Introduce ZSTD compression to ZFS #9735
Conversation
|
@behlendorf and @ahrens The following people might be interested in reviewing this (considering their previous activity on compression and/or zstd and/or their leading roles on their respective OpenZFS platforms): I'll send out the headsup to the OpenZFS mailinglist as soon as possible, as agreed on the Leadership meeting. edit |
Codecov Report
@@ Coverage Diff @@
## master #9735 +/- ##
========================================
+ Coverage 79% 79% +<1%
========================================
Files 386 387 +1
Lines 122448 122721 +273
========================================
+ Hits 97087 97521 +434
+ Misses 25361 25200 -161
Continue to review full report at Codecov.
|

2533571
to
4899077
Compare
|
Note: Latest force push was just fixing this documentation typo: |
|
@behlendorf test failures this run are unrelated, previous run already passed all.
You might still want to restart the failed once though... ;) |

There was a problem hiding this comment.
Proper commit attribution is important in open source; "Signed-off-by" helps but doesn't play well with "git blame". Most of this code must be committed by Allan Jude because he did most of the work behind it; the same method was used to integrate openzfs commits.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
We already have the people working on this at the very top: I'm not sure what adding another list of the same people should help? I'm not against it... just asking if we want to duplicate that :) |
|
@c0d3z3r0 It seems that tag gets auto translated on github to a linked user. |
|
This comment has been minimized.
This comment has been minimized.
4899077
to
c523a9f
Compare
This comment has been minimized.
This comment has been minimized.
|
@c0d3z3r0 That indeed looks amazing! And this would also give @BrainSlayer his, well deserved, "contributor" tag when merged 👍 @c0d3z3r0 While at it: It doesn't contain my code, this was a leftover from before we split. @neemoi |
c523a9f
to
bead964
Compare
This comment has been minimized.
This comment has been minimized.
|
@BrainSlayer offtopic please don't and go to the right place to discuss persistant l2arc |
|
@Ornias1993 i updated my own tree and merged the persistant arc code with the zstd code. i'm really not sure if all is correct. the persistent l2arc code is originally ignoring all user compression settings, and always enforced lz4, even if compression is disabled. i tried to cover this problem (i even think this is a bug in the origjnal patch). so testing is required |
this is not offtopic. its directly related to the zstd patch. |
|
@BrainSlayer the persistent L2ARC does use LZ4 only for the compression of the metadata (L2ARC log blocks). Otherwise the L2ARC buffers (L2ARC data) use whatever compression the filesystem uses. Let's continue this discussion in #9582. |
