-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
1 changed file
with
262 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,262 @@ | ||
| --- | ||
| title: 糟糕,我一发布怎么服务都504了 | ||
| categories: [K8S] | ||
| date: 2024-6-2 | ||
| keywords: ['网络','trouble shooting','Ingress','K8S','Controller manager'] | ||
| tags: | ||
| - 网络 | ||
| - trouble shooting | ||
| - Ingress | ||
| - K8S | ||
| - Controller manager | ||
| --- | ||
| # 背景 | ||
|
|
||
| 业务反馈发布的时候会偶尔会有504,重新发布也不行。重建Pod也不行,但是等一段时间就会自动恢复。 | ||
|
|
||
|  | ||
|
|
||
| 上图是一个服务的504的一个情况。从历史的指标跟 Ingress 日志来看,我们能够得到一个清晰的结论。已经销毁了的 Pod 的 IP 并没有被 Ingress 摘掉。 Pod A 在17:35就已经销毁了,但是持续到 17:37 Ingress 还在向已经销毁了的 Pod A 发送流量。 | ||
| <!-- more --> | ||
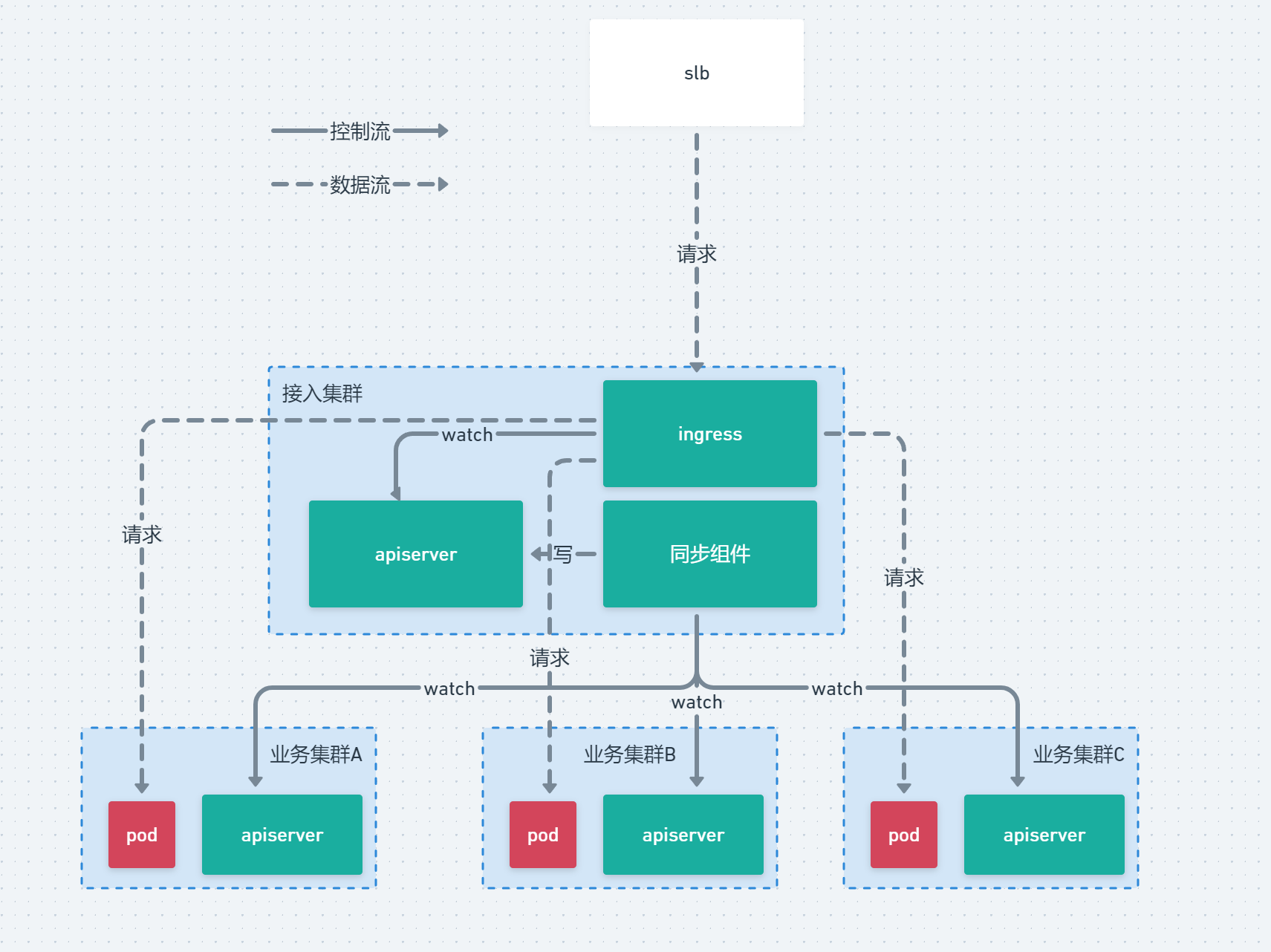
| # 流量接入链路 | ||
|
|
||
| 流量链路比较长,涉及的组件也比较多,所以需要提前简单的描述一下我们的流量链路。 | ||
|
|
||
|  | ||
|
|
||
| 从整体上看我们实现了一套多集群的Ingress,采用如下手段: | ||
|
|
||
| - 将业务集群的 endpoint 同步到接入集群 | ||
| - 在接入集群创建不带 selector 的 service 的方式通过名称与endpoint关联 | ||
| - 在接入集群下发 ingress 规则,并且关联到接入集群的 service | ||
|
|
||
| 从而不修改Nginx Ingress Controller 代码的方式达到一套Ingress能够支持多集群的效果。 | ||
|
|
||
| 流量从 slb → ingress → 业务Pod 整体流量大体是这个样子走的。 | ||
|
|
||
| 还有的是我们因为没有使用 ServiceIP 所以我们的 ServiceIP 都设置为了 None 即 Headless Service 的形式。 | ||
