes payment
Task<PaymentStatus> processPayment = processPayment(...);
// task that ships product
Task<ShipmentInfo> shipProduct = shipProduct(...);
Task<ShipmentInfo> shipAfterPayment =
processPayment.andThen("shipProductAterPayment", shipProduct);
In the example above shipProduct task will run even if processPayment task fails. Notice that shipProduct does not depend on an actual result of the task that proceeds it.
In many situations second task directly depends on a result of first task. Let's discuss this on the following example. Suppose we would like to get information about the first image from a given web page. We will write a task that will fetch a web page contents, find first reference to an image in it, fetch that image and return short description of it. We will have two asynchronous tasks: fetching page contents and fetching first image. Obviously second task depends on an actual result of the first task.
Please note there are two andThen() methods. They have different behaviors. One takes Task as a parameter which is the same as the example above. Another one takes Consumer as a parameter, and has been explained in the "Transforming Tasks" section, that if first task fails then consumer will not be called and failure will be propagated to task returned by this method.
Let's decompose this problem into smaller pieces. First we'll need tasks to fetch data given a URL. We need a version that treats contents as a String to fetch web page contents and one that treats contents as a binary data - for the image:
private Task<String> getAsString(String url) {
return HttpClient.get(url).task()
.map("bodyAsString", response -> response.getResponseBody());
}
private Task<byte[]> getAsBytes(String url) {
return HttpClient.get(url).task()
.map("bodyAsBytes", response -> response.getResponseBodyAsBytes());
}Having methods above we can write a method that returns info for an image (for simplicity just its length), given its URL:
private Task<String> info(String url) {
return getAsBytes(url).map("info", body -> url + ": length = " + body.length);
}We will also need a way to find occurrence of first image given a web page contents. Naive implementation (serving just as an example) might look like this:
private String findFirstImage(String body) {
Pattern pat = Pattern.compile("[\\('\"]([^\\(\\)'\"]+.(png|gif|jpg))[\\)'\"]");
Matcher matcher = pat.matcher(body);
matcher.find();
return matcher.group(1);
}We have all the pieces, let's combine them. First approach, using map() method:
getAsString(url).map("firstImageInfo", body -> info(url + findFirstImage(body)));The problem is that type of this expression is Task<Task<String>>. This situation (nested tasks) will occur when one task depends on an outcome of another task. In this case task that fetches image obviously depends on the outcome of task that fetches the contents of a web page. There is a method that can flatten such an expression, unsurprisingly called Task.flatten():
Task.flatten(getAsString(url).map("firstImageInfo", body -> info(url + findFirstImage(body))));Result of above expression has type Task<String>. This is such a common pattern that there is a shorthand which combines flatten() and map() called flatMap():
getAsString(url).flatMap("firstImageInfo", body -> info(url + findFirstImage(body)));Now we can write a method that returns info of a first image of a given web page:
private Task<String> firstImageInfo(String url) {
return getAsString(url).flatMap("firstImageInfo", body -> info(url + findFirstImage(body)));
}Let's use it on google.com:
final Task<String> firstImageInfo = firstImageInfo("http://www.google.com");Result:
http://www.google.com/images/google_favicon_128.png: length = 3243
Trace obtained from this task:

Finally let's combine sequential and parallel composition. We will, in parallel, get info of first image on google.com and bing.com web pages:
final Task<String> googleInfo = firstImageInfo("http://www.google.com");
final Task<String> bingInfo = firstImageInfo("http://www.bing.com");
Task<String> infos = Task.par(googleInfo, bingInfo)
.map("concatenate", (google, bing) -> "Google: " + google + "\n" +
"Bing: " + bing + "\n");Running above task would yield the following trace:
