


- Contents
- About Chronicle Software
- What is Chronicle Queue
- Downloading Chronicle Queue
- Simple Step-By-Step Guide
- Overview
- Chronicle Queue (Enterprise Edition)
- How does Chronicle Queue work
- Use Cases
- Using Chronicle Queue
- Writing to a Queue
- Finding the index at the end of a Chronicle Queue
- How to determine how many messages are between two indexes
- How to write 10 messages, then move to the 5th message to read it.
- Command line tools - reading and writing a Chronicle Queue
- Reading from a Queue using a Tailer
- Restartable Tailers
- High level interface
- Building Blocks
- Pretoucher configuration
- File Rolling
- File Handles and Flushing Data to the Disk
- Double-buffering for contended writes
- The Changes from Chronicle Queue version 4 to version 5
- Changes from Chronicle Queue v3
- Design
- Chronicle Queue vs Kafka
- Support
- Replication
- FAQs
- Can Chronicle Queue Work on OpenJ9
- How can I determine the speed of my disk sub system
- How many messages can you store in a Chronicle Queue?
- Is there an Appender to Tailer notification?
- Unlocking a locked queue
- Creating Chronicle Queue on Network File System (NFS) mount
- Configuration
- Running under Docker
- The Maximum number of messages per cycle
- More information
What is Chronicle Queue
-
You could consider Chronicle Queue to be similar to a low latency broker less durable/persisted JVM topic.
Chronicle Queue is a distributed unbounded persisted queue. Chronicle Queue:
-
supports asynchronous RMI and Publish/Subscribe interfaces with microsecond latencies.
-
passes messages between JVMs in under a microsecond (in optimised examples)
-
passes messages between JVMs on different machines via replication in under 10 microseconds (in optimised examples)
-
provides stable, soft, real-time latencies into the millions of messages per second for a single thread to one queue; with total ordering of every event.
When publishing 40-byte messages, a high percentage of the time we achieve latencies under 1 microsecond. The 99th percentile latency is the worst 1 in 100, and the 99.9th percentile is the worst 1 in 1000 latency.
| Batch Size | 10 million events per minute | 60 million events per minute | 100 million events per minute |
|---|---|---|---|
99%ile |
0.78 µs |
0.78 µs |
1.2 µs |
99.9%ile |
1.2 µs |
1.3 µs |
1.5 µs |
| Batch Size | 10 million events per minute | 60 million events per minute | 100 million events per minute |
|---|---|---|---|
99%ile |
20 µs |
28 µs |
176 µs |
99.9%ile |
901 µs |
705 µs |
5,370 µs |
|
Note
|
100 million events per minute is sending an event every 660 nanoseconds; replicated and persisted. |
|
Important
|
This performance is not achieved using a large cluster of machines. This is using one thread to publish, and one thread to consume. |
Releases are available on Maven Central as:
<dependency>
<groupId>net.openhft</groupId>
<artifactId>chronicle-queue</artifactId>
<version><!--replace with the latest version, see below--></version>
</dependency>Click here to get the Latest Version Number
Snapshots are available on https://oss.sonatype.org
Ths project covers the Java version of Chronicle Queue. Chronicle Queue is a persisted low-latency messaging framework for high performance and critical applications. A C++ version of this project is also available and can be evaluated upon request. If you are interested in looking at the C++ version please contact sales@chronicle.software.
At first glance Chronicle Queue can be seen as simply another queue implementation. However, it has major design choices that should be emphasised.
Using non-heap storage options (RandomAccessFile), Chronicle Queue provides a processing environment where applications do not suffer from Garbage Collection (GC).
When implementing high-performance and memory-intensive applications (you heard the fancy term "bigdata"?) in Java, one of the biggest problems is garbage collection.
Garbage collection may slow down your critical operations non-deterministically at any time. In order to avoid non-determinism, and escape from garbage collection delays, off-heap memory solutions are ideal. The main idea is to manage your memory manually so it does not suffer from garbage collection. Chronicle Queue behaves like a management interface over off-heap memory so you can build your own solutions over it.
Chronicle Queue uses RandomAccessFiles while managing memory and this choice brings lots of possibilities. RandomAccessFiles permit non-sequential, or random, access to a file’s contents.
To access a file randomly, you open the file, seek a particular location, and read from or write to that file.
RandomAccessFiles can be seen as "large" C-type byte arrays that you can access at any random index "directly" using pointers.
File portions can be used as ByteBuffers if the portion is mapped into memory.
This memory mapped file is also used for exceptionally fast interprocess communication (IPC) without affecting your system performance. There is no garbage collection as everything is done off-heap.
Chronicle Queue (Enterprise Edition) is a commercially supported version of our successful open source Chronicle Queue.
The open source documentation is extended by this document to describe the additional features that are available when you are licenced for Enterprise Edition. These are:
-
Encryption of message queues and messages. For more information see Encryption.
-
TCP/IP Replication between hosts to ensure real-time backup of all your queue data. For more information see Replication, the protocol is covered here.
-
Timezone support for daily queue rollover scheduling. For more information see Timezone support.
-
Ring Buffer support to give improved performance at high throughput on slower filesystems. For more information see Ring Buffer and also performance.
In addition, you will be fully supported by our technical experts.
For more information on Chronicle Queue (Enterprise Edition), please contact sales@chronicle.software.
Classes that reside in either of the packages 'internal', 'impl', and 'main' (the latter containing various runnable main methods) and
any sub-packages are not a part of the public API and may become subject to change at any time for any reason. See the respective package-info.java files for details.
-
Messages are grouped by topics. A topic can contain any number of sub-topics which are logically stored together under the queue/topic.
-
An appender is the source of messages.
-
A tailer is a receiver of messages.
-
Chronicle Queue is broker-less by default. You can use Chronicle Datagrid to act as a broker for remote access.
|
Note
|
We deliberately avoid the term consumer as messages are not consumed/destroyed by reading. |
At a high level:
-
appenders write to the end of a queue. There is no way to insert, or delete excerpts.
-
tailers read the next available message each time they are called.
By using Chronicle Datagrid, a Java or C# client can publish to a queue to act as a remote appender, and you subscribe to a queue to act as a remote tailer.
Chronicle Queue does not support operating off any network file system, be it NFS, AFS, SAN-based storage or anything else. The reason for this is those file systems do not provide all the required primitives for memory-mapped files Chronicle Queue uses.
If any networking is needed (e.g. to make the data accessible to multiple hosts), the only supported way is Chronicle Queue Replication (Enterprise feature).
Each topic is a directory of queues.
There is a file for each roll cycle.
If you have a topic called mytopic, the layout could look like this:
mytopic/
20160710.cq4
20160711.cq4
20160712.cq4
20160713.cq4To copy all the data for a single day (or cycle), you can copy the file for that day on to your development machine for replay testing.
You can add a StoreFileListener to notify you when a file is added, or no longer used.
This can be used to delete files after a period of time.
However, by default, files are retained forever.
Our largest users have over 100 TB of data stored in queues.
The only thing each tailer retains is an index which is composed from:
-
a cycle number. For example, days since epoch, and
-
a sequence number within that cycle.
In the case of a
DAILYcycle, the sequence number is 32 bit and theindex = ((long) cycle << 32) | sequenceNumberproviding up to 4 billion entries per day. if more messages per day are anticipated, theXLARGE_DAILYcycle, for example, provides up 4 trillion entries per day using a 48-bit sequence number.Printing the index in hexadecimal is common in our libraries, to make it easier to see these two components.
Appenders and tailers are cheap as they don’t even require a TCP connection; they are just a few Java objects.
Rather than partition the queue files across servers, we support each server, storing as much data as you have disk space. This is much more scalable than being limited to the amount of memory space that you have. You can buy a redundant pair of 6TB of enterprise disks very much more cheaply than 6TB of memory.
Topics are limited to being strings which can be used as directory names. Within a topic, you can have sub-topics which can be any data type that can be serialized. Messages can be any serializable data.
Chronicle Queue supports:
-
Serializableobjects, though this is to be avoided as it is not efficient -
Externalizableobjects is preferred if you wish to use standard Java APIs. -
byte[]andString -
Marshallable; a self describing message which can be written as YAML, Binary YAML, or JSON. -
BytesMarshallablewhich is low-level binary, or text encoding.
An abstraction can be added to filter messages, or assign messages to just one message processor. However, in general you only need one main tailer for a topic, with possibly, some supporting tailers for monitoring etc.
As Chronicle Queue doesn’t partition its topics, you get total ordering of all messages within that topic. Across topics, there is no guarantee of ordering; if you want to replay deterministically from a system which consumes from multiple topics, we suggest replaying from that system’s output.
It is common practice to replay a state machine from its inputs. To do this, there are two assumptions that you have to make; these are difficult to implement;
-
you have either just one input, or you can always determine the order the inputs were consumed,
-
you have not changed the software (or all the software is stored in the queue).
You can see from this that if you want to be able to upgrade your system, then you’ll want to replay from the output.
Replaying from the output means that;
-
you have a record of the order of the inputs that you processed
-
you have a record of all the decisions your new system is committed to; even if the new code would have made different decisions.