|
|
||
| # 排查 | ||
|
|
||
| 这里面可能出问题的地方有: | ||
|
|
||
| 1. Nginx Ingress Controller | ||
| 2. 同步组件异常/性能问题 | ||
| 3. APIServer 性能问题 | ||
| 4. Controller manager 性能问题 | ||
|
|
||
| 作为一个正常的人来讲,除了绞尽脑汁尝试把这个锅甩给别的团队以外[狗头]。我们优先需要排查的应当是自己的组件。 | ||
|
|
||
| 改动了一下我们同步组件的代码,增加了更详细的日志, 打印同步的 endpoint 的细则跟时间。 | ||
|
|
||
| 另外写了一个组件,代码 watch 各个集群的 endpoint 的变更,打印观测到变更的具体时间跟IP。 | ||
|
|
||
| 几天后另一个业务遇到了该问题,观测了一下我们的同步组件,跟新写的组件。有如下现象: | ||
|
|
||
| - 同步组件的打印 IP 变更时间是在 Pod 销毁后很久。 | ||
| - 新写的观测 endpoint 变更的代码观测到变更的时间与差为毫秒级别。 | ||
|
|
||
| 我们现在怀疑的目光落在了 APIServer 与 Controller Manager身上。此时 同步组件 与 Nginx Ingress Controller 的嫌疑已经被洗刷了。 | ||
|
|
||
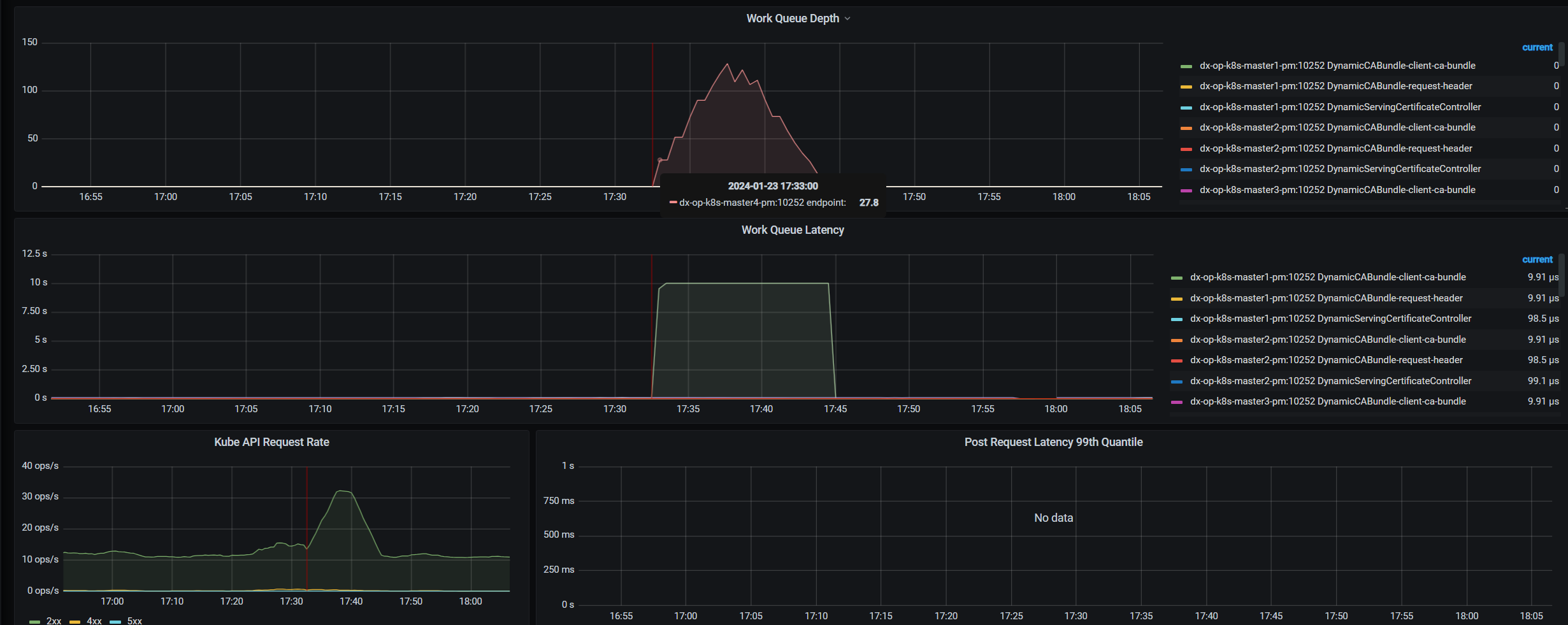
| ## controller manager堆积 | ||
|
|
||
|  | ||
|
|
||
| 我们观测到对应的时间是有 worke queue 的堆积的情况发生的。同时API Server 的 QPS升高到了30多,worke queue的延迟一直爆炸,持续到了这个queue消费完。整个过程从指标上看是持续能有10多分钟,之前业务遇到问题2分钟左右恢复,单纯是因为运气好,赶上了最末尾的2分钟。 | ||
|
|
||
| 这种情况我们优先怀疑是写 APIServer 被限流了,默认 Controller Manager 读写 API Server 都是带限流的,我们首先考虑提高限流的大小,让他快速的消费。 | ||
|
|
||
| 配置调整如下: | ||
|
|
||
| ```bash | ||
| --concurrent-endpoint-syncs=30 | ||
| --kube-api-burst=120 | ||
| --kube-api-qps=100 | ||
| ``` | ||
|
|
||
| 给 APIServer 上点强度,测试结果并不是非常让人满意。相比之前出问题的时间从12分钟级别降到了5分钟左右的级别。 | ||
|
|
||
|  | ||
|
|
||
| 这个结果并不太能让我们接受。我们试图开始寻找根因。到底是为什么会触发大规模的endpoint同步? 翻了一下代码大体上有2个部分。 | ||
|
|
||
| ```bash | ||
| func (e *EndpointController) Run(workers int, stopCh <-chan struct{}) { | ||
| defer utilruntime.HandleCrash() | ||
| defer e.queue.ShutDown() | ||
|
|
||
| klog.Infof("Starting endpoint controller") | ||
| defer klog.Infof("Shutting down endpoint controller") | ||
|
|
||
| if !cache.WaitForNamedCacheSync("endpoint", stopCh, e. POD sSynced, e.servicesSynced, e.endpointsSynced) { | ||
| return | ||
| } | ||
|
|
||
| for i := 0; i < workers; i++ { | ||
| go wait.Until(e.worker, e.workerLoopPeriod, stopCh) | ||
| } | ||
| // 这个func 会触发大规模同步,但是只有controller第一次启动时会执行到 | ||
| go func() { | ||
| defer utilruntime.HandleCrash() | ||
| e.checkLeftoverEndpoints() | ||
| }() | ||
|
|
||
| <-stopCh | ||
| } | ||
| ``` | ||
| 上边这段是启动的时候会执行一次的。 | ||
| ```bash | ||
| func NewEndpointController( POD Informer coreinformers. POD Informer, serviceInformer coreinformers.ServiceInformer, | ||
| endpointsInformer coreinformers.EndpointsInformer, client clientset.Interface, endpointUpdatesBatchPeriod time.Duration) *EndpointController { | ||
| e := &EndpointController{ | ||
| client: client, | ||
| queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "endpoint"), | ||
| workerLoopPeriod: time.Second, | ||
| } | ||
| // 这个注册的informer如果有大规模更新会发生大规模同步 | ||
| serviceInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{ | ||
| AddFunc: e.onServiceUpdate, | ||
| UpdateFunc: func(old, cur interface{}) { | ||
| e.onServiceUpdate(cur) | ||
| }, | ||
| DeleteFunc: e.onServiceDelete, | ||
| }) | ||
| e.serviceLister = serviceInformer.Lister() | ||
| e.servicesSynced = serviceInformer.Informer().HasSynced | ||
| // 这个注册的informer如果有大规模更新会发生大规模同步 | ||
| POD Informer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{ | ||
| AddFunc: e.add POD , | ||
| UpdateFunc: e.update POD , | ||
| DeleteFunc: e.delete POD , | ||
| }) | ||
|
|
||
| return e | ||
| } | ||
| ``` | ||
| 上边这段只有大规模更新才会触发大规模同步。 | ||
| ### Controller manager 周期性重入队 | ||
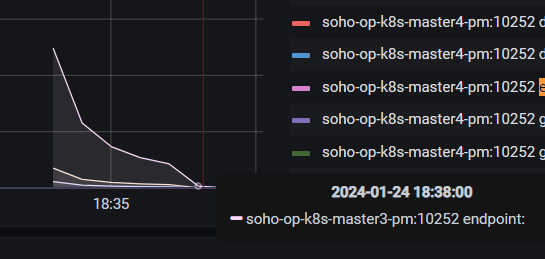
| 但是这两个并不太像是我们的场景,因为我们集群根本不会有大到消费不完的变更。所以另外一个可能就是周期的重新入队。我们把指标拉长了看。 | ||
|  | ||
| | 发生时间 | 差值 | | ||
| | --- | --- | | ||
| | 01-19 3:40 | - | | ||
| | 01-19 20:10 | 16:30 | | ||
| | 01-20 12:30 | 16:20 | | ||
| | 01-21 5:00 | 16:30 | | ||
| | 01-21 21:20 | 16:20 | | ||
| 大体上我们能推断16个多小时就会出现一次,所以是不是是 informer 的 resync 的时间 | ||
| ```bash | ||
| func RecommendedDefaultGenericControllerManagerConfiguration(obj *kubectrlmgrconfigv1alpha1.GenericControllerManagerConfiguration) { | ||
| if obj.MinResyncPeriod == zero { | ||
| // 这里默认是 12小时同步一次 | ||
| obj.MinResyncPeriod = metav1.Duration{Duration: 12 * time.Hour} | ||
| } | ||
| } | ||
| // 最终调用的时候random 了一个随机因子,所以可能会是16.5h 左右是合理的 | ||
| func ResyncPeriod(c *config.CompletedConfig) func() time.Duration { | ||
| return func() time.Duration { | ||
| factor := rand.Float64() + 1 | ||
| return time.Duration(float64(c.ComponentConfig.Generic.MinResyncPeriod.Nanoseconds()) * factor) | ||
| } | ||
| } | ||
| ``` | ||
| 根据这段代码我们确实就是遇到了这个大规模同步的问题了。但是问题是正常情况下即使是重新入队的这个操作,我们也会去更新有变化的 endpoint,没有的做一个检查基本就跳过了。但是我们遇到的这个,看起来是更新了很多 endpoint,因为endpoint PUT的调用一直处于满的状态。如下图所示: | ||
| 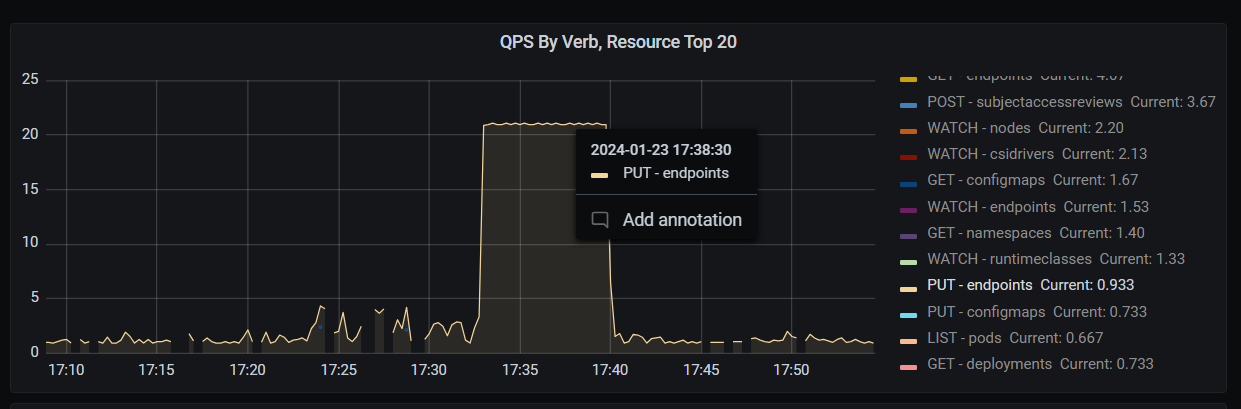 | ||
| 我们看一下一次这个问题发生的时候会有多少的 endpoint PUT 打开日志我们统计一波。 | ||
|  | ||
| 从日志上看我们有大概12954次的PUT | ||
| 我们看下我们的 endpoint 的数量 | ||
| ```bash | ||
| ❯ k get ep -A |wc -l | ||
| 12989 | ||
| ``` | ||
| 数量几乎相等。所以大概率的情况下我们的 endpoint 会被全部更新一个遍,这种问题简直难以想象。大概率是一个bug。有这种关键信息作为佐证的话,应该是 bug 能查询到一些结果。 | ||
| 找到了一个文章 [https://engineering.dollarshaveclub.com/kubernetes-fixing-delayed-service-endpoint-updates-fd4d0a31852c](https://engineering.dollarshaveclub.com/kubernetes-fixing-delayed-service-endpoint-updates-fd4d0a31852c) 但是没有定位原因。应该是相同的问题。除此之外并没有看到其他类似的问题的描述了。 | ||
| ### 二分法找bug | ||
| 可能因为关键词选择的不对,或者怎样,不管是github的issue 还是 google 都没找到更进一步的信息了,但是我们可以看下社区是否已经解决了该问题。我们出问题的集群是IDC的集群版本比较低是1.17.3 云上的版本是1.22+的。所以我们观测下云上的集群版本是否有类似的问题即可确定社区是否已经做了修复。 | ||
| 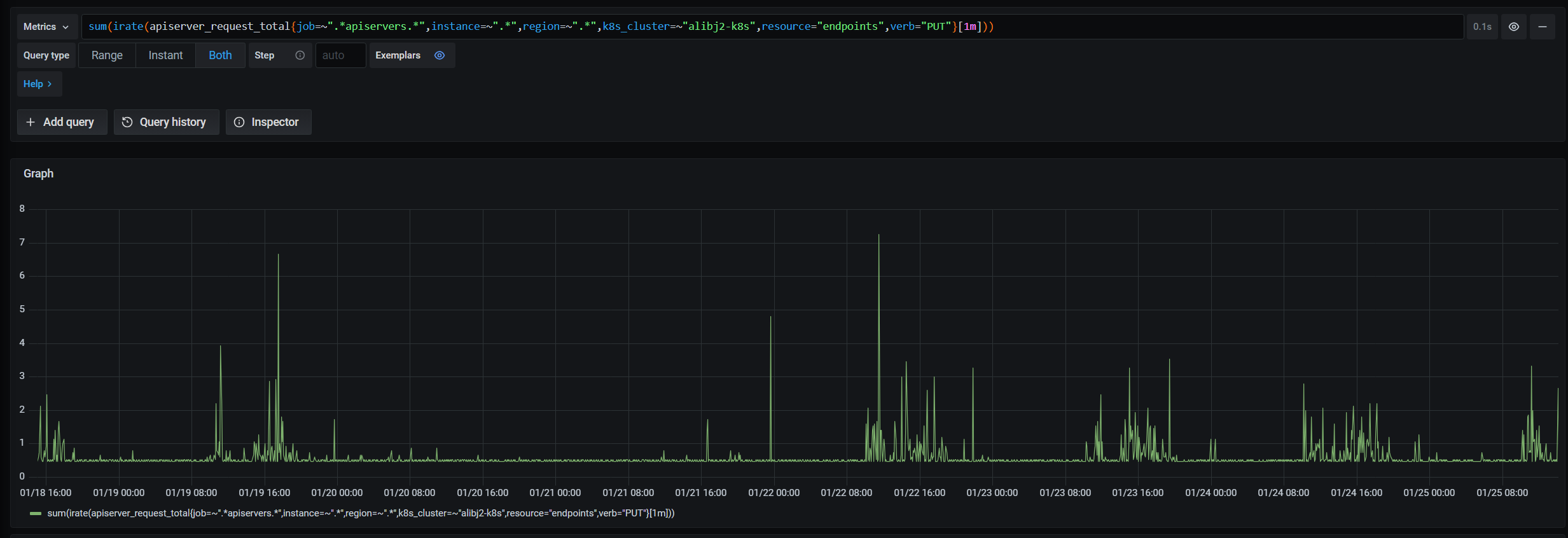 | ||
| 云上的版本非常稳定,所以肯定是修了,一定是我的关键字找的不对。所以只能去把endpoint相关的代码了。 | ||
| 我们在github打开 k8s endpoint controller 的代码,切换到1.22版本,然后看commit,看看哪些commit 1.17~1.22 之间的 endpoint 相关的代码可能相关。运气比较好,只看了3个就找到了。 | ||
| 具体PR如下:[https://github.com/kubernetes/kubernetes/pull/94112/files](https://github.com/kubernetes/kubernetes/pull/94112/files) | ||
| 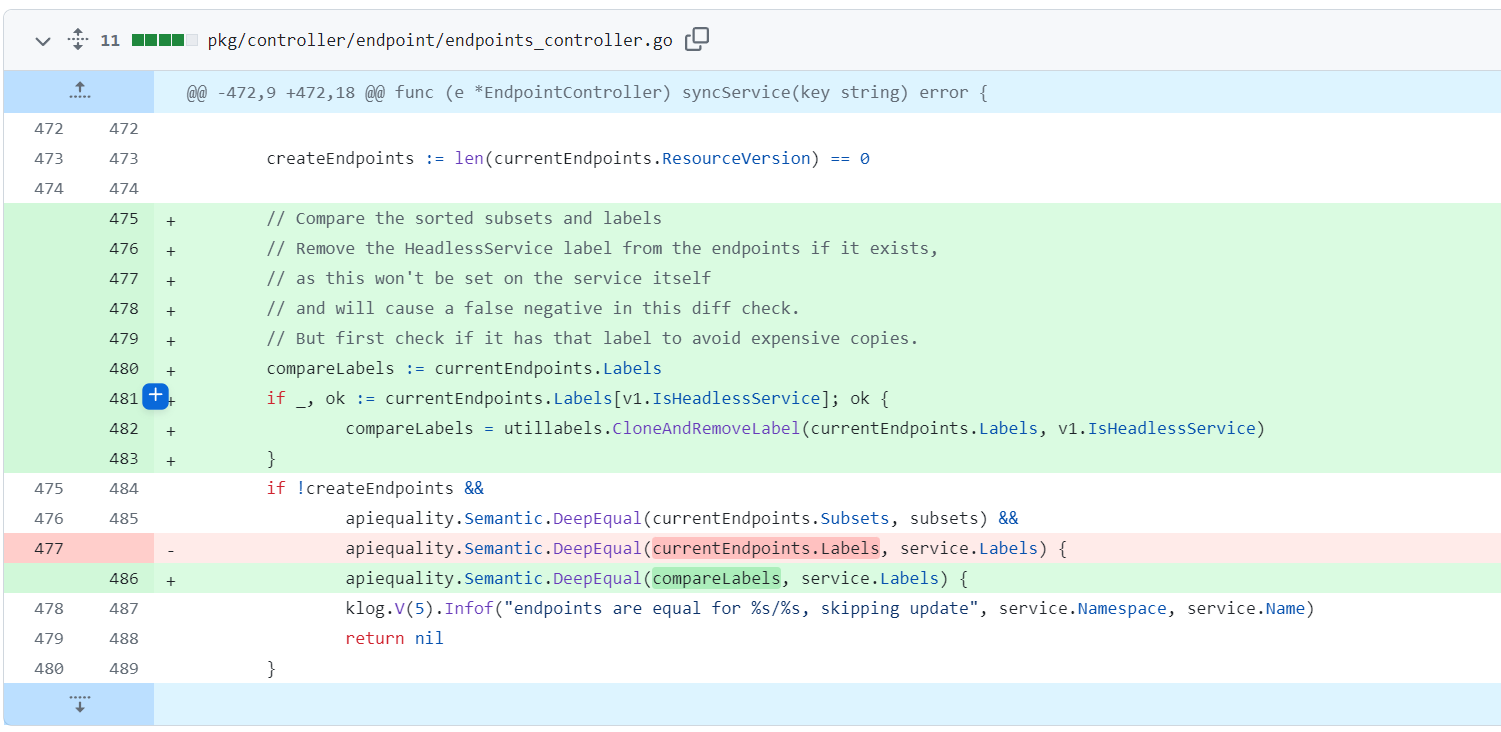 | ||
| 从代码中我们可以看到是移除了 endpoint label 中的 headless service 的 label,应该是这个label是endpoint 特有的,而service没有,所以比较会不相等。比较不相等就会不会走跳过的逻辑,会走更新的逻辑。 | ||
| 我们看下这个endpoint跟svc的label有什么不同: | ||
| ```bash | ||
| apiVersion: v1 | ||
| kind: Endpoints | ||
| metadata: | ||
| creationTimestamp: "2024-01-25T09:38:49Z" | ||
| labels: | ||
| service.kubernetes.io/headless: "" | ||
| name: zr-test | ||
| namespace: test | ||
| resourceVersion: "261135910" | ||
| selfLink: /api/v1/namespaces/test/endpoints/zr-test | ||
| uid: b1c05ded-1d31-40ec-b065-5373c7d2e496 | ||
| ------------- | ||
| apiVersion: v1 | ||
| kind: Service | ||
| metadata: | ||
| creationTimestamp: "2024-01-25T09:30:00Z" | ||
| name: zr-test | ||
| namespace: test | ||
| resourceVersion: "261104586" | ||
| selfLink: /api/v1/namespaces/test/services/zr-test | ||
| uid: 39d70c7c-a3db-462a-9e87-60bd3d490be8 | ||
| spec: | ||
| clusterIP: None | ||
| ports: | ||
| - name: http | ||
| port: 80 | ||
| protocol: TCP | ||
| targetPort: 8080 | ||
| selector: | ||
| yfd_http_tag: "" | ||
| yfd_service: zr-test | ||
| yfd_traffic: "true" | ||
| sessionAffinity: None | ||
| type: ClusterIP | ||
| status: | ||
| loadBalancer: {} | ||
| ``` | ||
| service 没有 label, endpoint 多了一个 service.kubernetes.io/headless: "" | ||
| 所以比较会不相等。感觉之前之所以搜不到是因为用 headless service 的规模应该不是很大。所以大家都没有反馈这个问题。而我们线上的1万多个 service 几乎全部都是 headless service,所以才掉到这个大坑里面了。 | ||
| # 修复 | ||
| 我们的版本比较老了,升级版本可能也推进比较慢,关键的改动不到10行我们选择自己backport到我们的版本上面。 | ||
| # 总结 | ||
| 1. 如果把社区的组件的指标都看一圈可能就不用在自己的代码里面加日志了。后续可以优先看一波。 | ||
| 2. 这套集群都在线上跑了3年了才发现这个问题,感觉其实或许大概,不修也行? |