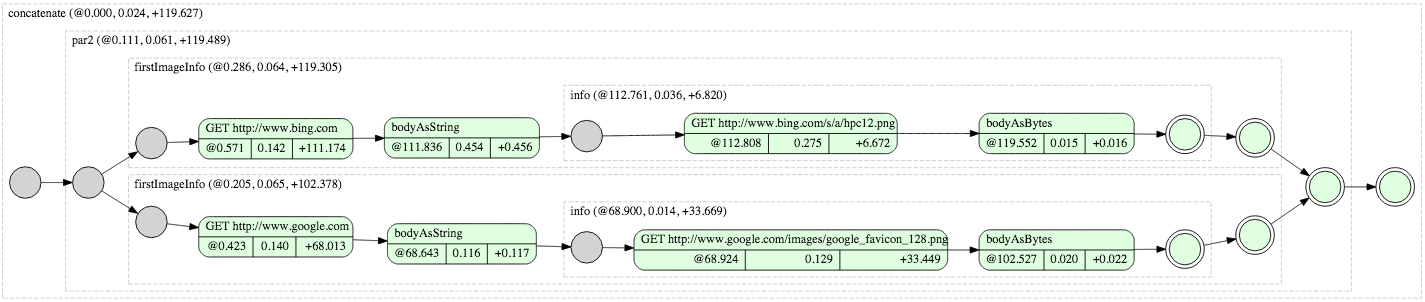
And here is the result:
Google: http://www.google.com/images/google_favicon_128.png: length = 3243
Bing: http://www.bing.com/s/a/hpc12.png: length = 5574
Main principle in ParSeq is that task failure is always propagated to tasks that depend on it. Generally there is no need for catching or re-throwing exceptions:
Task<String> failing = Task.callable("hello", () -> {
return "Hello World".substring(100);
});
Task<Integer> length = failing.map("length", s -> s.length());In example above length task would fail with java.lang.StringIndexOutOfBoundsException that was propagated from failing task.

Often degraded behavior is a better choice than simply propagating an exception. If there exists a reasonable fallback value we can use recover() method to recover from a failure:
Task<String> failing = Task.callable("hello", () -> {
return "Hello World".substring(100);
});
Task<Integer> length = failing.map("length", s -> s.length())
.recover("withDefault0", e -> 0);This time length task recovers from java.lang.StringIndexOutOfBoundsException with fallback default value 0. Notice that recovery function accepts exception that caused the failure as a parameter.

Sometimes we don't have fallback value ready to be used but we can compute it using another task e.g. compute it asynchronously. In those cases we can use recoverWith() method. The difference between recover() and recoverWith() is that the latter returns an instance of a Task that will be executed to obtain fallback value. The following example shows how to use recoverWith() to fetch a user from main DB when fetching it from cache failed:
Task<Person> user = fetchFromCache(id)
.recoverWith(e -> fetchFromDB(id));
It is a good idea to set a timeout on asynchronous tasks. ParSeq provides withTimeout() method to do that:
final Task<Response> google = HttpClient.get("http://google.com").task()
.withTimeout(10, TimeUnit.MILLISECONDS);In above example google task will fail with TimeoutException if fetching contents of google.com takes more 10ms.

ParSeq supports tasks cancellation. Cancelling a task means that result of that task is not relevant anymore. Task can be cancelled at any time. Implementation of a task can detect situation when it has been cancelled and react to it accordingly. Cancelled task completes with CancellationException and thus behaves like a failed task i.e. cancellation is automatically propagated to all tasks that depend on it. Even though cancelled tasks are effectively failed, methods that handle failures such as recover(), recoverWith(), onFailure() etc. are not called when task is cancelled. The reason is that task cancellation means that result of a task is not relevant, thus normally there is no point trying to recover from this situation. To cancel a task we can call cancel() method.
Usually the main goal of a task is to calculate a value. You can think of a task as an asynchronous function and once the value has been calculated there is no point in running the same task again. Thus, ParSeq will run any task only once. Engine will recognize task that has been completed (or even started) and will not run it again.
It is possible for the value of a task to be known before it finishes its execution or even before it starts. One of such cases occurs when we specify timeout for a task. After the specified time duration, the task will be marked as failed by timeoutTimer even though the task execution might still be running. In such cases ParSeq will automatically cancel the original task with EarlyFinishException and all its dependent tasks due to failure propagation, and current task will fail with TimeoutException
To illustrate using an example:
Task<Response> fetchContent = HttpClient.get("http://google.com").task();
final Task<Response> fetchWithTimeout = fetchContent.withTimeout(10, TimeUnit.MILLISECONDS);When the timeout happens, fetchWithTimeout task will fail with TimeoutException, and the original fetchContent task will be cancelled (fail with EarlyFinishException), note this does not mean fetchWithTimeout is cancelled. fetchWithTimeout can be handled using failure handling methods.
Trace visualization timeout example:
Resulting task has failed after 10ms, as represented by red circle, while the original GET task has been automatically cancelled with EarlyFinishException, which is represented by yellow color. See tracing section for details describing generated diagrams.
Sometimes, especially when network calls are involved, tasks could fail for random reasons and in many cases simple retry would fix the problem. ParSeq Retry provides a flexible mechanism for configuring a retry behavior, allowing your application to be more resilient to intermittent failures.
The most simple example provides basic retry functionality:
Task<String> task1 = Task.withRetryPolicy(RetryPolicy.attempts(3, 500), () -> Task.value("Hello, World!"));
Task<String> task2 = Task.withRetryPolicy(RetryPolicy.duration(5000, 500), () -> Task.value("Hello, World!"));It's possible for the task generator to take the current attempt number (zero-based):
Task<String> task =
Task.withRetryPolicy(RetryPolicy.attempts(3, 500), attempt -> Task.value("Current attempt: " + attempt));It's also recommended to specify the operation name, so that it can be used for logging and naming of ParSeq tasks:
Task<String> task =
Task.withRetryPolicy("sampleOperation", RetryPolicy.attempts(3, 500), () -> Task.value("Hello, World!"));Instead of using predefined RetryPolicy helpers it's possible to use a RetryPolicyBuilder to create a custom retry policy:
RetryPolicy retryPolicy = new RetryPolicyBuilder()
.setTerminationPolicy(TerminationPolicy.limitAttempts(3))
.setBackoffPolicy(BackoffPolicy.exponential(10))
.build();Not every task failure is intermittent and should be retried. Retry policy can be configured to do error classification:
Function<Throwable, ErrorClassification> errorClassifier =
error -> error instanceof TimeoutException ? ErrorClassification.RECOVERABLE : ErrorClassification.UNRECOVERABLE;
RetryPolicy retryPolicy = new RetryPolicyBuilder()
.setTerminationPolicy(TerminationPolicy.limitAttempts(3))
.setErrorClassifier(errorClassifier)
.build();
Task<Integer> task = Task.withRetryPolicy(retryPolicy, () -> Task.value(Random.nextInt(10)));To configure the number of retry attempts there are a few termination policies available:
RetryPolicy retryPolicy = new RetryPolicyBuilder()
.setTerminationPolicy(TerminationPolicy.limitDuration(1000))
.build();
Task<String> task = Task.withRetryPolicy(retryPolicy, () -> Task.value("Hello, World!"));The limitDuration policy would limit the total duration of the task (including all retries) to the provided number of milliseconds. Be careful: if the task fails fast, that could mean a lot of retries!
Other available termination policies include requireBoth, requireEither, alwaysTerminate and neverTerminate. It is possible to configure your own by implementing TerminationPolicy interface.
NOTE: When building a retry policy, there should be always some termination policy specified, otherwise exception will be thrown.
Simple retry policy from the examples above would retry failed tasks immediately. Sometimes it's a good idea to have some delay between retry attempts. To implement some delay between retries, the number of milliseconds should be passed to the policy:
Task<String> task = Task.withRetryPolicy(RetryPolicy.attempts(3, 1000), () -> Task.value("Hello, World!"));NOTE: Having non-zero backoff value specifies delay between completing previous attempt and scheduling new attempt. The counter starts after the task completes, not when it starts. For example, if your task takes exactly 500ms to complete and you have backoff time of 1000s then requests would come approximately every 1500ms.
