
NOTE : When you use any of the above yaml files as given in the repository, you will have to run the below command to create any of the Kubernetes Objects :
kubectl create -f file_name.yaml
Also, if we want to exec any commands or use a shell of any pod we can use the command
kubectl exec -it <pod-name> -- sh
# to hit any url from inside the shell
wget www.google.com
Some Commands for Exam (Sheet): Click Here
Notes : monolith app broken down into smaller services(micro)
- Used to store sensitive information like passwords and keys.
- They are stored in an encoded format.
- TO use it we need to :
- create secret
- inject it into Pod
- Here the data needs to be Encoded, so it is done using
echo -n 'root' | base64command - Decode
echo -n 'decode_value' | base64 --decode
Imperative way to create secrets :
#get secrets
kubectl get secrets
# describe or get info about particular secret
kubectl describe secret <secret-name> # This shows the attributes in secret but hides the values.
kubectl get secret <secret-name> -o yaml # To view the values (encoded).
# If you enter the pod where secret is injected, you can see decoded values.
kubectl create secret generic <secret-name> --from-literal=<key1>=<value1> --from-literal=<key2>=<value2>
kubectl create secret generic <secret-name> --from-file=<path to file> # colon or equals to as delimiter between keys and values
- It is helpful inorder to pass the env variables to the required Pods.
- We need to create Config Maps either through imperative or declarative(yaml file) way.
Imperative way to create config map :
#for single key value pairs
kubectl create cm <cm-name> --from-literal=<key1>=<value1> --from-literal=<key2>=<value2>
#to create from a file
kubectl create cm <cm-name> --from-file=<path to file> # colon or equals to as delimiter between keys and values
kubectl create cm <cm-name> --from-file=<directory>-
Used by external applications to query or authenticate itself to k8s cluster inorder to use the APIs of k8s.
-
As per latest version of k8s first we need to create service account as it will automatically not generate the secret object which contains token
-
When we use service account inside the pod, the secret for that service account is mounted as volume inside the pod.
-
We need to create token for that particular account by running the command
kubectl create sa <sa-name>
kubectl get sa
kubectl describe sa <sa-name>
# To fetch token from service account
kubectl describe sa <sa-name> # gives secret name
kubectl describe secret <secret-name> # gives token stored in secret- Can use it to perform any type of jobs like batch processing, generating a report and them mailing it.
- Some points to remember about job in k8s
-
In case of pods, default value for restart property is Always and in case of jobs, default value for restart property is Never.
-
Job has pod template. Job has 2 spec sections - one for job and one for pod (in order).
-
A pod created by a job must have its restartPolicy be OnFailure or Never. If the restartPolicy is OnFailure, a failed container will be re-run on the same pod. If the restartPolicy is Never, a failed container will be re-run on a new pod.
-
Job properties to remember:
completions, backoffLimit, parallelism, activeDeadlineSeconds, restartPolicy. -
By default, pods in a job are created one after the other (sequence). Second pod is created only after the first one is finished.
-
kubectl create job busybox --image=busybox -- /bin/sh -c "echo hello;sleep 30;echo world"
kubectl get jobs
#once a job is created then it launches a pod to do the work
#so you check the logs of that pod after we get the name of the pod from running the above the commands to get jobs
kubectl logs busybox-qhcnx # pod under job
kubectl delete job <job-name>- In a cronjob, there are 2 templates - one for job and another for pod.
- In a cronjob, there are 3 spec sections - one for cronjob, one for job and one for pod (in order).
- Properties to remember: spec -> successfulJobHistoryLimit, spec -> failedJobHistoryLimit
# Create a cron job with image busybox that runs on a schedule and writes to standard output
kubectl create cj busybox --image=busybox --schedule="*/1 * * * *" -- /bin/sh -c "date; echo Hello from Kubernetes cluster"
- Service Types:
-
Node port : This services helps to access internal pods from the port on the node(exposing port on node to outside world)
-
ClusterIp : This is the default service type and we don't have to specify a service type. It exposes the service on an internal-cluster IP. From inside (reachable only from within the cluster)
-
LoadBalancer : This service type exposes the service via cloud provider's LB
-
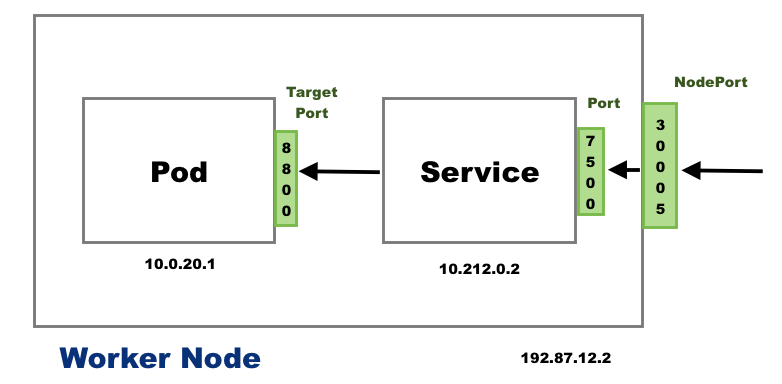
kubectl apply -f <svc.yaml>
kubectl get svc
kubectl describe svc <service-name> # to get to know about port, target port etc.
kubectl delete svc <service-name>
kubectl expose pod redis --port=6379 --name=redis-service --type=ClusterIP --dry-run=client -o yaml > svc.yaml
kubectl expose pod nginx --port=80 --target-port=8080 --name=nginx-service --type=NodePort --dry-run=client -o yaml > svc.yaml
kubectl expose deploy <deploy-name> --port=<>Note : IP of service is known as Cluster-IP (internal ip). Service can be accessed by pods using Cluster-IP or service name.
- A Pod is such that it contain one or more containers inside it.
- Basically an object
- You can check the configuration of any pod definition file using the below command :
kubectl get pod pod_name -o yaml
Note : To copy the above configuration to a file so that in future you can use it create/edit some other pods with almost same configuration.
- Can think of it as an Application layer 7 load balancer.
- It helps us enforce better security meausres on how a K8S cluster is to be used.
To view all admission controllers :
kube-apiserver -h | grep enable-admission-plugins
The kube-api yaml file is at location :
/etc/kubernetes/manifests/kube-apiserver.yaml
- Here, controllers first validates and then if required mutates basically change the object definition which is to be created.
- Alpha version might have bugs and is not that reliable.
- can be dropped
- Not enabled by default
- After end to end testing and major bugs are fixed then the Alpha version moves to Beta phase.
- enabled by default
- Can have minor bugs
- yes ny default
- highly reliable
-
If you want to deprecate any resource in that particular API group you need cannot removw it from that group in that current release.
-
You need to remove it from the next api version/release and that resource will continue to be present in previous version.
- Command to check about any particular resource like its version and group :
kubectl explain deployment
- Manage, observe and mantain the state of the resources/objects in the k8s cluster.
- Blue Green Stratergy
- The Blue part is that where the application is the older one & Green contains the newer version of the app
- But 100% of traffic is routed to the older one i.e Blue one
- Once green (newer app) - all tests are done and passed then the traffic is routed to green one (newer app) and blue deployment is taken down
- Basically service file is updated to route traffic to Green by changing the selector labels.
- Canary Stratergy ⏱️
- Here, one primary deployment where the current version of application is running and at the same time canary deployment is there where only some small percent of traffic is routed here which is the newer version of application (current app's).
- So, once all tests are done on canary deployment then canary deployment is taken down and current primary version application (pods) are upgraded with newer version of application.
- Also called as Package Manager
- Manages all Objects of an application like pods, deployments, services, etc. at one place.
- If we need to update some values of some objects we can just use values.yaml file and pass in necessary key and value pairs to it and apply a
helm upgradecommand.
- Together value.yaml file & template files of objects form the Helm Chart.
NOTE : You can refer to already created charts by other people here : Artifact Hub
Some Helm commands :
helm install [release-name] [chart-name]
- We can write our custom logic for
Schedulerif we want some specific conditions to be met - Steps to use the custom scheduler:
- Download the scheduler binary from k8s website
- Create a config file for scheduler where we will define the configuration for custom scheduler like the name, leader, etc
- Create a pod or deployment where we would point the config flag to the newly created custom scheduler in the above step
- Just create the above pod and check if Scheduler is created or not
- Now, create a pod and add
schedulerNameproperty and add the name of the created custom scheduler to it
# to check if pod is scheduler on that custom scheduler
kubectl get events -o wide
- No master node, only a node and
Kubeletis present on it with a container runtime ed Docker & no K8S Cluster - Kubelet knows hows to create Pods
- It can create Pods by periodically checking the folder /etc/kubernetes/manifests in the node where kubelet is running
- Basicaly why use Static Pods?
- Because you can setup your control plane components such as API server, controller manager, scheduler, etc (as they all are pods).
- So, Kubelet is to be installed on the
Master Node& then just run the Pod manifests of all the components of control plane - This is how the cluster is setup using the
kubeadmtool.
- In order to view Performance Metrics in k8s Cluster
- We first need to enable the
metrics server
# to view the cpu and memory usage by node
kubectl top node
# to view the cpu and memory usage by pod
kubectl top pod
# can check on which nodes the pods are scheduled
kubectl get pods -o wide
- When we drain a node, the pods on that node are gracefully terminated and then recreated on the other node in the cluster (If there are other nodes present)
- The node is then marked as
cordonorunschedulable - Then when the node is upgraded and rebooted you need to mark it uncordon
# to drain a node and evict pods on that node
kubectl drain node01 --ignore-daemonsets
# marks the node schedulable
kubectl uncordon node_1
# marks the node unschedulable & it does not drain the node or move the pods
# makes sure no new pods are scheduled on this node
kubectl cordon node_1
- K8S only supports 3 minor versions at a time
- And no other components can be at higher version than the api-server
- Upgrade one minor v at a time to reach the latest version
NOTE : Always upgrade the control plane (MASTER) first
1. Upgrade the kudeadm version to k8s version we want to upgrade to
2. Then drain the control plane and upgrade it and also upgrade the kubelet version
3. Now uncordon the control plane
4. Repeat the above steps for worker nodes
NOTE: Also, when we drain or uncordon the node we need to do it from the control plane. Even for worker nodes we need to do it on the control plane(basically run the drain and uncordon commands)
NOTE: To check on which nodes the pods are runnning kubectl get pods -o wide
- For ETCD data-dir (inside etcd.service file)is where the
cluster stateis stored - For taking a backup you need to run the
snapshot savecommand with respective arguments (basically certificates, endpoints, etc) - For restoring the backup you just need to run the restore command (refer the doc) and pass no arguments to it since the restore is on the local machine where the etcd is present
- Consider public and private key where public key can be assumed as a
LOCKand can be used to encrypt data and private key used for decrypt the data which is encrypted by public key - CA is Certificate Authority which are legit organizations that signs the requested certificate
- First, a CSR using the key you generated first on the server and the domain name
- The CA signs certificate and then is being used by Server
TIP : If any pod does not work just do a docker ps -a & find out the id and then check the logs and try to find out why that pod (basically container) exited or did not work
- Ingres -> Incoming traffic to that pod and Egress -> Outgoing traffic from that pod
- The response does not need any rule for eg if a n/w policy ingress on port 3306 is allowed then the response of db query does not require a separate rule
- Used to retain/persist data of pod
- As we know that containers are ephemeral so we need to store the data that is generated by the pod(containers) so
VOLUMEScome into picture
- It is basically a pool of Storage Volumes (a lot of storage types/options -> collection it is) which is used by the pod to claim the type of storage option it requires
- Admin creates the
Collectionn of Persistent Volumes
- The user creates PVC to use the Storage as per the need
- There is a one to one relation between the PVC and PV so even if the full capacity is not used of the Volume it cannot be used by other claim as it is a one to one relationship
- Here we don't need to explicitly create a PV since if Storage class uses a dynamic provisioner then it automatically creates a PV and assigns that to the PVC
- ip link -> to see the n/w interface of the host
Switch-> Its like a bridge where we can connect any no of devices to switch and then that switch assigns IP address to all the devices connected to that switch so now they all belong to the same networkRouter-> It is used to connect one or more different networks together where devices from different n/w can talk to devices on different n/w and all this is possible because of routerGateway-> It acts as a door before the router/host to guide the packets to respected destination (in a different n/w)
# to get the interface on that host
ip link
# to get the ip address
ip addr
# this will add the ip address to the device
ip addr add 192.168.1.10/24 dev eth0
# to check the route table of the device
ip route
# to add entry in route table gateway and destination
ip route add 192.168.1.0/24 <dest-ip> via 192.168.2.1 <gateway ip>
# change the below to 1 to allow to pass packets to destination through the host
cat /proc/sys/net/ipv4/ip_forward
0