{kind=link}
![]()
Published in IEEE Transactions on Software Engineering (TSE) 2020. ARXIV Link: [https://arxiv.org/abs/1910.09644](https://arxiv.org/abs/1910.09644]
@article{krishna2020conex,
title={ConEx: Efficient Exploration of Big-Data System Configurations for Better Performance},
author={Krishna, Rahul and Tang, Chong and Sullivan, Kevin and Ray, Baishakhi},
journal={IEEE Transactions on Software Engineering},
year={2020},
publisher={IEEE}
}
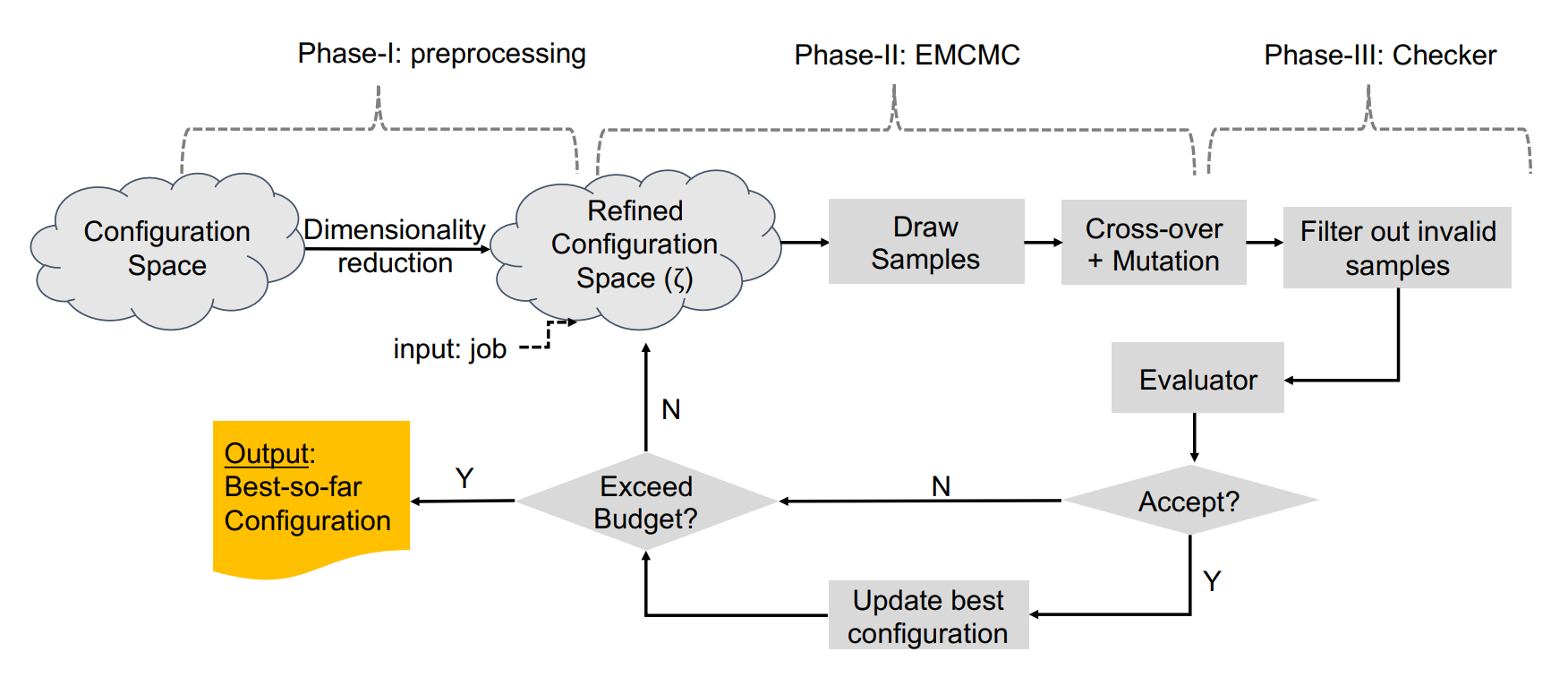
Configuration space complexity makes the big-data software systems hard to configure well. Consider Hadoop, with over nine hundred parameters, developers often just use the default configurations provided with Hadoop distributions. The opportunity costs in lost performance are significant. Popular learning-based approaches to auto-tune software does not scale well for big-data systems because of the high cost of collecting training data. We present a new method based on a combination of Evolutionary Markov Chain Monte Carlo (EMCMC) sampling and cost reduction techniques to find better-performing configurations for big data systems. For cost reduction, we developed and experimentally tested and validated two approaches: using scaled-up big data jobs as proxies for the objective function for larger jobs and using a dynamic job similarity measure to infer that results obtained for one kind of big data problem will work well for similar problems. Our experimental results suggest that our approach promises to improve the performance of big data systems significantly and that it outperforms competing approaches based on random sampling, basic genetic algorithms (GA), and predictive model learning. Our experimental results support the conclusion that our approach strongly demonstrates the potential to improve the performance of big data systems significantly and frugally.
- Rahul Krishna†(a), Chong Tang†(b), Kevin Sullivan, and Baishakhi Ray
- † Rahul Krishna and Chong Tang are joint first authors
- Tang, C. is with Walmart Labs, Mountain View, CA USA. E-mail: ct4ew@virginia.edu
- Sullivan, K. is with the Department of Computer Science, University of Virginia, Charlottesville, VA USA. E-mail: sullivan@virginia.edu
- Ray, B. and Krishna, R. are with the Department of Computer Science, Columbia University, New York City, NY USA. E-mail: rayb@cs.columbia.edu and i.m.ralk@gmail.com
This is free and unencumbered software released into the public domain.
Anyone is free to copy, modify, publish, use, compile, sell, or distribute this software, either in source code form or as a compiled binary, for any purpose, commercial or non-commercial, and by any means.
(BTW, it would be great to hear from you if you are using this material. But that is optional.)
In jurisdictions that recognize copyright laws, the author or authors of this software dedicate any and all copyright interest in the software to the public domain. We make this dedication for the benefit of the public at large and to the detriment of our heirs and successors. We intend this dedication to be an overt act of relinquishment in perpetuity of all present and future rights to this software under copyright law.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
For more information, please refer to http://unlicense.org