Simple constant backoff is not always the best approach and variable delays would produce higher success ratios. It's possible to configure backoff policies:
RetryPolicy retryPolicy = new RetryPolicyBuilder()
.setTerminationPolicy(TerminationPolicy.limitAttempts(3))
.setBackoffPolicy(BackoffPolicy.constant(1000))
.build();
Task<String> task = Task.withRetryPolicy(retryPolicy, () -> Task.value("Hello, World!"));There are several backoff policies available: constant, linear, exponential, fibonacci, randomized, selected. It's also possible to create your own by implementing BackoffPolicy interface.
See Tracing for details about ParSeq's tracing and visualization features.
In order for ParSeq based application to be responsive, ParSeq threads can not be blocked for a long period of time because it prevents other plans from progressing. Such blocking is typically caused by a programming mistake e.g. a 3rd party library is called and library blocks the thread without clearly documenting it. These problems are very hard to detect and debug. It is common that they occur sporadically and they last for a very short period of time e.g. thread might be blocked for 1 second. Execution Monitoring is a mechanism which can help detect such problems before they seriously affect the system. It is designed to avoid detecting platform level problems e.g. long STW GC pauses, VM pauses etc.
When enabled, all ParSeq threads start updating their state on every work they do. There exists a monitoring thread that periodically checks a state of all ParSeq threads and when it detects that at least one of the threads is stuck in executing work longer than specified amount of time, a log entry is generated. Log entry contains full thread dump of all threads and information about states of ParSeq threads before and after the thread dump was taken. Because taking a full thread dump is an expensive operation it is rate limited (by default to 1 per minute).
| Property | Description | Default value |
|---|---|---|
_MonitorExecution_ |
When true the Execution Monitoring will be enabled. |
false |
_ExecutionMonitorDurationThresholdNano_ |
Specifies the duration of execution that is considered to be exceedingly long. Thread executing longer than this value will trigger log event containing thread dump and state of all actively monitored threads. Unit of this value is nanoseconds. | 1000_000_000 |
_ExecutionMonitorCheckIntervaldNano_ |
Interval at which monitoring thread checks for long running tasks. Unit of this value is nanoseconds. | 10_000_000 |
_ExecutionMonitorIdleDurationNano_ |
Specifies amount of time after which thread is removed from a list of actively monitored threads if it has not been running any tasks. This allows detection of dead and inactive threads. Unit of this value is nanoseconds. | 60_000_000_000 |
_ExecutionMonitorLoggingIntervalNano_ |
Specifies minimum amount of time between two log events generated by Execution Monitoring. This is to avoid excessive logging because thread dumps can be large. Unit of this value is nanoseconds. | 60_000_000_000 |
_ExecutionMonitorLogLevel_ |
Level at which log events containing state of monitored threads and thread dump is emitted. | Level.WARN |
_MaxExecutionMonitors_ |
Maximum number of threads monitored by Execution Monitoring. It should be greater than expected number of threads in ParSeq thread pool. When number of active threads exceeds this number then warning is logged and some threads will not be monitored. | 1024 |
_ExecutionMonitorMinStallNano_ |
Specifies minimum amount of time which is considered a significant platform stall. In order to avoid triggering thread dumps on events such as long STW GCs Execution Monitoring tries to identify stalls caused by external factors by measuring the difference between time at which monitoring thread was woken up and scheduled wake up time. The difference is considered to be a stall if it is larger than this parameter. Unit of this value is nanoseconds. | 10_000_000 |
_ExecutionMonitorStallsHistorySize_ |
Size of the maximum stalls history to be kept in memory. | 1024 |
It might be a good idea, especially when this feature is used for the first time, to redirect logs to a separate log file. Below are config snippets that will do that.