This imports the unmodified ZStandard source to contrib/ which will be used by ZFS. This code shall not be modified in any way to keep it easily updatable. Only the required files from lib/ are imported. contrib/zstd is excluded from codecov calculation as dependencies don't need full codecov. Co-authored-by: Allan Jude <allanjude@freebsd.org> Co-authored-by: Kjeld Schouten-Lebbing kjeld@schouten-lebbing.nl Co-authored-by: Michael Niewöhner <foss@mniewoehner.de> Signed-off-by: Allan Jude <allanjude@freebsd.org> Signed-off-by: Kjeld Schouten-Lebbing kjeld@schouten-lebbing.nl Signed-off-by: Michael Niewöhner <foss@mniewoehner.de>
These files make ZStandard compile as a kernel module without modifying the ZStandard source files. Removed unexpanded SVN version tracking tags from FreeBSD Co-authored-by: Allan Jude <allanjude@freebsd.org> Co-authored-by: Michael Niewöhner <foss@mniewoehner.de> Signed-off-by: Allan Jude <allanjude@freebsd.org> Signed-off-by: Michael Niewöhner <foss@mniewoehner.de>
Extend APIs that deals with compression to also pass the compression level. Co-authored-by: Allan Jude <allanjude@freebsd.org> Co-authored-by: Sebastian Gottschall <s.gottschall@dd-wrt.com> Co-authored-by: Michael Niewöhner <foss@mniewoehner.de> Signed-off-by: Allan Jude <allanjude@freebsd.org> Signed-off-by: Sebastian Gottschall <s.gottschall@dd-wrt.com> Signed-off-by: Michael Niewöhner <foss@mniewoehner.de>
Closes: openzfs#6247 Co-authored-by: Allan Jude <allanjude@freebsd.org> Co-authored-by: Sebastian Gottschall <s.gottschall@dd-wrt.com> Co-authored-by: Michael Niewöhner <foss@mniewoehner.de> Signed-off-by: Allan Jude <allanjude@freebsd.org> Signed-off-by: Sebastian Gottschall <s.gottschall@dd-wrt.com> Signed-off-by: Michael Niewöhner <foss@mniewoehner.de>
This add a new build intermediary libzstd. This allows us to keep zstd cleanly separated from libzpool and to override the frame-size compiler option without for zstd only. (This is needed due to unused coude in the unmodified zstd source.) Signed-off-by: Michael Niewöhner <foss@mniewoehner.de>
Add zstd to the test suite - add zstd to history_002_pos.ksh - add random levels of zstd to history_002_pos.ksh - add zstd-fast to history_002_pos.ksh - add random levels of zstd-fast to history_002_pos.ksh Add documentation - add man page content - add README for contrib/zstd Fixup copyright headers of touched and new files - Adds copyright headers for Allan Jude / Klara Inc. - Added Ornias1993 Copyright - Cleans copyright header formatting Co-authored-by: Allan Jude <allanjude@freebsd.org> Co-authored-by: Sebastian Gottschall <s.gottschall@dd-wrt.com> Co-authored-by: Kjeld Schouten-Lebbing <kjeld@schouten-lebbing.nl> Co-authored-by: Michael Niewöhner <foss@mniewoehner.de> Signed-off-by: Allan Jude <allanjude@freebsd.org> Signed-off-by: Sebastian Gottschall <s.gottschall@dd-wrt.com> Signed-off-by: Kjeld Schouten-Lebbing <kjeld@schouten-lebbing.nl> Signed-off-by: Michael Niewöhner <foss@mniewoehner.de>
Will be squashed after successful test. Signed-off-by: Michael Niewöhner <foss@mniewoehner.de>
85d406c
to
ef6792a
Compare
|
Leadership meeting:
Yeah, so much left over feedback that no one is actually able to state what the hack they are talking about. There is one note about feature flags, which isn't a ZSTD specific issue and is actually out of scope.
