Serious bar sports, with seriously accurate XY coordinates.
A realtime solution to track dart targets with fastai and unets, using segmentations layers rather than classical regression.
![]()
📑 FlightVision_Unet_c950.ipynb.ipynb
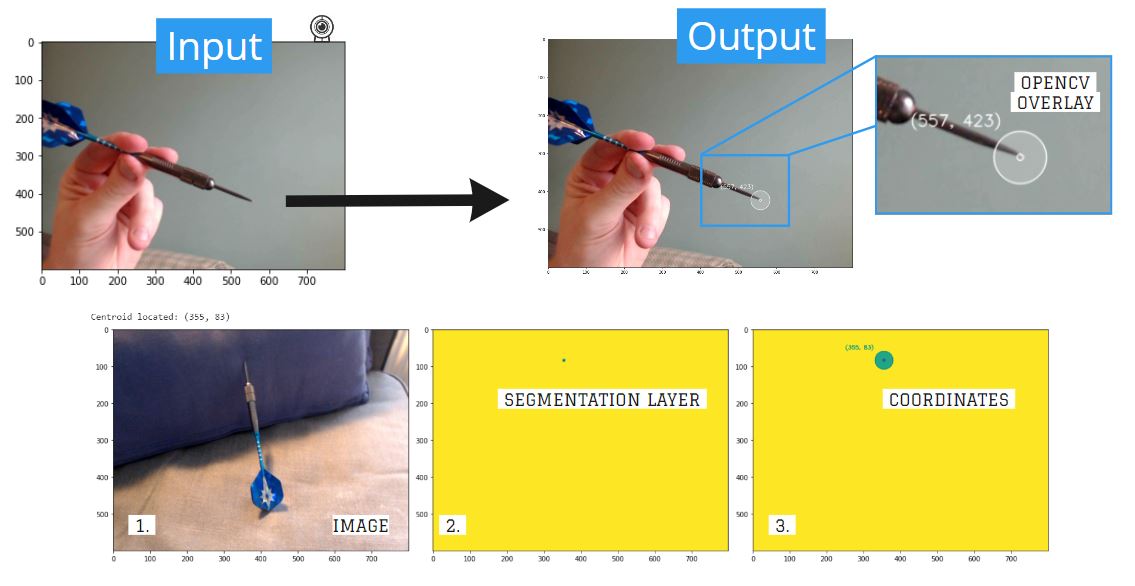
- Input frame passes through
unetmodel for segmentation mask inference. OpenCVblob detection identifies centroid location.OpenCVoverlay is applied to show the results
Flight Club is the name of a franchise in London that modernised the classic pub sport. It's success comes from the gamified automated scoring system. It has a 3D vision system comprised of live cameras, and also includes a well-polished interface which runs on a screen above the board. This opens the traditional game up for improved entertainment with the inclusion of minigames like team elimination, or a snakes-and-ladders adaption – where the target of your dart throw is how far forward you move on the board.
As of 2020 it has expanded into 3 locations in the UK and one in Chicago, USA.

Powered by a "highly sophisticated 3D vision system", the software brute-forces the solution using calibrated cameras positioned in a frame above the dart board.
A normal dart impact on the board triggers Flight Club Darts’ specially developed 3D fitting algorithms to identify, recognise and measure the precise position, pose and score of the dart to within a fraction of a millimetre. The software manipulates three virtual darts through millions of different orientations and angles until it finds what matches where the dart landed on the board. Using multiple cameras reduces obscuration effects.
A deep learning approach was attempted with a challenge to PhD students as part of a country-wide university competition around 2014. At that time no solution was found, and so more conventional computer vision techniques were used.
