The Blog Post for this Repository can be viewed here on Medium: https://medium.com/ml-2-vec/using-word2vec-to-analyze-reddit-comments-28945d8cee57
In this post, I am going to go over Word2Vec. I will talk about some background of what the algorithm is, and how it can be used to generate Word Vectors from. Then, I will walk through the code for training a Word2Vec model on the Reddit comments dataset, and exploring the results from it.
What is Word2Vec? Word2Vec is an algorithm that generates Vectorized representations of words, based on their linguistic context. These Word Vectors are obtained by training a Shallow Neural Network (single hidden layer) on individual words in a text, and given surrounding words as the label to predict. By training a Neural Network on the data, we update the weights of the Hidden layer, which we extract at the end as the word vectors. To understand Word2Vec, let’s walk through it step by step. The input of the algorithm is text data, so for a string of sentences, the training data will consist of individual sentences, paired with the contextual words we are trying to predict. Let’s look at the following diagram (from Chris McCormick’s blog):
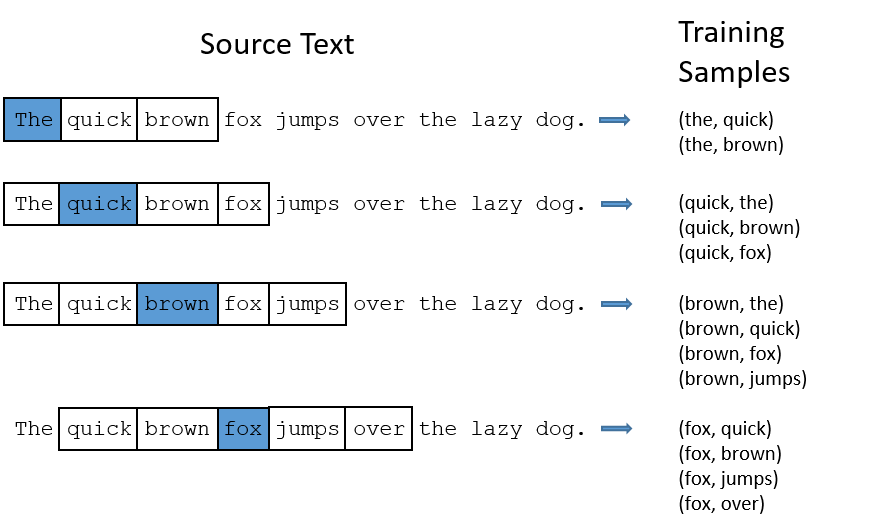
We use a sliding window over the text, and for each “target word” in the set, we pair it with an adjacent word to obtain an x-y pair. In this case, the window size (denoted as C ) is 4, so there are 2 words on each side, except for edge words. The input words are then processed into one-hot vectors. One-hot vectors are a vectorial representation of data, in which we use a large vector of zeros which correspond to each word in the vocabulary, and set the position corresponding to the target word to 1. In this case, we have a total of V words, so each vector will be of V length, and will have the index corresponding to it’s position set to 1. In the example above, the vector corresponding to the last sentence will be 0 0 0 1 0 0 0 0, because the word “fox” is the 4th word in the vocabulary, and there are 8 words (counting “the” once). Having obtained the input, the next step is to design the Neural Network. Word2Vec is a shallow network, which means that there is a single-hidden layer in it. A traditional neural network diagram looks like this:
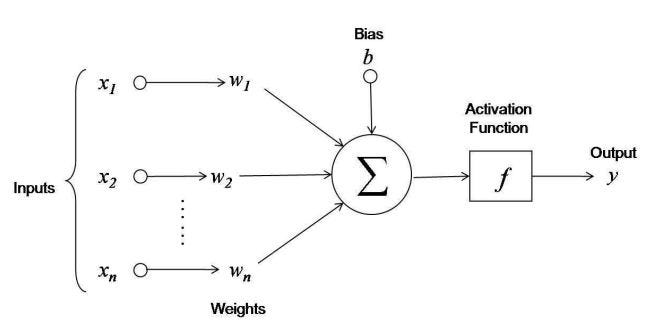
In the above diagram, the input data is fed through the Neural Network by applying the weight vectors and bias units. What this means is that for each x, we obtain the output as:

Neural Networks are trained iteratively, which means that once we do the forward calculation of y, we update the weight vectors w and bias units b with backwards calculation of how much they change w.r.t. error of prediction. Here are the update equations, although I will not be going over the actual derivation of backpropagation in this post:

Let’s look at the Neural Network diagram of Word2Vec now:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The above diagram summarizes the Word2Vec model well. We take as input one-hot vectorized representations of the words, applying W1 (and b1) to obtain the hidden layer representations, then feeding them again through a W2 and b2 , and applying a SoftMax activation to obtain the probabilities of the target word and each of their associated y values. However, we need Word2Vec to obtain vectorial representations of the input words. By training the model on the target words and their surrounding labels, we are updating the values of the hidden layer iteratively to the point where the cost (or the difference between the prediction and actual label) is minimum. Once the model has been trained, we extract this hidden representation as the Word Vector of the word, as there is a 1-to-1 correspondence between each. The size of the hidden units h is also an important consideration here, since it decides the length of the hidden layer representation for each word.