Which is already done by @c0d3z3r0 and @BrainSlayer and it's insanely annoyingno-one asked for more splitting for months. It would've been almost no work while we are splitting it. Also why didn't @allanjude stated to be working on redoing the splitting done by @BrainSlayer over here?
If the guys/gals in the leadership meeting actually followed ZSTD-on-ZFS, they would've known I went over EVERY GOD DAMN COMMENT AND REVIEW. already. 3 times. It seems people that aren't interesting in reviewing this PR themselves (even though promises are made) are now making pisses in the Leadership meeting. Yes, i'm getting annoyed at this. Don't sneak in feedback in leaderships meetings, but file them in a gosh damn review so the people involved can discus them and work at them. What I find annoying the most is the lack of honesty. It's clear for me that @BrainSlayer was right in the end: The leadership doesn't actually want to support this PR and just tends to ignore it when they can. It's a never ending cycle of "fixing it up", "not getting reviews" and "yeah, but now it's not working anymore". For years now btw. As there is no leadership interest in this, I'm out. And fully out of ZFS completely too for that mater: I don't mind if there is no interest from project leadership in a feature. But be gosh damn honest about it. @BrainSlayer @c0d3z3r0 and @allanjude Good luck getting this merged before 2025, I really hope you guys can do it! |
|
to be honest, zstd compression has been announced publicly more than 2 years ago ( https://www.phoronix.com/scan.php?page=news_item&px=OpenZFS-Zstd-Compression ) and at least i heard of that more then 3 years ago. given the fact that i read that implementing another compression scheme in zfs is mostly straightforward, i'm really curious why it's taking that long. please , make the good thing happen. i think zstd feature is very very useful. |
|
@devZer0 This. Don't take me wrong: I don't mind frustrating approval processes to ensure quality. But this isn't about quality, it's about putting things off due to personal preferences. Which I (also) find bad form. This sums it up nicely:
You know what they missed? The few hunderd messages discussing all older versions to make sure we didn't miss anything in the new(this) version. The Hubris. |
What the fuck!? First they want to merge it all into one big blob. I said this is a bad idea, so we split it up, but they did take part on any discussion. And now, they want to split it up further? lol Guess what? I'm fed up with this. This is not the way people willing to help should be treated. Closed. |
|
what? i had to close my PR in favor you opened yours and now you closed yours and all my work is wasted? |
|
@BrainSlayer No, you can just continue with this. Just pull his Repo and send in a new PR. Me and @c0d3z3r0 just don't want to maintain the PR. The code is still there. |
|
reopened to avoid a mess. |
|
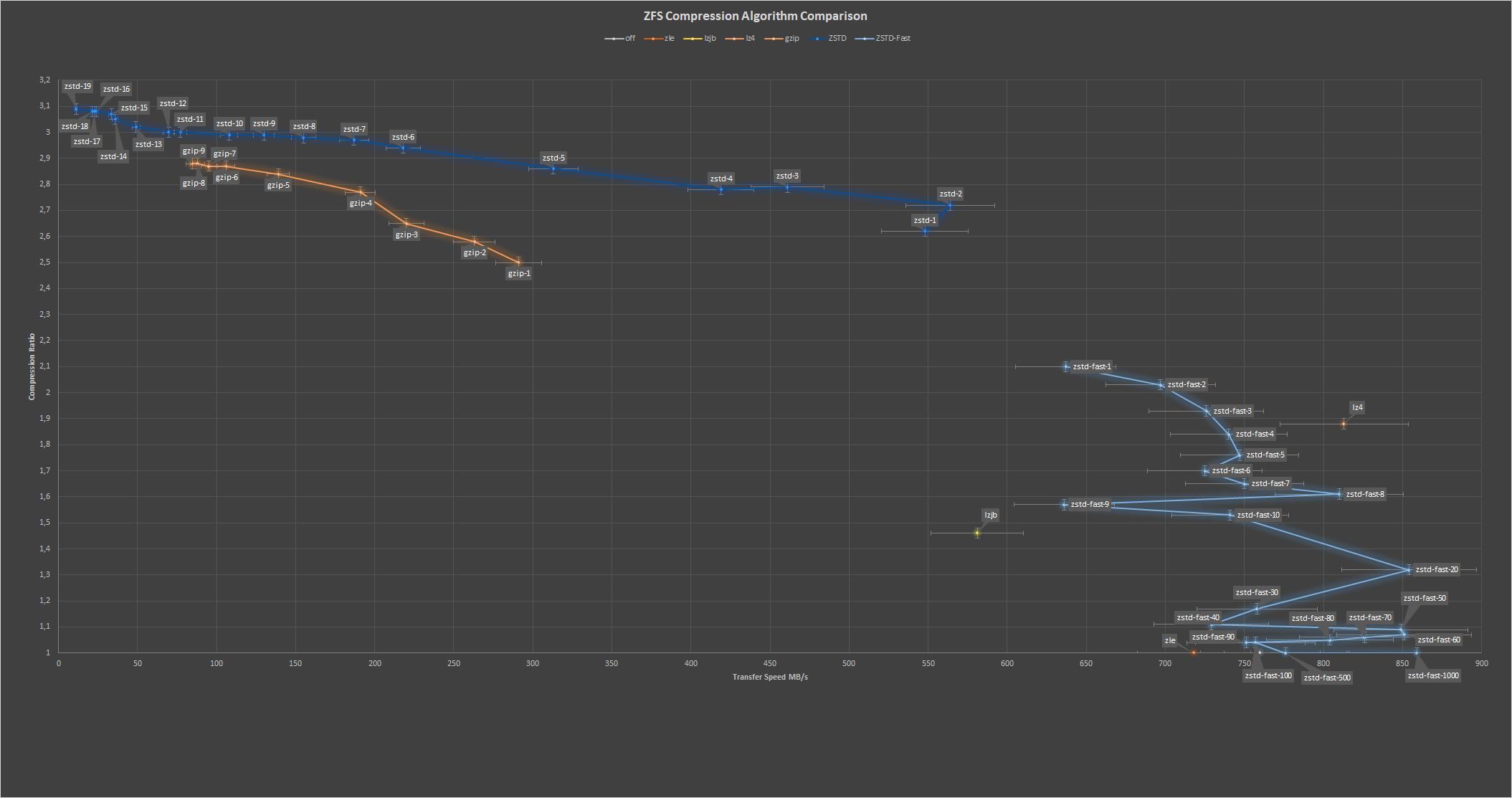
