Jesth has triggered the creation of two spin-offs to push its ideas further:
- Braq: Customizable data format for config files, AI prompts, and more.
- Paradict: Streamable multi-format serialization with schema.
These projects therefore make Jesth obsolete.
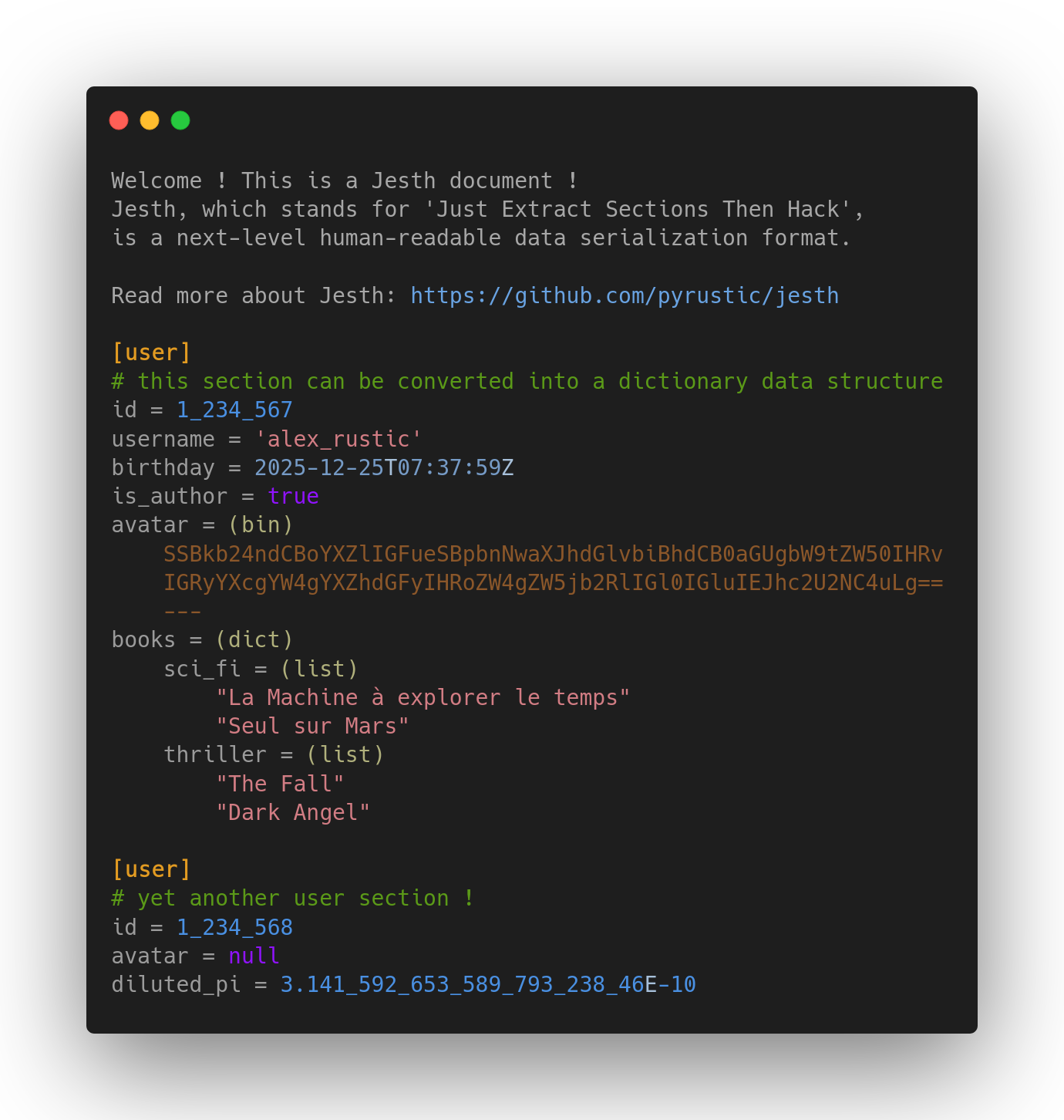
JesthFile with 1 anonymous top section, and 2 'user' sections
Human-readable versatile data format
This project is part of the Pyrustic Open Ecosystem.
- Overview
- Why not TOML, YAML, or JSON ?
- Why use Jesth ?
- Demo
- Code snippets for everyday scenarios
- Anatomy of a Section
- Specs of the Dict Section
- Application programming interface
- Jesth Schema for data validation
- Available implementations
- Miscellaneous
- Contributing
- Installation
Jesth (pronounced /dʒest/), which stands for Just Extract Sections Then Hack'em, is a human-readable data format whose reference parser is an eponymous lightweight Python library available on PyPI.
Read the backstory in this HN discussion !
A Jesth document is made up of sections, each defined by a header (between two square brackets) and a body which is just lines of text.
Instead of interpreting these lines upstream after extracting the sections, the Jesth parser lays low and lets the programmer decide which hack to apply to them.
Because of this parsing policy, a single Jesth document can contain an eclectic set of sections representing a poem, server configs, help text, prompts for a chatbot, directed graph, ascii artwork, and more.
Jesth is used by Shared for data persistence and exchange. Visit Shared !
For convenience, the Jesth library includes a proper and extensively tested hack to convert a compatible section to a dictionary data structure. In such a section that allows comments, one can encode strings (single or multi-line), scalars (integer, float, decimal float, complex, booleans), date and time, null value, binary data and nested collections (list and dictionary).
Therefore, Jesth can be used for configuration files, to create a scripting language, to act as a markup language to write docstrings so that a tool can generate reference documentation after parsing them, etc.
In the next few sections, we'll dive deep into Jesth, but first, why not TOML, YAML, or JSON ?
Jesth offers a high level of versatility that allows the programmer to freely decide what a section can contain and how to interpret its contents.
Moreover, whenever the programmer decides to adopt a dictionary as a data structure to formalize some or all sections of a Jesth document, he/she is offered a very readable and strict syntax to encode the data.
The library exposes an intuitive API for loading and dumping Dict sections with an option to preserve comments and whitespaces.
The following subsections will briefly compare TOML, YAML, and JSON to Jesth's dictionary data structure support.
Jesth shares with TOML the use of square brackets to define sections (or tables in TOML terminology), therefore, among other formats, the TOML syntax is closest to Jesth. However, when dealing with nested structures, TOML becomes very confusing, revealing the limitations of its syntax.
Besides intuitiveness and readability, the design decisions behind Jesth accidentally created an unlimited reserved word pool. For example, the [[END]] header (note the double brackets on either side) is reserved as a document separator, allowing you to mark the end of a Jesth stream or store multiple Jesth documents in a single file.
YAML tightly embraces complexity and ambiguity, which are probably not useful for most programmers' needs. Jesth keeps it minimalist, unambiguous and very readable.
JSON is great because it mimics the way we define data structures in source code. Therefore, it can be minified and is also a reasonable choice for machine-to-machine communication, but it cannot beat the readability of formats that natively support line breaks and/or indentation. In comparison to Jesth, JSON has fewer native data types and no native support for comments.
Jesth is ideal for configuration files, whether intended for use by a standard application or by a chatbot/AI. Personal notes can also benefit from being entered into a Jesth file, so they can be parsed later. As mentioned in the Overview section, Jesth was used to design a scripting language and currently serves as the markup language for docstrings in all projects that are part of the Pyrustic ecosystem.
Loading a Jesth document is stress-free because exceptions are only thrown when you try to convert a non-compatible section to a dictionary. But even that is the strict default behavior of the dictionary converter since you can customize the converter to string invalid values. This specific customization is as simple as this: value_converter.fallback_decoder = str
There's more to say, for example the Jesth Dict Section syntax is text editor/IDE-friendly, so it may benefit from supporting some cool features like the folding mechanism.
The demo is a clonable repository containing a JesthFile and a Python script to load its contents.
Load a JesthFile:
from jesth import read
path = "/home/alex/jesthfile"
document = read(path)Get sections:
...
# get the "config" section
config_section = document.get("config")
# get the list of all "user" sections
user_sections = document.get_all("user")
# show the body of a section
print(config_section.body) # list of lines
# show the body as a text (concatenated lines)
print(config_section.to_text())
# update the body of a section
new_body = [r"# comment",
r"server1 = '1.1.1.1'",
r"port = 80"]
config_section.update(new_body)Convert a compatible section into a Python Dict:
...
# won't raise an exception if the section can't be converted to dict
dict_object = section.to_dict()
# will raise an exception if the section can't be converted to dict
dict_object = section.create_dict()
# Note that `.create_dict` accepts `default` and `strict` arguments
# If the body can be converted to a dict but is empty, you get `default`
# Set True to `strict` to preserve comments and whitespaces
# Note that `.to_dict` accepts `default`, `strict`, and `fallback`
# If the body can't be converted to a dict, you get `fallback`Edit a document:
...
# append a new "user" section at the end of document
body = {"name": "alex", "id": 420}
document.append("user", body) # body as a regular Python dict
# insert a new "user" section at the beginning of document
body = [r"# comment",
r"name = 'alex'",
r"id = 420"]
document.insert(0, "user", body) # body as a list of linesSave a document:
from jesth import write
...
# if the document is linked to a JesthFile, call its `save` method
document.save()
# or save to a new path
document.save_to(path)
# Under the hood, the Document class actually uses the `write` function
write(document, path)Render a document:
from jesth import render
...
# return the string representation of the data
# this jesth text can be stored as it in a JesthFile
jesth_text = document.render()
# Under the hood, the Document class actually uses the `render` function
jesth_text = render(document)A section is made up of two parts: a header and a body. The header is defined on its own line, surrounded by two single brackets (opening and closing brackets respectively).
The body is what is between two consecutive headers or between a header and the end of the document.
Example of headers:
[this is a header]
[this_is_another_header]
\[this is not a header at all]
[[this is very illegal]]
\[[this is not illegal at all but still not a header]]
Note: A header may be empty and referenced from the source code with an empty string. Sections with empty headers are called
anonymous sections.
Example of two anonymous sections:
This text actually belongs to an anonymous section,
which happens to also be the first section of this document
[]
This text actually belongs to the second anonymous section
of this document.
If the very first section of a document is anonymous, it can
ignore to define its header.
Note: As you noticed, two sections may have similar headers. Read more about this in the 'Section family' section.
Is called Base section a section as defined in the document, without any transformation, i.e., just text lines. From the source code perspective, the body of such section is represented by default as a list of lines (string).
The alternative representation of such body is just a concatenated version of this list.
Is called Dict section, a section that is intended to be converted into a dictionary object by the parser.
By default, the library uses the regular dict type to represent the body of such section. This default behavior can be customized through the ValueConverter object.
Different sections can have the same header. In this case, they belong to a section family. By default, the .get(header) method from the Document class returns the first defined section with the given header argument. This method actually accepts a sub_index argument which is set to 0 by default to access the first item of the section family.
Get the 2nd section in the 'user' section family:
...
section = document.get("user", sub_index=1)Get the list of all sections in the 'user' section family:
...
sections = document.get_all("user")The specs for a Dictionary Section are mostly aligned with Python specs. For example, a Jesth Integer follows exactly the definition of Python Integer.
Note: The Jesth library allows the customization of each type of data as well in the context of parsing or in the context of rendering. This customization is made via the ValueConverter object
Jesth supports integers (base 10, hexadecimal, octal, binary), float (approximate binary floating-point, fixed-precision decimal floating-point), complex numbers, and booleans.
Note: Jesth Scalars specs are aligned with their respective Python equivalent specs.
Jesth Dict section supports Integer whose specs is aligned with Python int type specs.
Example:
int = -4_200_000
hex_int = 0xAE1F
oct_int = 0o3427
bin_int = 0b101_0011_1010_1010
Note: By default, Jesth tidy up numbers by using the underscore convention.
Mapping with actual Python objects:
| Jesth | Python |
|---|---|
| integer | int |
| hexadecimal int | jesth.box.HexInt subclassing int |
| octal int | jesth.box.OctInt subclassing int |
| binary int | jesth.box.BinInt subclassing int |
Jesth Dict section supports approximate binary floating-point and fixed-precision decimal floating-point which should be represented in the scientific notation.
Approximate binary floating-point:
float = 3.14
fixed-precision decimal floating-point:
decimal_float = 3.14E0
Note: By default, Jesth tidy up float numbers by using the underscore convention.
Decimal float with underscores:
decimal_float = 3.141_592_653_589_793_238_46E0
Mapping with actual Python objects:
| Jesth | Python |
|---|---|
| binary floating-point | float |
| decimal floating-point | decimal.Decimal |
Jesth Dict section supports complex numbers.
Example:
my_complex = -4.2+6.9i
The number in the example above is equivalent to this in Python:
my_complex = -4.2+6.9j
# or
my_complex = complex(-4.2, 6.9)Note: The only difference between the Jesth complex and Python complex is the usage of
ias suffix by Jesth instead ofjlike Python.
Jesth Dict section supports booleans.
Mapping with actual Python objects:
| Jesth | Python |
|---|---|
| true | True |
| false | False |
Jesth Dict section supports the null value that translates to Python None singleton.
Jesth Dict Section supports single-line strings. Such strings may embed unicode escape sequence and should be enclosed with double-quotes. Raw strings (WYSIWYG) are also supported and in these ones should be enclosed with single-quotes.
String embedding unicode escape sequences:
my_string = "this is a \n single-line string \u000A with line breaks"
another_string = "string containing "double quotes" and a \\ backslash"
Note: The Backslash character is a special one here. It is used to escape a backslash or to make a unicode escape sequence. It shouldn't be used to escape a quote.
Raw string (WYSIWYG):
my_string = 'this is a \n single-line string \u000A with no line break'
another_string = 'string containing 'single quotes' and a \ backslash'
Mapping with actual Python objects:
| Jesth | Python |
|---|---|
| Double quotes String | str |
| Single quotes String | jesth.box.RawString |
The Jesth single-line String type is aligned with Python
strtype.
Multi-line strings work like single-line strings with one major difference: they can actally span on multilines !
Creating multi-line strings implies using tags and indentation. The Jesth name for a multi-line string that supports unicode escape sequences is Text and its tag is (text). For raw multi-line string, the Jesth name is Raw and its tag is (raw).
A multi-line string is written with a 4-spaces indent under its tag. This indented block under the tag is then closed with a --- separator symbol placed on its own line.
Multi-line string that supports unicode escape sequences:
multiline = (text)
This is a multi-line
string that supports \\
unicode escape sequences \u000A
---
empty_text = (text)
---
Raw multi-line string:
multiline = (raw)
This is a raw multi-line \
string \u000A
---
empty_raw = (raw)
---
Mapping with actual Python objects:
| Jesth | Python |
|---|---|
| Text | jesth.box.Text subclassing str |
| Raw | jesth.box.Raw subclassing str |
Jesth Dict Section supports date and time (ISO 8601). Date and time:
datetime = 2020-10-20T15:35:57Z+01:00
date = 2020-10-20
time = 15:35:57
Mapping with actual Python objects:
| Jesth | Python |
|---|---|
| datetime | datetime.datetime |
| date | datetime.date |
| time | datetime.time |
Jesth Dict Section supports binary data. Under the hood, standard base64 (RFC 4648) is used. For convenience, the Jesth parser allows for line breaks and the Jesth renderer outputs base64 lines of 76 characters.
Embedding binary data encoded with base64 implies the use of a specific tag and indentation. The Jesth name for binary data is Bin and its tag is (bin).
Binary data encoded with base64 is written with a 4-spaces indent under the (bin) tag. This indented block under the tag is then closed with a --- separator symbol placed on its own line.
bin = (bin)
TG9yZW0gaXBzdW0gZG9sb3Igc2l0IGFtZXQsIGNvbnNlY3RldHVyIGFkaXBpc2NpbmcgZWxpdCwg
c2VkIGRvIGVpdXNtb2QgdGVtcG9yIGluY2lkaWR1bnQgdXQgbGFib3JlIGV0IGRvbG9yZSBtYWduY
SBhbGlxdWEu
---
empty_bin = (bin)
---
Mapping with actual Python objects:
| Jesth | Python |
|---|---|
| bin (base64) | bytes |
Jesth Dict Section supports comments which are strings starting with #. Comments and Whitespaces can be preserved while converting a Jesth Dict Section into a Python Dictionary.
Example with comments and whitespaces:
# this is a comment
key = "value"
# another comment
number = 42
Mapping with actual Python objects:
| Jesth | Python |
|---|---|
| comment | jesth.box.Comment subclassing ``str |
| whitespace | jesth.box.Whitespace subclassing ``str |
Note: Along with
jesth.box.Commentandjesth.box.Whitespace, the classesjesth.box.CommentIDandjesth.box.WhitespaceIDare also used to help embed comments and whitespace in a Python dictionary by playing the role of keys. They don't accept any argument, subclassint. Each instanciation of one of these classes create a new unique ID. The creation of this unique ID is thread-safe and handled byjesth.box.N.
Jesth Dict Section supports nested dictionaries and lists.
Nesting a collection implies the use of a specific tag and indentation. The Jesth name for a nested dictionary is Dict and its tag is (dict). In the case of a nested list, its Jesth name is List and its tag is (list).
Nested collections:
my_dict = (dict)
key_1 = "value"
# Nested list
key_2 = (list)
"item i"
"item ii"
# nested dict
(dict)
project = "jesth"
number = 42
Mapping with actual Python objects:
| Jesth | Python |
|---|---|
| dict | dict |
| list | list |
The library exposes functions and classes to load and dump Jesth document with optional customization at each stage. Loaded documents and their sections are encapsulated into classes exposing methods and properties with a high emphasis on ergonomy.
To load Jesth data, one may use the jesth.parser.read function when the source is a file (file-like object, path string, or pathlib.Path object), or jesth.parser.parse function when the source is a string.
These functions returns a Document object that is expected to contain Section objects. Under the hood, these functions use the jesth.parser.Parser class that consume line by line the contents and stops when [[END]] is encountered.
Both functions accept the ValueConverter object for customization.
Examples:
from decimal import Decimal
from jesth import read, parse
# Using 'read'
path = "/path/to/jesthfile"
document = read(path) # path may also be a pathlib.Path object
# Using 'parse'
with open(path, "r") as file:
text = file.read()
document = parse(text)
# Force floats to use decimal.Decimal
vc = ValueConverter(float_decoder=Decimal)
document = parse(text, value_converter=vc)As showed in the example above, references to these functions are available from the root module.
To save the contents of a Document in a file, use the jesth.renderer.write function. This function uses another function jesth.renderer.render which takes a document as argument then return its textual representation (with the square brackets and all).
Note: The
Documentclass itself already exposes therenderandsavemethods which use under the hood the functionsrenderandwritethat has been described above.
Example:
from jesth import read, write, render
path = "/path/to/jesthfile"
document = read(path)
# Save to same file
document.save()
# Save to another file
new_path = "/path/to/copy.txt"
document.save_to(new_path)
# render (convert the document into text)
text = document.render()
# note that the 'render' method accepts *headers
# and spacing arguments.
# By default the spacing is 1 (space) between sections
# Save to a file with 'write' function
write(document, path) # path may be a pathlib.Path instance
# render with the 'render' function
text = render(document)As showed in the example above, references to the write and render functions are available from the root module.
The read and parse functions returns a document object which contains the list of sections objects and exposes methods to edit the document, save it in a file, render its contents etc.
Properties:
path,sections,value_converter, andheaders.
The document object exposes append, insert, remove, and remove_all methods to add and remove sections.
Example:
from jesth import read
path = "/path/to/jestfile"
document = read(path)
# append a new section to the document
body = ["line 1", "line 2", "line 3"]
document.append("header", body=body) # body may be a dict or string
# insert an empty section at a specific index
document.insert(0, "header") # therefore, first section
# override the first section with a new empty one
document.set(0, "header") # 'body' is still set to None here
# remove the last section with a specific header
document.remove("header") # sub_index defaults to -1
# remove the first section with a specific header
document.remove("header", sub_index=0)
# note that the index argument is meant to be relative
# to this 'section family', i.e., sections with same header.
# remove all sections by header
document.remove_all("header")The document object exposes get, get_all, and count methods to retrieve sections or their count.
Example:
from jesth import read
path = "/path/to/jestfile"
document = read(path)
# get the first section with a specific header
section = document.get("header") # the index arg defaults to 0
# get the last section with a specific header
section = document.get("header", sub_index=-1)
# note that the index argument is meant to be relative
# to this 'section family', i.e., sections with same header.
# get all sections with a specific header
sections = document.get_all("header")
# count the number of sections sharing a specific header
n = document.count("header")The Section object contains the header and the body of a section. The body is stored as a list of string that may be converted on demand, if compatible, into a Python dictionary.
Properties:
header,body, andvalue_converter.
Example:
from jesth import read
path = "/path/to/jestfile"
document = read(path)
section = document.get("header")
# Convert the body of this section into a dict then return it.
# Beware, this method won't raise an exception at all
# instead, it may return a fallback value
data = section.to_dict() # accepts "default", "fallback", "strict"
# Concatenate the lines of the body to form a text string
data = section.to_text()
# Convert the body of this section into a dict then return it.
# Beware, this method will raise an exception if the conversion fails
data = section.create_dict() # accepts "default" and "strict"
# the default parameter is for default data if the new created dict
# is empty. The strict parameter is to tell whether comment/whitespace
# should be preserved and inserted in the new dict !
# update the body of this section
body = ["line 1", "line 2", "line 3"]
section.update(body) # here, body may be a string or a dictThis object has methods to encode and decode values, and also properties to customize conversion types.
Most time, you won't need to set or edit this object. The encode and decode methods of this object are only useful for test purpose.
Parameters:
-
dict_type: the Python type in which a Jesth Dict should be converted into. Defaults to Python dict type.
-
list_type: the Python type in which a Jesth List should be converted into. Defaults to Python list type.
-
XXX_types: this represents a group of parameters. Here, XXX is a placeholder for a Jesth data type. Valid types are: dict, list, bin, bool, complex, date, datetime, float, integer, raw, string, text, time. Examples: dict_types, float_types, and time_types. Use this parameter to set a list of Python types that may be encoded in the Jesth type (the same used as prefix). Example: dict_types defaults to [dict, OrderedDict], i.e., while encoding some Python data, an OrderedDict instance or a regular dict instance will be encoded as a Jesth dict.
-
XXX_encoder: this represents a group of parameters. Here, XXX is a placeholder for one of: bin, bool, complex, date, datetime, float, integer, null, raw, string, text, time, fallback. Use these parameters to set a callable to encode Python values into Jesth values. Example: float_encoder = decimal.Decimal
-
XXX_decoder: this represents a group of parameters. Here, XXX is a placeholder for one of: bin, bool, complex, date, datetime, float, integer, null, raw, string, text, time, fallback. Use these parameters to set a callable to decode Jesth values into Python values. Example: integer_decoder = int
Note: the parameters of ValueConverter are mirrored as read and write properties.
Coming soon... ;)
For the moment, the only available implementation of Jesth is this reference library written in Python. If you are interested into writing a Jesth library for another language (Rust, C#, Java, JavaScript, PHP, etc), feel free to get in touch with me for any question !
Collection of miscellaneous notes.
Jesth stands for Just Extract Sections Then Hack'em. Here, the word hack is a direct reference to the Hacker culture.
To tell the parser to stop parsing a document, input in the document the [[END]] (case-insensitive) tag on its own line.
You must escape the opening square brackets at the start of a line of a body with a backslash \ character. And whenever your line needs to start with n backslash(es) followed by an opening square bracket, you need to prepend an extra backslash to the line, resulting in n+1 backslash(es).
Note: This does not apply when programmatically submitting the body of a section as an argument to a function or class.
Example:
[header]
\[hello world !
\\\[Here there is one extra line to escape the bracket. Backslashes themselves shouldn't be escaped
Indentation in a Jesth file is aligned with the de-facto indentation convention in Python. Four spaces represent one indent.
The beautiful cover image is made with the amazing carbon app.
Feel free to open an issue to report a bug, suggest some changes, show some useful code snippets, or discuss anything related to this project. You can also directly email me.
Note: I would like to automate a decent Git workflow (branching, merging patches, all the basic cool things cool kids do) with Backstage. In the meantime, I will manually incorporate the fixes into the only existing branch (
master). Thank you for your understanding !
Following are instructions to setup your development environment
# create and activate a virtual environment
python -m venv venv
source venv/bin/activate
# clone the project then change into its directory
git clone https://github.com/pyrustic/jesth.git
cd jesth
# install the package locally (editable mode)
pip install -e .
# run tests
python -m unittest discover -f -s tests -t .
# deactivate the virtual environment
deactivateJesth is cross platform. It is built on Ubuntu with Python 3.8 and should work on Python 3.5 or newer.
python -m venv venv
source venv/bin/activatepip install jesthpip install jesth --upgrade --upgrade-strategy eagerdeactivateHi, I'm Alex, a tech enthusiast ! Get in touch with me !