For log4j2:
<Appender type="RollingFile" name="ExecutionMonitoringAppender"
fileName="logs/parseq-execution-monitoring.log"
append="true"
filePattern="logs/parseq-execution-monitoring.log.%d{yyyy-MM-dd}.gz">
<Layout type="PatternLayout" pattern="%d{yyyy/MM/dd HH:mm:ss.SSS} %p %m%n" />
<Policies>
<Policy type="TimeBasedTriggeringPolicy"/>
</Policies>
</Appender>
<Logger type="AsyncLogger" name="com.linkedin.parseq.internal.ExecutionMonitor" additivity="false" level="warn">
<AppenderRef ref="ExecutionMonitoringAppender"/>
</Logger>For logback:
<appender name="ExecutionMonitoringAppender" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${application.home}/logs/parseq-execution-monitoring.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- daily rollover -->
<fileNamePattern>${application.home}/logs/parseq-execution-monitoring.log.%d{yyyy-MM-dd}</fileNamePattern>
<!-- keep 30 days' worth of history -->
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder>
<pattern>%d{yyyy/MM/dd HH:mm:ss.SSS} %level %msg%n</pattern>
</encoder>
</appender>
<logger name="com.linkedin.parseq.internal.ExecutionMonitor" additivity="false"
level="WARN">
<appender-ref ref="ExecutionMonitoringAppender"/>
</logger>Ids of threads that have been blocked are marked with (!). Since taking a full thread dump may take a lot of time a state of all ParSeq threads is reported twice: before and after taking thread dump.
2017-08-08 17:47:00,047 [ParSeqExecutionMonitor] WARN com.linkedin.parseq.internal.ExecutionMonitor: Found ParSeq threads running longer than 1000ms.
Monitored ParSeq threads before thread dump:
Thread Id=17 idle for 1006.902ms
Thread Id=18 idle for 1006.931ms
Thread Id=19 idle for 1008.102ms
Thread Id=20 idle for 1008.06ms
Thread Id=21 idle for 1007.096ms
Thread Id=13 idle for 1008.086ms
(!) Thread Id=14 busy for 1008.115ms
Thread Id=15 idle for 1007.01ms
Thread Id=16 idle for 1008.12ms
Thread dump:
"pool-1-thread-9" Id=21 WAITING on lock=java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@707eaac3
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1081)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
"pool-1-thread-8" Id=20 WAITING on lock=java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@707eaac3
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1081)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
"pool-1-thread-7" Id=19 WAITING on lock=java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@707eaac3
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1081)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
"pool-1-thread-6" Id=18 WAITING on lock=java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@707eaac3
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1081)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
"pool-1-thread-5" Id=17 WAITING on lock=java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@707eaac3
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1081)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
"pool-1-thread-4" Id=16 WAITING on lock=java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@707eaac3
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1081)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
"pool-1-thread-3" Id=15 WAITING on lock=java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@707eaac3
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1081)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
"pool-1-thread-2" Id=14 TIMED_WAITING
at java.lang.Thread.sleep(Native Method)
at com.linkedin.parseq.internal.TestExecutionMonitor.lambda$4(TestExecutionMonitor.java:200)
at com.linkedin.parseq.internal.TestExecutionMonitor$$Lambda$29/673068808.run(Unknown Source)
at com.linkedin.parseq.Task.lambda$12(Task.java:908)
at com.linkedin.parseq.Task$$Lambda$45/520232556.call(Unknown Source)
at com.linkedin.parseq.Task.lambda$16(Task.java:1080)
at com.linkedin.parseq.Task$$Lambda$55/1159114532.apply(Unknown Source)
at com.linkedin.parseq.Task$1.run(Task.java:1117)
at com.linkedin.parseq.BaseTask.doContextRun(BaseTask.java:232)
at com.linkedin.parseq.BaseTask.contextRun(BaseTask.java:200)
at com.linkedin.parseq.internal.ContextImpl$1.run(ContextImpl.java:90)
at com.linkedin.parseq.internal.SerialExecutor$DrainingExecutorLoop.run(SerialExecutor.java:133)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Locked synchronizers: count = 1
