Add lightweight locking C API #108724
Comments
|
Would it be possible to start with no public API for now, and consider adding the public API later? |
|
Yes, it would be possible to put everything in the internal API for now. |
It's way easier for me to review a change if the API is restricted to the internal C API, than adding a public C API (need doc, tests, review the design, error cases, etc.). |
`PyMutex` is a one byte lock with fast, inlineable lock and unlock functions for the common uncontended case. The design is based on WebKit's `WTF::Lock`. PyMutex is built using the `_PyParkingLot` APIs, which provides a cross-platform futex-like API (based on WebKit's `WTF::ParkingLot`). This internal API will be used for building other synchronization primitives used to implement PEP 703, such as one-time initialization and events.
|
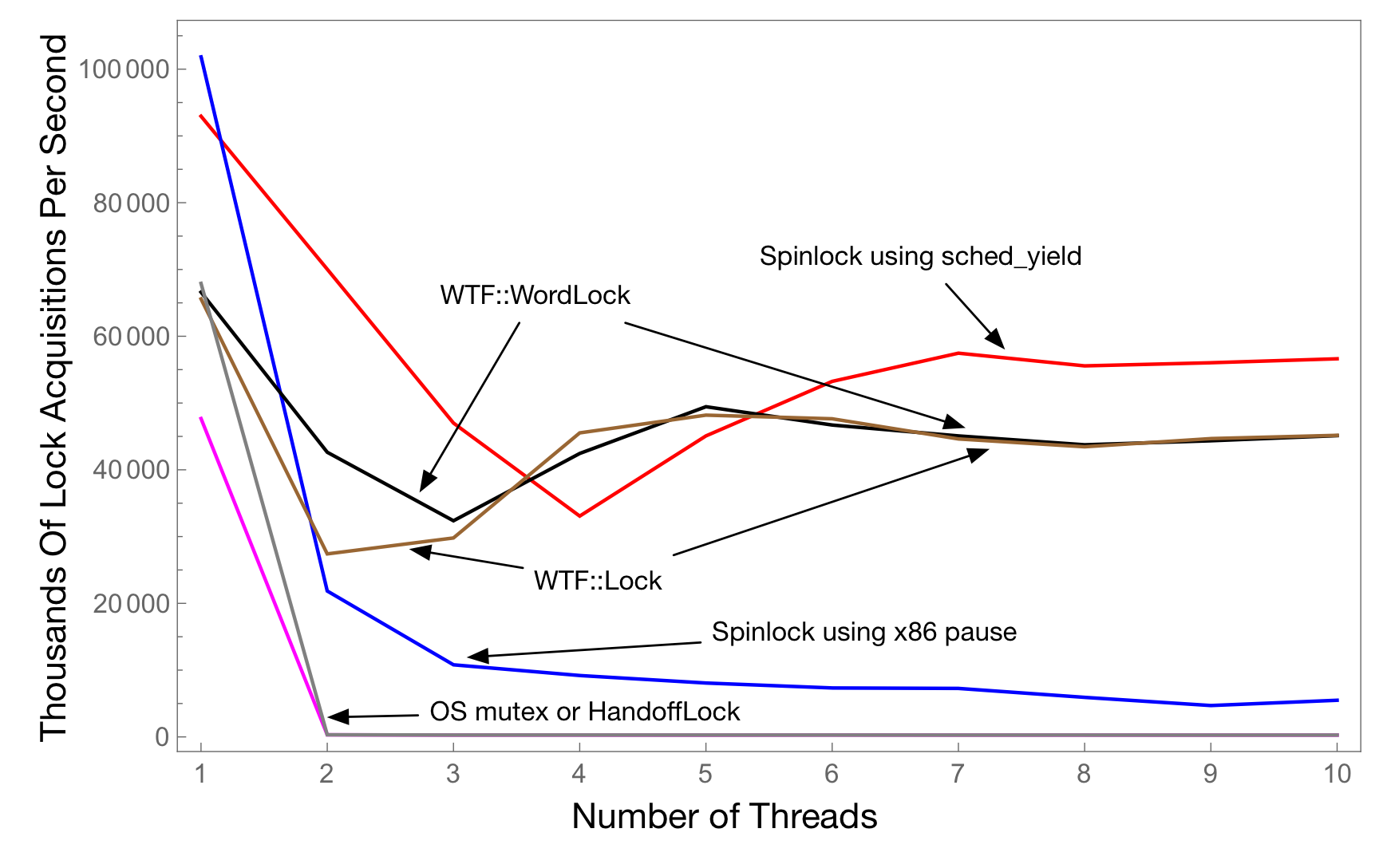
Having read through https://webkit.org/blog/6161/locking-in-webkit/ now, I'm wondering if we could make wide use of the new lock API in place of Also, the benchmark results in that paper imply that the picture isn't quite so rosy with 2 or 3 threads. |
Yes. I did this to some extent in nogil-3.12 (e.g., colesbury/nogil-3.12@45bdd27). I did not do this as part of the linked PR to avoid increasing the scope.
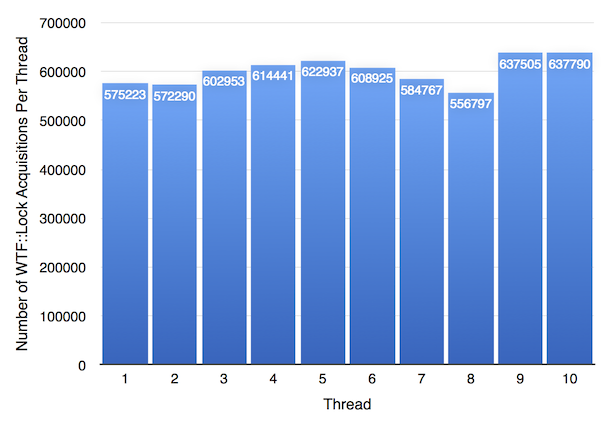
Assuming you're referring to this benchmark result, the results for 2-3 threads are actually quite good. The most important comparison is One thing to keep in mind is that the benchmark is inherently serial because it's testing lock contention with a very short critical section. It's not a general purpose benchmark -- real applications may have some mix of contention and and parallelizable code -- this benchmark is all contention. This means it will always perform best with 1 thread, and perhaps unintuitively, better with one core than on a multi core machine. I think that's why there's a dip around 3-4 threads for many of the locks implementations (the blog post mentions it's run on a machine with 4 cores). Here's the equivalent benchmark for
|

{kind=link}
My understanding is that the dip is at least partly due to the approach Regardless, you're completely correct that this appears to be a drastic improvement over the OS mutex. 😄 |
{kind=link}
PyMutex is a one byte lock with fast, inlineable lock and unlock functions for the common uncontended case. The design is based on WebKit's WTF::Lock. PyMutex is built using the _PyParkingLot APIs, which provides a cross-platform futex-like API (based on WebKit's WTF::ParkingLot). This internal API will be used for building other synchronization primitives used to implement PEP 703, such as one-time initialization and events. This also includes tests and a mini benchmark in Tools/lockbench/lockbench.py to compare with the existing PyThread_type_lock. Uncontended acquisition + release: * Linux (x86-64): PyMutex: 11 ns, PyThread_type_lock: 44 ns * macOS (arm64): PyMutex: 13 ns, PyThread_type_lock: 18 ns * Windows (x86-64): PyMutex: 13 ns, PyThread_type_lock: 38 ns PR Overview: The primary purpose of this PR is to implement PyMutex, but there are a number of support pieces (described below). * PyMutex: A 1-byte lock that doesn't require memory allocation to initialize and is generally faster than the existing PyThread_type_lock. The API is internal only for now. * _PyParking_Lot: A futex-like API based on the API of the same name in WebKit. Used to implement PyMutex. * _PyRawMutex: A word sized lock used to implement _PyParking_Lot. * PyEvent: A one time event. This was used a bunch in the "nogil" fork and is useful for testing the PyMutex implementation, so I've included it as part of the PR. * pycore_llist.h: Defines common operations on doubly-linked list. Not strictly necessary (could do the list operations manually), but they come up frequently in the "nogil" fork. ( Similar to https://man.freebsd.org/cgi/man.cgi?queue) --------- Co-authored-by: Eric Snow <ericsnowcurrently@gmail.com>
Some WASM platforms have POSIX semaphores, but not sem_timedwait.
Some WASM platforms have POSIX semaphores, but not sem_timedwait.
