Credits :
-
This repo uses Tensorflow implementation of image-to-text found at tensorflow/models of the image-to-text paper described below :
-
"Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge." Oriol Vinyals, Alexander Toshev, Samy Bengio, Dumitru Erhan. Full text available at: http://arxiv.org/abs/1609.06647
-
Pretrained model was borrowed from github page of KranthiGV. For convenience, here is the checkpoint file : https://drive.google.com/file/d/0B3laN3vvvSD2T1RPeDA5djJ6bFE/view?usp=sharing) | Released under MIT License. Be sure to credit the original author if you use the checkpoint file.
- Clone the repository.
- Install Python 3.5+, Tensorflow 1.0+ . You may need to install certain python packages if they are missing.
- Install NLTK and NLTK data :
- Download the pretrained checkpoint file from the link specified above and place the checkpoint file, along with the corresponding index file, in
modelsdirectory. - The live camera feed url as well as other camera parameters should be specified in
stream_utils/config.ini. Currently, the supported formats are JPEG and MJPEG. - Finally, edit and run the script
run.sh.
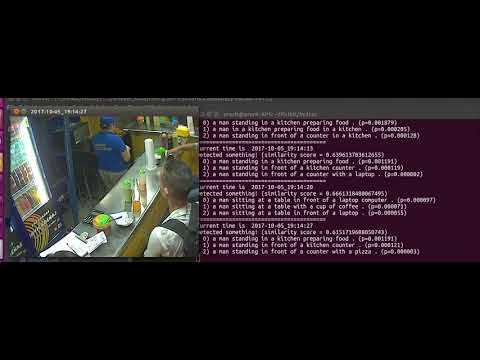
Here is resulting captions on a random live camera feed without any fine-tuning: