![]()
AWS X-Ray recommends using AWS Distro for OpenTelemetry (ADOT) to instrument your application instead of this X-Ray SDK due to its wider range of features and instrumentations. See the AWS X-Ray docs on Working with Python for more help with choosing between ADOT and X-Ray SDK.
If you want additional features when tracing your Python applications, please open an issue on the OpenTelemetry Python Instrumentation repository.
The AWS X-Ray SDK for Python is compatible with Python 2.7, 3.4, 3.5, 3.6, 3.7, 3.8, and 3.9.
Install the SDK using the following command (the SDK's non-testing dependencies will be installed).
pip install aws-xray-sdk
To install the SDK's testing dependencies, use the following command.
pip install tox
Use the following community resources for getting help with the SDK. We use the GitHub issues for tracking bugs and feature requests.
- Ask a question in the AWS X-Ray Forum.
- Open a support ticket with AWS Support.
- If you think you may have found a bug, open an issue.
If you encounter a bug with the AWS X-Ray SDK for Python, we want to hear about it. Before opening a new issue, search the existing issues to see if others are also experiencing the issue. Include the version of the AWS X-Ray SDK for Python, Python language, and botocore/boto3 if applicable. In addition, include the repro case when appropriate.
The GitHub issues are intended for bug reports and feature requests. For help and questions about using the AWS SDK for Python, use the resources listed in the Getting Help section. Keeping the list of open issues lean helps us respond in a timely manner.
The developer guide provides in-depth guidance about using the AWS X-Ray service. The API Reference provides guidance for using the SDK and module-level documentation.
from aws_xray_sdk.core import xray_recorder
xray_recorder.configure(
sampling=False,
context_missing='LOG_ERROR',
plugins=('EC2Plugin', 'ECSPlugin', 'ElasticBeanstalkPlugin'),
daemon_address='127.0.0.1:3000',
dynamic_naming='*mysite.com*'
)Using context managers for implicit exceptions recording:
from aws_xray_sdk.core import xray_recorder
with xray_recorder.in_segment('segment_name') as segment:
# Add metadata or annotation here if necessary
segment.put_metadata('key', dict, 'namespace')
with xray_recorder.in_subsegment('subsegment_name') as subsegment:
subsegment.put_annotation('key', 'value')
# Do something here
with xray_recorder.in_subsegment('subsegment2') as subsegment:
subsegment.put_annotation('key2', 'value2')
# Do something else async versions of context managers:
from aws_xray_sdk.core import xray_recorder
async with xray_recorder.in_segment_async('segment_name') as segment:
# Add metadata or annotation here if necessary
segment.put_metadata('key', dict, 'namespace')
async with xray_recorder.in_subsegment_async('subsegment_name') as subsegment:
subsegment.put_annotation('key', 'value')
# Do something here
async with xray_recorder.in_subsegment_async('subsegment2') as subsegment:
subsegment.put_annotation('key2', 'value2')
# Do something else Default begin/end functions:
from aws_xray_sdk.core import xray_recorder
# Start a segment
segment = xray_recorder.begin_segment('segment_name')
# Start a subsegment
subsegment = xray_recorder.begin_subsegment('subsegment_name')
# Add metadata or annotation here if necessary
segment.put_metadata('key', dict, 'namespace')
subsegment.put_annotation('key', 'value')
xray_recorder.end_subsegment()
# Close the segment
xray_recorder.end_segment()As a decorator:
from aws_xray_sdk.core import xray_recorder
@xray_recorder.capture('subsegment_name')
def myfunc():
# Do something here
myfunc()or as a context manager:
from aws_xray_sdk.core import xray_recorder
with xray_recorder.capture('subsegment_name') as subsegment:
# Do something here
subsegment.put_annotation('mykey', val)
# Do something moreAsync capture as decorator:
from aws_xray_sdk.core import xray_recorder
@xray_recorder.capture_async('subsegment_name')
async def myfunc():
# Do something here
async def main():
await myfunc()or as context manager:
from aws_xray_sdk.core import xray_recorder
async with xray_recorder.capture_async('subsegment_name') as subsegment:
# Do something here
subsegment.put_annotation('mykey', val)
# Do something morefrom aws_xray_sdk.core import xray_recorder
# Start a segment if no segment exist
segment1 = xray_recorder.begin_segment('segment_name')
# This will add the key value pair to segment1 as it is active
xray_recorder.put_annotation('key', 'value')
# Start a subsegment so it becomes the active trace entity
subsegment1 = xray_recorder.begin_subsegment('subsegment_name')
# This will add the key value pair to subsegment1 as it is active
xray_recorder.put_metadata('key', 'value')
if xray_recorder.is_sampled():
# some expensitve annotations/metadata generation code here
val = compute_annotation_val()
metadata = compute_metadata_body()
xray_recorder.put_annotation('mykey', val)
xray_recorder.put_metadata('mykey', metadata)X-Ray Python SDK will by default generate no-op trace and entity id for unsampled requests and secure random trace and entity id for sampled requests. If customer wants to enable generating secure random trace and entity id for all the (sampled/unsampled) requests (this is applicable for trace id injection into logs use case) then they should set the AWS_XRAY_NOOP_ID environment variable as False.
Often times, it may be useful to be able to disable X-Ray for specific use cases, whether to stop X-Ray from sending traces at any moment, or to test code functionality that originally depended on X-Ray instrumented packages to begin segments prior to the code call. For example, if your application relied on an XRayMiddleware to instrument incoming web requests, and you have a method which begins subsegments based on the segment generated by that middleware, it would be useful to be able to disable X-Ray for your unit tests so that SegmentNotFound exceptions are not thrown when you need to test your method.
There are two ways to disable X-Ray, one is through environment variables, and the other is through the SDKConfig module.
Disabling through the environment variable:
Prior to running your application, make sure to have the environment variable AWS_XRAY_SDK_ENABLED set to false.
Disabling through the SDKConfig module:
from aws_xray_sdk import global_sdk_config
global_sdk_config.set_sdk_enabled(False)
Important Notes:
-
Environment Variables always take precedence over the SDKConfig module when disabling/enabling. If your environment variable is set to
falsewhile your code callsglobal_sdk_config.set_sdk_enabled(True), X-Ray will still be disabled. -
If you need to re-enable X-Ray again during runtime and acknowledge disabling/enabling through the SDKConfig module, you may run the following in your application:
import os
from aws_xray_sdk import global_sdk_config
del os.environ['AWS_XRAY_SDK_ENABLED']
global_sdk_config.set_sdk_enabled(True)
from aws_xray_sdk.core import xray_recorder
def lambda_handler(event, context):
# ... some code
subsegment = xray_recorder.begin_subsegment('subsegment_name')
# Code to record
# Add metadata or annotation here, if necessary
subsegment.put_metadata('key', dict, 'namespace')
subsegment.put_annotation('key', 'value')
xray_recorder.end_subsegment()
# ... some other codeimport concurrent.futures
import requests
from aws_xray_sdk.core import xray_recorder
from aws_xray_sdk.core import patch
patch(('requests',))
URLS = ['http://www.amazon.com/',
'http://aws.amazon.com/',
'http://example.com/',
'http://www.bilibili.com/',
'http://invalid-domain.com/']
def load_url(url, trace_entity):
# Set the parent X-Ray entity for the worker thread.
xray_recorder.set_trace_entity(trace_entity)
# Subsegment captured from the following HTTP GET will be
# a child of parent entity passed from the main thread.
resp = requests.get(url)
# prevent thread pollution
xray_recorder.clear_trace_entities()
return resp
# Get the current active segment or subsegment from the main thread.
current_entity = xray_recorder.get_trace_entity()
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# Pass the active entity from main thread to worker threads.
future_to_url = {executor.submit(load_url, url, current_entity): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception:
passBy default, if no other value is provided to .configure(), SQL trace streaming is enabled
for all the supported DB engines. Those currently are:
- Any engine attached to the Django ORM.
- Any engine attached to SQLAlchemy.
The behaviour can be toggled by sending the appropriate stream_sql value, for example:
from aws_xray_sdk.core import xray_recorder
xray_recorder.configure(service='fallback_name', stream_sql=True)from aws_xray_sdk.core import patch
libs_to_patch = ('boto3', 'mysql', 'requests')
patch(libs_to_patch)Full modules in the local codebase can be recursively patched by providing the module references to the patch function.
from aws_xray_sdk.core import patch
libs_to_patch = ('boto3', 'requests', 'local.module.ref', 'other_module')
patch(libs_to_patch)An xray_recorder.capture() decorator will be applied to all functions and class methods in the
given module and all the modules inside them recursively. Some files/modules can be excluded by
providing to the patch function a regex that matches them.
from aws_xray_sdk.core import patch
libs_to_patch = ('boto3', 'requests', 'local.module.ref', 'other_module')
ignore = ('local.module.ref.some_file', 'other_module.some_module\.*')
patch(libs_to_patch, ignore_module_patterns=ignore)In django settings.py, use the following.
INSTALLED_APPS = [
# ... other apps
'aws_xray_sdk.ext.django',
]
MIDDLEWARE = [
'aws_xray_sdk.ext.django.middleware.XRayMiddleware',
# ... other middlewares
]You can configure the X-Ray recorder in a Django app under the ‘XRAY_RECORDER’ namespace. For a minimal configuration, the 'AWS_XRAY_TRACING_NAME' is required unless it is specified in an environment variable.
XRAY_RECORDER = {
'AWS_XRAY_TRACING_NAME': 'My application', # Required - the segment name for segments generated from incoming requests
}
For more information about configuring Django with X-Ray read more about it in the API reference
If Django's ORM is patched - either using the AUTO_INSTRUMENT = True in your settings file
or explicitly calling patch_db() - the SQL query trace streaming can then be enabled or
disabled updating the STREAM_SQL variable in your settings file. It is enabled by default.
The automatic module patching can also be configured through Django settings.
XRAY_RECORDER = {
'PATCH_MODULES': [
'boto3',
'requests',
'local.module.ref',
'other_module',
],
'IGNORE_MODULE_PATTERNS': [
'local.module.ref.some_file',
'other_module.some_module\.*',
],
...
}If AUTO_PATCH_PARENT_SEGMENT_NAME is also specified, then a segment parent will be created
with the supplied name, wrapping the automatic patching so that it captures any dangling
subsegments created on the import patching.
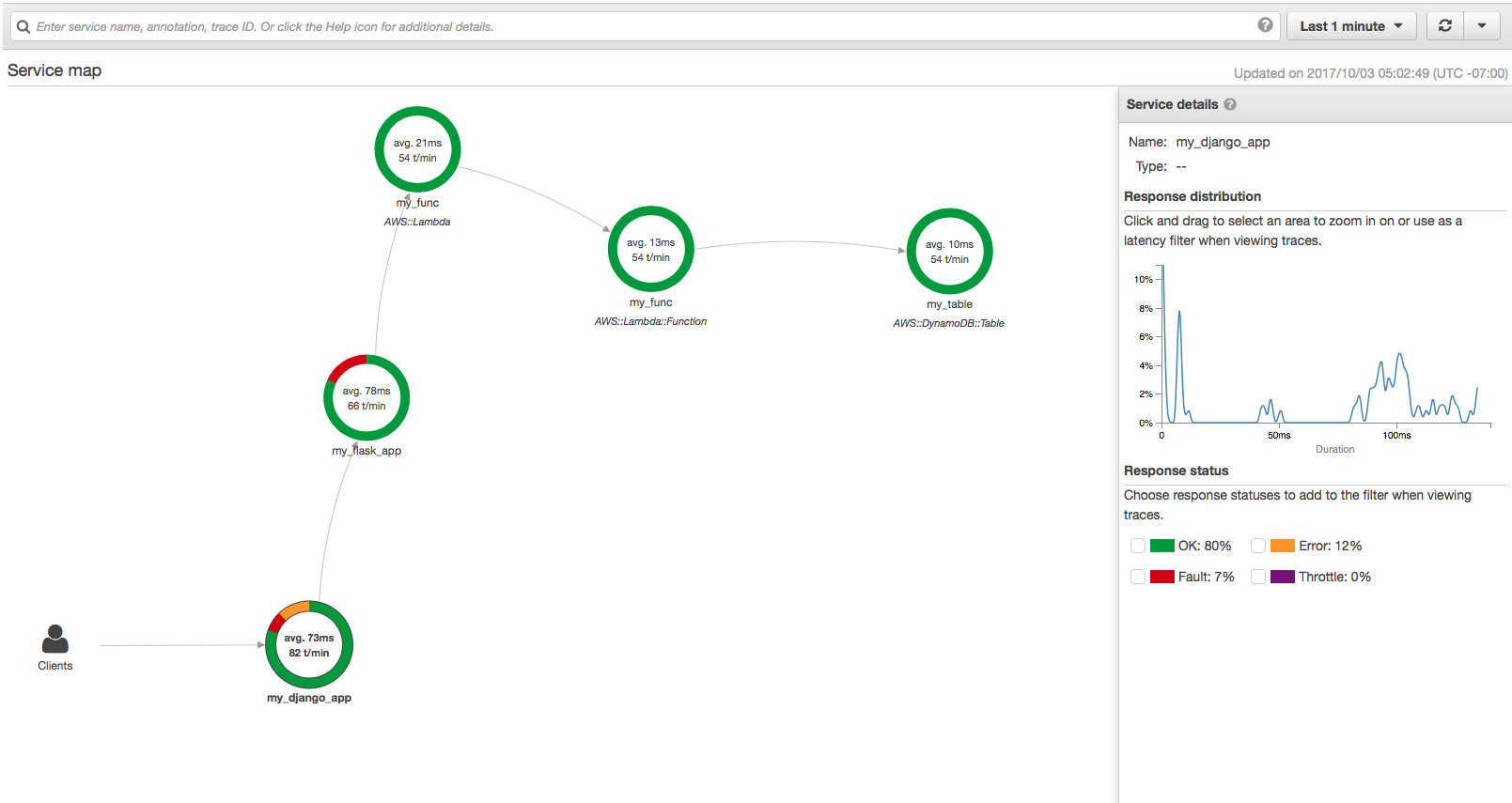
X-Ray can't search on http annotations in subsegments. To enable searching the middleware adds the http values as annotations This allows searching in the X-Ray console like so
This is configurable in settings with URLS_AS_ANNOTATION that has 3 valid values
LAMBDA - the default, which uses URLs as annotations by default if running in a lambda context
ALL - do this for every request (useful if running in a mixed lambda/other deployment)
NONE - don't do this for any (avoiding hitting the 50 annotation limit)
annotation.url BEGINSWITH "https://your.url.com/here"
from aws_xray_sdk.core import xray_recorder
from aws_xray_sdk.ext.flask.middleware import XRayMiddleware
app = Flask(__name__)
xray_recorder.configure(service='fallback_name', dynamic_naming='*mysite.com*')
XRayMiddleware(app, xray_recorder)from aws_xray_sdk.core import xray_recorder
from aws_xray_sdk.ext.bottle.middleware import XRayMiddleware
app = Bottle()
xray_recorder.configure(service='fallback_name', dynamic_naming='*mysite.com*')
app.install(XRayMiddleware(xray_recorder))Serverless is an application model that enables you to shift more of your operational responsibilities to AWS. As a result, you can focus only on your applications and services, instead of the infrastructure management tasks such as server provisioning, patching, operating system maintenance, and capacity provisioning. With serverless, you can deploy your web application to AWS Lambda and have customers interact with it through a Lambda-invoking endpoint, such as Amazon API Gateway.
X-Ray supports the Serverless model out of the box and requires no extra configuration. The middlewares in Lambda generate Subsegments instead of Segments when an endpoint is reached. This is because Segments cannot be generated inside the Lambda function, but it is generated automatically by the Lambda container. Therefore, when using the middlewares with this model, it is important to make sure that your methods only generate Subsegments.
The following guide shows an example of setting up a Serverless application that utilizes API Gateway and Lambda:
Instrumenting Web Frameworks in a Serverless Environment
Adding aiohttp middleware. Support aiohttp >= 2.3.
from aiohttp import web
from aws_xray_sdk.ext.aiohttp.middleware import middleware
from aws_xray_sdk.core import xray_recorder
from aws_xray_sdk.core.async_context import AsyncContext
xray_recorder.configure(service='fallback_name', context=AsyncContext())
app = web.Application(middlewares=[middleware])
app.router.add_get("/", handler)
web.run_app(app)Tracing aiohttp client. Support aiohttp >=3.
from aws_xray_sdk.ext.aiohttp.client import aws_xray_trace_config
async def foo():
trace_config = aws_xray_trace_config()
async with ClientSession(loop=loop, trace_configs=[trace_config]) as session:
async with session.get(url) as resp
await resp.read()The SQLAlchemy integration requires you to override the Session and Query Classes for SQL Alchemy
SQLAlchemy integration uses subsegments so you need to have a segment started before you make a query.
from aws_xray_sdk.core import xray_recorder
from aws_xray_sdk.ext.sqlalchemy.query import XRaySessionMaker
xray_recorder.begin_segment('SQLAlchemyTest')
Session = XRaySessionMaker(bind=engine)
session = Session()
xray_recorder.end_segment()
app = Flask(__name__)
xray_recorder.configure(service='fallback_name', dynamic_naming='*mysite.com*')
XRayMiddleware(app, xray_recorder)from aws_xray_sdk.core import xray_recorder
from aws_xray_sdk.ext.flask.middleware import XRayMiddleware
from aws_xray_sdk.ext.flask_sqlalchemy.query import XRayFlaskSqlAlchemy
app = Flask(__name__)
app.config["SQLALCHEMY_DATABASE_URI"] = "sqlite:///:memory:"
XRayMiddleware(app, xray_recorder)
db = XRayFlaskSqlAlchemy(app)If you want to ignore certain httplib requests you can do so based on the hostname or URL that is being requsted. The hostname is matched using the Python fnmatch library which does Unix glob style matching.
from aws_xray_sdk.ext.httplib import add_ignored as xray_add_ignored
# ignore requests to test.myapp.com
xray_add_ignored(hostname='test.myapp.com')
# ignore requests to a subdomain of myapp.com with a glob pattern
xray_add_ignored(hostname='*.myapp.com')
# ignore requests to /test-url and /other-test-url
xray_add_ignored(urls=['/test-path', '/other-test-path'])
# ignore requests to myapp.com for /test-url
xray_add_ignored(hostname='myapp.com', urls=['/test-url'])If you use a subclass of httplib to make your requests, you can also filter on the class name that initiates the request. This must use the complete package name to do the match.
from aws_xray_sdk.ext.httplib import add_ignored as xray_add_ignored
# ignore all requests made by botocore
xray_add_ignored(subclass='botocore.awsrequest.AWSHTTPConnection')The AWS X-Ray SDK for Python is licensed under the Apache 2.0 License. See LICENSE and NOTICE.txt for more information.