{kind=link}
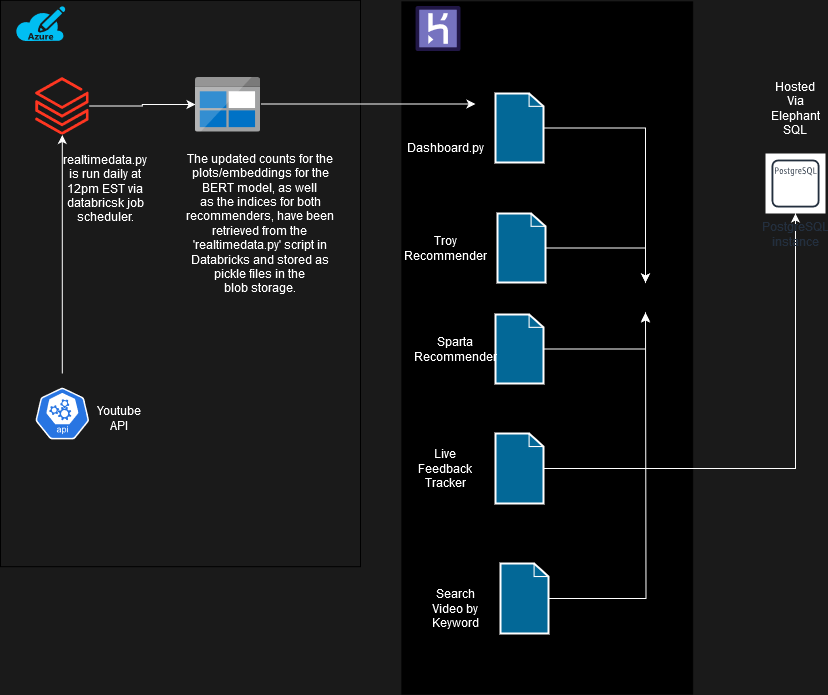
I designed and deployed a machine learning web application that uses data from the FreeCodeCamp YouTube channel to compare the popularity of videos related to emerging technologies. The application includes two content-based recommender systems: Troy, which is based on BERT, and Sparta, which is a hybrid model using TFIDF and user likes for the corresponding videos. These recommender systems suggest similar videos to users based on their selection of technology-related content.
The application is hosted on Heroku server using Docker, and I've set up a CI/CD pipeline with Git and GitHub Actions for efficient management.
By offering a mechanism to collect user feedback for the Troy and Sparta recommender systems via the Live Feedback tracker, we can leverage this data to conduct A/B testing using both Frequentist and Bayesian testing approaches. A detailed analysis is provided in the attached Jupyter notebook.
- demo on Heroku: https://freecodecampwebapp.herokuapp.com/


-
Clone the repository by running the following command: git clone https://github.com/saldanhad/freecodecampmlapp
-
Get your Youtube API key, by creating your project in your GCP environment, refer to video tutorial by Thu Vu, next generate two databases for the sparta and troy systems respectively using Elephant SQL and retrive the API key, refer to video tutorial by Sven, enter these details in a .env file.
-
Install the required Python packages by running the following command: pip install -r requirements.txt
-
Run the code by executing the following file in the Python interpreter: streamlit run Dashboard.py
- Create tables to track feedback for each of the models, table names - feedback_trackertroy, feedback_trackersparta

Framework to run A/B Test to compare Troy vs Sparta recommenders using Frequentist and Bayesian Approach.
-
The North Star Metric used is # of users that provide a rating of 4 or greater out of total 5 star ratings. For each of the recommenders the ratings are being tabulated via the feedback section in the recommender pages and stored in a Postgresql DB for A/B test use.
-
Using the Frequentist Approach and Power Analysis we are able to commute that the minimum sample size required to perform an A/B test is 4800 samples for both control (Sparta model) and treatement group (Troy Model):
Please refer to power analysis plot below:

- Also proposed a framework to use Bayesian testing using Monte Carlo Simulation to generate random posterior probabilities.
For detailed analysis please refer to the attached A_B_Test_Compare_Recommender_Systems.ipynb file.
-
Vu, Thu[Thu Vu]. (2022, Jan 22).Youtube API for Python: How to Create a Unique Data Portfolio Project.Youtube. https://www.youtube.com/watch?v=D56_Cx36oGY
-
Sven[Coding is Fun].(2022,Jun 26).Build A Streamlit Web App From Scratch (incl. NoSQL Database + interactive Sankey chart).Youtube. https://www.youtube.com/watch?v=3egaMfE9388
-
reimers-2019-sentence-bert, title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks", author = "Reimers, Nils and Gurevych, Iryna", booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing", month = "11", year = "2019", publisher = "Association for Computational Linguistics", url = "http://arxiv.org/abs/1908.10084",