Chronicle Queue provides the following guarantees;
-
for each appender, messages are written in the order the appender wrote them. Messages by different appenders are interleaved,
-
for each tailer, it will see every message for a topic in the same order as every other tailer,
-
when replicated, every replica has a copy of every message.
Replication has three modes of operation;
-
replicate as soon as possible; < 1 millisecond in as many as 99.9% of cases,
-
a tailer will only see messages which have been replicated,
-
an appender doesn’t return until a replica has acknowledged it has been received.
Chronicle Queue is most often used for producer-centric systems where you need to retain a lot of data for days or years.
Most messaging systems are consumer-centric. Flow control is implemented to avoid the consumer ever getting overloaded; even momentarily. A common example is a server supporting multiple GUI users. Those users might be on different machines (OS and hardware), different qualities of network (latency and bandwidth), doing a variety of other things at different times. For this reason it makes sense for the client consumer to tell the producer when to back off, delaying any data until the consumer is ready to take more data.
Chronicle Queue is a producer-centric solution and does everything possible to never push back on the producer, or tell it to slow down. This makes it a powerful tool, providing a big buffer between your system, and an upstream producer over which you have little, or no, control.
Market data publishers don’t give you the option to push back on the producer for long; if at all. A few of our users consume data from CME OPRA. This produces peaks of 10 million events per minute, sent as UDP packets without any retry. If you miss, or drop a packet, then it is lost. You have to consume and record those packets as fast as they come to you, with very little buffering in the network adapter.
For market data in particular, real time means in a few microseconds; it doesn’t mean intra-day (during the day).
Chronicle Queue is fast and efficient, and has been used to increase the speed that data is passed between threads. In addition, it also keeps a record of every message passed allowing you to significantly reduce the amount of logging that you need to do.
Compliance Systems are required by more and more systems these days. Everyone has to have them, but no one wants to be slowed down by them. By using Chronicle Queue to buffer data between monitored systems and the compliance system, you don’t need to worry about the impact of compliance recording for your monitored systems.
Again, Chronicle Queue can support millions of events per-second, per-server, and access data which has been retained for years.
Chronicle Queue supports low latency IPC (Inter Process Communication) between JVMs on the same machine in the order of magnitude of 1 microsecond; as well as between machines with a typical latency of 10 microseconds for modest throughputs of a few hundred thousands. Chronicle Queue supports throughputs of millions of events per second, with stable microsecond latencies.
Chronicle Queue can be monitored to obtain latency, throughput, and activity metrics, in real time (that is, within microseconds of the event triggering it).
As Chronicle Queue can be used to build state machines. All the information about the state of those components can be reproduced externally, without direct access to the components, or to their state. This significantly reduces the need for additional logging.
However, any logging you do need can be recorded in great detail.
This makes enabling DEBUG logging in production practical.
This is because the cost of logging is very low; less than 10 microseconds.
Logs can be replicated centrally for log consolidation.
Chronicle Queue is being used to store 100+ TB of data, which can be replayed from any point in time.
Non-batching streaming components are highly performant, deterministic, and reproducible. You can reproduce bugs which only show up after a million events played in a particular order, with accelerated realistic timings.
This makes using Stream Processing attractive for systems which need a high degree of quality outcomes.
Chronicle Queue is designed to be driven from code.You can easily add an interface which suits your needs.
|
Note
|
Due to fairly low-level operation, Chronicle Queue read/write operations can throw unchecked exceptions.In order to prevent thread death, it might be practical to catch `RuntimeException`s and log/analyze them as appropriate. |
In Chronicle Queue we refer to the act of writing your data to the Chronicle queue, as storing an excerpt.This data could be made up from any data type, including text, numbers, or serialised blobs.Ultimately, all your data, regardless of what it is, is stored as a series of bytes.
Just before storing your excerpt, Chronicle Queue reserves a 4-byte header.Chronicle Queue writes the length of your data into this header.This way, when Chronicle Queue comes to read your excerpt, it knows how long each blob of data is.We refer to this 4-byte header, along with your excerpt, as a document.So strictly speaking Chronicle Queue can be used to read and write documents.
|
Note
|
Within this 4-byte header we also reserve a few bits for a number of internal operations, such as locking, to make Chronicle Queue thread-safe across both processors and threads. The important thing to note is that because of this, you can’t strictly convert the 4 bytes to an integer to find the length of your data blob. |
To write data to a Chronicle-Queue, you must first create an Appender
try (ChronicleQueue queue = ChronicleQueue.singleBuilder(path + "/trades").build()) {
final ExcerptAppender appender = queue.acquireAppender();
}So, Chronicle Queue uses an Appender to write to the queue and a Tailer to read from the queue.Unlike other java queuing solutions, messages are not lost when they are read with a Tailer.This is covered in more detail in the section below on "Reading from a Queue".
Chronicle Queue uses the following low-level interface to write the data:
try (final DocumentContext dc = appender.writingDocument()) {
dc.wire().write().text(“your text data“);
}The close on the try-with-resources, is the point when the length of the data is written to the header.You can also use the DocumentContext to find out the index that your data has just been assigned (see below).You can later use this index to move-to/look up this excerpt.Each Chronicle Queue excerpt has a unique index.
try (final DocumentContext dc = appender.writingDocument()) {
dc.wire().write().text(“your text data“);
System.out.println("your data was store to index="+ dc.index());
}The high-level methods below such as writeText() are convenience methods on calling appender.writingDocument(), but both approaches essentially do the same thing.The actual code of writeText(CharSequence text) looks like this:
/**
* @param text to write a message
*/
void writeText(CharSequence text) {
try (DocumentContext dc = writingDocument()) {
dc.wire().bytes().append8bit(text);
}
}So you have a choice of a number of high-level interfaces, down to a low-level API, to raw memory.
This is the highest-level API which hides the fact you are writing to messaging at all.The benefit is that you can swap calls to the interface with a real component, or an interface to a different protocol.
// using the method writer interface.
RiskMonitor riskMonitor = appender.methodWriter(RiskMonitor.class);
final LocalDateTime now = LocalDateTime.now(Clock.systemUTC());
riskMonitor.trade(new TradeDetails(now, "GBPUSD", 1.3095, 10e6, Side.Buy, "peter"));You can write a "self-describing message".Such messages can support schema changes.They are also easier to understand when debugging or diagnosing problems.
// writing a self describing message
appender.writeDocument(w -> w.write("trade").marshallable(
m -> m.write("timestamp").dateTime(now)
.write("symbol").text("EURUSD")
.write("price").float64(1.1101)
.write("quantity").float64(15e6)
.write("side").object(Side.class, Side.Sell)
.write("trader").text("peter")));You can write "raw data" which is self-describing.The types will always be correct; position is the only indication as to the meaning of those values.
// writing just data
appender.writeDocument(w -> w
.getValueOut().int32(0x123456)
.getValueOut().int64(0x999000999000L)
.getValueOut().text("Hello World"));You can write "raw data" which is not self-describing.Your reader must know what this data means, and the types that were used.
// writing raw data
appender.writeBytes(b -> b
.writeByte((byte) 0x12)
.writeInt(0x345678)
.writeLong(0x999000999000L)
.writeUtf8("Hello World"));Below, the lowest level way to write data is illustrated.You get an address to raw memory and you can write whatever you want.
// Unsafe low level
appender.writeBytes(b -> {
long address = b.address(b.writePosition());
Unsafe unsafe = UnsafeMemory.UNSAFE;
unsafe.putByte(address, (byte) 0x12);
address += 1;
unsafe.putInt(address, 0x345678);
address += 4;
unsafe.putLong(address, 0x999000999000L);
address += 8;
byte[] bytes = "Hello World".getBytes(StandardCharsets.ISO_8859_1);
unsafe.copyMemory(bytes, Jvm.arrayByteBaseOffset(), null, address, bytes.length);
b.writeSkip(1 + 4 + 8 + bytes.length);
});You can print the contents of the queue.You can see the first two, and last two messages store the same data.
// dump the content of the queue
System.out.println(queue.dump());prints:
# position: 262568, header: 0
--- !!data #binary
trade: {
timestamp: 2016-07-17T15:18:41.141,
symbol: GBPUSD,
price: 1.3095,
quantity: 10000000.0,
side: Buy,
trader: peter
}
# position: 262684, header: 1
--- !!data #binary
trade: {
timestamp: 2016-07-17T15:18:41.141,
symbol: EURUSD,
price: 1.1101,
quantity: 15000000.0,
side: Sell,
trader: peter
}
# position: 262800, header: 2
--- !!data #binary
!int 1193046
168843764404224
Hello World
# position: 262830, header: 3
--- !!data #binary
000402b0 12 78 56 34 00 00 90 99 00 90 99 00 00 0B ·xV4·· ········
000402c0 48 65 6C 6C 6F 20 57 6F 72 6C 64 Hello Wo rld
# position: 262859, header: 4
--- !!data #binary
000402c0 12 ·
000402d0 78 56 34 00 00 90 99 00 90 99 00 00 0B 48 65 6C xV4····· ·····Hel
000402e0 6C 6F 20 57 6F 72 6C 64 lo WorldChronicle Queue appenders are thread-local. In fact when you ask for:
final ExcerptAppender appender = queue.acquireAppender();the acquireAppender() uses a thread-local pool to give you an appender which will be reused to reduce object creation.
