Align or axiomatize PATO/BFO/UO with qudt #101
Comments
|
I took some time to look into both QUDT and OM, which is produced by Hajo Rijgersperg at U of Wagenigen in the Netherlands: https://github.com/HajoRijgersberg/OM . OM has been developed as an offspring of food research needs (http://www.foodvoc.org/page/om-1.8) , but takes on a broad scope of units like QUDT. Hajo compares OM with QUDT in this paper: http://www.semantic-web-journal.net/sites/default/files/swj177_7.pdf . Another comparison paper puts OM out front in quantity of unit terms: http://www.semantic-web-journal.net/system/files/swj1825.pdf Here's a comparison diagram I based on Hajo's diagraming, which focuses on specifying values of measurables/estimates etc. ('has unit label' ~= 'has measurement unit label').
|
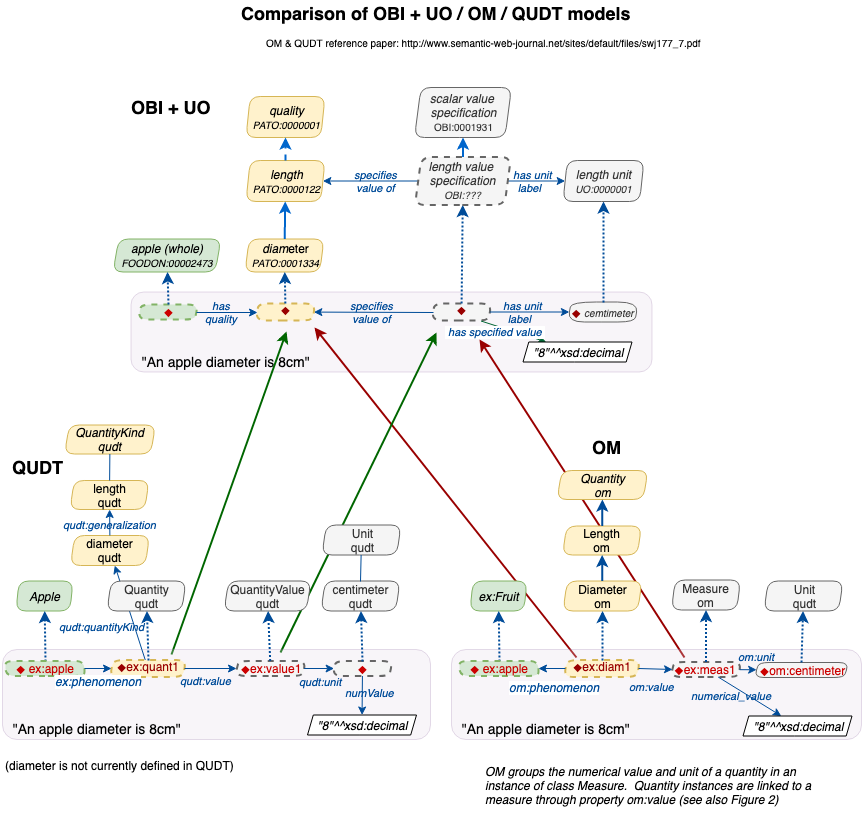
|
Just found this thread. A few response and comments on the concerns raised above:
|
|
Thanks for the interest in OM! Just ran into this thread and I want to read all of it. I was pointed to the comment of dr. Short Hair above. Please allow me to state a few corrections: OM contains the same order of amount of units as QUDT, and - as far as we know - contains no errors whatsoever. Thought it would be good to let you know. |
|
I have studied your great diagram above, Damion, https://user-images.githubusercontent.com/4000582/56243972-a72e7280-6050-11e9-8277-fcad93ad58e7.png. It seems that OBI+UO and OM resemble a lot, as far as the definition of classes is concerned. For example, 'scalar value specification' matches to om:Measure. What is more, similar to the approach in OBI+UO, the om:hasValue relation is restricted on class level, om: Quantity, to om:Measure (among some other classes). This makes OBI+UO and OM look even more alike. Differences I see have to do with:
|
|
UO (https://github.com/bio-ontology-research-group/unit-ontology) does have a top level "unit" class, and has a few versions - one with all units as instances and the other with units as classes. Looks like I could have given "length unit" a parent of "unit".
So at the class level, yes I think OM and UO are quite similar. I know OM has modelled out units in terms of SI base units, and so has more smarts about how to do unit conversions?! P.s. for reference, the OM ontology home: https://github.com/HajoRijgersberg/OM |

|
Thanks, Damion! Clear. With that 'unit' class indeed UO and OM look even more like each other. |
Perhaps I'm not looking in the right place? However, I don't think this is a competition ;-). The different ontologies are all transformable (the underlying models are necessarily the same), and we have several parallel options in practice for the good reason of history and community expectations. So the coverage does not overlap completely for this reason. Our (larger) community goal should be to (i) improve quality in all of them, in both the model/ontology and the catalogues of individuals or classes (cross comparisons such as @jmkeil's https://github.com/fusion-jena/abecto-unit-ontology-comparison is a big help here) (ii) develop rules and scripts to allow us to align and harvest between them (iii) advertise and educate the broader community that units is a solved problem, so future efforts would be better put into improving the quality of the existing offers, and not in creating yet more options that are essentially duplicative. |
No, you should also count the different compound units (unit multiplications, unit divisions, and unit exponentiations) and prefixed units. In total the same order of amount as QUDT. (See also the publication of Jan Martin.) As a matter of fact, huge ranges of prefixed units and compound units composed of different prefixed units still have to be defined. That must be the case with QUDT too. And indeed, it's not a competition! :) |
|
Good. IMO the static representations would be better thought of as a 'cache'. Strictly, only the primitive ones need be built manually, and the general case should be to generate semantic descriptions for all the compound units and most of the derived units on-the-fly from these. This is essentially the UCUM approach - only the terminals are stored, and all combinations are generated by rules. BUT - in semantic/linked-data applications, stable URIs are essential. So dynamically generated representations of units would need a rule for URIs, and thus non-opaque URIs. Which is not the normal OBO approach. Right @cmungall ? |
|
Sounds interesting, but to understand you 100%, what do you mean with 'cache'? And with 'the primitive ones' and 'terminals' you mean the base units such as metre, second, etc.? |
|
By 'cache' I mean the units that could be computed, but are actually instantiated as static members of a vocabulary such as the QUDT units catalogue. By referring to them as a 'cache' I'm emphasizing that they should be understood in that way - they are a pre-computed cache of individuals that are known to be used, but which could have been generated on-demand. By having them in a cache it allows some additional annotations and links to be included, and maybe provides some performance optimization. UCUM is the most mature precedent for the set of 'primitive' ones that must be built manually. The UCUM 'essence' is its list of the things ('terminals') that can't be computed by combination of other terminals using the UCUM production rule. It is composed of
This is not complete, but gives a sense of the scale of the required set. (QUDT adds a few more prefixes for the information quantities (Kibi, Mebi, Gibi, etc) ) |
|
Clear, thanks. |
Indeed. They have to be part of the static set. On the stable URIs issue - the thing I'm most concerned about is that OBO (which includes PATO/BFO/UO) has a strong preference for opaque URIs. However, because of the combinatorial requirement in units, and the fact that it is an unbounded set but in a predictable way, I suspect that non-opaque URIs are necessary. So I'd like this issue surfaced sooner rather than later. (BTW - I now see that my count of OM units failed to account for sub-classes. The sizes of the corpuses are very similar, which is reassuring. QUDT has more derived units including some fairly random combos, while OM has a more systematic accounting of the prefixed-units, but a much smaller number of derived units.) |
|
Hey Simon, just checking for my full understanding: an opaque IRI is an IRI with human-understandable terms in it? And a non-opaque IRI is like a code (which human beings can't understand, with no specific meaning)? (BTW: sounds good! :) I think with Kai's algorithms he will create a lot more prefixed units and compound units!) |
|
It is the other way around:
|
Possibly. But I'm not sure that the algorithm should be run to just create (and cache) all the combos willy-nilly. You don't really want a catalogue of 50,000 units of which only 1,000 ever appear in actual datasets, do you? |
|
Pulling @satra in here since we have poked at the issue of units a number of times when qudt was still in the trough. Creating a catalogue of precomposed units was very much a non-starter for us as well. |
|
I agree. We need coverage of units devices record in, and units humans talk to each other about and share in data. But all other units would only arise as ephemeral intermediate constructs i.e. in intermediate math that doesn't need a name for such constructs. |
|
thanks for the ping @tgbugs - if it helps i provide a brief summary of where we went with units. we went away from the route of enumerating units and unit combos to treating a unit as a special string literal. we decided on using this https://people.csail.mit.edu/jaffer/MIXF/CMIXF-12 and implemented a python parser https://github.com/sensein/cmixf . for us this became more about practicality than ontology as we can write validators and converters around this. this is not going to satisfy every use-case since it focuses on SI units, but we also needed something that standardizes use in a specific context (the BIDS system). even in our case the units for weight, height, and age remain non-standardized for now. further, age itself has additional considerations of reference value, where the unit is insufficient to disambiguate information. |
|
Personally, I do think we should define "all" possible compound (prefixed) units. If people have to define them themselves, we will encounter similar definitions, that just deviate a bit from each other, especially in their URI (especially if the URIs are opaque, but also with non-opaque URIs formed using rules people will make mistakes). |
|
If all possible combinations are constructed then wouldn't there need to be a function to take the composition rule and the input units and turn it into an identifier to make it possible for people to find the right opaque identifier? |
|
Yes, I think so. That could definitely be automated. Kai could incorporate it into his algorithms, although it anticipates the opaque/non-opaque discussion. |
|
For those opening this old thread, latest work to provide non-opaque, normalized UCUM units, meant to bridge UO, OM, etc. : https://units-of-measurement.org/ and https://github.com/units-of-measurement |
This is emerging as the standard for units on the semantic web: http://qudt.org/
How does this affect PATO? Here are some possibilities:
I'll briefly explore the last option here. Note the motivation here is primarily pragmatic, not philosophical. Some familiarity with contents of PATO assumed, and in particular with the use cases it aims to solve (which we should really have documented elsewhere...)