PyMutex is a one byte lock with fast, inlineable lock and unlock functions for the common uncontended case. The design is based on WebKit's WTF::Lock. PyMutex is built using the _PyParkingLot APIs, which provides a cross-platform futex-like API (based on WebKit's WTF::ParkingLot). This internal API will be used for building other synchronization primitives used to implement PEP 703, such as one-time initialization and events. This also includes tests and a mini benchmark in Tools/lockbench/lockbench.py to compare with the existing PyThread_type_lock. Uncontended acquisition + release: * Linux (x86-64): PyMutex: 11 ns, PyThread_type_lock: 44 ns * macOS (arm64): PyMutex: 13 ns, PyThread_type_lock: 18 ns * Windows (x86-64): PyMutex: 13 ns, PyThread_type_lock: 38 ns PR Overview: The primary purpose of this PR is to implement PyMutex, but there are a number of support pieces (described below). * PyMutex: A 1-byte lock that doesn't require memory allocation to initialize and is generally faster than the existing PyThread_type_lock. The API is internal only for now. * _PyParking_Lot: A futex-like API based on the API of the same name in WebKit. Used to implement PyMutex. * _PyRawMutex: A word sized lock used to implement _PyParking_Lot. * PyEvent: A one time event. This was used a bunch in the "nogil" fork and is useful for testing the PyMutex implementation, so I've included it as part of the PR. * pycore_llist.h: Defines common operations on doubly-linked list. Not strictly necessary (could do the list operations manually), but they come up frequently in the "nogil" fork. ( Similar to https://man.freebsd.org/cgi/man.cgi?queue) --------- Co-authored-by: Eric Snow <ericsnowcurrently@gmail.com>
|
Hi @colesbury, I hate to resurrect a closed issue, but wanted to raise this point as something worth spending some time on:
I'm currently looking at what it would take to add proper locking to NumPy (thinking about NEP 55, but NumPy has a number of threading bugs right now that are hidden by the GIL) and it looks like indeed there are very few cross-platform synchronization libraries I could use - it would be very nice for NumPy if CPython added a public version of |
|
@ngoldbaum Yeah, I'm planning on coming back to this in a bit to propose the public APIs. I'll probably wait until #111569 and maybe a few other changes land first. |
Using a system clock causes issues when it's being updated by the system administrator, NTP, Daylight Saving Time, or anything else. Sadly, on Windows, the monotonic clock resolution is around 15.6 ms. Example: python#85876
In general, when `_PyThreadState_GET()` is non-NULL then the current thread is "attached", but there is a small window during `PyThreadState_DeleteCurrent()` where that's not true: tstate_delete_common is called when the thread is detached, but before current_fast_clear(). This updates _PySemaphore_Wait() to handle that case.
In general, when `_PyThreadState_GET()` is non-NULL then the current thread is "attached", but there is a small window during `PyThreadState_DeleteCurrent()` where that's not true: tstate_delete_common() is called when the thread is detached, but before current_fast_clear(). Co-authored-by: Eric Snow <ericsnowcurrently@gmail.com>
…ython#116483) In general, when `_PyThreadState_GET()` is non-NULL then the current thread is "attached", but there is a small window during `PyThreadState_DeleteCurrent()` where that's not true: tstate_delete_common() is called when the thread is detached, but before current_fast_clear(). Co-authored-by: Eric Snow <ericsnowcurrently@gmail.com>
…ython#116483) In general, when `_PyThreadState_GET()` is non-NULL then the current thread is "attached", but there is a small window during `PyThreadState_DeleteCurrent()` where that's not true: tstate_delete_common() is called when the thread is detached, but before current_fast_clear(). Co-authored-by: Eric Snow <ericsnowcurrently@gmail.com>
Feature or enhancement
Implementing PEP 703 will require adding additional fine grained locks and other synchronization mechanisms. For good performance, it's important that these locks be "lightweight" in the sense that they don't take up much space and don't require memory allocations to create. Additionally, it's important that these locks are fast in the common uncontended case, perform reasonably under contention, and avoid thread starvation.
Platform provided mutexes like
pthread_mutex_tare large (40 bytes on x86-64 Linux) and our current cross-platform wrappers ([1], [2], [3]) require additional memory allocations.I'm proposing a lightweight mutex (
PyMutex) along with internal-only APIs used for building an efficientPyMutexas well as other synchronization primitives. The design is based on WebKit'sWTF::LockandWTF::ParkingLot, which is described in detail in the Locking in WebKit blog post. (The design has also been ported to Rust in theparking_lotcrate.)Public API
The public API (in
Include/cpython) would provide aPyMutexthat occupies one byte and can be zero-initialized:I'm proposing making
PyMutexpublic because it's useful in C extensions, such as NumPy, (as opposed to C++) where it can be a pain to wrap cross-platform synchronization primitives.Internal APIs
The internal only API (in
Include/internal) would provide APIs for buildingPyMutexand other synchronization primitives. The main addition is a compare-and-wait primitive, like Linux'sfutexor Window'sWaitOnAdress.The API closely matches
WaitOnAddressbut with two additions:argis an optional, arbitrary pointer passed to the wake-up thread anddetachindicates whether to release the GIL (or detach in--disable-gilbuilds) while waiting. The additionalargpointer allows the locks to be only one byte (instead of at least pointer sized), since it allows passing additional (stack allocated) data between the waiting and the waking thread.The wakeup API looks like:
_PyParkingLot_Unparkis currently a macro that takes a code block. ForPyMutexwe need to update the mutex bits after we identify the thread but before we actually wake it up.cc @ericsnowcurrently
Linked PRs
The text was updated successfully, but these errors were encountered: