Infer SQL queries from plain-text questions and table headers.
Requirements:
- install
docker - install
curl(or, if you're feeling brave, asql) - Make sure docker allows at least 3GB of RAM (see
Docker>Preferences>Advancedor equivalent) for SQLova, or 5GB for IRNet or ValueNet.
I take pretrained models published along with academic papers, and do whatever it takes to make them testable on fresh data (academic work often omits that, with code tied to a particular benchmark dataset). I spend days tracking down and patching obscure data preprocessing steps so you don't have to.
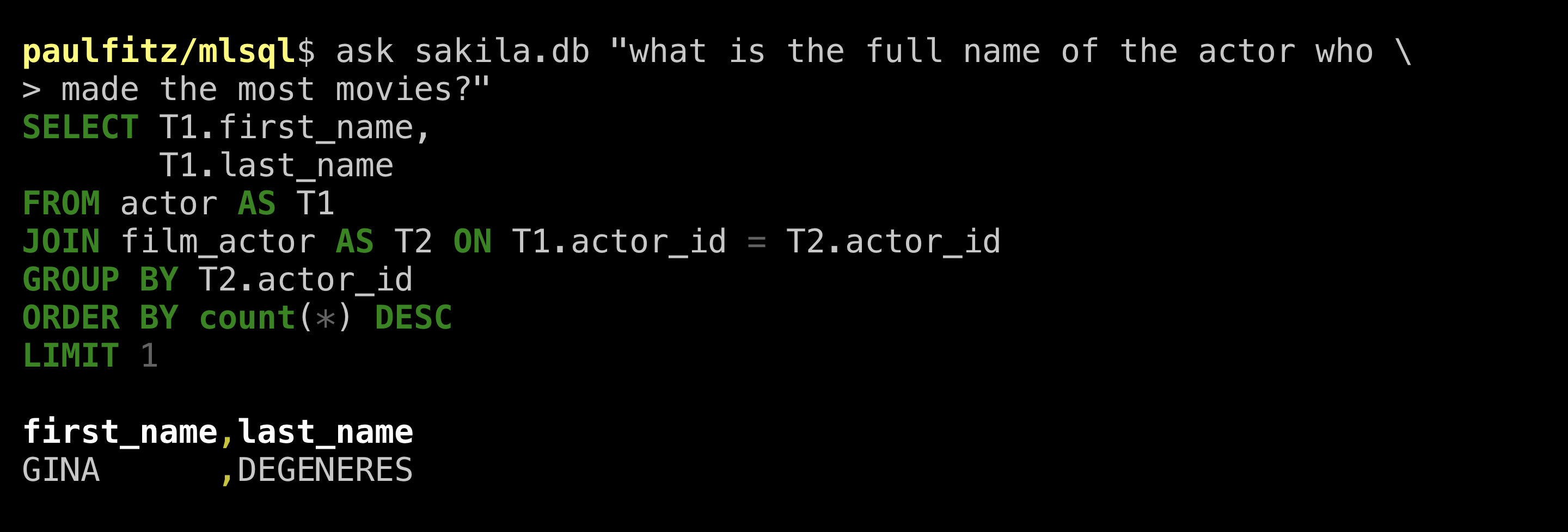
So far I've packaged three models:
- SQLova. Works on single tables.
- ValueNet. Works on multiple tables, and makes an effort to predict parameters.
- IRNet. Works on multiple tables, but doesn't predict parameters.
In each case, I've mangled the original network somewhat, so if they interest you do follow up with the original sources.
This wraps up a published pretrained model for SQLova (https://github.com/naver/sqlova/).
Fetch and start SQLova running as an api server on port 5050:
docker run --name sqlova -d -p 5050:5050 paulfitz/sqlova
Be patient, the image is about 4.2GB. Once it is running, it'll take a few seconds to load models and then you can start asking questions about CSV tables. For example:
curl -F "csv=@bridges.csv" -F "q=how long is throgs neck" localhost:5050
# {"answer":[1800],"params":["throgs neck"],"sql":"SELECT (length) FROM bridges WHERE bridge = ?"}
This is using the sample bridges.csv included in this repo.
| bridge | designer | length |
|---|---|---|
| Brooklyn | J. A. Roebling | 1595 |
| Manhattan | G. Lindenthal | 1470 |
| Williamsburg | L. L. Buck | 1600 |
| Queensborough | Palmer & Hornbostel | 1182 |
| Triborough | O. H. Ammann | 1380,383 |
| Bronx Whitestone | O. H. Ammann | 2300 |
| Throgs Neck | O. H. Ammann | 1800 |
| George Washington | O. H. Ammann | 3500 |
Here are some examples of the answers and sql inferred for plain-text questions about this table:
| question | answer | sql |
|---|---|---|
| how long is throgs neck | 1800 | SELECT (length) FROM bridges WHERE bridge = ? ['throgs neck'] |
| who designed the george washington | O. H. Ammann | SELECT (designer) FROM bridges WHERE bridge = ? ['george washington'] |
| how many bridges are there | 8 | SELECT count(bridge) FROM bridges |
| how many bridges are designed by O. H. Ammann | 4 | SELECT count(bridge) FROM bridges WHERE designer = ? ['O. H. Ammann'] |
| which bridge are longer than 2000 | Bronx Whitestone, George Washington | SELECT (bridge) FROM bridges WHERE length > ? ['2000'] |
| how many bridges are longer than 2000 | 2 | SELECT count(bridge) FROM bridges WHERE length > ? ['2000'] |
| what is the shortest length | 1182 | SELECT min(length) FROM bridges |
With the players.csv sample from WikiSQL:
| Player | No. | Nationality | Position | Years in Toronto | School/Club Team |
|---|---|---|---|---|---|
| Antonio Lang | 21 | United States | Guard-Forward | 1999-2000 | Duke |
| Voshon Lenard | 2 | United States | Guard | 2002-03 | Minnesota |
| Martin Lewis | 32, 44 | United States | Guard-Forward | 1996-97 | Butler CC (KS) |
| Brad Lohaus | 33 | United States | Forward-Center | 1996 | Iowa |
| Art Long | 42 | United States | Forward-Center | 2002-03 | Cincinnati |
| John Long | 25 | United States | Guard | 1996-97 | Detroit |
| Kyle Lowry | 3 | United States | Guard | 2012-present | Villanova |
| question | answer | sql |
|---|---|---|
| What number did the person playing for Duke wear? | 21 | SELECT (No.) FROM players WHERE School/Club Team = ? ['duke'] |
| Who is the player that wears number 42? | Art Long | SELECT (Player) FROM players WHERE No. = ? ['42'] |
| What year did Brad Lohaus play? | 1996 | SELECT (Years in Toronto) FROM players WHERE Player = ? ['brad lohaus'] |
| What country is Voshon Lenard from? | United States | SELECT (Nationality) FROM players WHERE Player = ? ['voshon lenard'] |
Some questions about iris.csv:
| question | answer | sql |
|---|---|---|
| what is the average petal width for virginica | 2.026 | SELECT avg(Petal.Width) FROM iris WHERE Species = ? ['virginica'] |
| what is the longest sepal for versicolor | 7.0 | SELECT max(Sepal.Length) FROM iris WHERE Species = ? ['versicolor'] |
| how many setosa rows are there | 50 | SELECT count(col0) FROM iris WHERE Species = ? ['setosa'] |
There are plenty of types of questions this model cannot answer (and that aren't covered in the dataset it is trained on, or in the sql it is permitted to generate).
This wraps up a published pretrained model for ValueNet (https://github.com/brunnurs/valuenet).
Fetch and start ValueNet running as an api server on port 5050:
docker run --name valuenet -d -p 5050:5050 paulfitz/valuenet
You can then ask questions of individual csv files as before, or several csv files
(just repeat -F "csv=@fileN.csv") or a simple sqlite db with tables related by foreign keys.
In this last case, the model can answer using joins.
curl -F "sqlite=@companies.sqlite" -F "q=who is the CEO of Omni Cooperative" localhost:5050
# {"answer":[["Dracula"]], "sql":"SELECT T1.name FROM people AS T1 JOIN organizations AS T2 \
# ON T1.id = T2.ceo_id WHERE T2.company = 'Omni Cooperative'"}
curl -F "csv=@bridges.csv" -F "q=how many designers are there?" localhost:5050
# {"answer":[[5]],"sql":"SELECT DISTINCT count(DISTINCT T1.designer) FROM bridges AS T1"}
curl -F "csv=@bridges.csv" -F "csv=@airports.csv" -F "q=how many designers are there?" localhost:5050
# same answer
curl -F "csv=@bridges.csv" -F "csv=@airports.csv" -F "q=what is the name of the airport with the highest latitude?" localhost:5050
# {"answer":[["Disraeli Inlet Water Aerodrome"]],
# "sql":"SELECT T1.name FROM airports AS T1 ORDER BY T1.latitude_deg DESC LIMIT 1"}
I've includes material to convert user tables into the form needed to query them. Don't judge the network by its quality here, go do a deep dive with the original - I've deviated from the original in important respects, including how named entity recognition is done.
I've written up some experiments with ValueNet.
This wraps up a published pretrained model for IRNet (https://github.com/microsoft/IRNet). Upstream released a better model after I packaged this, so don't judge the model by playing with it here.
Fetch and start IRNet running as an api server on port 5050:
docker run --name irnet -d -p 5050:5050 -v $PWD/cache:/cache paulfitz/irnet
Be super patient! Especially on the first run, when a few large models need to be downloaded and unpacked.
You can then ask questions of individual csv files as before, or several csv files
(just repeat -F "csv=@fileN.csv") or a simple sqlite db with tables related by foreign keys.
In this last case, the model can answer using joins.
curl -F "sqlite=@companies.sqlite" -F "q=what city is The Firm headquartered in?" localhost:5050
# Answer: SELECT T1.city FROM locations AS T1 JOIN organizations AS T2 WHERE T2.company = 1
curl -F "sqlite=@companies.sqlite" -F "q=who is the CEO of Omni Cooperative" localhost:5050
# Answer: SELECT T1.name FROM people AS T1 JOIN organizations AS T2 WHERE T2.company = 1
curl -F "sqlite=@companies.sqlite" -F "q=what company has Dracula as CEO" localhost:5050
# Answer: SELECT T1.company FROM organizations AS T1 JOIN people AS T2 WHERE T2.name = 1
(Note there's no value prediction, so e.g. the where clauses are = 1 rather than something
more useful).
Curl can be replaced by Postman for those who like that. Here's a working set-up:

I hope to track research in the area and substitute in models as they become available:
- Photon by the SalesForce group is a good live demo of text-to-SQL.