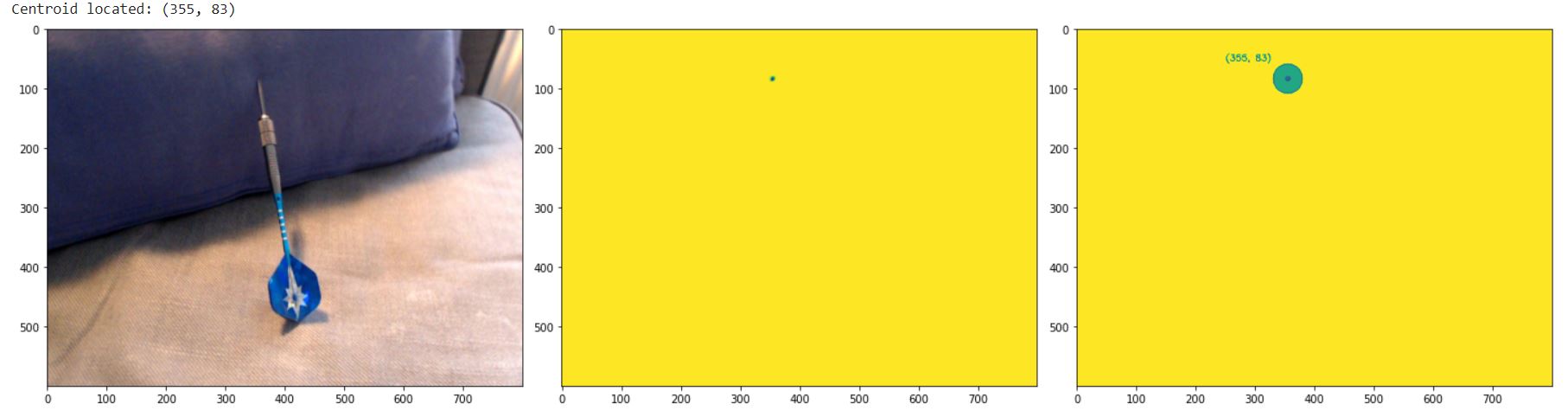
Take your own pictures, find the x,y coordinates of the dart point using a unet segmentation layer.


In lesson 3 of the fastai deep learning course, it explains how regression can be used within computer vision. Unlike classification tasks, which are used to make a categorical predicions (i.e. cat or dog), regression is used to find a continuous numerical values. This fits for our example, because we are trying to determine the x, y pixel locations of the dart point.

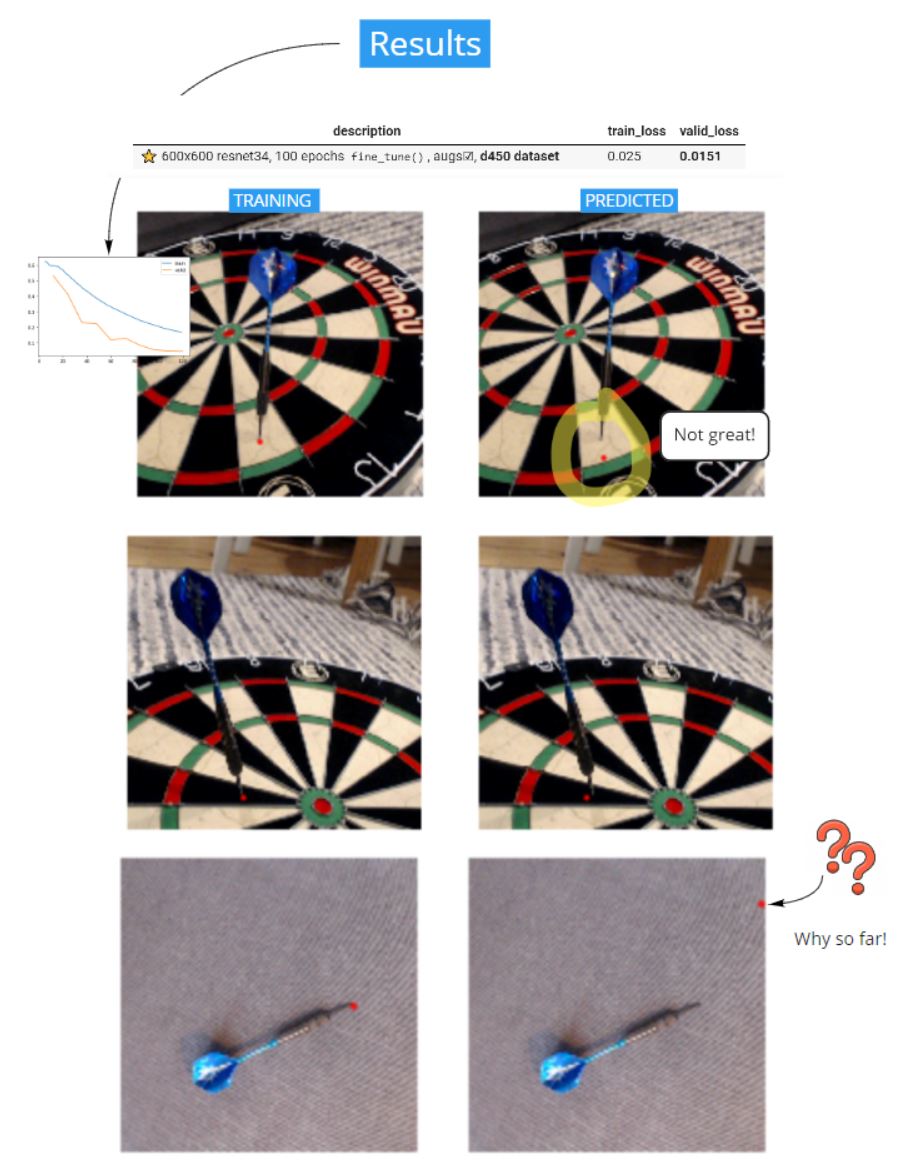
I spent a fair amount of time trying to get this regression based cnn_learner working – but it simply failed to converge during training. I was surprised that the model couldn't accurately predict the validation data given the simplicity of some of the samples. For example, the third image down was a picture of a dart, by itself, on a plain background – and it still couldn't make a reasonable prediction.
I knew something must be wrong either with the training process and architecture, or there was a limitation with the dataset I had created. In order to isolate the problem I generated a new dataset.
Using blender I simulated a simplified version of the problem. With this I could determine whether it was my training database that was wrong, or whether it was my ML/Dl approach that was wrong. I downloaded a 3d model from grabcad and created a python script to automate rendering.
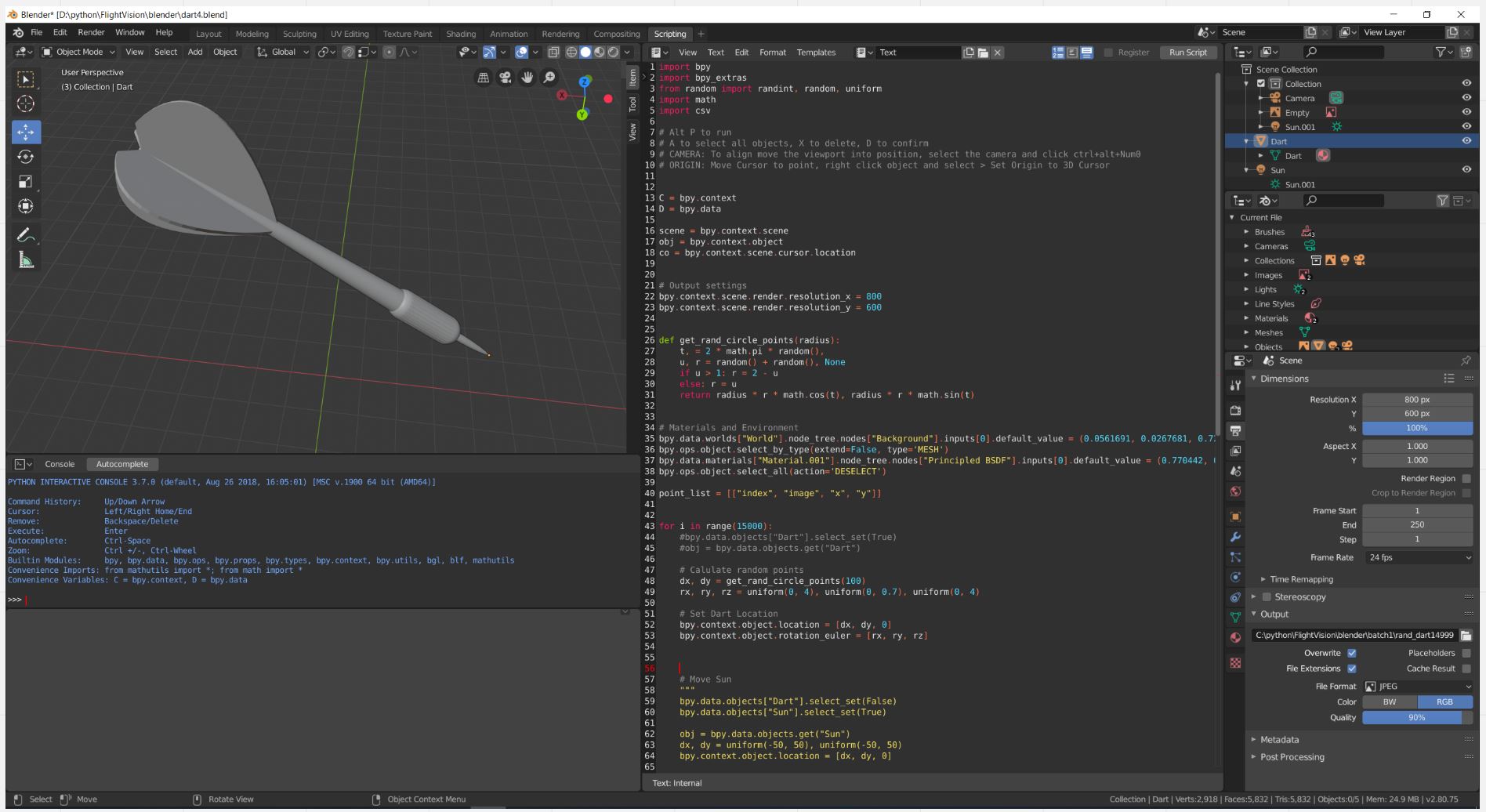
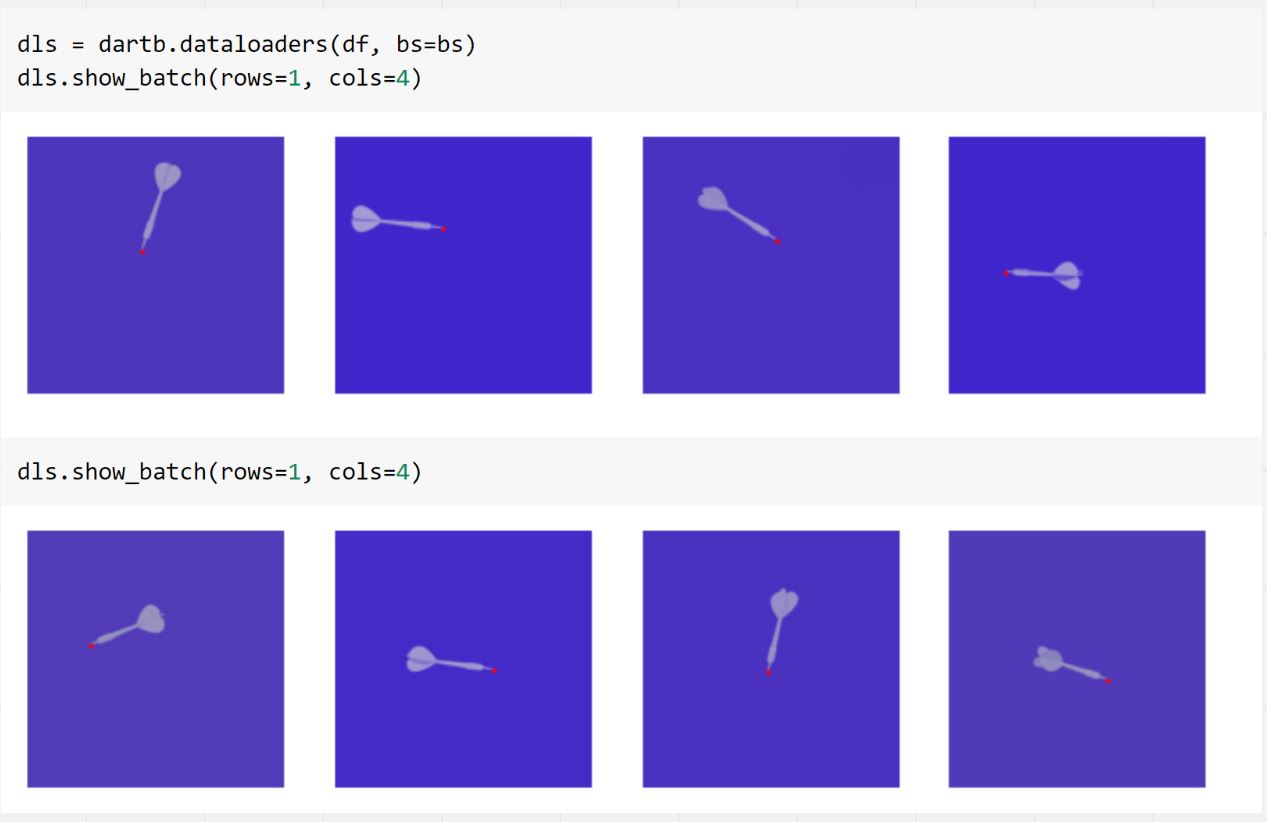
Blender allows for scripting with python. It is quick to learning the scripting API, because when you create an event with the UI the equivalent python command appears in the console, which you can then paste directly into a script. Then with python you can add a loop around it – specify the inputs/outputs, and the whole process is automated. My blender script randomised the rotation, zoom, light position, and centroid x, y location. With these in place I generated 15,000 renders in about half an hour.
What I found was that even with this much simplified computer vision problem, the cnn_learner with regression head still couldn't converge (and overfit) the training dataset. With that I was convinced the problem was with the architecture, so I moved on to try something else.
Unets are a segmentation method, where the output of the model is a per-pixel classification mask of the original image. These are commonly used in examples of self-driving car solutions online. My intuition here was that instead of using a multi-classification class of scenery objects (like tree, road, traffic_light etc), the target segmentation mask could simply be 0 or 1, where 0 is a pixel where the centroid isn't, and 1 is a pixel where the centroid is.
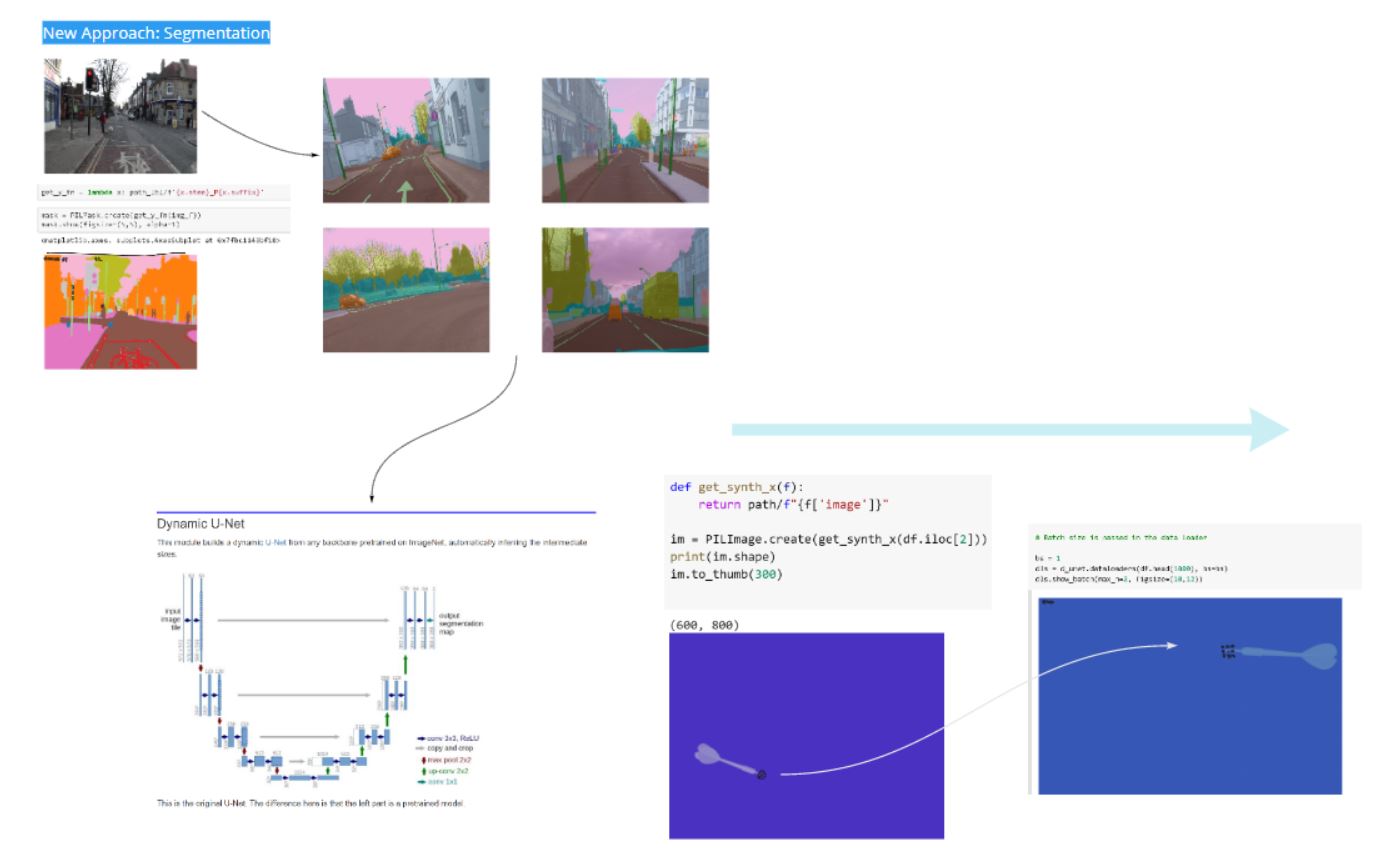
Upon observing that the novel architecture significantly enhanced accuracy by an order of magnitude, I fully committed to exploring this approach in my manually sourced data.