Sorry for commenting on this old pull request. I have a question about the benchmark data posted here, and also referenced from the newer pull request #10278 . You posted two different benchmark results from the benchmark tool. The first result from the original post indicates that sequential read/write However your "updated" performance graphs seem to indicate that You said that you wanted to not draw any conclusion about the performance of zstd on zfs and let the numbers speak for themselves. But can you help me understand what has changed the relative performance of the compression algorithms between the two tests so dramatically? Was it optimizations and development? Or was it different hardware? Or different test data? Or all of those? Is the "updated" result more representative of the relative performance of those algorithms in zfs in your opinion? Did I miss something? Thanks in advance! |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
Only the last test should be used. To be clear: These tests can ONLY be read within their own context, you cannot compare the two or draw conclusions for your own systems. They are both only intended to be viewed within their own suite of tests. There where many changes between the two suites, but as it isn't relevant (as they are not applicable outside their own context of comparing algorithms) it's not listed. Nor do I even know YEAR later. |
|
Thanks for the feedback and for contextualizing the benchmark data for me @Ornias1993. I won't bother you any more. |
Feel completely free to throw messages on more recent PR's/Issues and/or email me though. |
This PR introduces ZSTD compression to ZFS.
Many thanks to:
The original Proof of Concept by @allanjude see: #9024
The Linux compatibility redesign by @BrainSlayer see: #8941
Spin-off kvmem patch by @c0d3z3r0 see: #9034
Spin-off test refactor by @ornias1993 see: #9626
Spin-off Code-coverage Ignore by @ornias1993 see: #9726
Additional testing, validation and review by @dan-and and @ornias1993 see: Test suite
Restructure and Refactor by @c0d3z3r0 and @BrainSlayer see: This PR
PR description and documentation by @ornias1993 see: This PR
Co-authored-by: Allan Jude allanjude@freebsd.org
Co-authored-by: Sebastian Gottschall s.gottschall@dd-wrt.com
Co-authored-by: Kjeld Schouten-Lebbing kjeld@schouten-lebbing.nl
Co-authored-by: Michael Niewöhner foss@mniewoehner.de
Signed-off-by: Allan Jude allanjude@freebsd.org
Signed-off-by: Sebastian Gottschall s.gottschall@dd-wrt.com
Signed-off-by: Kjeld Schouten-Lebbing kjeld@schouten-lebbing.nl
Signed-off-by: Michael Niewöhner foss@mniewoehner.de
See commits for sign-off-by per code-portion
Motivation and Context
ZStandard is a modern, high performance, general compression algorithm originally developed by Yann Collet (the author of LZ4). It aims to provide similar or better compression levels to GZIP, but with much better performance. ZStandard provides a large selection of compression levels to allow a storage administrator to select the preferred performance/compression trade-off.
A Proof of Concept was made by @allanjude for FreeBSD and reworked by @BrainSlayer in his PR, adding the following:
This work was restructured and, somewhat, refactored by @c0d3z3r0 and description/documentation is(re)written by @ornias1993 to ensure it's easy-to and ready-for review.
This PR description might be a long read, but tries to encapsulate multiple previous iterations, much work and many comments.
Description
ZSTD Feature
This PR adds the new compression types: zstd and zstd-fast, which is basically a faster "negative" level of zstd.
Available compression levels for zstd are zstd-1 through zstd-19. In addition, faster levels supported by zstd-fast are 1-10, 20-100 (in increments of 10), 500 and 1000. As zstd-fast is basically a "negative" level of zstd, it gets faster with every level in stark contrast with "normal" zstd which gets slower with every level.
Rather than the approach used when gzip was added, of using a separate compression type for each different level, this PR added a new hidden property,
compression_level. All of the zstd levels use the single entry in the zio_compress enum, since all levels use the same decompression function.However, in some cases, it was necessary to know what level a block was compressed within other parts of the code, so the compression level is stored on disk inline with the data, after the compression header (uncompressed size). The level is plumbed through arc_buf_hdr_t, objset_t, and zio_prop_t. There may still be additional places where this needs to be added.
This new property is hidden from the user, and the user simply does
zfs set compress=zstd-10 datasetand zfs_ioctl.c splits this single value into the two values to be stored in the dataset properties. This logic has been extended to Channel Programs as well.How Has This Been Tested?
The following testing has been performed:
Performance testing
Extra care has been taken to guarantee performance and reliability.
Compression performance using a custom development script by @Ornias.
Repeatability of the test is confirmed by @dan-and.
Updated performance graphs: here
Please click the graphs for more detail
Speeds are for comparative reference only and will differ based on the system from which the test is ran
Test Tool: #9756
This test also includes SHA256 checkum verification, which it passes.
Buildbot testing
On top of the normal build-bot procedure, extra manual verification has been done to ensure the test timers of relevant tests stay as close to master as possible. This is done due to early tests indicating situations in which a test would pass, but (due to bugs) with significant performance degradation.
No unexpected slow executions of tests where observed in this PR.
Stress and live testing
Stress testing has been performed on a ssd only pool by @BrainSlayer and on an hdd pool by @dan-and
On top of that, multiple versions of this build have been tested running on a ssd and hdd based live (production) machines with varying load, to ensure stability.
Frequently Asked Questions
A: Most of this code is the ZSTD library, which has not been altered. Therefor it would be safe to skip contrib/zstd during your review.
A: This was a difficult choice, we tried to take into account the problems upgrading lz4 and wanted to keep it as "upgrade friendly" as possible. The performance difference between a cut-down and full zstd library are minimal.
A: A lot can happen in a year. Because of the FreeBSD merger (and to not spend time removing things only to put it back) we wanted to keep it as easy as possible for the BSD developers to port. However: We did not test on FreeBSD.
A: Some tests happen to run/build in user-space, this ensures test compatibility and shouldn't have any adverse effects
A: Copyright headers do not change actual copyright. When we added a header, we just reformatted the rest to ensure it looks nice. We also made extra sure the headers are correct for ZSTD, by going over all changes and adding headers where they where forgotten by previous contributors.
ccflags-y += -Wframe-larger-than=20480, wouldn't this cause issues down the line?A: This is a consequence of using the unmodified ZSTD library and is only used on said library. However, the functions giving Frame-Size errors are not actually used by us. This is tested by modifying the Library without the troubled code. We can assure you this does not cause issues.
contrib/zstdignored from code coverage, don't we want to cover zstd with tests too?A: Most of the code in the unmodified library is not in use by ZFS (and thus: Not covered by tests) and is already tested/supported by the ZSTD project. There are no plans for OpenZFS to maintain our own ZSTD fork. So in short: Calculating coverage on the ZSTD library leads to lots of "uncovered code" which is only a distraction because the ZSTD library isn't supposed to be covered by our tests.
A: While the compression speeds are on par with stock-zstd metrics, indeed on the decompression side there is still room for improvement. Luckily this PR never was meant to be the end of ZSTD-on-ZFS development and we are full of idea's for future incremental performance, quality and feature enhancements...
Types of changes
Checklist:
Signed-off-by.