卡卡字幕助手(VideoCaptioner)操作简单且无需高配置,支持网络调用和本地离线(支持调用GPU)两种方式进行语音识别,利用可用通过大语言模型进行字幕智能断句、校正、翻译,字幕视频全流程一键处理!为视频配上效果惊艳的字幕。
- 🎯 无需GPU即可使用强大的语音识别引擎,生成精准字幕
- ✂️ 基于 LLM 的智能分割与断句,字幕阅读更自然流畅
- 🔄 AI字幕多线程优化与翻译,调整字幕格式、表达更地道专业
- 🎬 支持批量视频字幕合成,提升处理效率
- 📝 直观的字幕编辑查看界面,支持实时预览和快捷编辑
- 🤖 消耗模型 Token 少,且内置基础 LLM 模型,保证开箱即用

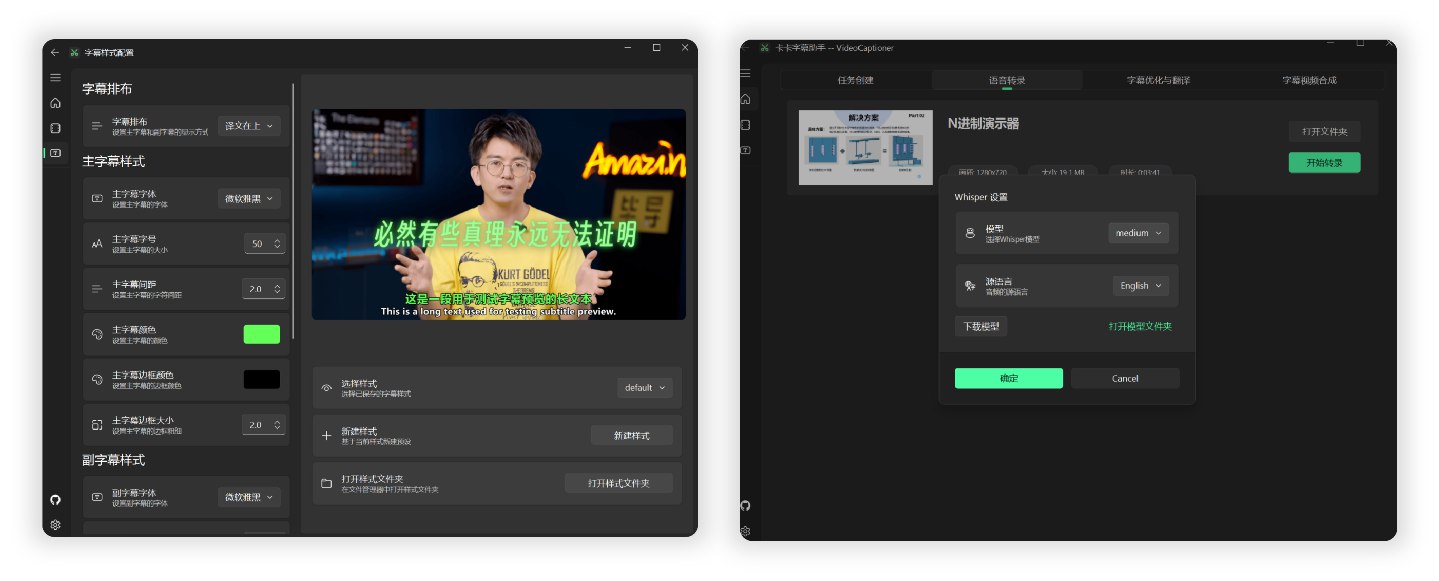
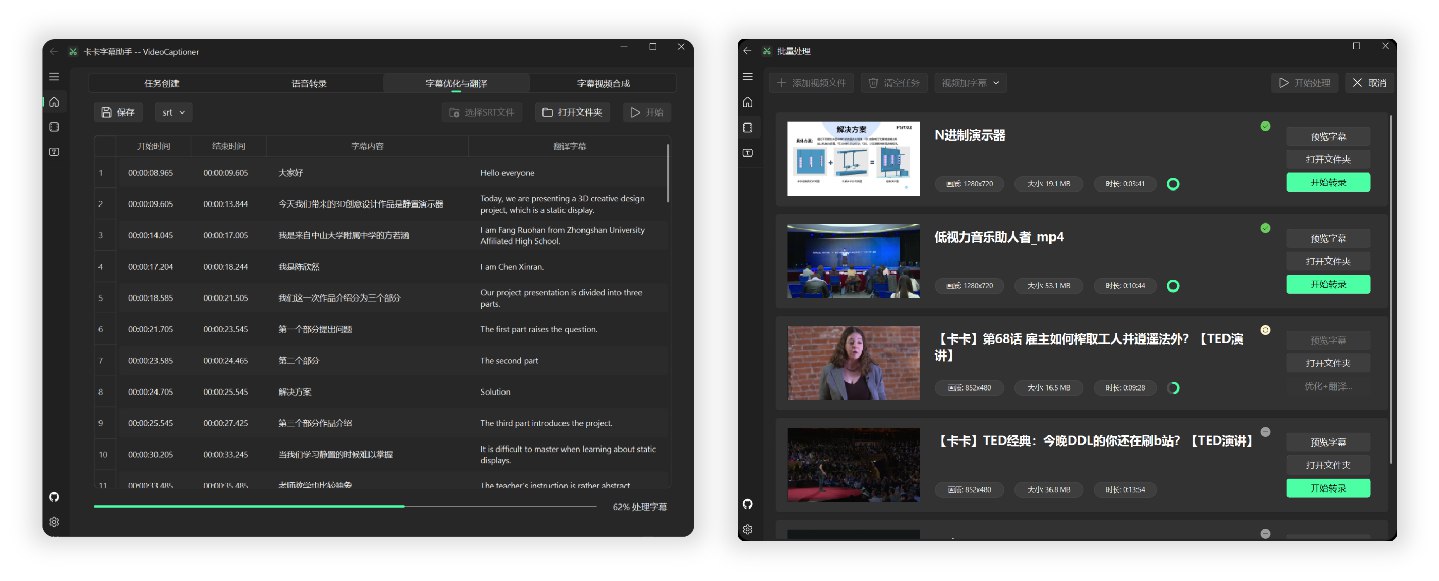
全流程处理一个14分钟1080P的 B站英文 TED 视频,调用本地 Whisper 模型进行语音识别,使用 gpt-4o-mini 模型优化和翻译为中文,总共消耗时间约 4 分钟。
近后台计算,模型优化和翻译消耗费用不足 ¥0.01(以OpenAI官方价格为计算)
具体字幕和视频合成的效果的测试结果图片,请参考 TED视频测试
软件较为轻量,打包大小不足 60M,已集成所有必要环境,下载后可直接运行。
提示:每一个步骤均支持单独处理,均支持文件拖拽。
MacOS 用户
由于本人缺少 Mac,所以没法测试和打包,暂无法提供 MacOS 的可执行程序。
Mac 用户请自行使用下载源码和安装 python 依赖运行。(本地 Whisper 功能暂不支持 MacOS)
- 安装 ffmpeg 和 Aria2 下载工具
brew install ffmpeg
brew install aria2- 克隆项目
git clone https://github.com/WEIFENG2333/VideoCaptioner.git- 安装依赖
pip install -r requirements.txt- 运行程序
python main.py软件充分利用大语言模型(LLM)在理解上下文方面的优势,对语音识别生成的字幕进一步处理。有效修正错别字、统一专业术语,让字幕内容更加准确连贯,为用户带来出色的观看体验!
- 支持国内外主流视频平台(B站、Youtube等)
- 自动提取视频原有字幕处理
- 提供多种接口在线识别,效果媲美剪映(免费、高速)
- 支持本地Whisper模型(保护隐私、可离线)
- 自动优化专业术语、代码片段和数学公式格式
- 上下文进行断句优化,提升阅读体验
- 支持文稿提示,使用原有文稿或者相关提示优化字幕断句
- 结合上下文的智能翻译,确保译文兼顾全文
- 通过Prompt指导大模型反思翻译,提升翻译质量
- 使用序列模糊匹配算法、保证时间轴完全一致
- 丰富的字幕样式模板(科普风、新闻风、番剧风等等)
- 多种格式字幕视频(SRT、ASS、VTT、TXT)
| 配置项 | 说明 |