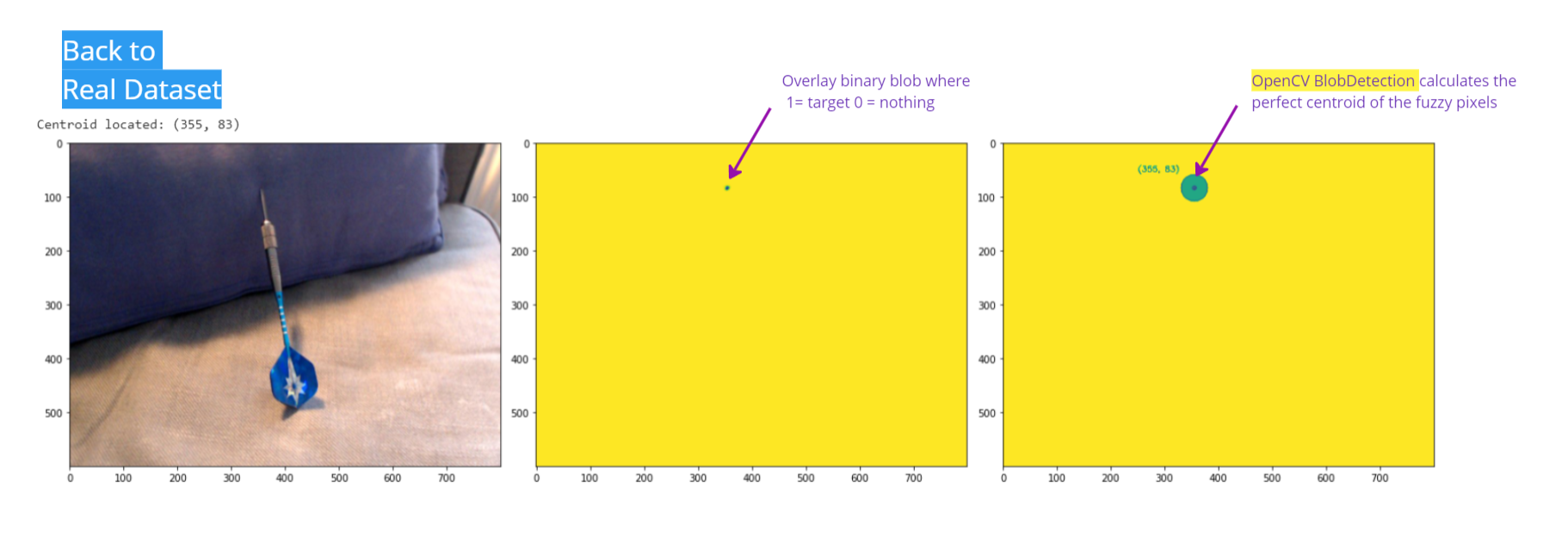
Incredibly this new technique was now giving me about 99% accuracy, and only failing on sample images which had heavy blurs across the photos, or obstructed views – which is a common problem of data quality. It's not something I'm interesting in solving immediately – when the other option is to ignore those frames and make a prediction when you see a high fidelity shot.
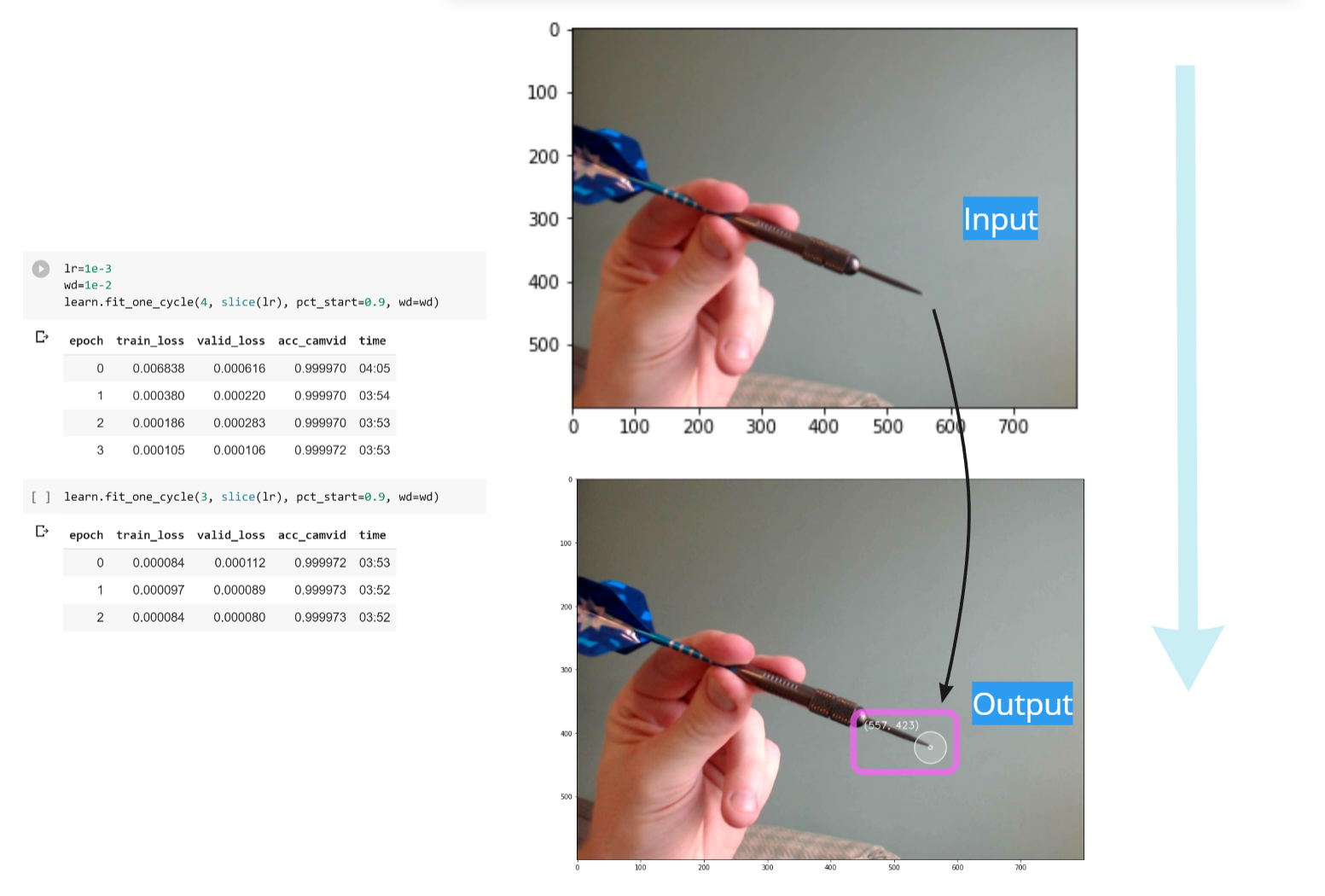
Like the video shown at the top of the article, the algorithm can accurately predict the point of a dart down to sub-pixel scales 🎯 It does have some failure points – like when the camera is moving to fast (causing blur) or I suppose when there is some major out-of-sample examples. But I took considerable joy in in this project branching out into different fields, to explore the limits of what was possible (synethic image generation with blender) – some of which were a dead end (regression analysis for a CV coordinate). I hope this project has been of interest to you.