- java.util.concurrent.ThreadPoolExecutor$Worker@10d59286
"pool-1-thread-1" Id=13 WAITING on lock=java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@707eaac3
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1081)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
"ParSeqExecutionMonitor" Id=12 RUNNABLE
at sun.management.ThreadImpl.dumpThreads0(Native Method)
at sun.management.ThreadImpl.dumpAllThreads(ThreadImpl.java:446)
at com.linkedin.parseq.internal.ThreadDumper.dumpThreadInfoWithLocks(ThreadDumper.java:62)
at com.linkedin.parseq.internal.ThreadDumper.threadDump(ThreadDumper.java:45)
at com.linkedin.parseq.internal.ExecutionMonitor.logMonitoredThreads(ExecutionMonitor.java:268)
at com.linkedin.parseq.internal.ExecutionMonitor.monitorStep(ExecutionMonitor.java:215)
at com.linkedin.parseq.internal.ExecutionMonitor.monitor(ExecutionMonitor.java:168)
at com.linkedin.parseq.internal.ExecutionMonitor$$Lambda$13/1205555397.run(Unknown Source)
at java.lang.Thread.run(Thread.java:745)
"Attach Listener" Id=11 RUNNABLE
"ReaderThread" Id=10 RUNNABLE (running in native)
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.read(SocketInputStream.java:150)
at java.net.SocketInputStream.read(SocketInputStream.java:121)
at sun.nio.cs.StreamDecoder.readBytes(StreamDecoder.java:284)
at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:326)
at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178)
- locked java.io.InputStreamReader@7eb94abc
at java.io.InputStreamReader.read(InputStreamReader.java:184)
at java.io.BufferedReader.fill(BufferedReader.java:161)
at java.io.BufferedReader.readLine(BufferedReader.java:324)
- locked java.io.InputStreamReader@7eb94abc
at java.io.BufferedReader.readLine(BufferedReader.java:389)
at org.testng.remote.strprotocol.BaseMessageSender$ReaderThread.run(BaseMessageSender.java:254)
"Signal Dispatcher" Id=4 RUNNABLE
"Finalizer" Id=3 WAITING on lock=java.lang.ref.ReferenceQueue$Lock@7a86c1b3
at java.lang.Object.wait(Native Method)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:142)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:158)
at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:209)
"Reference Handler" Id=2 WAITING on lock=java.lang.ref.Reference$Lock@3f844087
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:502)
at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:157)
"main" Id=1 TIMED_WAITING on lock=java.util.concurrent.CountDownLatch$Sync@3aa9dd06
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireSharedNanos(AbstractQueuedSynchronizer.java:1037)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.tryAcquireSharedNanos(AbstractQueuedSynchronizer.java:1328)
at java.util.concurrent.CountDownLatch.await(CountDownLatch.java:277)
at com.linkedin.parseq.promise.SettablePromiseImpl.await(SettablePromiseImpl.java:90)
at com.linkedin.parseq.promise.DelegatingPromise.await(DelegatingPromise.java:56)
at com.linkedin.parseq.ParSeqUnitTestHelper.runAndWait(ParSeqUnitTestHelper.java:170)
at com.linkedin.parseq.ParSeqUnitTestHelper.runAndWait(ParSeqUnitTestHelper.java:153)
at com.linkedin.parseq.AbstractBaseEngineTest.runAndWait(AbstractBaseEngineTest.java:60)
at com.linkedin.parseq.internal.TestExecutionMonitor.testThreadDump(TestExecutionMonitor.java:200)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:483)
at org.testng.internal.MethodInvocationHelper.invokeMethod(MethodInvocationHelper.java:85)
at org.testng.internal.Invoker.invokeMethod(Invoker.java:639)
at org.testng.internal.Invoker.invokeTestMethod(Invoker.java:816)
at org.testng.internal.Invoker.invokeTestMethods(Invoker.java:1124)
at org.testng.internal.TestMethodWorker.invokeTestMethods(TestMethodWorker.java:125)
at org.testng.internal.TestMethodWorker.run(TestMethodWorker.java:108)
at org.testng.TestRunner.privateRun(TestRunner.java:774)
at org.testng.TestRunner.run(TestRunner.java:624)
at org.testng.SuiteRunner.runTest(SuiteRunner.java:359)
at org.testng.SuiteRunner.runSequentially(SuiteRunner.java:354)
at org.testng.SuiteRunner.privateRun(SuiteRunner.java:312)
at org.testng.SuiteRunner.run(SuiteRunner.java:261)
at org.testng.SuiteRunnerWorker.runSuite(SuiteRunnerWorker.java:52)
at org.testng.SuiteRunnerWorker.run(SuiteRunnerWorker.java:86)
at org.testng.TestNG.runSuitesSequentially(TestNG.java:1215)
at org.testng.TestNG.runSuitesLocally(TestNG.java:1140)
at org.testng.TestNG.run(TestNG.java:1048)
at org.testng.remote.AbstractRemoteTestNG.run(AbstractRemoteTestNG.java:132)
at org.testng.remote.RemoteTestNG.initAndRun(RemoteTestNG.java:236)
at org.testng.remote.RemoteTestNG.main(RemoteTestNG.java:81)
Monitored ParSeq threads after thread dump:
Thread Id=17 idle for 1012.044ms
Thread Id=18 idle for 1012.073ms
Thread Id=19 idle for 1013.244ms
Thread Id=20 idle for 1013.202ms
Thread Id=21 idle for 1012.238ms
Thread Id=13 idle for 1013.228ms
(!) Thread Id=14 busy for 1013.257ms
Thread Id=15 idle for 1012.152ms
Thread Id=16 idle for 1013.262ms
ParSeq comes with a test classified artifact that contains BaseEngineTest which can be used as a base class for ParSeq related tests. It will automatically create and shut down engine for every test case and provides many useful methods for running and tracing tasks.
To use it add the following dependency in build.gradle
testCompile group: 'com.linkedin.parseq', name: 'parseq', version:'3.0.0', classifier:'test'
Or in Maven pom.xml:
<dependency>
<groupId>com.linkedin.parseq</groupId>
<artifactId>parseq</artifactId>
<version>2.0.5</version>
<classifier>test</classifier>
<scope>test</scope>
</dependency>This section describes how to integrate existing asynchronous libraries with ParSeq. We provided two examples that might be useful as further guides:
- parseq-http-client integrates async http client and provides tasks for making asynchronous HTTP requests
- parseq-exec integrates Java's Process API and provides tasks for asynchronous running native processes
We will use Task.async() method to create a task instance that will be completed asynchronously. It accepts either Callable or a Function1 that returns an instance of a Promise. When returned task is executed it will call provided callable or a function and will propagate returned promise completion to itself. It means that task will complete when the promise completes. The following example shows how async http client can be integrated with ParSeq, for full source see WrappedRequestBuilder:
public Task<Response> task(final String desc) {
return Task.async(desc, () -> {
final SettablePromise<Response> result = Promises.settable();
_delegate.execute(new AsyncCompletionHandler<Response>() {
@Override
public Response onCompleted(final Response response) throws Exception {
result.done(response);
return response;
}
@Override
public void onThrowable(Throwable t) {
result.fail(t);
}
});
return result;
});
}In example above we first create instance of SettablePromise. Next, we invoke http client's method and pass a completion handler which will propagate result to the promise.
Unfortunately not every library provides asynchronous API, e.g. JDBC libraries. We should never run blocking code directly inside ParSeq task because this can affect other asynchronous tasks.
In order to integrate blocking API with ParSeq we can use Task.blocking() method. It accepts two parameters:
-
Callablethat executes blocking code -
Executorinstance on which callable will be called
At runtime ParSeq will submit a blocking callable to provided executor and will complete the task with its result once it has completed.
Managing executors used for blocking calls it outside of ParSeq responsibilities and is use case specific but we recommend to always limit number of threads used by executor, limit size of work queue and specify Rejection Policy other than CallerRunsPolicy.
ParSeq has an interface for integrating CompletionStage/CompletableFuture from Java's concurrent library. This made integrating Java native async API with ParSeq easier. User can create a Task using a Callable returning a CompletionStage, this will set the value of task using value returned from the CompletionStage.
Task<String> task = Task.fromCompletionStage(() ->{
CompletableFuture<String> completableFuture
= CompletableFuture.supplyAsync(<your-code>);
return completableFuture;
});User can also convert a Task to a CompletionStage.
Task<String> task = Task.fromCompletionStage(() ->{
CompletableFuture<String> completableFuture
= CompletableFuture.supplyAsync(() -> result);
return completableFuture;
});
CompletionStage<String> future = task.toCompletionStage();