Sử dụng mô hình ngôn ngữ để trả lời các câu hỏi ở mức độ bài thi toán SAT.
Tinh chỉnh mô hình flan-t5 để trả lời cho các câu hỏi trắc nghiệm và sử dụng gpt-3.5-turbo-instruct cho các câu hỏi trả lời đáp án.
Flan-T5 là một mô hình được tinh chỉnh từ T5 với thêm hơn 1000 tác vụ mới và nhiều ngôn ngữ mới, mô hình được tinh chỉnh theo nhiều kiểu như được mô tả trong hình dưới.
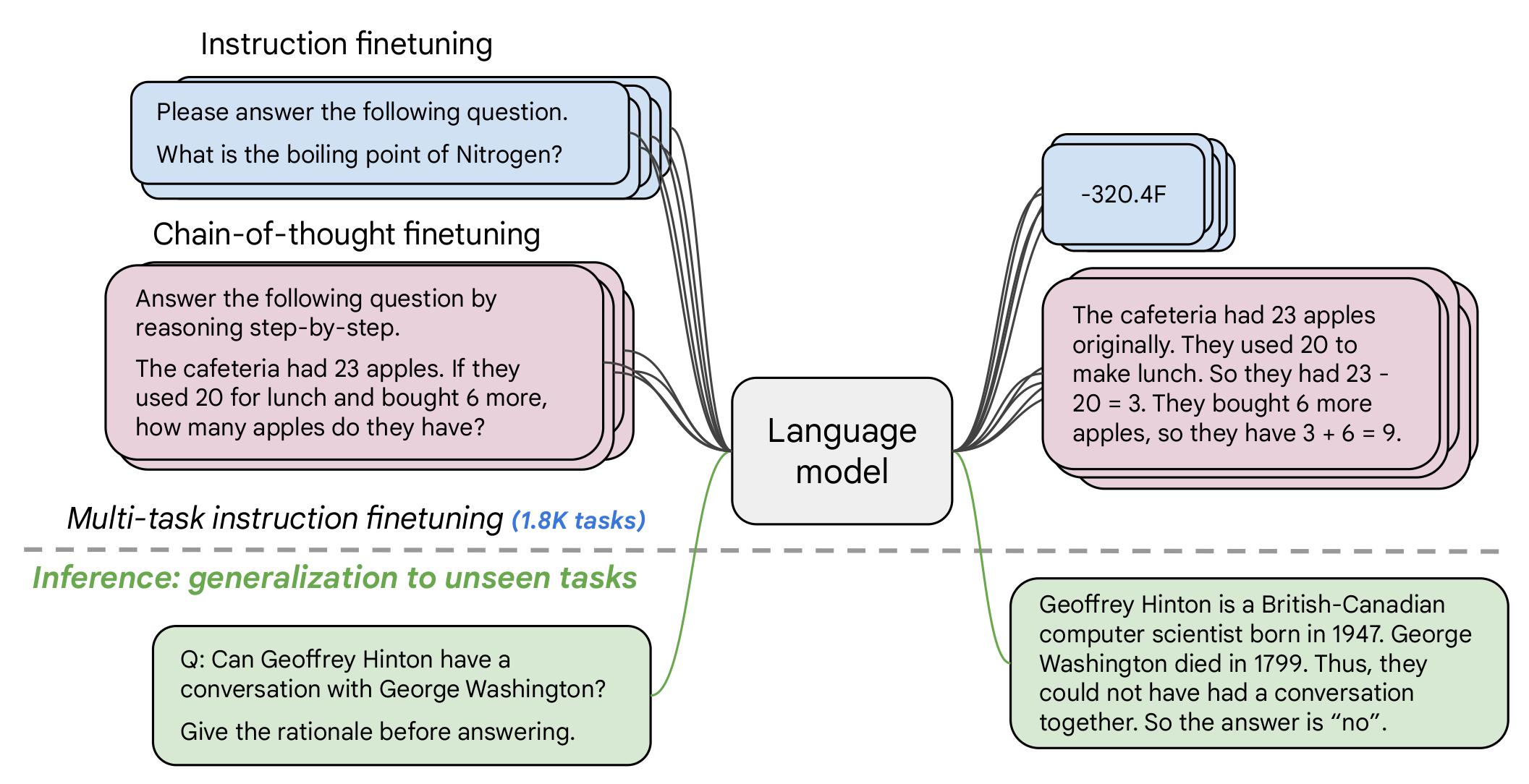
Ở đây, mô hình flan-t5 được tinh chỉnh thêm với dữ liệu mới trong thư mục data/train/ để tăng độ chính xác trong việc trả lời các câu hỏi trắc nghiệm toán học. Ưu điểm của mô hình này là tốc độ trả kết quả nhanh với độ chính xác khi kiểm tra với dữ liệu trong data/test/.
- Model:
flan-t5 - Evaluate trên tổng số 7287 câu hỏi trắc nghiệm
Kết quả của mô hình dựa trên 5000 câu đầu của tập train:
| Index | Total Question | Correct Answers | Percentage Correct |
|---|---|---|---|
gain |
886 | 469 | 52.93 |
general |
2243 | 940 | 41.91 |
geometry |
342 | 156 | 45.61 |
other |
286 | 121 | 42.31 |
physics |
1162 | 582 | 50.09 |
probability |
81 | 27 | 33.33 |
Kết quả của mô hình trên tập public test (7287 câu hỏi trắc nghiệm)
| Paramaters | Epochs | Accuracy | |
|---|---|---|---|
flan-t5-small |
77M | 0 | 19.32 |
flan-t5-base |
248M | 0 | 26.86 |
flan-t5-large |
783M | 0 | 27.67 |
flan-t5-base-mathqa_v1 |
248M | 3 | 30.57 |
flan-t5-base-mathqa_v2 |
248M | 5 | 34.07 |
flan-t5-base-mathqa_v3 |
248M | 8 | 39.60 |
Mô hình được tinh chỉnh có trên huggingface: NghiemAbe/flan-t5-base-mathqa_v3.
Một số mô hình ngôn ngữ như ToRA, LLeMMA, WizardMath,... được đánh giá là có khả năng trả lời các câu hỏi toán học với độ chính xác cao, các mô hình thường mạnh ở những đặc điểm riêng ví dụ như:
-
ToRA có khả năng sinh ra một chuỗi quá trình bao gồm lý luận, mã thực thi python, kết quả đầu ra để đưa ra câu trả lời cuối cùng cho bài toán.
-
LLeMMA có điểm mạnh trong các bài toán chứng minh.
Tuy nhiên để có độ chính xác cao cần yêu cầu mô hình cỡ lớn với rất nhiều tham số, mô hình dưới 7 tỷ tham số thường khó đạt được độ chính xác như vậy và bởi tài nguyên hạn chế của máy tính thông thường nên thời gian sinh lâu.
Các mô hình dưới 7 tỷ tham số khi chạy với GPU T4 của Google Colab thường chỉ mang lại độ chính xác dưới 10% cho việc trả lời đúng kết quả chỉ trong 1 lần sinh. Do đó, giải pháp là sử dụng API của một mô hình lớn như GPT 3.5, cụ thể ở đây sử dụng mô hình gpt-3.5-turbo-instruct của OpenAI và kỹ thuật prompt để sinh kết quả chỉ trong 1 request với độ chính xác khi kiểm tra với dữ liệu trong data/test/ là 24.8%.
| Model | Mean time | Accuracy |
|---|---|---|
flan-t5-small-mathqa-v8 |
0.0569 | 209/604 |
flan-t5-large |
0.1452 | 165/604 |
API gpt-3.5-turbo-instruct |
0.3129 | 166/604 |
flan-t5-base-mathqa-v3 |
0.071 | 235/604 |