Terraform module implementation for managing stateful application on AWS modelled as immutable infrastructure.
- Immutable infrastructure reduces configuration drifts for the cluster nodes.
- Zero downtime node by node rolling update with health checks (requires user's health check script).
- Auto recover the node loss at runtime as every node is backed by AWS ASG .
- Provides stable identity to cluster nodes with fixed/Static IPs.
- External EBS volumes are used per node. Auto-mounts the EBS volumes during node startup.
- Allow file uploads to individual nodes as part of the automation code.
- Can be used to setup Kafka, Zookeeper, MongoDB and possibly others.
Note: Currently only Amazon Linux based AMI is supported. The script is written assuming Amazon Linux and currently only tested on Amazon Linux.
module "cluster" {
source = "git::git@github.com:prashantkalkar/stateful_application_module.git?ref=<version-git-tag>"
app_name = "cluster-test-setup"
node_image = "<ami_id>"
node_key_name = "my-keypair"
nodes = [
{
node_ip = "<InstanceIPToBeAllocated>"
node_id = "<NodeId>" # should be unique
node_subnet_id = "<subnet_id>"
},
{
node_ip = "<InstanceIPToBeAllocated>"
node_id = "<NodeId>"
node_subnet_id = "<subnet_id>"
},
{
node_ip = "<InstanceIPToBeAllocated>"
node_id = "<NodeId>"
node_subnet_id = "<subnet_id>"
}
]
node_files = [
{
node_id = "<NodeId>" # should be unique
node_files_toupload = [filebase64("${path.module}/config_file.cfg")]
},
{
node_id = "<NodeId>"
node_files_toupload = [filebase64("${path.module}/config_file.cfg")]
},
{
node_id = "<NodeId>"
node_files_toupload = [filebase64("${path.module}/config_file.cfg")]
}
]
node_config_script = filebase64("${path.module}/node_config_script.sh")
security_groups = [aws_security_group.cluster_sg.id]
instance_type = "<node_instance_type>"
default_data_volume = {
file_system_type = "xfs"
mount_path = "/mydata"
mount_path_owner_user = "ec2-user"
mount_path_owner_group = "ec2-user"
size_in_gibs = 16
type = "gp3"
mount_params = ["noatime"]
}
}For a stateful application cluster, every node needs to have an unique identity. This is required sometime to know which node is the leader and which nodes are followers. In other cases it is required to know which node in the cluster has what data. The node identity has to persist even when node is destroyed and recreated. This is completely different that stateless application when it does not matter which node you are talking to, as all nodes are identical. The node identity is generally provided with the help of fixed node IPs or fixed hostnames.
For highly available clusters, the majority of nodes has to be running. This majority is called as quorum. For a cluster of n nodes, the quorum is represented by n/2 + 1 nodes. to provide high availability. The cluster can remain available as long as nodes equals to the quorum are running. In other words, the cluster can service crash of nodes above the quorum size. For example, for a 3 nodes cluster, quorum size is 2 and hence it can service 1 node crash. Similar, 5 node cluster can service 2 node crashes at the same time. Any cluster automation assumes that minimum cluster size is 3 to allow a single node crash. This allows the automation to perform rolling update one node at a time. Since cluster size should service single node cluster, the cluster will remain fully operational while performing rolling update. For stateful application every decision like rolling updates or replacement of unhealthy nodes etc. should be taken at cluster level rather than locally at node level.
- To solve the identity problem of the nodes, a external ENI is created. This ENI is then attached to every node launch template. This ENI retains the IP address even when node is recreated. The new replaced instance will resume the same IP address and hence same identity in the cluster.
- The ensure the nodes are restored due to lost at runtime, every node is backed by Autoscaling group.
- The use of ASG backed instances also allows immutable infrastructure for the cluster nodes. Restoring a mis-configured and mis-behaving node can be replaced by just terminating it which will be replaced with fresh node with last released configuration. Replacing the nodes for any config changes also reduced the configuration drift as well.
- For rolling update, one node at the time, the rolling update script has to have a feedback that the last node that was replaced has successfully completed the node configuration and is healthy. The health check should consider that the node has joined the cluster and cluster as a whole is considered to be healthy. To get this feedback during the node startup, the module add a ASG lifecycle hook. This makes the nodes start in Pending:Wait state till the node userdata script executes completely and the node passes the health checkup. If the node complete the configuration and health check successfully then the userdata script completes the lifecycle hook action and this move the node into InService state. The rolling update script waits till the nodes are InService post replacing the node. This ensures that only one node is updated at a time and the rolling process fails if node replacement is not successful.
- Custom rolling update script: Terraform manages the infrastructure as a graph of dependencies and optimises the infra updates in parallel as much as possible. But for stateful application, a proper orchestration is required during rolling updates which becomes difficult to mange as part of the terraform dependency graph. That's why this is handled as part of a custom script.
The module will create cluster nodes depending on the cluster size requested (generally set to old value starting from 3 e.g. 3, 5, 7 etc).
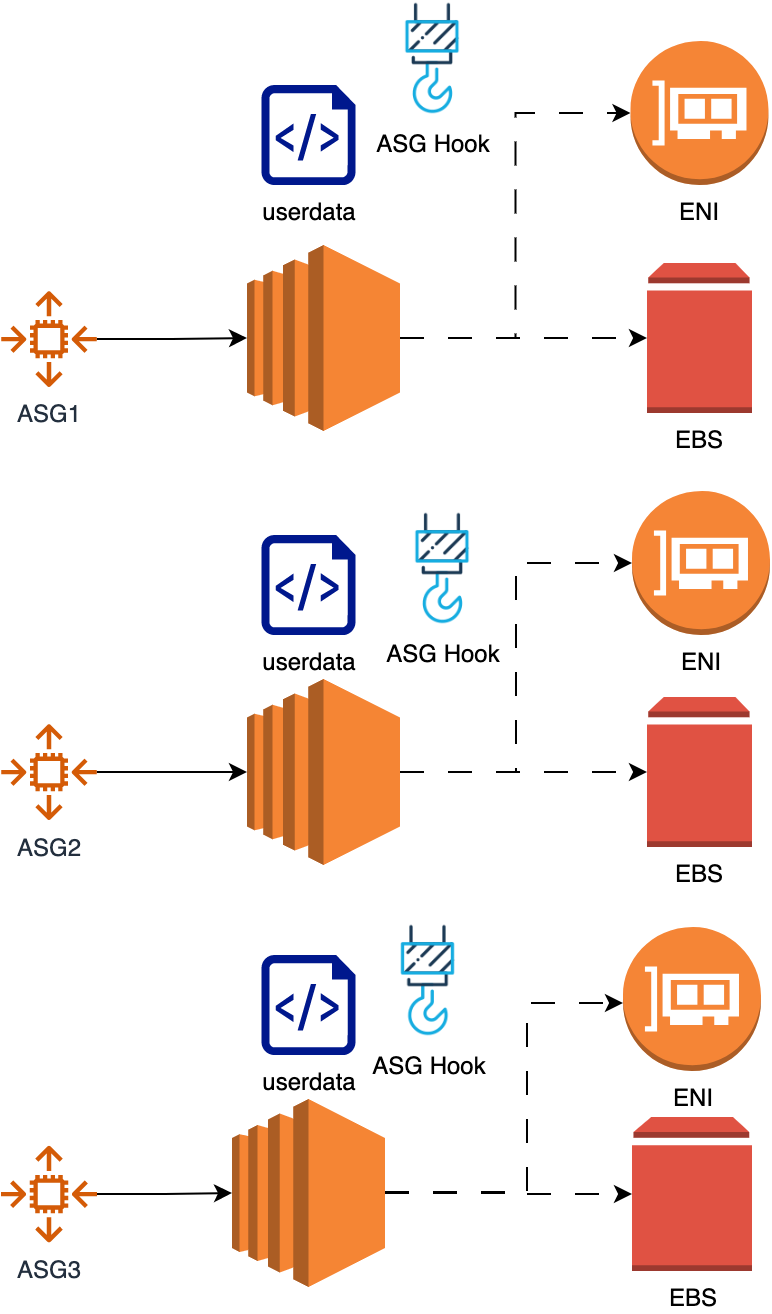
The module creates mainly following resources per node (as shown in the image above)
- Auto-scaling group with min max set to 1.
- External Elastic Network interface (ENI) with IP address as requested.
- Elastic block storage (EBS) as requested.
- Launch template with user data script to mount the EBS volume and to perform health checks (user data script has 2 parts one part has to be provided by module user. Another part is maintained within the module and calls the user provided script).
- Autoscaling lifecycle hook for instance creation.
Apart from above resources, the module also include a rolling update script to update cluster instances as per the latest version of the Launch Template attached to the ASGs. (ASG by default do not replace instances as per new Launch Template version). Rolling update script only update on node at a time.
When the cluster node is created or is replaced (due to modifications), the ASG lifecycle hook puts the node in a Pending:Wait state. The instance will remain in this state unless lifecycle action is not marked as complete (with continue). At the end of module user data script called the complete continue command on the instance lifecycle hook to complete the instance startup process. The userdata script also perform the cluster health check to ensure that node has joined the cluster successfully (this cluster health check function has to provided by the module user which is called from the module userdata script). The cluster health check happens before the lifecycle hook action.
This ensures that instance is shown as InService only after successful completion on user data script and also checking the cluster health status. The above-mentioned rolling update script waits for the instance to be InService before updating other instances in the service. The script will timeout for any failed instance which is stuck in Pending:Wait state due to failure of the user data script. (Refer to FAQs if this happens). That way, other cluster nodes are not updated with a failed change preventing any downtime (single node failure generally does not cause cluster unavailability due to quorum)
1. How do I debug the instance failure? (or My instance is stuck in Pending:Wait state, how do I recover?) Majority of instance failure will be due to userdata script. To debug the userdata script failure, ssh into the instance. The ssh can be done either through bastion (if bastion is being used) or AWS SSM session manager can be used to ssh into the instance. The module code attach the AmazonSSMManagedInstanceCore permission to the instance for ssm based ssh to work. Once logged into the instance, check out the /var/log/cloud-init-output.log fail for failure details.
sudo tail -200f /var/log/cloud-init-output.logSee the recovery FAQ for possible steps to recover from instance failure.
2. The rolling script keeps waiting as one of my instance is not healthy. How do I recover? The rolling instance script is designed to fail fast. It's better to fail in case of errors for a single instance rather than updating multiple instances and failing multiple instances. Multiple instance failure can cause the cluster level failure but generally a single node failure keeps the cluster in running state (as long as cluster quorum permits single node failure). The rolling script will exit with failure when at least one instance is not InService status. This requires manual recovery. You can possibly follow the following steps:
- Make the appropriate configuration changes to terraform code that will update the ASG Launch template with the fix (this can be userdata changes or other changes).
- Apply the changes, this will update the launch configurations but the rolling_update script will still wait for ASGs instances to be InService.
- Complete ASG lifecycle hook as ABANDON to unblock the ASG to start a fresh instance.
aws autoscaling complete-lifecycle-action --lifecycle-action-result ABANDON \
--instance-id "$INSTANCE_ID" --lifecycle-hook-name "$ASG_HOOK_NAME" \
--auto-scaling-group-name "$ASG_NAME" --region "$REGION"This should allow the instance to become InService. Rolling script should eventually detect that all instances are healthy and will proceed with rolling instances which are required to be changed.
3. I have more than one instance in non InService state. What should I do? Ideally, the cluster should never get into the state where there are multiple instances failed. This will cause the cluster to be unavailable. If the issue has occurred during the terraform rolling update script, then can also be a bug with the script. Please report the issue. If the failure has occurred at runtime (not during terraform apply), then ideally instances should be automatically recovered unless infrastructure is manually changed to cause the failure during instance recovery. Try to follow the FQA 1 and 2 to debug and recover the infrastructure to desired state.
4. I already have a cluster and I am not using the ASG to manage the instances. How do I move to this module for my existing cluster?
The best possibly way to import your existing infrastructure is to move one node at a time to stateful_module. If the older cluster is not managed by an ASG there is no way to import the node in the module code just by using terraform import blocks. For this its best to import the identity(IP) and data to the TF code that is using the stateful module. That means, import the node EBS volume at address module.cluster_module.module.cluster_nodes["00"].aws_ebs_volume.node_data (here the module name is cluster_module update it as per your name of the module in the calling code. Also the node id in this case is string "00"). And import the ENI (Node network interface) at address module.cluster_module.module.cluster_nodes["00"].aws_network_interface.node_network_interface. During the plan the TF code will now try to attach the existing EBS disk and existing ENI to the new node managed by the stateful module. Before terraform apply the EBS and the ENI has to be detached from the older cluster node. This most likely require the node termination during the migration to stateful module (ensure that you have the right quoram in the cluster to allow termination of a single node. Also ensure that EBS and ENI are not destoyed in the process of node termination). Post the node termination, the TF apply can be performed with stateful module. The module will provision an ASG which in turn privision a new cluster node. The setup will attach the older EBS volume and the ENI to the new node, giving the same data and the IP as per the older cluster. The node should be able to join the existing cluster without any issues since the data and identity (IP) are preserved. Repeat the process for other nodes. Ensure that cluster as a whole is working through out the migration process.
https://cloudonaut.io/a-pattern-for-continuously-deployed-immutable-and-stateful-applications-on-aws/ https://docs.aws.amazon.com/autoscaling/ec2/userguide/create-launch-template.html#change-network-interface https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/best-practices-for-configuring-network-interfaces.html https://aws.amazon.com/premiumsupport/knowledge-center/ec2-ubuntu-secondary-network-interface/
| Name | Version |
|---|---|
| terraform | >= 1.3.7 |
| aws | >= 4.50.0 |
| null | >= 3.2.1 |
| Name | Version |
|---|---|
| aws | 4.50.0 |
| null | 3.2.1 |
| Name | Source | Version |
|---|---|---|
| cluster_nodes | ./modules/node-module | n/a |
| Name | Type |
|---|---|
| aws_iam_instance_profile.node_instance_profile | resource |
| aws_iam_policy.node_policy | resource |
| aws_iam_role.node_role | resource |
| aws_iam_role_policy_attachment.instance_userdata_policy | resource |
| aws_iam_role_policy_attachment.ssm_policy | resource |
| null_resource.roll_instances | resource |
| aws_caller_identity.current | data source |
| aws_iam_policy_document.instance-assume-role-policy | data source |
| aws_region.current | data source |
| Name | Description | Type | Default | Required |
|---|---|---|---|---|
| app_name | n/a | string |
n/a | yes |
| asg_inservice_timeout_in_mins | Timeout in mins which will be used by the rolling update script to wait for instances to be InService for an ASG | number |
10 |
no |
| asg_lifecycle_hook_heartbeat_timeout | Timeout for ASG initial lifecycle hook. This is used only during ASG creation, subsequent value changes are not handled by terraform (has to be updated manually) | number |
3600 |
no |
| command_timeout_seconds | The timeout that will be used by the userdata script to retry commands on failure. Keep it higher to allow manual recovery | number |
1800 |
no |
| default_data_volume | This is default data volume configuration. This can be selectively overridden at node config level device_name = "Device name for additional Data volume, select name as per https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/device_naming.html" type = "EBS volume type e.g. gp2, gp3 etc" iops = "Only valid for type gp3" throughput_mib_per_sec = "only valid for type gp3" mount_path = "path where to mount the data volume" file_system_type = "File system to use to format the volume. eg. ext4 or xfs. This is used only initial time. Later changes will be ignored" mount_params = "Parameters to be used while mounting the volume eg. noatime etc. Optional, empty if not provided" mount_path_owner_user = "OS user that should own volume mount path will be used for chown" mount_path_owner_group = "OS group that should own the volume mount path, will be used for chown" |
object({ |
n/a | yes |
| http_put_response_hop_limit | n/a | number |
1 |
no |
| instance_type | n/a | string |
n/a | yes |
| jq_download_url | n/a | string |
"https://github.com/stedolan/jq/releases/download/jq-1.6/jq-linux64" |
no |
| node_config_script | Base64 encoded node configuration shell script. Must include configure_cluster_node and wait_for_healthy_cluster function. Check documentation for more details about the contract |
string |
n/a | yes |
| node_files | node_id = node identifier (this is not a index and need not in any specific ordered). node_files_toupload = list of file to be uploaded per node. These can be cluster config files etc. node_files_toupload.contents = Base64 encoded contents of the file to be uploaded on the node. node_files_toupload.destination = File destination on the node. This will be the file path and name on the node. The file ownership should be changed by node_config_script. |
set(object({ |
n/a | yes |
| node_image | n/a | string |
n/a | yes |
| node_key_name | n/a | string |
n/a | yes |
| nodes | node_id = node identifier (this is not a index and need not in any specific ordered). node_ip = IP address of the cluster node. This should be available within the subnet. node_image = image for node of the cluster node. node_subnet_id = Id of the subnet where node should be created. node_data_disk = override the default data disk configuration for the node. (follow the same schema of data disk). |
set(object({ |
n/a | yes |
| root_volume | n/a | object({ |
{ |
no |
| security_groups | n/a | list(string) |
n/a | yes |
| Name | Description |
|---|---|
| asg_names | n/a |
| node_iam_role_name | n/a |
| node_id_to_node_userdata_script_map | n/a |