KaKa Caption Assistant
A video subtitle processing assistant based on Large Language Models (LLM), supporting speech recognition, subtitle segmentation, optimization, and translation workflow
VideoCaptioner is easy to operate and requires no high-end configuration. It supports both online and offline (GPU-enabled) speech recognition, utilizing large language models for intelligent subtitle segmentation, correction, and translation. Process video subtitles with one click for stunning subtitle effects!
- 🎯 Use powerful speech recognition engine without GPU for accurate subtitles
- ✂️ LLM-based smart segmentation for natural and fluid subtitle reading
- 🔄 Multi-threaded AI subtitle optimization and translation for idiomatic expression
- 🎬 Support batch video subtitle synthesis for improved efficiency
- 📝 Intuitive subtitle editing interface with real-time preview
- 🤖 Low model token consumption with built-in basic LLM models for out-of-box use

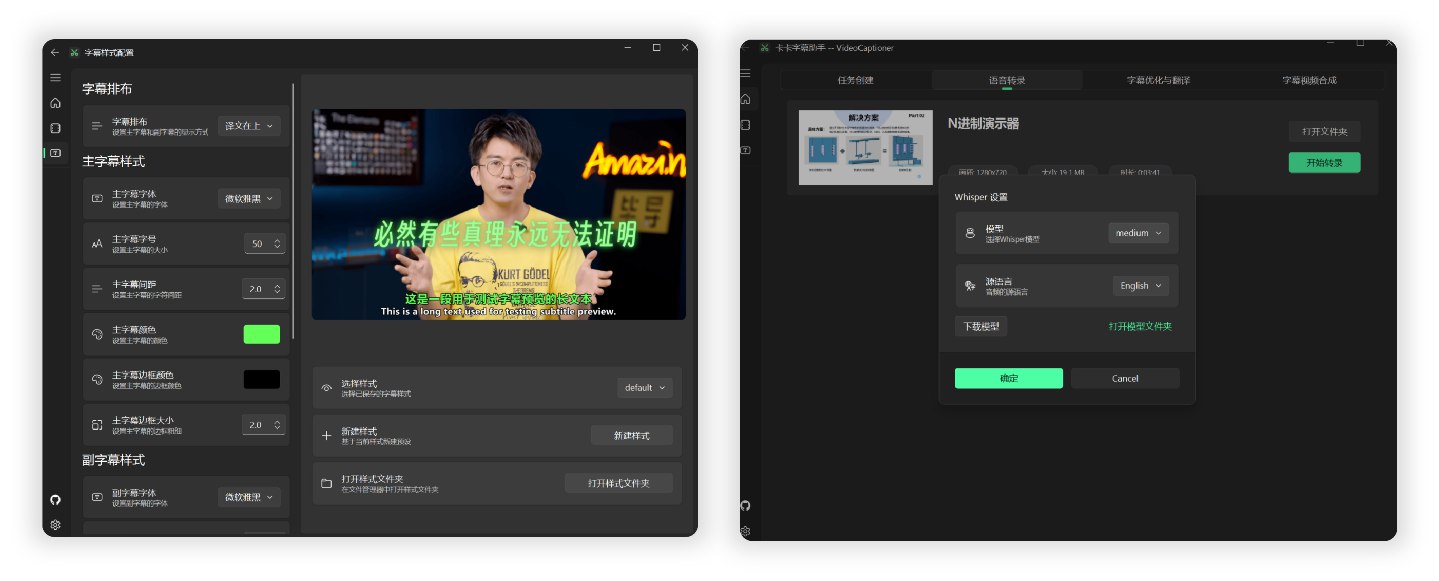
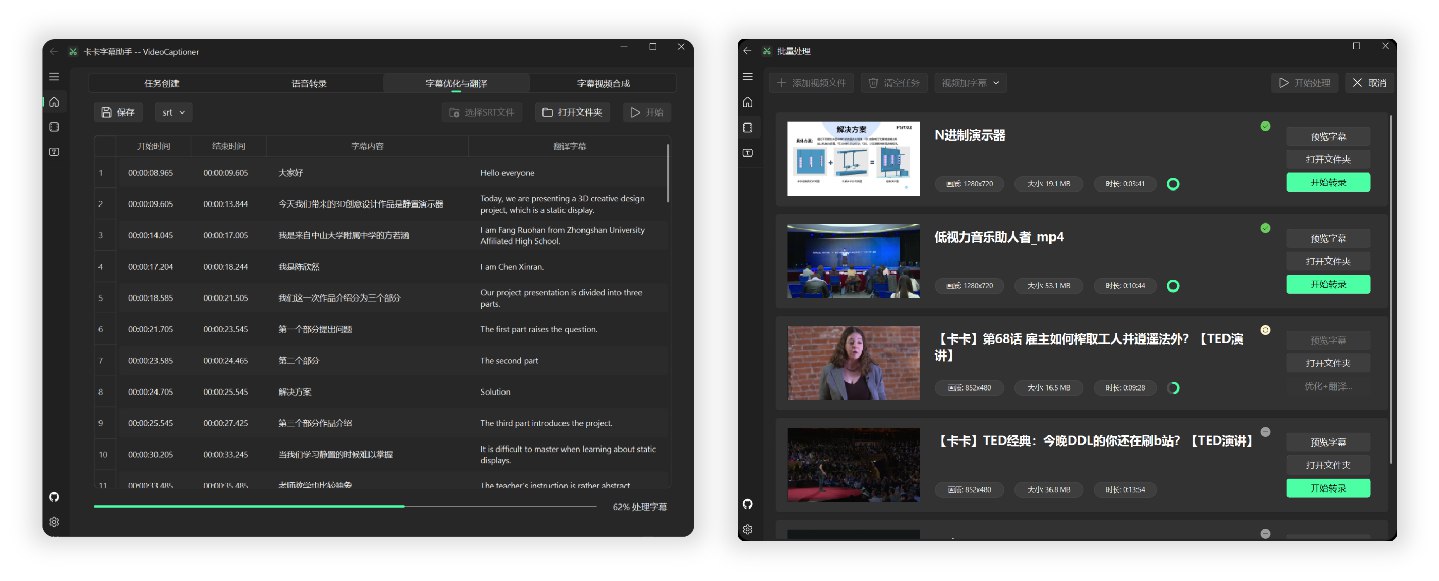
Processing a 14-minute 1080P Bilibili English TED video using local Whisper model for speech recognition and gpt-4o-mini model for optimization and Chinese translation took approximately 4 minutes.
Backend calculations show that model optimization and translation costs less than ¥0.01 (based on official pricing)
For specific subtitle and video synthesis test results, please refer to TED Video Test
The software is lightweight, with package size under 60MB, and includes all necessary environments for immediate use after download.
-
Download the latest executable from Release page. Or: LanzouCloud Download
-
Open the installation package to install
-
(Optional) LLM API configuration, choose whether to enable subtitle optimization or translation
-
Drag video files to the software window for automatic processing
