This uploads artifacts from your workflow allowing you to share data between jobs and store data once a workflow is complete.
See also download-artifact.
- Easier upload
- Specify a wildcard pattern
- Specify an individual file
- Specify a directory (previously you were limited to only this option)
- Multi path upload
- Use a combination of individual files, wildcards or directories
- Support for excluding certain files
- Upload an artifact without providing a name
- Fix for artifact uploads sometimes not working with containers
- Proxy support out of the box
- Port entire action to typescript from a runner plugin so it is easier to collaborate and accept contributions
Refer here for the previous version
See action.yml
steps:
- uses: actions/checkout@v2
- run: mkdir -p path/to/artifact
- run: echo hello > path/to/artifact/world.txt
- uses: actions/upload-artifact@v2
with:
name: my-artifact
path: path/to/artifact/world.txt- uses: actions/upload-artifact@v2
with:
name: my-artifact
path: path/to/artifact/ # or path/to/artifact- uses: actions/upload-artifact@v2
with:
name: my-artifact
path: path/**/[abc]rtifac?/*- uses: actions/upload-artifact@v2
with:
name: my-artifact
path: |
path/output/bin/
path/output/test-results
!path/**/*.tmpFor supported wildcards along with behavior and documentation, see @actions/glob which is used internally to search for files.
If a wildcard pattern is used, the path hierarchy will be preserved after the first wildcard pattern.
path/to/*/directory/foo?.txt =>
∟ path/to/some/directory/foo1.txt
∟ path/to/some/directory/foo2.txt
∟ path/to/other/directory/foo1.txt
would be flattened and uploaded as =>
∟ some/directory/foo1.txt
∟ some/directory/foo2.txt
∟ other/directory/foo1.txt
If multiple paths are provided as input, the least common ancestor of all the search paths will be used as the root directory of the artifact. Exclude paths do not effect the directory structure.
Relative and absolute file paths are both allowed. Relative paths are rooted against the current working directory. Paths that begin with a wildcard character should be quoted to avoid being interpreted as YAML aliases.
The @actions/artifact package is used internally to handle most of the logic around uploading an artifact. There is extra documentation around upload limitations and behavior in the toolkit repo that is worth checking out.
If a path (or paths), result in no files being found for the artifact, the action will succeed but print out a warning. In certain scenarios it may be desirable to fail the action or suppress the warning. The if-no-files-found option allows you to customize the behavior of the action if no files are found.
- uses: actions/upload-artifact@v2
with:
name: my-artifact
path: path/to/artifact/
if-no-files-found: error # 'warn' or 'ignore' are also available, defaults to `warn` To upload artifacts only when the previous step of a job failed, use if: failure():
- uses: actions/upload-artifact@v2
if: failure()
with:
name: my-artifact
path: path/to/artifact/You can upload an artifact without specifying a name
- uses: actions/upload-artifact@v2
with:
path: path/to/artifact/world.txtIf not provided, artifact will be used as the default name which will manifest itself in the UI after upload.
Each artifact behaves as a file share. Uploading to the same artifact multiple times in the same workflow can overwrite and append already uploaded files
- run: echo hi > world.txt
- uses: actions/upload-artifact@v2
with:
path: world.txt
- run: echo howdy > extra-file.txt
- uses: actions/upload-artifact@v2
with:
path: extra-file.txt
- run: echo hello > world.txt
- uses: actions/upload-artifact@v2
with:
path: world.txtWith the following example, the available artifact (named artifact which is the default if no name is provided) would contain both world.txt (hello) and extra-file.txt (howdy).
Warning: Be careful when uploading to the same artifact via multiple jobs as artifacts may become corrupted
strategy:
matrix:
node-version: [8.x, 10.x, 12.x, 13.x]
steps:
- name: 'Create a file'
run: echo ${{ matrix.node-version }} > my_file.txt
- name: 'Accidently upload to the same artifact via multiple jobs'
uses: 'actions/upload-artifact@v2'
with:
name: my-artifact
path: ${{ github.workspace }}In the above example, four jobs will upload four different files to the same artifact but there will only be one file available when my-artifact is downloaded. Each job overwrites what was previously uploaded. To ensure that jobs don't overwrite existing artifacts, use a different name per job.
uses: 'actions/upload-artifact@v2'
with:
name: my-artifact ${{ matrix.node-version }}
path: ${{ github.workspace }}You can use ~ in the path input as a substitute for $HOME. Basic tilde expansion is supported.
- run: |
mkdir -p ~/new/artifact
echo hello > ~/new/artifact/world.txt
- uses: actions/upload-artifact@v2
with:
name: 'Artifacts-V2'
path: '~/new/**/*'Environment variables along with context expressions can also be used for input. For documentation see context and expression syntax.
env:
name: my-artifact
steps:
- run: |
mkdir -p ${{ github.workspace }}/artifact
echo hello > ${{ github.workspace }}/artifact/world.txt
- uses: actions/upload-artifact@v2
with:
name: ${{ env.name }}-name
path: ${{ github.workspace }}/artifact/**/*Artifacts are retained for 90 days by default. You can specify a shorter retention period using the retention-days input:
- name: 'Create a file'
run: echo "I won't live long" > my_file.txt
- name: 'Upload Artifact'
uses: actions/upload-artifact@v2
with:
name: my-artifact
path: my_file.txt
retention-days: 5
The retention period must be between 1 and 90 inclusive. For more information see artifact and log retention policies.
At the bottom of the workflow summary page, there is a dedicated section for artifacts. Here's a screenshot of something you might see:
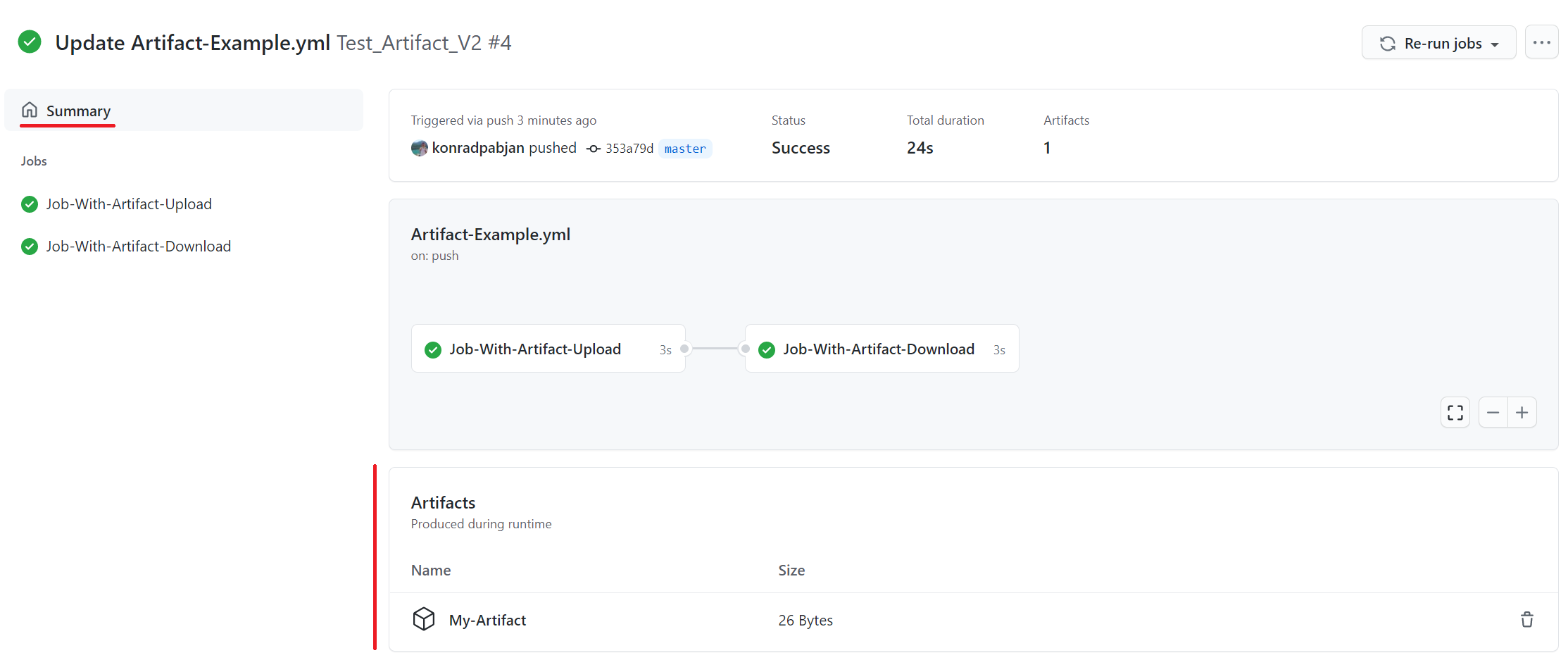
There is a trashcan icon that can be used to delete the artifact. This icon will only appear for users who have write permissions to the repository.
The size of the artifact is denoted in bytes. The displayed artifact size denotes the raw uploaded artifact size (the sum of all the individual files uploaded during the workflow run for the artifact), not the compressed size. When you click to download an artifact from the summary page, a compressed zip is created with all the contents of the artifact and the size of the zip that you download may differ significantly from the displayed size. Billing is based on the raw uploaded size and not the size of the zip.
During a workflow run, files are uploaded and downloaded individually using the upload-artifact and download-artifact actions. However, when a workflow run finishes and an artifact is downloaded from either the UI or through the download api, a zip is dynamically created with all the file contents that were uploaded. There is currently no way to download artifacts after a workflow run finishes in a format other than a zip or to download artifact contents individually. One of the consequences of this limitation is that if a zip is uploaded during a workflow run and then downloaded from the UI, there will be a double zip created.
❗ File permissions are not maintained during artifact upload ❗ For example, if you make a file executable using chmod and then upload that file, post-download the file is no longer guaranteed to be set as an executable.
❗ File uploads are case insensitive ❗ If you upload A.txt and a.txt with the same root path, only a single file will be saved and available during download.
If file permissions and case sensitivity are required, you can tar all of your files together before artifact upload. Post download, the tar file will maintain file permissions and case sensitivity.
- name: 'Tar files'
run: tar -cvf my_files.tar /path/to/my/directory
- name: 'Upload Artifact'
uses: actions/upload-artifact@v2
with:
name: my-artifact
path: my_files.tar A very minute subset of users who upload a very very large amount of artifacts in a short period of time may see their uploads throttled or fail because of Request was blocked due to exceeding usage of resource 'DBCPU' in namespace or Unable to copy file to server StatusCode=TooManyRequests.
To reduce the chance of this happening, you can reduce the number of HTTP calls made during artifact upload by zipping or archiving the contents of your artifact before an upload starts. As an example, imagine an artifact with 1000 files (each 10 Kb in size). Without any modification, there would be around 1000 HTTP calls made to upload the artifact. If you zip or archive the artifact beforehand, the number of HTTP calls can be dropped to single digit territory. Measures like this will significantly speed up your upload and prevent uploads from being throttled or in some cases fail.
See persisting workflow data using artifacts for additional examples and tips.
See extra documentation for the @actions/artifact package that is used internally regarding certain behaviors and limitations.
The scripts and documentation in this project are released under the MIT License