|---|---|
| 内置模型 | 软件内置基础大语言模型(gpt-4o-mini),无需配置即可使用 |
| API支持 | 支持标准 OpenAI API 格式。兼容 SiliconCloud、DeepSeek 、 Ollama 等。 配置方法请参考配置文档 |
推荐模型: 追求更高质量可选用 Claude-3.5-sonnet 或 gpt-4o
Whisper 版本有 WhisperCpp 和 fasterWhisper 两种,后者效果更好,都需要自行在软件内下载模型。
| 模型 | 磁盘空间 | 内存占用 | 说明 |
|---|---|---|---|
| Tiny | 75 MiB | ~273 MB | 转录很一般,仅用于测试 |
| Small | 466 MiB | ~852 MB | 英文识别效果已经不错 |
| Medium | 1.5 GiB | ~2.1 GB | 中文识别建议至少使用此版本 |
| Large-v1/v2 | 2.9 GiB | ~3.9 GB | 效果好,配置允许情况推荐使用 |
| Large-v3 | 2.9 GiB | ~3.9 GB | 社区反馈可能会出现幻觉/字幕重复问题 |
注:以上模型国内网络可直接在软件内下载;支持GPU也支持核显调用。
- 在"字幕优化与翻译"页面,包含"文稿匹配"选项,支持以下一种或者多种内容,辅助校正字幕和翻译:
| 类型 | 说明 | 填写示例 |
|---|---|---|
| 术语表 | 专业术语、人名、特定词语的修正对照表 | 机器学习->Machine Learning 马斯克->Elon Musk 打call -> 应援 图灵斑图 公交车悖论 |
| 原字幕文稿 | 视频的原有文稿或相关内容 | 完整的演讲稿、课程讲义等 |
| 修正要求 | 内容相关的具体修正要求 | 统一人称代词、规范专业术语等 填写内容相关的要求即可,示例参考 |
- 如果需要文稿进行字幕优化辅助,全流程处理时,先填写文稿信息,再进行开始任务处理
- 注意: 使用上下文参数量不高的小型LLM模型时,建议控制文稿内容在1千字内,如果使用上下文较大的模型,则可以适当增加文稿内容。
| 接口名称 | 支持语言 | 运行方式 | 说明 |
|---|---|---|---|
| B接口 | 仅支持中文、英文 | 在线 | 免费、速度较快 |
| J接口 | 仅支持中文、英文 | 在线 | 免费、速度较快 |
| WhisperCpp | 中文、日语、韩语、英文等 99 种语言,外语效果较好 | 本地 | 需要下载转录模型 中文建议medium以上模型 英文等使用较小模型即可达到不错效果。 |
| fasterWhisper | 中文、英文等多99种语言,外语效果优秀,时间轴更准确 | 本地 | 需要下载程序和转录模型 支持CUDA,速度更快,转录准确。 建议优先使用 |
但你需要URL下载功能时,如果遇到以下情况:
- 下载的视频需要登录信息
- 只能下载较低分辨率的视频
- 网络条件较差时需要验证
- 请参考 Cookie 配置说明 获取Cookie信息,并将cookies.txt文件放置到软件的
AppData目录下,即可正常下载高质量视频。
程序简单的处理流程如下:
语音识别 -> 字幕断句 -> 字幕优化翻译(可选) -> 字幕视频合成
安装软件的主要目录结构说明如下:
VideoCaptioner/
├── runtime/ # 运行环境目录(不用更改)
├── resources/ # 软件资源文件目录(界面、图标等,不用更改)
├── work-dir/ # 工作目录,处理完成的视频和字幕文件保存在这里
├── AppData/ # 应用数据目录
├── cache/ # 缓存目录,临时数据
├── models/ # 存放 Whisper 模型文件
├── logs/ # 日志目录,记录软件运行状态
├── settings.json # 存储用户设置
└── cookies.txt # 视频平台的 cookie 信息
└── VideoCaptioner.exe # 主程序执行文件
-
字幕断句的质量对观看体验至关重要。为此我开发了 SubtitleSpliter,它能将逐字字幕智能重组为符合自然语言习惯的段落,并与视频画面完美同步。
-
在处理过程中,仅向大语言模型发送纯文本内容,不包含时间轴信息,这大大降低了处理开销。
-
在翻译环节,我们采用吴恩达提出的"翻译-反思-翻译"方法论。这种迭代优化的方式不仅确保了翻译的准确性。
作者是一名大三学生,个人能力和项目都还有许多不足,项目也在不断完善中,如果在使用过程遇到的Bug,欢迎提交 Issue 和 Pull Request 帮助改进项目。
2024.12.07
- 新增 Faster-whisper 支持,音频转字幕质量更优
- 支持Vad语音断点检测,大大减少幻觉现象
- 支持人声音分离,分离视频背景噪音
- 支持关闭视频合成
- 新增字幕最大长度设置
- 新增字幕末尾标点去除设置
- 优化和翻译的提示词优化
- 优化LLM字幕断句错误的情况
- 修复音频转换格式不一致问题
2024.11.23
- 新增 Whisper-v3 模型支持,大幅提升语音识别准确率
- 优化字幕断句算法,提供更自然的阅读体验
- 修复检测模型可用性时的稳定性问题
2024.11.20
- 支持自定义调节字幕位置和样式
- 新增字幕优化和翻译过程的实时日志查看
- 修复使用 API 时的自动翻译问题
- 优化视频工作目录结构,提升文件管理效率
2024.11.17
- 支持双语/单语字幕灵活导出
- 新增文稿匹配提示对齐功能
- 修复字幕导入时的稳定性问题
- 修复非中文路径下载模型的兼容性问题
2024.11.13
- 新增 Whisper API 调用支持
- 支持导入 cookie.txt 下载各大视频平台资源
- 字幕文件名自动与视频保持一致
- 软件主页新增运行日志实时查看
- 统一和完善软件内部功能
如果觉得项目对你有帮助,可以给项目点个Star,这将是对我最大的鼓励和支持!

