Dans cette session pratique, nous allons:
- comprendre le fonctionnement de Kafka et ses différentes terminologies
- déployer et configurer un cluster Kafka
- mettre en oeuvre une application de traitement de données en Python
- ...
A faire avant la session pratique.
PyCharm est un IDE permettant de développer des applications en Python. Nous allons l'utiliser lors de cette session pratique car il intègre plusieurs outils qui facilitent et accélèrent le développement des applications.
La version PyCharm Community est disponible ici.
Téléchargez et installez la version compatible avec votre machine.
Commande spéciale pour Ubuntu 16.04 ou plus:
sudo snap install pycharm-community --classic
Note: votre compte étudiant de Dauphine vous donne accès gratuitement à la version Ultimate. Pour cela, il suffit de vous enregistrer avec votre adresse mail de Dauphine et de valider l'inscription.
Je vous invite à prendre en main PyCharm avec ce tutoriel.
Dans cette session, pour des raisons pratiques, nous allons utiliser des dockers (conteneurs d'applications) pour exécuter nos applications.
Un docker est un conteneur d'applications permettant d'exécuter une application indépendamment du système d'exploitation et de ses dépendances.
L'application est packagée d'une façon autonome (avec toutes ses dépendances) pour être exécutée sur n'importe quel système.
Les liens ci-dessous vous guident dans l'installation de Docker sur votre machine locale:
Windows | Ubuntu | Mac.
Veuillez réaliser l'installation avant la session.
Les utilisateurs de Linux ont besoin d'installer docker-compose. Pour les autres (Mac et Windows), cet utilitaire est déjà inclus dans Docker Desktop (installé plus haut).
Le code source de cette partie est disponible dans ce repository.
Vous pouvez le récupérer en utilisant git ou en téléchargeant l'archive https://github.com/osekoo/hands-on-kafka/archive/refs/heads/develop.zip.
Nous allons étudier deux cas:
- get_started: une application simple d'écriture et de lecture de données. Il permet de comprendre les différents mécanismes de Kafka (producers, consumers, consumer group, etc).
- dico: une application asynchrone de recherche de définition des mots sur internet (dictionnaire).
Nous allons utiliser les images bitnami de Kafka pour exécuter Kafka sur notre machine locale.
- extrayez l'archive dans un répertoire
- ouvrez le répertoire
hands-on-kafkaavecPyCharm - si l'interpréteur python n'est pas reconnu,
- sélectionnez un interpréteur qui vous sera proposé
- ou allez dans
File > Settings > Project: hands-on-kafka - cliquez ensuite sur
Add interpreteretAdd local interpreter. - cochez la case
Newet sélectionnez unBase interpreter - ensuite validez tout en cliquant sur
OK
- installez les dépendances python avec la commande
pip install -r requirements.txt - exécution du broker kafka: dans un terminal exécutez la commande
docker-compose up- allez visiter le
dashboard kafkaà l'adressehttp://localhost:9094. - Nous verrons ensemble les informations disponibles sur ce dashboard.
- allez visiter le
Le module get_started permet de publier et de lire des messages. Il contient 3 fichiers:
config.py: contient les variables/constantes globales.producer.py: permet de publier une série de messages (ici une série de chiffres) sur le bus Kafka.consumer.py: permet de lire les messages (les chiffres publiés par leproducer) publiés par le consumer.

- exécution du producer: dans un autre terminal exécuter la commande
python ./get_started/producer.py- le producer envoie sur le broker une série de nombres de 0 à 99
- exécution du consumer: dans un autre terminal exécuter la commande
python ./get_started/consumer.py- le consumer lit les nombres envoyés par le producer et affiche un message sur la console
- allez sur le
dashboard, cliquez surmy-topicensuite sur lapartition 0pour voir les messages envoyés

Le module dico permet de chercher la définition d'un mot sur Internet. Il supporte le français (lerobert.com) et l'anglais (dictionary.com). Ce module contient 5 fichiers:
config.py: contient les variables globales (noms des topics, noms des dictionnaires, etc.).crawler.py: permet de chercher la définition des mots sur Internet en français (CrawlerFR) et en anglais (CrawlerEN). Cette classe extrait la définition des mots en parsant la source HTML du résultat de recherche. Le parsing peut parfois échoué si la structure HTML de la page a changé.worker.py: contient une class (Worker) qui permet de lire les requêtes de recherche postées dans le bus Kafka (en modeconsumer), effectue la recherche en utilisant le crawler (data processing) et republie le résultat dans Kafka (en modeproducer).client.py: publie dans Kafka la requête de recherche de définition (en modeproducer) et lit au retour la réponse (en modeconsumer). Il affiche la réponse sur la console.kafka_data.py: implémente les structures de données (KafkaRequest,KafkaResponse) échangées entre les clients et les workers à travers Kafka.
- cluster kafka: dans un terminal, exécutez la commande
docker-compose up - lancement du client: dans un autre terminal, exécutez le script
python dico/client.py- entrez votre pseudonyme
- choisissez le dictionnaire, par exemple
frpour le français - entrez un mot en français, par exemple
bonjour - allez sur le dashboard de kafka (http://localhost:9094), ouvrez le topic
topic-dictionary-fr, naviguez dans les partitions pour trouver le message avec le mot que vous venez d'entrer
- lancement du worker: dans un autre terminal, exécutez le script
python dico/worker.py- le worker lit les mots à définir de puis kafka et les définit en utilisant le crawler
- crawle un site internet (Larousse pour le français) pour récupérer la définition du mot
- republie le résultat sur le broker kafka dans le topic
topic-dictionary-fr-<pseudonyme>pour qu'il puisse être lu par le client - dans le même temps, le worker publie dans le topic
spark-streaming-dicole mot et sa définition - ce topic sera lu par l'application
Spark Streamingpour réaliser d'autres opérations (e.g WordCount) - vous devez voir également sur le dashboard un topic nommé
topic-dictionary-fr-<pseudonyme>avec le message contenant le mot et sa définition
à faire chez vous
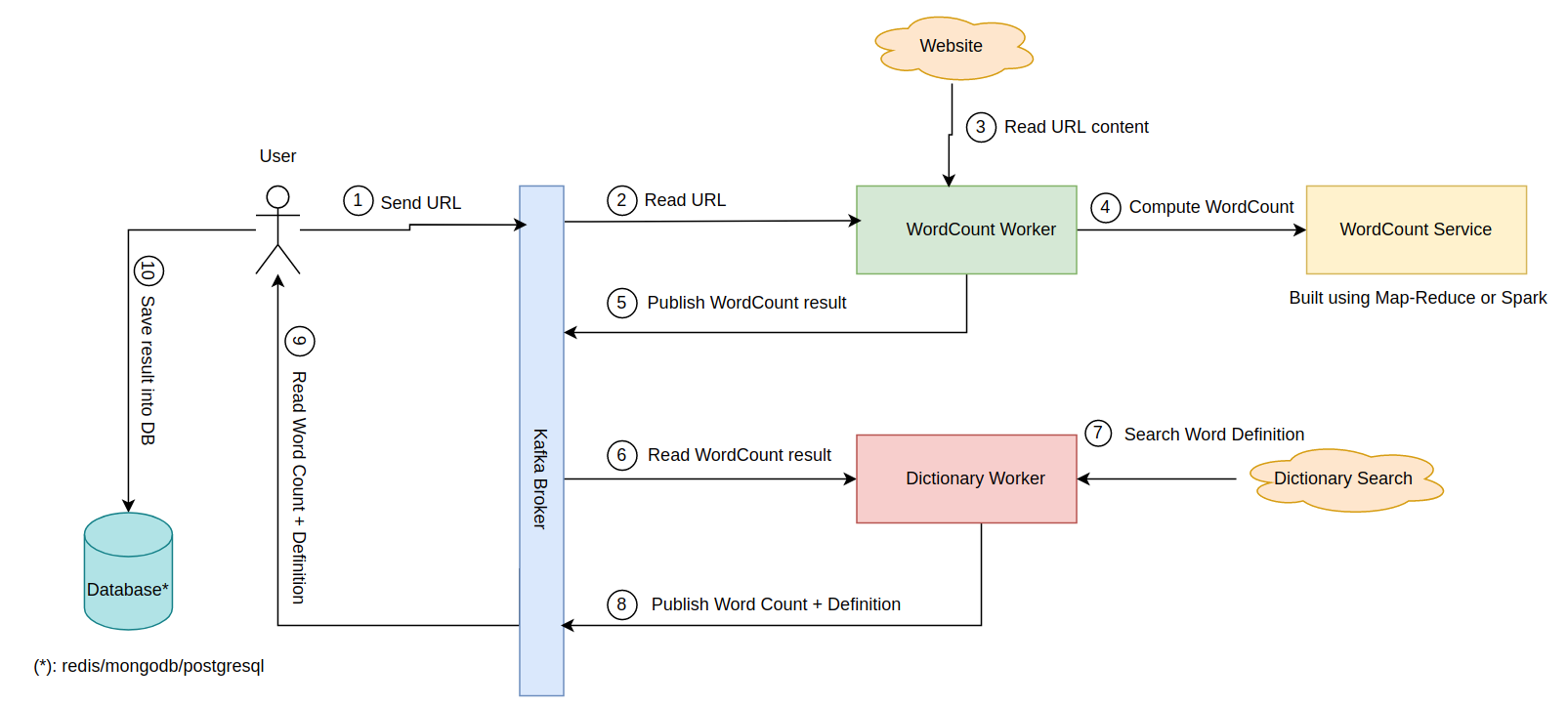
Implémentez une application de data pipeline ayant les fonctionnalités suivantes:
- un utilisateur envoie sur un topic Kafka une URL d'un site Internet contenant du texte,
- un premier groupe de consumers lit l'URL, récupère le contenu de l'URL et réalise un WordCount sur ce contenu. Il publie ensuite le résultat de wordCount (liste de mots et leur occurrence) dans Kafka,
- un deuxième groupe de consumers lit le résultat de wordCount et cherche la définition de chaque mot. Il renvoie ensuite au client la liste des mots avec leur occurrence et leur définition.
- l'utilisateur lit ce résultat et... l'enregistre dans une base de données!
- Vous pouvez rajoutez d'autres langues (espagnol, allemand, chinois, etc.)
L'application doit supporter au moins deux langues.
Quelles sont les applications possibles d'un tel programme?