Modeling differences
The QUDT schema is shown here:
A rough alignment to PATO/BFO/OBO Ontologies is:
valuesubset of PATOattributesubset of PATOQuantities vs qualities
The first difference that should be noted is that PATO's scope includes many inherently non-quantifiable or hard to quantify qualities. There is no 'shape' in qudt. However, it may still be possible to encompass complex multi-dimensional qualities like this using some morphometric formalization.
Another difference is the use of classes vs instances. PATO forms a simple subclass hierarchy. E.g.
In qudt, quantities Velocity and 'Angular Velocity' (I'll use the qudt upper class labels to distinguish from lowercase PATO) are individuals. They are linked by the qudt:generalization OP. The use of SubClass is used to place these individuals into broad categories. For example, Volume is of type 'Spaces and Time' (more will be said of the naming conventions later).
While this is clearly has different semantics with different implications for reasoning, it's not clear it's fundamentally incompatible - in that the two systems could live side by side with axioms connecting them.
The use of an ObjectProperty in place of SubClass semantics could be pragmatically difficult for us as we are reliant on OWL reasoning. Some portion of this could be recapitulated via property chains, but this is would probably be insufficient for many PATO use cases, which include axiomatization of phenotype and trait ontologies where are inherently class-based.
One possibility here is to pun qudt and reconstitute the generalization assertions as SubClassOf axioms. The more pragmatic route will likely to be to maintain PATO classes, but to axiomatize them using some pattern such as
PATO:Q EquivalentTo P Value qudt:Q. P can be an invented property here, the purpose is to maintain a correspondence (and potentially use for inference). If an interpretation is sought then this can be thought of as a kind of set-extent relation that projects from a class to an individual that is the mereological sum of all instances of that class, and the generalization relation can be interpreted as part-of.The larger difference here is in the distinction between Quantity and Quantity Kind. The qudt notion of Quantity corresponds well to the value subset of PATO. It is even compatible with realism, for those who care. qudt Quantities can be thought of as mind-independent. However, it is not BFO compliant in that it forces a determinable-determinant distinction (recall in PATO values are subclasses of attributes). This is a topic larger than this ticket. From a pragmatic POV, we can note two things: (1) a shadowing strategy similar to the one above can be followed, and (2) many PATO values are ontological oddities like 'increased length' that are best represented relationally, for example as representing some kind of change between two quantities.
Naming Conventions
Of note there are naming convention differences. qudt uses captitalization, and sometimes arbitrarily CamelCases's.
These could easily be handled with an automatic rewrite (were we to decide to use qudt directly)
There is also the use of labels such as 'Biology' for qudt:Biology when the more appropriate label would be 'Biological Quality Kind'. Again, these could be ignored or rewritten - an annoying but fundamentally minor issue.
Biology-specific quantities in UO
qudt has a class 'Biology' (think of this as being labeled 'Biological Quantity Kind', see above). It has only 4 instances:
Leaving aside the fact these are clearly not instances of 'Biology', this seems a bit ad-hoc. There is no axiomatization of HeartRate, no connection to a generic rate (and thus no abstraction connecting HeartRate and 'Respiratory Rate')
It seems best to leave the biological part alone. We have coverage of this in OBA using EQ patterns.
Most bio users would therefore prefer to use OBA for biological quantities (our strength) and instead leverage qudt for physical, chemical non-bio quantities (their strength).
Measurements vs values
ud:QuantityValue has some relationship to IAO measurement datum, but the difference is that we could have multiple measurements of the same quantity or value. There is not a direct cognate of QuantityValue in IAO or OBI at the moment.
Steps forward
For practical reasons, PATO classes are likely to stick around. However, qudt with it's better support of physical/chemical qualities may form a better basis on which to axiomatize PATO.
Some users may wish to ditch UO altogether, but at the least there should be some kind of linkage between these.
= R Valuepattern aboveThe text was updated successfully, but these errors were encountered: