Use better logic for picking which node to build first #376
Comments
|
https://github.com/nico/ninja/compare/cpsched?expand=1 is a proof-of-concept implementation of letting |
|
Is this likely to be merged? I have a pretty involved old-style Makefile I would like to speed up. My main problem is critical path scheduling - I have some tests that take a long time (almost a minute) to run, and it is nearly impossible to trick make -j to schedule these ahead doing a lot of other smaller tasks that could happen in parallel. I can live with the ~10 seconds overall make tax, but waiting another minute for the build to finish because of bad scheduling is starting to get to me. I was hoping ninja could solve my problem, but if it doesn't do critical path analysis either, then it seems all I'll gain is the 10 seconds or so, not worth the effort of converting the Makefile... BTW, about #60 - it is easy to provide this functionality within a critical-path algorithm by artificially increasing the criticality of tasks that failed when they were last attempted. The "correct" amount to increase by would make a good PHD thesis (involving things like the probability that this new build will succeed, how long it takes to edit the sources to fix the error, and the phase of the moon); in practice adding some configurable amount should be fine. |
|
I tried that on larger projects, and in practice it seemed to do way worse than the current scheduling approach, maybe because it's worse for the disk cache. In practice, most processes seem to be shortlived and there are many of them, so being nice to the disk cache (which the current behavior is) seems more important than being smart about the order. If there are long-running tasks like in your case, the tradeoff is different though. Have you tried using the branch linked to above and measure how much it helps? |
|
What I did is log (out of the existing Makefile) when does each task start, end, and how much CPU % it consumes (this would be lower for an IO intensive task). I then visualized this on a diagram. I can see that my few long-living, high-CPU tasks come "too late", while a ton of short-lived, low CPU % tasks come at the start (where Make doesn't even manage to spawn enough of them to saturate the CPUs). If I could manually rearrange the order they were executed, I could reduce my 3.5 minute build time by about 1 minute (the dependencies allow for that). Also, if I could say "run more of the low-CPU % tasks in parallel" I could probably get it down for 2m for a full build. I think I should be able to do that by using pools in Ninja... The Makefile is pretty involved (several hundred lines of rules, using GNU make macros and wildcard expansions and so on). Converting it to Ninja would take "some effort" - I'm not even certain what the best way would be (would I be able to control everything I want using CMAKE, such as pools etc.? Should I just write some shell/python/ruby script that directly spits out the Ninja rules? etc.). There are other things I can do to speed things up. For example, thanks to my "wonderful" IT department, the compiler and the libraries are installed on an NFS disk... sigh. I could use precompiled headers to reduce some of that pain but there's a GCC bug about such headers that prevents us from doing so (I opened a bug report in GCC, I guess it might be fixed in a few years...). I could do a private install of GCC on a local disk in each and every machine... The problem is that this is my "day job" and I have a lot on my plate. My build time is 3.5 minutes for a full build, and a "nothing to do build" is almost 20 seconds. These numbers aren't enough for me to justify taking a lot of time off my development tasks to "goof off playing with the build system". But it gets annoying and my build times will just grow as we pour more code into the system. I need to be careful deciding where to spend my efforts. Switching to Ninja, even speculatively, would depend on whether I have a good expectation it will actually help. Your point about the disk cache is interesting. It would make sense that "immediately" using the results of a previous step would be more efficient than returning to it after a "long time". Also, using the same source files in parallel steps would be more efficient than running these steps in different times. And, of course, doing a critical path analysis would also help... Optimal scheduling is NP-complete on the best of days. The general solution is "critical chain analysis" (it takes resource contention into account - e.g., considering the effect of pools). There are reasonable, well-known heuristics for it. But it doesn't take into account issues like different times due to caching, as you pointed out. They can be extended to cover these but the hard part would be to estimate the effects of the caching on a given schedule (do we saturate the disk cache here? how much will it cost? etc.). Perhaps one could get "most of" of the goodness is with combining simple tricks. At any given time, you have a list of nodes you can schedule. Suppose you had a modular scheduler, allowing to plug-in different (possibly competing) heuristics which act as tie-breakers. Say each is giving a score to each node, and you decide by the sum of the scores. A configuration file would enable/disable, give parameters, and apply a linear scale to the results of each heuristic, to calibrate it against the others. You could then provide heuristics like "prefer to consume task results as soon as they were created", as well as "prefer to read the same source files in parallel tasks that run together", "prefer to earlier run tasks that failed on a previous build", and also classic critical path/chain analysis. People would be able to easily contribute new heuristics, and people would be able to tweak their configuration files to get an optimal schedule for their projects. Being obsessed with build speed is what Ninja is all about, right? :-) |
|
One approach is to continue to use Makefiles but do more work ahead of time in a script that generates your Makefiles. This script can easily be changed to use Ninja at some point if it looks promising. (CMake can be thought of as one choice for the language to write your script in. But if your Makefiles are complex then maybe you'll think it's easier to write your own Perl script or whatever.) |
There is a makefiles debugging hack One of the best (IMO) decision which I've made in that respect was not to Maxim |
|
I wish that Ideally I need a 2-phase system - regenerate the Ninja file when the file lists change (rarely) and a fast build (using Ninja). The 1st phase can be "almost anything". |
|
It will be interesting to hear the conclusions, if you make any progress
|
|
I have run into exactly same issue described by issue #60: I have a complex and slow to compile C++ project, where full compilation takes almost 10 minutes, a lot of the code is in header files, and changing one header file causes 50 source files to need recompiling. |
|
I have a case where one task in my build is (unfortunately) completely serial, has no build time dependencies and provides one library which is needed at link time by one executable. What I want to do is make sure that it is the first thing that is run (if it needs to be run) but because it is single threaded I want to run other stuff at the same time as well. Any ideas as to how to achieve that? |
|
Wouldn't adding a build order dependency of this target do that? On 4:48PM, Mon, Sep 28, 2015 nathanaelg notifications@github.com wrote:
|
|
If I make everything dependent on the slow task then it will definitely start first, but then everything else will only start once it has completed (which is a waste of time). If I make nothing dependent on it, and only the executable dependent on the slow task it seems to start quite late in the build. |
|
Seconded @nyh - I also have a large C++ project, and have the same desire. Have an option for ninja to sort the current set of runnable targets by newest modification date of the first dependency, or something similar. The goal is to compile the files I've actually been changing first, and then go on to compile the files that haven't been changed. A secondary great idea would be to record failures and have the next ninja run sort previously failed targets first. ie if a header file is changed to fix a build error then I want to know quickly that the fix is good instead of waiting for the failed .cc to eventually come up. To be clear, this is optimizing the compile-build-fix error-compile cycle (try to minimize time to error), not minimizing total build time as other have been talking about. |
|
currently I have one very long build job (10 minutes to complete linking) among other short jobs, and seems ninja schedule this job too late, makes total build time longer than necessary, as profiler shows:
I think both can be implemented by simply reverse walking the dependency graph to find longest path, for first one, we can:
for second one , we can repeat previously steps, just exclude all targets listed in command line from first step, when all nodes marked , makes last target(in command line) outputs distance = current longest distance , and mark from this target again . repeat until all target used as start point. -----update |
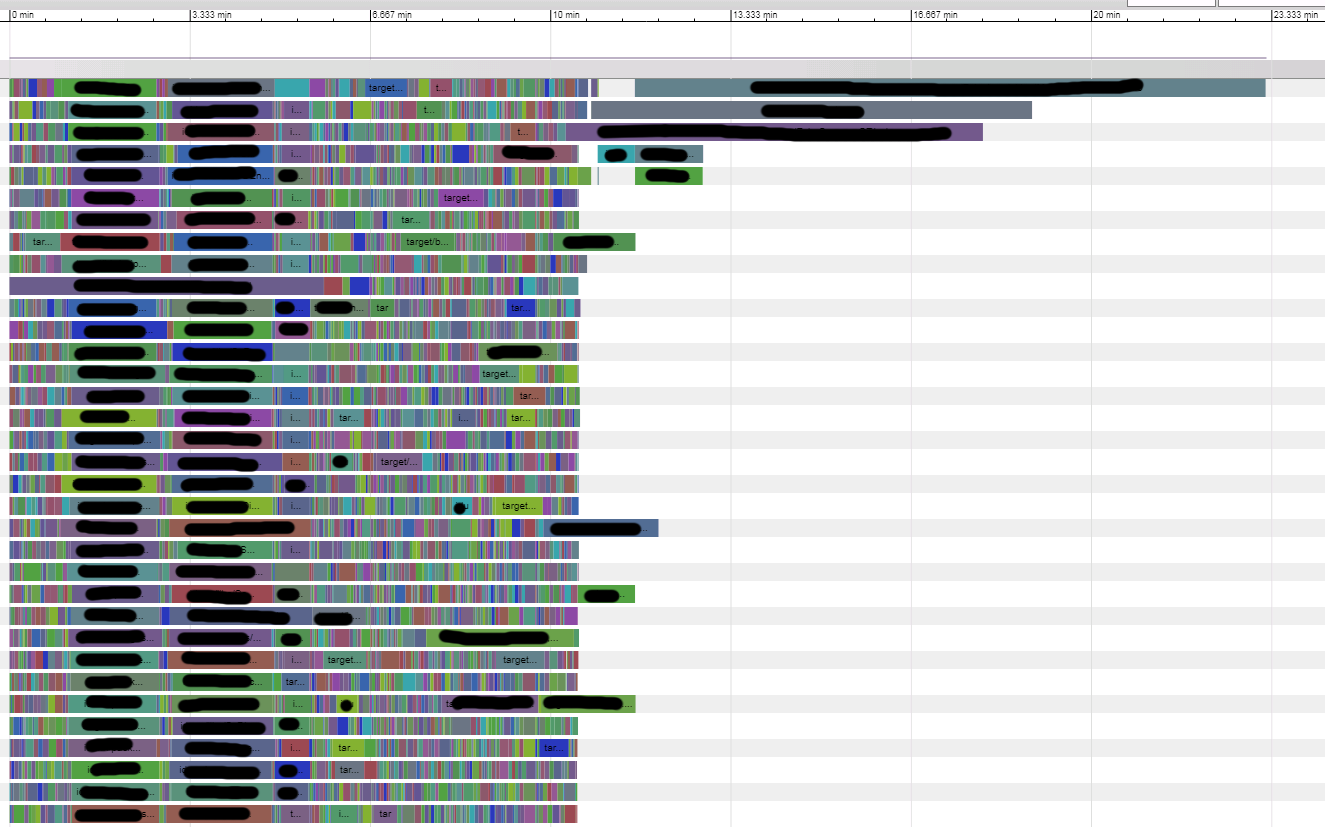
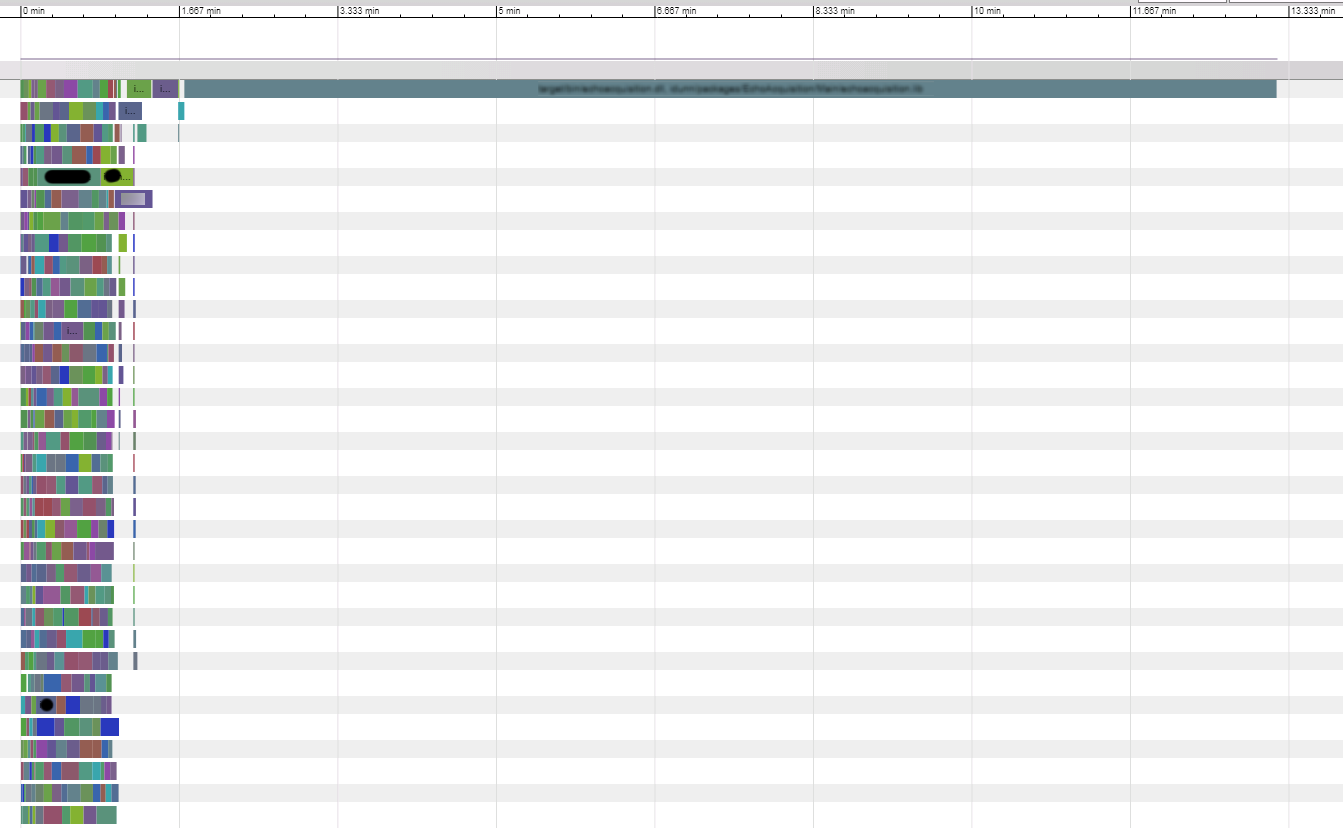

when targets is given in command line , gives higher build priority to target appeared earlier.for example you know longestjob1 longjob2 in project have not been built before, you can run ninja longestjob1 longjob2 all to guild ninja schedule them first to improve overall build time. (this is only needed when such long job have never been built before for first time. ninja always auto schedule the best build order for all targets which built before). this is implmented by assign weight * priority as initial value when compute edge critical time. weight is computed as "total time of these targets if built in serial" so its big enough to assume forward edges of higher priority target always got higher value than edges on lower ones.
|
I can't wait for the the PR in #2019 to be merged, it will be awesome. In many cases it would cut our build times by a ~third, because we have one file (with no input task dependencies) which takes 2x as long as most files: this file should be built immediately at the start but ninja choose to build it near the end, adding about 1 minute to a 3 minute build. Almost any old scheduling algorithm examining .ninja_log would solve this immediately. |
|
fixed by #2177 |
See discussion in #60
The text was updated successfully, but these errors were encountered: