Extract data from binary .nif file using the nif.xml file description
In this document, we will present how to read data from NIF files. It is assumed you have basic knowledge of low-level programming, i.e. what a string is, what a byte is, what a condition is, and what a variable is.
We recommend to equip yourself with a hex editor first. HxD tool is a free Windows tool to read such files. You can also consider 010, which has a 30-day trial but adds several options such as templates (to define and parse a file's layout) or scripts (to automate tasks).
If you use 010, you can find templates made for NIF files in the NifTools ecosystem.
All the examples in this document will be based on the file "OutfitCaitGO", from Fallout 4.
The NIF header contains all the necessary information to read the file. It mostly contains the file version, the list of the actual data to read and sometimes--it depends on the version--the strings used in the file.
To read the header, go to the nif.xml file and search for the "compound" object named Header.
<compound name="Header">
The NIF file header.
<field name="Header String" type="HeaderString">[...]</field>
<field name="Copyright" type="LineString" arr1="3" ver2="3.1" />
<field name="Version" type="FileVersion" default="0x04000002" ver1="3.3.0.13">[...]</field>
[...]
</compound>Then, open the binary file and begin to read the described XML object.
Here is how it works :

A compound (it's also true for a niobject) describes the contents of the block in order.
Each content is called a member of the compound or a member of the niobject.
For this specific block, you'll first want to read the "HeaderString" member.
To find what an "HeaderString" is, go to the nif.xml file again and find the basic xml node with a "name" attribute of "HeaderString".
<basic name="HeaderString" integral="false">
A variable length string that ends with a newline character (0x0A). The string starts as follows depending on the version:
Version <= 10.0.1.0: 'NetImmerse File Format'
Version >= 10.1.0.0: 'Gamebryo File Format'
</basic>Then, read the block content to know what the member actually is.
Here, it's a series of characters ended by the 0A value.
Finally, read all the bytes from the file until you read the value 0A. All the bytes before are the actual chars you have to gather.
You should then have a resulting string like this : Gamebryo File Format, Version 20.2.0.7
Save your current position, as it is supposed to be your current position in the file, and continue to read from there.
In compounds or objects, some members have an associated attribute called ver1 or ver2. These are version checking conditions.
Basically, the version condition is verified when ver1 < version < ver2.
If either ver1 (resp. ver2) isn't specified, then the lower (resp. higher) bound isn't checked.
Some examples:
-
version= 10.0.0.3 ;ver1= 3.0.0.1 ;ver2= 10.0.0.2
The condition isn't checked -
version= 20.0.0.7 ;ver1= 3.0.0.1
The condition is checked -
version= 20.0.0.7 ;ver2= 3.1
The condition isn't checked
Let's go back to our example header. We had the HeaderString Gamebryo File Format, Version 20.2.0.7, and we're asked to read the next member:
<compound name="Header">
The NIF file header.
<field name="Header String" type="HeaderString">[...]</field>
<field name="Copyright" type="LineString" arr1="3" ver2="3.1" />
<field name="Version" type="FileVersion" default="0x04000002" ver1="3.3.0.13">[...]</field>
[...]
</compound>The next member is then Copyright. However, it has a ver2 attribute of 3.1.
We already extracted version from the HeaderString, and the version value is 20.2.0.7.
Because 20.2.0.7 > 3.1, the version condition isn't met.
Therefore, we don't read the Copyright member.
However, we will read the next member, <field name="Version" type="FileVersion" default="0x04000002" ver1="3.3.0.13">[...]</field>, as its version check (ver1 < version) is met by our current version.
The idea of an array is that the array size is either static (as seen in Copyright) or dynamic.
A dynamic size will be defined by either a memberor an ARG.
We will see ARGs later, but for array lengths it works the same way a member size would work.
An array is defined by the arr1 attribute. In Copyright, arr1 was associated to 3. That meant that the intended value was three consecutive instances of the Copyright type, LineString.
Let's go further into the header :
<compound name="Header">
[...]
<field name="Num Block Types" type="ushort" ver1="10.0.1.0">[...]</field>
<field name="Block Types" type="SizedString" arr1="Num Block Types" ver1="10.0.1.0">[...]</field>
<field name="Block Type Index" type="BlockTypeIndex" arr1="Num Blocks" ver1="10.0.1.0">[...]</field>
<field name="Block Size" type="uint" arr1="Num Blocks" ver1="20.2.0.7">[...]</field>
[...]
</compound>Here, we can see that the Num Block Types value is used for arr1 for all the next members.
What that basically means is that the value acquired from the file when reading Num Block Types is actually the size of the array.
To go back to our example, we have the following data :
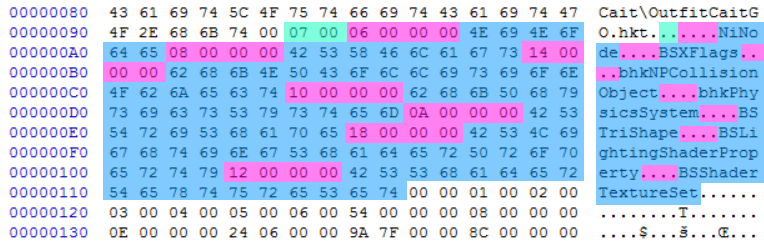
The first value to read is a ushort that describes the length.
As seen at the beginning of the file, a ushort is an 'unsigned 16-bits integer', which means it is a 2-byte object.
Here, the ushort Num Block Types is 7. We will read 7 array components.
Each array component is of the following format :
<compound name="SizedString">
A string of given length.
<field name="Length" type="uint">The string length.</field>
<field name="Value" type="char" arr1="Length">The string itself.</field>
</compound>The structure of an array 'component' is therefore a Length value, which according to the beginning of the file is a 32-bits (4-bytes) number.
Then, there is Length consecutive char values, each char being an 8-bits (1-byte) value. A char can also be seen as a letter.
We can then acquire the data : we will do the operation "read a SizedString" 7 times in a row, each operation being "read the length" then "read the chars".
Some members, in addition to the ver1, ver2 and arr1 attributes, have a cond attribute.
The cond attribute describes a condition for the member to exist, much like ver1 and ver2 do.
It has the ability to be custom described and much like arr1 attributes it can take the value of another member as a variable.
The ARG value is in reality a value passed from a compound or object to a member.
It isn't used in the header, but later in the file you might find the "arg" attribute.
The value you pass as the arg attribute is used in the underlying member as an ARG variable. It can therefore be used as an array size or in a cond.
The only thing always read in the nif.xml document is the header. The idea is that all other data in the file is first described in the header itself.
In the header, we already saw there is a Block Types array:
<compound name="Header">
[...]
<field name="Num Block Types" type="ushort" ver1="10.0.1.0">[...]</field>
<field name="Block Types" type="SizedString" arr1="Num Block Types" ver1="10.0.1.0">[...]</field>
[...]
</compound>The idea is that the array describes all the available types in the file.
There is also a Block Type Index array in the header :
<compound name="Header">
[...]
<field name="Num Blocks" type="ulittle32" ver1="3.3.0.13">[...]</field>
[...]
<field name="Block Type Index" type="BlockTypeIndex" arr1="Num Blocks" ver1="10.0.1.0">[...]</field>
[...]
</compound>This array is a list of all the blocks in the file. Each member of this array is a "BlockTypeIndex" :
<basic name="BlockTypeIndex" integral="true" countable="false" size="2">
A 16-bit (signed?) integer, which is used in the header to refer to a particular object type in a object type string array.
The upper bit appears to be a flag used for PhysX block types.
</basic>These values are in reality positions in the header array.
Let's see the values we have in our header example:
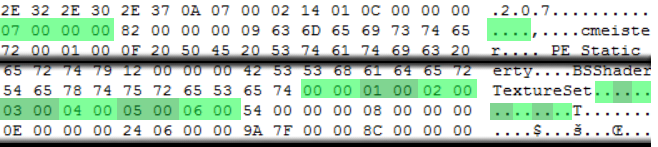
We have 7 values, which are basically just numbers from 0 to 6. They are the positions in the array, and describe all the blocks we have to read. Here, the file is quite simple, as there is only one instance for each block. But keep in mind that in other files it could be more complex with repeating values.
Now, once you've finished to read the header, you can read each block you found one by one from the file.
Just read the niobject that corresponds to the Block Type (e.g. here you'll first read the NiNode object, because the first object is of type 00 which is the type NiNode)
As from version 20.1.0.3, NIF files contains their strings in the header. The idea is that each block needing a string will read it from the head of the file.
String reading is much like Block Type reading, and you'll in reality have a "reference" in the form of a value. This value is the position in the header String array.
Well, hopefully you now know everything you need to try and read NIF files yourself.
Of course, there are several utils by the NifTool community already able to do that automatically:
- NifSkope is the most known util to read NIF files.
- PyFFI supports NIF files, and is used as part of the Blender plugin
- NifLib is a library made specifically to read and write NIF files, and is used as part of several tools (the 3dsMax and Maya plugins).
But knowing how NIF files works at a basic level is a useful skill when a new version comes out or when you try to decode unknown parts of the file.
You can always refer to the full Nif.XML reference here