Note: Each step supports individual processing and file drag-and-drop.
MacOS Users
Due to lack of Mac hardware, testing and packaging are unavailable, so no MacOS executable is provided.
Mac users please download source code and install Python dependencies to run. (Local Whisper feature currently unsupported on MacOS)
- Install ffmpeg and Aria2 download tool
brew install ffmpeg
brew install aria2- Clone the project
git clone https://github.com/WEIFENG2333/VideoCaptioner.git- Install dependencies
pip install -r requirements.txt- Run the program
python main.pyThe software leverages the contextual understanding capabilities of Large Language Models (LLMs) to further process speech recognition generated subtitles. It effectively corrects typos, standardizes technical terms, and makes subtitle content more accurate and coherent, providing users with an excellent viewing experience!
- Supports major domestic and international video platforms (Bilibili, Youtube, etc.)
- Automatically extracts and processes original video subtitles
- Provides multiple online recognition interfaces comparable to professional tools (Free & Fast)
- Supports local Whisper model (Privacy protection & Offline capability)
- Automatically optimizes technical terms, code snippets, and mathematical formula formats
- Contextual sentence segmentation optimization for better readability
- Supports script prompting, using original scripts or relevant hints to optimize subtitle segmentation
- Context-aware intelligent translation ensuring coherent full-text translation
- Uses Prompt to guide LLM translation reflection, improving translation quality
- Employs sequence fuzzy matching algorithm to ensure perfect timeline consistency
- Rich subtitle style templates (Popular Science, News, Anime styles, etc.)
- Multiple subtitle video formats (SRT, ASS, VTT, TXT)
| Configuration Item | Description |
|---|---|
| Built-in Model | Software includes basic LLM (gpt-4o-mini), usable without configuration |
| API Support | Supports standard OpenAI API format. Compatible with SiliconCloud, DeepSeek, Ollama, etc. For configuration, refer to Configuration Documentation |
Recommended models: For higher quality, consider Claude-3.5-sonnet or gpt-4o
| Model | Disk Space | Memory Usage | Description |
|---|---|---|---|
| Tiny | 75 MiB | ~273 MB | Basic transcription, testing only |
| Small | 466 MiB | ~852 MB | Good for English recognition |
| Medium | 1.5 GiB | ~2.1 GB | Recommended minimum for Chinese recognition |
| Large-v1/v2 | 2.9 GiB | ~3.9 GB | Excellent results, recommended if hardware allows |
| Large-v3 | 2.9 GiB | ~3.9 GB | Community reports potential hallucination/subtitle repetition issues (Not actually supported) |
Note: Models can be downloaded directly within the software in China; supports both GPU and integrated graphics.
- The "Subtitle Optimization and Translation" page includes a "Script Matching" option supporting the following one or more content types to assist in subtitle correction and translation:
| Type | Description | Example |
|---|---|---|
| Terminology List | Reference table for technical terms, names, specific phrases | Machine Learning->机器学习 Elon Musk->马斯克 Support->应援 Turing Pattern Bus Paradox |
| Original Script | Original script or related content | Complete speech transcript, course notes, etc. |
| Correction Requirements | Specific content-related correction requirements | Standardize pronouns, normalize technical terms, etc. Fill in content-related requirements, Example Reference |
- For script-assisted subtitle optimization, fill in script information before starting task processing
- Note: When using small LLM models with lower context parameters, keep script content within 1,000 characters. For models with larger context, script content can be appropriately increased.
| Interface Name | Supported Languages | Operation Mode | Description |
|---|---|---|---|
| B Interface | Chinese & English only | Online | Free, relatively fast |
| J Interface | Chinese & English only | Online | Free, relatively fast |
| Whisper | 96 languages including Chinese, Japanese, Korean, English, better for foreign languages | Local | Requires model download Medium or above recommended for Chinese Smaller models work well for English etc. |
When using URL download functionality, if you encounter:
- Videos requiring login information
- Only low-resolution video downloads available
- Network verification required under poor conditions
- Please refer to Cookie Configuration Instructions to obtain Cookie information, and place the cookies.txt file in the software's
AppDatadirectory for normal high-quality video downloads.
The basic processing flow is as follows:
VideoCaptioner/
├── runtime/ # 运行环境目录(不用更改)
├── resources/ # 软件资源文件目录(界面、图标等,不用更改)
├── work-dir/ # 工作目录,处理完成的视频和字幕文件保存在这里
├── AppData/ # 应用数据目录
├── cache/ # 缓存目录,临时数据
├── models/ # 存放 Whisper 模型文件
├── logs/ # 日志目录,记录软件运行状态
├── settings.json # 存储用户设置
└── cookies.txt # 视频平台的 cookie 信息
└── VideoCaptioner.exe # 主程序执行文件
-
The quality of subtitle segmentation is crucial for viewing experience. For this, I developed SubtitleSpliter, which can intelligently reorganize word-by-word subtitles into paragraphs that follow natural language habits and perfectly synchronize with video scenes.
-
During processing, only pure text content is sent to the large language model, without timeline information, which greatly reduces processing overhead.
-
In the translation phase, we adopt Andrew Ng's "translate-reflect-translate" methodology. This iterative optimization approach ensures translation accuracy.
As a junior student, both my personal abilities and the project still have many shortcomings. The project is continuously being improved. If you encounter any bugs during use, please feel free to submit Issues and Pull Requests to help improve the project.
2024.11.23
- Added Whisper-v3 model support, significantly improving speech recognition accuracy
- Optimized subtitle segmentation algorithm for more natural reading experience
- Fixed stability issues when detecting model availability
2024.11.20
- Added support for customizing subtitle position and style
- Added real-time log viewing for subtitle optimization and translation process
- Fixed automatic translation issues when using API
- Optimized video working directory structure for improved file management efficiency
2024.11.17
- Added flexible export of bilingual/monolingual subtitles
- Added script matching prompt alignment feature
- Fixed stability issues with subtitle import
- Fixed model download compatibility issues with non-Chinese paths
2024.11.13
- Added Whisper API call support
- Added support for importing cookie.txt to download resources from major video platforms
- Subtitle filenames automatically match video names
- Added real-time log viewing on software homepage
- Unified and improved internal software functionality