As such, the method call to:
long index = appender.lastIndexAppended();will only give you the last index appended by this appender; not the last index appended by any appender.
If you wish to find the index of the last record written to the queue, then you have to call:
queue.lastIndex()Which will return the index of the last excerpt present in the queue (or -1 for an empty queue). Note that if the queue is being written to concurrently it’s possible the value may be an under-estimate, as subsequent entries may have been written even before it was returned.
to count the number of messages between two indexes you can use:
((SingleChronicleQueue)queue).countExcerpts(<firstIndex>,<lastIndex>);|
Note
|
You should avoid calling this method on latency sensitive code, because if the indexes are in different cycles this method may have to access the .cq4 files from the file system. |
for more information on this see :
net.openhft.chronicle.queue.impl.single.SingleChronicleQueue.countExcerpts@Test
public void read5thMessageTest() {
try (final ChronicleQueue queue = singleBuilder(getTmpDir()).build()) {
final ExcerptAppender appender = queue.acquireAppender();
int i = 0;
for (int j = 0; j < 10; j++) {
try (DocumentContext dc = appender.writingDocument()) {
dc.wire().write("hello").text("world " + (i++));
long indexWritten = dc.index();
}
}
// get the current cycle
int cycle;
final ExcerptTailer tailer = queue.createTailer();
try (DocumentContext documentContext = tailer.readingDocument()) {
long index = documentContext.index();
cycle = queue.rollCycle().toCycle(index);
}
long index = queue.rollCycle().toIndex(cycle, 5);
tailer.moveToIndex(index);
try (DocumentContext dc = tailer.readingDocument()) {
System.out.println(dc.wire().read("hello").text());
}
}
}Chronicle Queue stores its data in binary format, with a file extension of cq4:
\��@π�header∂�SCQStoreÇE���»wireType∂�WireTypeÊBINARYÕwritePositionèèèèß��������ƒroll∂�SCQSRollÇ*���∆length¶ÄÓ6�∆format
ÎyyyyMMdd-HH≈epoch¶ÄÓ6�»indexing∂
SCQSIndexingÇN��� indexCount•��ÃindexSpacing�Àindex2Indexé����ß��������…lastIndexé�
���ß��������fllastAcknowledgedIndexReplicatedé������ߡˇˇˇˇˇˇˇ»recovery∂�TimedStoreRecoveryÇ����…timeStampèèèß����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������This can often be a bit difficult to read, so it is better to dump the cq4 files as text. This can also help you fix your production issues, as it gives you the visibility as to what has been stored in the queue, and in what order.
You can dump the queue to the terminal using net.openhft.chronicle.queue.main.DumpMain or net.openhft.chronicle.queue.ChronicleReaderMain. DumpMain performs a simple dump to the terminal while ChronicleReaderMain handles more complex operations, e.g. tailing a queue. They can both be run from the command line in a number of ways described below.
If you have a project pom file that includes the Chronicle-Queue artifact, you can read a cq4 file with the following command:
$ mvn exec:java -Dexec.mainClass="net.openhft.chronicle.queue.main.DumpMain" -Dexec.args="myqueue"|
Note
|
myqueue is the directory containing your .cq4 files |
You can also set up any dependent files manually. This requires the chronicle-queue.jar, from any version 4.5.3 or later, and that all dependent files are present on the class path. The dependent jars are listed below:
$ ls -ltr
total 9920
-rw-r--r-- 1 robaustin staff 112557 28 Jul 14:52 chronicle-queue-5.20.108.jar
-rw-r--r-- 1 robaustin staff 209268 28 Jul 14:53 chronicle-bytes-2.20.104.jar
-rw-r--r-- 1 robaustin staff 136434 28 Jul 14:56 chronicle-core-2.20.114.jar
-rw-r--r-- 1 robaustin staff 33562 28 Jul 15:03 slf4j-api-1.7.30.jar
-rw-r--r-- 1 robaustin staff 33562 28 Jul 15:03 slf4j-simple-1.7.30.jar
-rw-r--r-- 1 robaustin staff 324302 28 Jul 15:04 chronicle-wire-2.20.105.jar
-rw-r--r-- 1 robaustin staff 35112 28 Jul 15:05 chronicle-threads-2.20.101.jar
-rw-r--r-- 1 robaustin staff 344235 28 Jul 15:05 affinity-3.20.0.jar
-rw-r--r-- 1 robaustin staff 124332 28 Jul 15:05 commons-cli-1.4.jar
-rw-r--r-- 1 robaustin staff 4198400 28 Jul 15:06 19700101-02.cq4|
Tip
|
To find out which version of jars to include please, refer to the chronicle-bom.
|
Once the dependencies are present on the class path, you can run:
$ java -cp chronicle-queue-5.20.108.jar net.openhft.chronicle.queue.main.DumpMain 19700101-02.cq4This will dump the 19700101-02.cq4 file out as text, as shown below:
!!meta-data #binary
header: !SCQStore {
wireType: !WireType BINARY,
writePosition: 0,
roll: !SCQSRoll {
length: !int 3600000,
format: yyyyMMdd-HH,
epoch: !int 3600000
},
indexing: !SCQSIndexing {
indexCount: !short 4096,
indexSpacing: 4,
index2Index: 0,
lastIndex: 0
},
lastAcknowledgedIndexReplicated: -1,
recovery: !TimedStoreRecovery {
timeStamp: 0
}
}
...
# 4198044 bytes remaining|
Note
|
The example above does not show any user data, because no user data was written to this example file. |
There is also a script named dump_queue.sh located in the Chonicle-Queue/bin-folder that gathers the needed dependencies in a shaded jar and uses it to dump the queue with DumpMain. The script can be run from the Chronicle-Queue root folder like this:
$ ./bin/dump_queue.sh <file path>The second tool for logging the contents of the chronicle queue is the ChronicleReaderMain (in the Chronicle Queue project). As mentioned above, it is able to perform several operations beyond printing the file content to the console. For example, it can be used to tail a queue to detect whenever new messages are added (rather like $tail -f).
Below is the command line interface used to configure ChronicleReaderMain:
usage: ChronicleReaderMain
-d <directory> Directory containing chronicle queue files
-e <exclude-regex> Do not display records containing this regular
expression
-f Tail behaviour - wait for new records to arrive
-h Print this help and exit
-i <include-regex> Display records containing this regular expression
-l Squash each output message into a single line
-m <max-history> Show this many records from the end of the data set
-n <from-index> Start reading from this index (e.g. 0x123ABE)
-r <interface> Use when reading from a queue generated using a MethodWriter
-s Display index
-w <wire-type> Control output i.e. JSON
Just as with DumpQueue you need the classes in the example above present on the class path. This can again be achieved by manually adding them and then run:
$ java -cp chronicle-queue-5.20.108.jar net.openhft.chronicle.queue.ChronicleReaderMain -d <directory>Another option is to create an Uber Jar using the Maven shade plugin. It is configured as follows:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<includes>
<include>net/openhft/**</include>
<include>software/chronicle/**</include>
</includes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>Once the Uber jar is present, you can run ChronicleReaderMain from the command line via:
java -cp "$UBER_JAR" net.openhft.chronicle.queue.ChronicleReaderMain "19700101-02.cq4"
Lastly, there is a script for running the reader named queue_reader.sh which again is located in the Chonicle-Queue/bin-folder. It automatically gathers the needed dependencies in a shaded jar and uses it to run ChronicleReaderMain. The script can be run from the Chronicle-Queue root folder like this:
$ ./bin/queue_reader.sh <options>If using MethodReaders and MethodWriters then you can write single-argument method calls to a queue
using net.openhft.chronicle.queue.ChronicleWriterMain or the shell script queue_writer.sh e.g.
usage: ChronicleWriterMain files.. -d <directory> [-i <interface>] -m <method>
Missing required options: m, d
-d <directory> Directory containing chronicle queue to write to
-i <interface> Interface to write via
-m <method> Method nameIf you want to write to the below "doit" method
public interface MyInterface {
void doit(DTO dto);
}
public class DTO extends SelfDescribingMarshallable {
private int age;
private String name;
}Then you can call ChronicleWriterMain -d queue doit x.yaml with either (or both) of the below Yamls:
{
age: 19,
name: Henry
}or
!x.y.z.DTO {
age: 42,
name: Percy
}If DTO makes use of custom serialisation then you should specify the interface to write to with -i
Reading the queue follows the same pattern as writing, except there is a possibility there is not a message when you attempt to read it.
try (ChronicleQueue queue = ChronicleQueue.singleBuilder(path + "/trades").build()) {
final ExcerptTailer tailer = queue.createTailer();
}You can turn each message into a method call based on the content of the message, and have Chronicle Queue automatically deserialise the method arguments.Calling reader.readOne() will automatically skip over (filter out) any messages that do not match your method reader.
// reading using method calls
RiskMonitor monitor = System.out::println;
MethodReader reader = tailer.methodReader(monitor);
// read one message
assertTrue(reader.readOne());You can decode the message yourself.
|
Note
|
The names, type, and order of the fields doesn’t have to match. |
assertTrue(tailer.readDocument(w -> w.read("trade").marshallable(
m -> {
LocalDateTime timestamp = m.read("timestamp").dateTime();
String symbol = m.read("symbol").text();
double price = m.read("price").float64();
double quantity = m.read("quantity").float64();
Side side = m.read("side").object(Side.class);
String trader = m.read("trader").text();
// do something with values.
})));You can read self-describing data values.This will check the types are correct, and convert as required.
assertTrue(tailer.readDocument(w -> {
ValueIn in = w.getValueIn();
int num = in.int32();
long num2 = in.int64();
String text = in.text();
// do something with values
}));You can read raw data as primitives and strings.
assertTrue(tailer.readBytes(in -> {
int code = in.readByte();
int num = in.readInt();
long num2 = in.readLong();
String text = in.readUtf8();
assertEquals("Hello World", text);
// do something with values
}));or, you can get the underlying memory address and access the native memory.
assertTrue(tailer.readBytes(b -> {
long address = b.address(b.readPosition());
Unsafe unsafe = UnsafeMemory.UNSAFE;
int code = unsafe.getByte(address);
address++;
int num = unsafe.getInt(address);
address += 4;
long num2 = unsafe.getLong(address);
address += 8;
int length = unsafe.getByte(address);
address++;
byte[] bytes = new byte[length];
unsafe.copyMemory(null, address, bytes, Jvm.arrayByteBaseOffset(), bytes.length);
String text = new String(bytes, StandardCharsets.UTF_8);
assertEquals("Hello World", text);
// do something with values
}));Chronicle queue tailers may create file handlers, the file handlers are cleaned up whenever the associated chronicle queue’s close() method is invoked or whenever the Jvm runs a Garbage Collection.
If you are writing your code not have GC pauses and you explicitly want to clean up the file handlers, you can call the following:
((StoreTailer)tailer).releaseResources()In some applications, it may be necessary to start reading from the end of the queue (e.g. in a restart scenario).
For this use-case, ExcerptTailer provides the toEnd()
method.
When the tailer direction is FORWARD (by default, or as set by the ExcerptTailer.direction
method), then calling toEnd() will place the tailer just after the last existing record in the queue.
In this case, the tailer is now ready for reading any new records appended to the queue.
Until any new messages are appended to the queue, there will be no new DocumentContext
available for reading:
// this will be false until new messages are appended to the queue
boolean messageAvailable = tailer.toEnd().readingDocument().isPresent();If it is necessary to read backwards through the queue from the end, then the tailer can be set to read backwards:
ExcerptTailer tailer = queue.createTailer();
tailer.direction(TailerDirection.BACKWARD).toEnd();When reading backwards, then the toEnd() method will move the tailer to the last record in the queue.
If the queue is not empty, then there will be a
DocumentContext available for reading:
// this will be true if there is at least one message in the queue
boolean messageAvailable = tailer.toEnd().direction(TailerDirection.BACKWARD).
readingDocument().isPresent();It can be useful to have a tailer which continues from where it was up to on restart of the application.
try (ChronicleQueue cq = SingleChronicleQueueBuilder.binary(tmp).build()) {
ExcerptTailer atailer = cq.createTailer("a");
assertEquals("test 0", atailer.readText());
assertEquals("test 1", atailer.readText());
assertEquals("test 2", atailer.readText()); // (1)
ExcerptTailer btailer = cq.createTailer("b");
assertEquals("test 0", btailer.readText()); // (3)
}
try (ChronicleQueue cq = SingleChronicleQueueBuilder.binary(tmp).build()) {
ExcerptTailer atailer = cq.createTailer("a");
assertEquals("test 3", atailer.readText()); // (2)
assertEquals("test 4", atailer.readText());
assertEquals("test 5", atailer.readText());
ExcerptTailer btailer = cq.createTailer("b");
assertEquals("test 1", btailer.readText()); // (4)
}-
Tailer "a" last reads message 2
-
Tailer "a" next reads message 3
-
Tailer "b" last reads message 0
-
Tailer "b" next reads message 1
This is from the RestartableTailerTest where there are two tailers, each with a unique name.
These tailers store their index within the Queue itself and this index is maintained as the tailer uses toStart(), toEnd(), moveToIndex() or reads a message.
|
Note
|
The direction() is not preserved across restarts, only the next index to be read.
|
|
Note
|
The index of a tailer is only progressed when the DocumentContext.close() is called.
If this is prevented by an error, the same message will be read on each restart.
|
Chronicle v4.4+ supports the use of proxies to send and consume messages.
You start by defining an asynchronous interface, where all methods have:
-
arguments which are only inputs
-
no return value or exceptions expected.
import net.openhft.chronicle.wire.SelfDescribingMarshallable;
interface MessageListener {
void method1(Message1 message);
void method2(Message2 message);
}
static class Message1 extends SelfDescribingMarshallable {
String text;
public Message1(String text) {
this.text = text;
}
}
static class Message2 extends SelfDescribingMarshallable {
long number;
public Message2(long number) {
this.number = number;
}
}To write to the queue you can call a proxy which implements this interface.
SingleChronicleQueue queue1 = ChronicleQueue.singleBuilder(path).build();
MessageListener writer1 = queue1.acquireAppender().methodWriter(MessageListener.class);
// call method on the interface to send messages
writer1.method1(new Message1("hello"));
writer1.method2(new Message2(234));These calls produce messages which can be dumped as follows.
# position: 262568, header: 0
--- !!data #binary
method1: {
text: hello
}
# position: 262597, header: 1
--- !!data #binary
method2: {
number: !int 234
}To read the messages, you can provide a reader which calls your implementation with the same calls that you made.
// a proxy which print each method called on it
MessageListener processor = ObjectUtils.printAll(MessageListener.class)
// a queue reader which turns messages into method calls.
MethodReader reader1 = queue1.createTailer().methodReader(processor);
assertTrue(reader1.readOne());
assertTrue(reader1.readOne());
assertFalse(reader1.readOne());Running this example prints:
method1 [!Message1 {
text: hello
}
]
method2 [!Message2 {
number: 234
}
]-
For more details see, Using Method Reader/Writers and MessageReaderWriterTest
Chronicle has three main concepts:
-
Tailer. Sequential and random reads, forwards and backwards
A Tailer is an excerpt optimized for sequential reads.
-
Appender. Sequential writes, append to the end only
An Appender is something like an iterator in Chronicle environment. You add data appending the current chronicle.
-
Excerpt. Excerpt is the main data container in a Chronicle queue.
Each Chronicle queue is composed of excerpts. Putting data to a Chronicle queue means starting a new excerpt, writing data into it, and finishing the excerpt at the end.
Pretoucher is a class designed to be called from a long-lived thread. The purpose of the Pretoucher
is to accelerate writing in a queue. Upon invocation of the execute() method, this object will pre-touch
pages in the queue’s underlying store file, so that they are resident in the page-cache (i.e. loaded from
storage) before they are required by appenders to the queue. Resources held by this object will be released when the underlying
queue is closed. Alternatively, the shutdown() method can be called to close the supplied queue and
release any other resources. Invocation of the execute() method after shutdown() has been called will
cause an IllegalStateException to be thrown.
The Pretoucher’s configuration parameters (set via the system properties) are as follows:
-
SingleChronicleQueueExcerpts.earlyAcquireNextCycle(defaults to false): Causes the Pretoucher to create the next cycle file while the queue is still writing to the current one in order to mitigate the impact of stalls in the OS when creating new files.
Note: earlyAcquireNextCycle is off by default and if it is going to be turned on, you should very carefully
stress test before and after turning it on. Basically what you experience is related to your system.
-
SingleChronicleQueueExcerpts.pretoucherPrerollTimeMs(defaults to 2,000 milliseconds) The pretoucher will create new cycle files this amount of time in advanced of them being written to. Effectively moves the Pretoucher’s notion of which cycle is "current" into the future bypretoucherPrerollTimeMs. -
SingleChronicleQueueExcerpts.dontWrite(defaults to false): Tells the Pretoucher to never create cycle files that do not already exist. As opposed to the default behaviour where if the Pretoucher runs inside a cycle where no excerpts have been written, it will create the "current" cycle file. Obviously enabling this will preventearlyAcquireNextCyclefrom working.
The Pretoucher’s constructor takes the following parameter:
-
queue: The queue that this Pretoucher is assigned to.
The configuration parameters of the Pretoucher that described above, should be set via system properties. For example, in the following excerpt earlyAcquireNextCycle is set to true and pretoucherPrerollTimeMs to 100ms.
System.setProperty("SingleChronicleQueueExcerpts.earlyAcquireNextCycle", "true");
System.setProperty("SingleChronicleQueueExcerpts.pretoucherPrerollTimeMs", "100");The constructor of Pretoucher takes the name of the queue that this Pretoucher is assigned to and creates a new Pretoucher. Then, by invoking the execute() methode the Pretoucher starts.
// Create the queue q1 (or q1 is a queue that already exists)
try(final SingleChronicleQueue q1 = SingleChronicleQueueBuilder.binary("queue-storage-path").build();
// Create Pretoucher pretouch for q1
final Pretoucher pretouch = new Pretoucher(q1)){
try {
// Start the Pretoucher
pretouch.execute();
} catch (InvalidEventHandlerException e) {
throw Jvm.rethrow(e);
}
}The methode shutdown(), closes the queue and releases any other resources.
// Calls q1.close() and releases the resources
pretouch.shutdown();Chronicle Queue is designed to roll its files depending on the roll cycle chosen when queue is created (see RollCycles).
When the roll cycle reaches the point it should roll, appender will atomically writes EOF mark at the end of current file to indicate that no other appender should write to this file and no tailer should read further, and instead everyone should use new file.
If the process was shutdown, and restarted later when the roll cycle should be using a new file, an appender will try to locate old files and write an EOF mark in them to help tailers reading them.
However, tailers are robust enough to understand that the EOF mark should be present in the file from previous roll cycle even if it’s not written, after a certain timeout.
As mentioned previously Chronicle Queue stores its data off-heap in a ‘.cq4’ file. So whenever you wish to append data to this file or read data into this file, chronicle queue will create a file handle .
Typically, Chronicle Queue will create a new ‘.cq4’ file every day. However, this could be changed so that you can create a new file every hour, every minute or even every second.
If we create a queue file every second, we would refer to this as SECONDLY rolling. Of course, creating a new file every second is a little extreme, but it’s a good way to illustrate my following point. When using secondly rolling, If you had written 10 seconds worth of data and then you wish to read this data, chronicle would have to scan across 10 files. To reduce the creation of the file handles, chronicle queue cashes them lazily and when it comes to writing data to the queue files, care-full consideration must be taken when closing the files, because on most OS’s a close of the file, will force any data that has been appended to the file, to be flushed to disk, and if we are not careful this could stall your application.
By default, double-buffering is disabled. You can enable double-buffering by calling
SingleChronicleQueueBuilder#doubleBuffer(true);Normally (when double-buffering is disabled), all writes to the queue will be serialized based on the write lock acquisition.
Each time ExcerptAppender#writingDocument()
is called, appender tries to acquire the write lock on the queue, and if it fails to do so it blocks until write lock is unlocked, and in turn locks the queue for itself.
When double-buffering is enabled, if appender sees that the write lock is acquired upon call to ExcerptAppender#writingDocument() call, it returns immediately with a context pointing to the secondary buffer, and essentially defers lock acquisition until the context.close() is called (normally with try-with-resources pattern it is at the end of the try block), allowing user to go ahead writing data, and then essentially doing memcpy on the serialized data (thus reducing cost of serialization).
|
Note
|
During a write that is buffered, DocumentContext.index() will throw an IndexNotAvailableException. This is because it is impossible to know the index until the buffer is written back to the queue, which only happens when the DocumentContext is closed.
|
This is only useful if (majority of) the objects being written to the queue are big enough AND their marshalling is not straight-forward (e.g. BytesMarshallable’s marshalling is very efficient and quick and hence double-buffering will only slow things down), and if there’s a heavy contention on writes (e.g. 2 or more threads writing a lot of data to the queue at a very high rate).
Below are the benchmark results for various data sizes at the frequency of 10 KHz for a cumbersome message (see net.openhft.chronicle.queue.bench.QueueContendedWritesJLBHBenchmark), YMMV - always do your own benchmarks:
-
1 KB
-
Double-buffer disabled:
-------------------------------- SUMMARY (Concurrent) ------------------------------------------------------------ Percentile run1 run2 run3 % Variation 50: 90.40 90.59 91.17 0.42 90: 179.52 180.29 97.50 36.14 99: 187.33 186.69 186.82 0.05 99.7: 213.57 198.72 217.28 5.86 worst: 82345.98 73039.87 55820.29 17.06 ------------------------------------------------------------------------------------------------------------------ -------------------------------- SUMMARY (Concurrent2) ----------------------------------------------------------- Percentile run1 run2 run3 % Variation 50: 179.14 179.26 180.93 0.62 90: 183.49 183.36 185.92 0.92 99: 192.19 190.02 215.49 8.20 99.7: 240.70 228.16 258.88 8.24 worst: 82477.06 45891.58 28172.29 29.54 ------------------------------------------------------------------------------------------------------------------
-
Double-buffer enabled:
-------------------------------- SUMMARY (Concurrent) ------------------------------------------------------------ Percentile run1 run2 run3 % Variation 50: 86.05 85.60 86.24 0.50 90: 170.18 169.79 170.30 0.20 99: 176.83 176.58 177.09 0.19 99.7: 183.36 185.92 183.49 0.88 worst: 68911.10 28368.90 28860.42 1.14 ------------------------------------------------------------------------------------------------------------------ -------------------------------- SUMMARY (Concurrent2) ----------------------------------------------------------- Percentile run1 run2 run3 % Variation 50: 86.24 85.98 86.11 0.10 90: 89.89 89.44 89.63 0.14 99: 169.66 169.79 170.05 0.10 99.7: 175.42 176.32 176.45 0.05 worst: 69042.18 28368.90 28876.80 1.18 ------------------------------------------------------------------------------------------------------------------
-
-
4 KB
-
Double-buffer disabled:
-------------------------------- SUMMARY (Concurrent) ------------------------------------------------------------ Percentile run1 run2 run3 % Variation 50: 691.46 699.65 701.18 0.15 90: 717.57 722.69 721.15 0.14 99: 752.90 748.29 748.29 0.00 99.7: 1872.38 1743.36 1780.22 1.39 worst: 39731.20 43171.84 88834.05 41.35 ------------------------------------------------------------------------------------------------------------------ -------------------------------- SUMMARY (Concurrent2) ----------------------------------------------------------- Percentile run1 run2 run3 % Variation 50: 350.59 353.66 353.41 0.05 90: 691.46 701.18 697.60 0.34 99: 732.42 733.95 729.34 0.42 99.7: 1377.79 1279.49 1302.02 1.16 worst: 35504.13 42778.62 87130.11 40.87 ------------------------------------------------------------------------------------------------------------------
-
Double-buffer enabled:
-------------------------------- SUMMARY (Concurrent) ------------------------------------------------------------ Percentile run1 run2 run3 % Variation 50: 342.40 344.96 344.45 0.10 90: 357.25 360.32 359.04 0.24 99: 688.38 691.97 691.46 0.05 99.7: 1376.77 1480.19 1383.94 4.43 worst: 71532.54 2391.04 2491.39 2.72 ------------------------------------------------------------------------------------------------------------------ -------------------------------- SUMMARY (Concurrent2) ----------------------------------------------------------- Percentile run1 run2 run3 % Variation 50: 343.68 345.47 346.24 0.15 90: 360.06 362.11 363.14 0.19 99: 694.02 698.62 699.14 0.05 99.7: 1400.32 1510.91 1435.14 3.40 worst: 71925.76 80314.37 62537.73 15.93 ------------------------------------------------------------------------------------------------------------------
-
In Chronicle Queue 5 tailers are now read-only, in Chronicle Queue 4 we have the concept of lazy indexing, where the appenders would not write indexes but instead the indexing was done by the tailer, or to be more precise, when lazy indexing was turned on the indexing was done by the first tailer that read the data. Since in chronicle queue 4 tailers could do the indexing we could not rely on them to be read-only. We decided to drop lazy indexing in chronicle queue 5. Making tailers read-only not only simplifies Chronicle Queue but also allows us to add optimisations elsewhere in the code.
The locking model of Chronicle Queue was changed, in Chronicle Queue 4 a write lock (to prevent concurrent writes to the queue) exists in the .cq4 file. In Chronicle Queue 5 this was moved to a single file called a table store (metadata.cq4t). This simplifies the locking code internally as only the table store file has to be inspected.
You can use Chronicle 5 to read messages written with Chronicle 4, however you should not concurrently run chronicle queue 4 and chronicle queue 5 at the same time. In other words avoid running Chronicle Queue 4’s appenders and tailers on a queue which at the same time is also read and written to via Chronicle Queue 5.
Chronicle Queue v4 solves a number of issues that existed in Chronicle Queue v3.
-
Without self-describing messages, users had to create their own functionality for dumping messages and long term storage of data.
With Q4 you don’t have to do this, but you can if you wish to.
-
Vanilla Chronicle Queue would create a file per thread.This is fine if the number of threads is controlled, however, many applications have little or no control over how many threads are used and this caused usability problems.
-
The configuration for Indexed and Vanilla Chronicle was entirely in code so the reader had to have the same configuration as the writers and it wasn’t always clear what that was.
-
There was no way for the producer to know how much data had been replicated to the a second machine.The only work around was to replicate data back to the producers.
-
You needed to specify the size of data to reserve before you started to write your message.
-
You needed to do your own locking for the appender when using Indexed Chronicle.
Yes. They use different packages. Chronicle Queue v4 is a complete re-write so there is no problem using it at the same time as Chronicle Queue v3. The format of how the data is stored is slightly different, so they are are not interoperable on the same queue data file.
In Chronicle Queue v3, everything was in terms of bytes, not wire.
There are two ways to use byte in Chronicle Queue v4. You can use the writeBytes and readBytes methods, or you can get the bytes() from the wire.
For example:
appender.writeBytes(b -> b.writeInt(1234).writeDouble(1.111));
boolean present = tailer.readBytes(b -> process(b.readInt(), b.readDouble()));try (DocumentContext dc = appender.writingDocument()) {
Bytes bytes = dc.wire().bytes();
// write to bytes
}
try (DocumentContext dc = tailer.readingDocument()) {
if (dc.isPresent()) {
Bytes bytes = dc.wire().bytes();
// read from bytes
}
}This queue is a designed to support:
-
rolling files on a daily, weekly or hourly basis,
-
concurrent writers on the same machine,
-
concurrent readers on the same machine or across multiple machines via TCP replication (With Chronicle Queue Enterprise),
-
zero copy serialization and deserialization,
-
millions of writes/reads per second on commodity hardware.
Approximately 5 million messages/second for 96-byte messages on a i7-4790 processor.
The directory structure is as follows:
base-directory /
{cycle-name}.cq4 - The default format is yyyyMMdd for daily rolling.The format consists of size-prefixed bytes which are formatted using BinaryWire or TextWire.
The ChronicleQueue.dump() method can be used to dump the raw contents as a string.
Creating an instance of Chronicle Queue is a little more complex than just calling a constructor.
To create an instance you have to use the ChronicleQueueBuilder.
String basePath = OS.getTarget() + "/getting-started"
ChronicleQueue queue = SingleChronicleQueueBuilder.single(basePath).build();In this example we have created an IndexedChronicle which creates two RandomAccessFiles; one for indexes, and one for data having names relatively:
${java.io.tmpdir}/getting-started/{today}.cq4// Obtain an ExcerptAppender
ExcerptAppender appender = queue.acquireAppender();
// write - {msg: TestMessage}
appender.writeDocument(w -> w.write("msg").text("TestMessage"));
// write - TestMessage
appender.writeText("TestMessage");ExcerptTailer tailer = queue.createTailer();
tailer.readDocument(w -> System.out.println("msg: " + w.read(()->"msg").text()));
assertEquals("TestMessage", tailer.readText());Chronicle Queue stores its data off-heap, and it is recommended that you call close() once you have finished working with Chronicle Queue, to free resources,
|
Note
|
No data will be lost if you do not do this. This is only to clean up resources that were used. |
queue.close();try (ChronicleQueue queue = SingleChronicleQueueBuilder.single("queue-dir").build()) {
// Obtain an ExcerptAppender
ExcerptAppender appender = queue.acquireAppender();
// write - {msg: TestMessage}
appender.writeDocument(w -> w.write("msg").text("TestMessage"));
// write - TestMessage
appender.writeText("TestMessage");
ExcerptTailer tailer = queue.createTailer();
tailer.readDocument(w -> System.out.println("msg: " + w.read(()->"msg").text()));
assertEquals("TestMessage", tailer.readText());
}Caused by: java.lang.OutOfMemoryError: Map failed
at sun.nio.ch.FileChannelImpl.map0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at net.openhft.chronicle.core.OS.map0(OS.java:292)
at net.openhft.chronicle.core.OS.map(OS.java:280)
... 54 moreThe problem is that it is running out of virtual memory, you are more likely to see this if you are running a 32-Bit JVM on 64-bit. One work around is to use a 64-bit JVM.
The time Chronicle Queue rolls, is based on the UTC time, it uses System.currentTimeMillis().
When using daily-rolling, Chronicle Queue will roll at midnight UTC. If you wish to change the time it rolls, you have to change Chronicle Queue’s epoch() time.
This time is a milliseconds offset, in other words, if you set the epoch to be epoch(1) then chronicle will roll at 1 millisecond past midnight.
Path path = Files.createTempDirectory("rollCycleTest");
SingleChronicleQueue queue = ChronicleQueue.singleBuilder(path).epoch(0).build();We do not recommend that you change the epoch() on an existing system, which already has .cq4 files created, using a different epoch() setting.
If you were to set :
.epoch(System.currentTimeMillis()This would make the current time the roll time, and the cycle numbers would start from zero.
WireStore wireStore = queue.storeForCycle(queue.cycle(), 0, false);
System.out.println(wireStore.file().getAbsolutePath());You can access the bytes in wire as follows:
try (DocumentContext dc = appender.writingDocument()) {
Wire wire = dc.wire();
Bytes bytes = wire.bytes();
// write to bytes
}try (DocumentContext dc = tailer.readingDocument()) {
Wire wire = dc.wire();
Bytes bytes = wire.bytes();
// read from the bytes
}You can use isPresent() to check that there is data to read.
try (DocumentContext dc = tailer.readingDocument()) {
if(!dc.isPresent()) // this will tell you if there is any data to read
return;
Bytes bytes = dc.wire().bytes();
// read from the bytes
}You can access native memory:
try (DocumentContext dc = appender.writingDocument()) {
Wire wire = dc.wire();
Bytes bytes = wire.bytes();
long address = bytes.address(bytes.readPosition());
// write to native memory
bytes.writeSkip(lengthActuallyWritten);
}try (DocumentContext dc = appender.writingDocument()) {
Wire wire = dc.wire();
Bytes bytes = wire.bytes();
long address = bytes.address(bytes.readPosition());
long length = bytes.readRemaining();
// read from native memory
}If you are writing bytes to a Chronicle-Queue you will find that it occasionally adds padding to the end of each message. This is to ensure that each message starts on a 4-byte boundary which is a requirement for ARM architectures. NOTE: Intel requires that messages don’t straggle 64-byte cash lines. but aligning to 4 bytes also ensures 64-byte alignment and allows your Chronicle Queues to be shared between various different platforms.
For Chronicle Queue, the 4-byte alignment is now enforced, so there is now, no way to turn this feature on or off. This behaviour was changed on 21 April 2020 as part of OpenHFT#656
The writingDocument() should be performed as quickly as possible because a write lock is held until the DocumentContext is closed by the try-with-resources.
This blocks other appenders and tailers.
More dangerously, if something keeps the thread busy long enough(more than recovery timeout, which is 20 seconds by default) between call to appender.writingDocument() and code that actually writes something into bytes, it can cause recovery to kick in from other appenders (potentially in other process), which will rewrite message header, and if your thread subsequently continues writing its own message it the will corrupt queue file.
try (DocumentContext dc = appender.writingDocument()) {
// this should be performed as quickly as possible because a write lock is held until the
// DocumentContext is closed by the try-with-resources, this blocks other appenders and tailers.
}If an exception is thrown while you are holding the writingDocument(), then the close() method will be called on the
DocumentContext which will release the lock, set the length in the header, and allow writing to continue.
If the exception was thrown halfway through writing your data, then you will end up with your data half-written in the chronicle queue.
If there is a possibility of an exception during writing, you should use something like the below.
This calls the DocumentContext.rollbackOnClose() method to tell the DocumentContext to rollback the data.
@NotNull DocumentContext dc = writingDocument();
try {
// perform the write which may throw
} catch (Throwable t) {
dc.rollbackOnClose();
throw Jvm.rethrow(t);
} finally {
dc.close();
}You should try to avoid abruptly killing Chronicle Queue, especially if its in the middle of writing a message.
try (DocumentContext dc = appender.writingDocument()) {
// killing chronicle queue here will leave the file in a locked state
}If you kill Chronicle Queue when its half way through writing a document, this can leave your Chronicle Queue in a locked state, which could later prevent other appenders from writing to the queue file.
Although we do not recommend that you $kill -9 your process, in the event that your process abruptly terminates we have added recovery code that should recover from this situation.
Chronicle Queue is designed to be a "record everything store" which can read with microsecond real-time latency. This supports even the most demanding High Frequency Trading systems. However, it can be used in any application where the recording of information is a concern.
Chronicle Queue is designed to support reliable replication with notification to either the appender or a tailer, when a message has been successfully replicated.
Chronicle Queue assumes disk space is cheap compared with memory. Chronicle Queue makes full use of the disk space you have, and so you are not limited by the main memory of your machine. If you use spinning HDD, you can store many TBs of disk space for little cost.
The only extra software that Chronicle Queue needs to run is the operating system. It doesn’t have a broker; instead it uses your operating system to do all the work. If your application dies, the operating system keeps running for seconds longer, so no data is lost; even without replication.
As Chronicle Queue stores all saved data in memory-mapped files, this has a trivial on-heap overhead, even if you have over 100 TB of data.
Chronicle put significant effort into achieving very low latency.
In other products which focus on support of web applications, latencies of less than 40 milliseconds are fine as they are faster than you can see; for example, the frame rate of cinema is 24 Hz, or about 40 ms.
Chronicle Queue aims to achieve latencies of under 40 microseconds for 99% to 99.99% of the time. Using Chronicle Queue without replication, we support applications with latencies below 40 microseconds end-to-end across multiple services. Often the 99% latency of Chronicle Queue is entirely dependant on the choice of operating system and hard disk sub-system.
Replication for Chronicle Queue supports Chronicle Wire Enterprise. This supports a real-time compression which calculates the deltas for individual objects, as they are written. This can reduce the size of messages by a factor of 10, or better, without the need for batching; that is, without introducing significant latency.
Chronicle Queue also supports LZW, Snappy, and GZIP compression. These formats however add significant latency. These are only useful if you have strict limitations on network bandwidth.
Chronicle Queue supports a number of semantics.
-
Every message is replayed on restart.
-
Only new messages are played on restart.
-
Restart from any known point using the index of the entry.
-
Replay only the messages you have missed. This is supported directly using the methodReader/methodWriter builders.
Chronicle Queue supports explicit, or implicit, nanosecond resolution timing for messages as they pass end-to-end over across your system. We support using nano-time across machines, without the need for specialist hardware.
SidedMarketDataListener combiner = out.acquireAppender()
.methodWriterBuilder(SidedMarketDataListener.class)
.recordHistory(true)
.get();
combiner.onSidedPrice(new SidedPrice("EURUSD1", 123456789000L, Side.Sell, 1.1172, 2e6));A timestamp is added for each read and write as it passes from service to service.
--- !!data #binary
history: {
sources: [
1,
0x426700000000 # (4)
]
timings: [
1394278797664704, # (1)
1394278822632044, # (2)
1394278824073475 # (3)
]
}
onTopOfBookPrice: {
symbol: EURUSD1,
timestamp: 123456789000,
buyPrice: NaN,
buyQuantity: 0,
sellPrice: 1.1172,
sellQuantity: 2000000.0
}-
First write
-
First read
-
Write of the result of the read.
-
What triggered this event.
On most systems System.nanoTime() is roughly the number of nanoseconds since the system last rebooted (although different JVMs may behave differently).
This is the same across JVMs on the same machine, but wildly different between machines.
The absolute difference when it comes to machines is meaningless.
However, the information can be used to detect outliers; you can’t determine what the best latency is, but you can determine how far off the best latencies you are.
This is useful if you are focusing on the 99th percentile latencies.
We have a class called RunningMinimum to obtain timings from different machines, while compensating for a drift in the nanoTime between machines.
The more often you take measurements, the more accurate this running minimum is.
Chronicle Queue manages storage by cycle.
You can add a StoreFileListener which will notify you when a file is added, and when it is no longer retained.
You can move, compress, or delete all the messages for a day, at once.
NOTE : Unfortunately on Windows, if an IO operation is interrupted, it can close the underlying FileChannel.
Due to performance reasons, we have removed checking for interrupts in the chronicle queue code. Because of this, we recommend that you avoid using chronicle queue with code that generates interrupts. If you can not avoid generating interrupts then we suggest that you create a separate instance of chronicle-queue per thread.
Chronicle Queue is designed to out-perform its rivals such as Kafka.
Chronicle Queue supports over an order-of-magnitude of greater throughput, together with an order-of-magnitude of lower latency, than Apache Kafka. While Kafka is faster than many of the alternatives, it doesn’t match Chronicle Queue’s ability to support throughputs of over a million events per second, while simultaneously achieving latencies of 1 to 20 microseconds.
Chronicle Queue handles more volume from a single thread to a single partition. This avoids the need for the complexity, and the downsides, of having partitions.
|
Note
|
Chronicle Datagrid does support partitioning of queues across machines, though not the partitioning of a single queue. |
Kafka uses an intermediate broker to use the operating system’s file system and cache, while Chronicle Queue directly uses the operating system’s file system and cache.
Chronicle Queue Enterprise supports TCP and UDP replication.
Replication between hosts ensures real-time backup of all your queue data. For more information see Replication, the protocol is covered here.

The following charts show how long it takes to:
-
write a 40 byte message to a Chronicle Queue
-
have the write replicated over TCP
-
have the second copy acknowledge receipt of the message
-
have a thread read the acknowledged message
The test was run for ten minutes, and the distribution of latencies plotted.
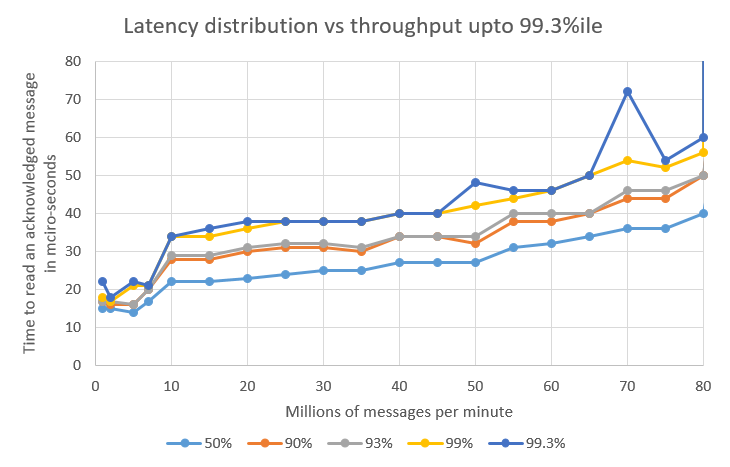
|
Note
|
There is a step in latency at around 10 million message per second; it jumps as the messages start to batch. At rates below this, each message can be sent individually. |
The 99.99 percentile and above are believed to be delays in passing the message over TCP. Further research is needed to prove this. These delays are similar, regardless of the throughput.
The 99.9 percentile and 99.93 percentile are a function of how quickly the system can recover after a delay. The higher the throughput, the less headroom the system has to recover from a delay.
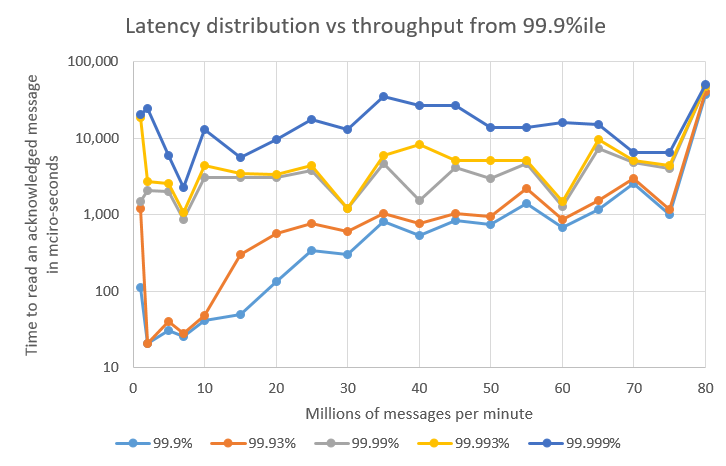
If you wish to tune your code for ultra-low latency, you could take a similar approach to our QueueReadJitterMain
net.openhft.chronicle.queue.jitter.QueueReadJitterMainThis code can be considered as a basic stack sampler profiler.
This is assuming you base your code on the net.openhft.chronicle.core.threads.EventLoop, you can periodically sample the stacks to find a stall.
It is recommended to not reduce the sample rate below 50 microseconds as this will produce too much noise
It is likely to give you finer granularity than a typical profiler. As it is based on a statistical approach of where the stalls are, it takes many samples, to see which code has the highest grouping ( in other words the highest stalls ) and will output a trace that looks like the following :
28 at java.util.concurrent.ConcurrentHashMap.putVal(ConcurrentHashMap.java:1012) at java.util.concurrent.ConcurrentHashMap.put(ConcurrentHashMap.java:1006) at net.openhft.chronicle.core.util.WeakReferenceCleaner.newCleaner(WeakReferenceCleaner.java:43) at net.openhft.chronicle.bytes.NativeBytesStore.<init>(NativeBytesStore.java:90) at net.openhft.chronicle.bytes.MappedBytesStore.<init>(MappedBytesStore.java:31) at net.openhft.chronicle.bytes.MappedFile$$Lambda$4/1732398722.create(Unknown Source) at net.openhft.chronicle.bytes.MappedFile.acquireByteStore(MappedFile.java:297) at net.openhft.chronicle.bytes.MappedFile.acquireByteStore(MappedFile.java:246) 25 at net.openhft.chronicle.queue.jitter.QueueWriteJitterMain.lambda$main$1(QueueWriteJitterMain.java:58) at net.openhft.chronicle.queue.jitter.QueueWriteJitterMain$$Lambda$11/967627249.run(Unknown Source) at java.lang.Thread.run(Thread.java:748) 21 at java.util.concurrent.ConcurrentHashMap.putVal(ConcurrentHashMap.java:1027) at java.util.concurrent.ConcurrentHashMap.put(ConcurrentHashMap.java:1006) at net.openhft.chronicle.core.util.WeakReferenceCleaner.newCleaner(WeakReferenceCleaner.java:43) at net.openhft.chronicle.bytes.NativeBytesStore.<init>(NativeBytesStore.java:90) at net.openhft.chronicle.bytes.MappedBytesStore.<init>(MappedBytesStore.java:31) at net.openhft.chronicle.bytes.MappedFile$$Lambda$4/1732398722.create(Unknown Source) at net.openhft.chronicle.bytes.MappedFile.acquireByteStore(MappedFile.java:297) at net.openhft.chronicle.bytes.MappedFile.acquireByteStore(MappedFile.java:246) 14 at net.openhft.chronicle.queue.jitter.QueueWriteJitterMain.lambda$main$1(QueueWriteJitterMain.java:54) at net.openhft.chronicle.queue.jitter.QueueWriteJitterMain$$Lambda$11/967627249.run(Unknown Source) at java.lang.Thread.run(Thread.java:748)
from this, we can see that most of the samples (on this occasion 28 of them ) were captured in ConcurrentHashMap.putVal() if we wish to get finer grain granularity,
we will often add a net.openhft.chronicle.core.Jvm.safepoint into the code because thread dumps are only reported at safe-points.
In the test described above, the typical latency varied between 14 and 40 microseconds. The 99 percentile varied between 17 and 56 microseconds depending on the throughput being tested. Notably, the 99.93% latency varied between 21 microseconds and 41 milliseconds, a factor of 2000.
Acceptable Latency |
Throughput |
< 30 microseconds 99.3% of the time |
7 million message per second |
< 20 microseconds 99.9% of the time |
20 million messages per second |
< 1 milliseconds 99.9% of the time |
50 million messages per second |
< 60 microseconds 99.3% of the time |
80 million message per second |
The byte[] methods on StringUtils are designed to work only on those Java 9+ VMs that have the compact strings feature enabled, but not on ones that have non-compact strings. This is not specific to OpenJ9, and HotSpot should fail with Java9 (but it doesn’t because compact strings are enabled by default).
Conversely, OpenJ9 should be able to run Chronicle Queue with compact strings. We can confirm ( with limited testing ) that Chronicle Queue is able to work on OpenJ9 VM with the -XX:+CompactStrings option enabled.
In summary, Chronicle Queue can be considered compatible with OpenJ9, provided the -XX:+CompactStrings option is used.
OpenJ9 version 0.12.1 and earlier requires the file descriptor limit to be manually adjusted to a higher value - for example, using the command ulimit -Sn 500.
$ for i in 0 1 2 3 4 5 6 7 8 9; do dd bs=65536 count=163840 if=/dev/zero of=deleteme$i ; done
163840+0 records in
163840+0 records out
10737418240 bytes (11 GB) copied, 5.60293 s, 1.9 GB/s
163840+0 records in
163840+0 records out
10737418240 bytes (11 GB) copied, 6.08841 s, 1.8 GB/s
163840+0 records in
163840+0 records out
10737418240 bytes (11 GB) copied, 5.64981 s, 1.9 GB/s
163840+0 records in
163840+0 records out
10737418240 bytes (11 GB) copied, 5.77591 s, 1.9 GB/s
163840+0 records in
163840+0 records out
10737418240 bytes (11 GB) copied, 5.59537 s, 1.9 GB/s
163840+0 records in
163840+0 records out
10737418240 bytes (11 GB) copied, 5.74398 s, 1.9 GB/s
163840+0 records in
163840+0 records out
10737418240 bytes (11 GB) copied, 8.24996 s, 1.3 GB/s
163840+0 records in
163840+0 records out
10737418240 bytes (11 GB) copied, 11.1431 s, 964 MB/s
163840+0 records in
163840+0 records out
10737418240 bytes (11 GB) copied, 12.2505 s, 876 MB/s
163840+0 records in
163840+0 records out
10737418240 bytes (11 GB) copied, 12.7551 s, 842 MB/sThe number of messages that you can store depends on the roll-cycle; the roll-cycle determines how often you create a new Chronicle Queue data file. Most people use a new file each day and we call this daily-rolling. The Chronicle index is a unique index that is given to each message. You can use the index to retrieve any message that you have stored.
When using daily-rolling, each message stored to the Chronicle queue will increase the index by 1. The high bytes in the 64-bit index are used to store the cycle number, and the low bits to store the sequence number.
The index is broken down into two numbers:
-
cycle number - When using daily-rolling, the first file from epoch has cycle number of 1, and the next day it will have a cycle number of 2, and so on
-
message sequence number - Within a cycle, when using daily-rolling, the first message of each day will have a message sequence number of 1, and the next message within that day have a message sequence number of 2, and so on
Different roll-cycles have a difference balance between how many bits are allocated to the message sequence number, and how many of the remaining bits are allocated to the cycle number. In other words, different roll-cycles allow us to trade off the maximum number of cycles, for the maximum number of messages within the cycle.
With daily-rolling we use:
-
a 32-bit message sequence number - which gives us 4 billion messages per day, and
-
a 31-bit cycle number (reserving the high bit for the sign ) - allows us to store messages up to the year 5,881,421. With hourly rolling we can store messages up to the year 246,947.
If you have more than 4 billion messages per cycle you can increase the number of bits used for cycles and thus the number of messages per cycle, though reducing the number of cycles.
For example, you may have up to 1 trillion messages per day and you need 23-bit cycles to allow for up to the year 24,936. If we had rolled every second with 32-bit 4 bn messages per second, we would be running out in about a decade. With hourly and daily-rolling it’s pretty limitless.
Also, by changing the epoch, you can extend the dates further, shifting the limit between the first and last cycle to 31-bits or 23-bits.
Not implicitly. We didn’t want to assume whether the appenders or tailers:
-
were running at the same time
-
were in the same process
-
wanted to block on the queue for either writing or reading.
If both the appender and tailer are in the same process, the tailer can use a pauser when not busy.
pauser = balanced ? Pauser.balanced() : Pauser.millis(1, 10);
while (!closed) {
if (reader.readOne())
pauser.reset();
else
pauser.pause();
}In another thread you can wake the reader with:
pauser.unpause();To unlock a locked chronicle queue (perhaps an appending process has been abruptly killed), the
net.openhft.chronicle.queue.QueueUnlockMain utility will accomplish this. There is also a script unlock_queue.sh to call this.
One of the challenges with NFS is the variation in behaviour/functionality from version to version, across Operating Systems, and also differences between how individual deployments have been configured. The main concerns with NFS relevant to a Chronicle Queue are:
-
support and behaviour of file locks (including fine-grained locking of distinct byte ranges within a file)
-
support and behaviour of memory mapping, and visibility of changes across separate mappings
Crucially, if you are only using the file on one host, then the OS layer for memory mapping comes before the file system, so the fact that the backing file resides on an NFS mount is less of a concern. There are however some nuances with NFS around the behaviour of syncs to disk (both in normal operation and importantly if an application crashes) which in turn requires slightly more defensive programming and consequently some degradation in performance is likely.
File locking will generally work provided you are using an up to date version of NFS (4+) and it has been suitably configured. There are additional elements to file locking through NFS which need to be handled (e.g. dealing with network interruptions with an NFS server which can cause locks to go stale/lost), but the basic mechanism works as needed.
So in summary using an NFS mount locally is fine, however care is needed to ensure the environment is correctly configured. The "local" caveat is very important.
|
Note
|
We would certainly recommend running a series of tests to confirm lock and memory map behaviour. Chronicle Software can work with you to set this up. |
In brief, our recommendation is that using local disk rather than NFS is always preferable in cases where appenders and tailers are on the same host. One option to consider may be using local disk for the shared appender/tailer data, then replicate this onto an NFS mount if passive copies are needed elsewhere. If you only have NFS available then using NFS locally can be fine subject to some caveats as above. Tests would be required to confirm correct behaviour in your specific environment.
|
Note
|
The above explanation assumes C++ Queue on Linux. Java Queue has similar functional requirements which should ultimately use similar native calls to C++ via the JVM, but this would need to be confirmed in your environment. |
Chronicle Queue (CQ) can be configured via a number of methods on the SingleChronicleQueueBuilder class.
One such piece of configuration is the RollCycle that determines the rate at which CQ will roll the underlying queue files.
For instance, using the following code snippet will result in the queue files being rolled (i.e. a new file created) every hour:
ChronicleQueue.singleBuilder(queuePath).rollCycle(RollCycles.HOURLY).build()Once a queue’s roll-cycle has been set, it cannot be changed at a later date.
More formally, after the first append has been made to a Chronicle Queue, any further instances of SingleChronicleQueue
configured to use the same path must be configured to use the same roll-cycle.
This check is enforced by SingleChronicleQueueBuilder, so the following code causes an exception to be thrown:
final Path queueDir = Paths.get("/data/queue/my-queue");
try (ChronicleQueue queue = ChronicleQueue.singleBuilder(queueDir).rollCycle(SECONDLY).build()) {
// this append call will 'lock' the queue to use the SECONDLY roll-cycle
try (DocumentContext documentContext = queue.acquireAppender().writingDocument()) {
documentContext.wire().write("somekey").text("somevalue");
}
}
// this call will fail since we are trying to create a new queue,
// at the same location, with a different roll-cycle
try (ChronicleQueue recreated = ChronicleQueue.singleBuilder(queueDir).rollCycle(HOURLY).build()) {
}In the case where a Chronicle Queue instance is created before any appends have been made, and there is a subsequent append operation with a different roll-cycle, then the roll-cycle will be updated to match the persisted roll-cycle. In this case, a warning log message will be printed in order to notify the library user of the situation:
// creates a queue with roll-cycle MINUTELY
try (ChronicleQueue minuteRollCycleQueue = ChronicleQueue.singleBuilder(queueDir).rollCycle(MINUTELY).build()) {
// creates a queue with roll-cycle HOURLY - valid since no appends have yet been made
try (ChronicleQueue hourlyRollCycleQueue = ChronicleQueue.singleBuilder(queueDir).rollCycle(HOURLY).build()) {
// append using the HOURLY roll-cycle
try (DocumentContext documentContext = hourlyRollCycleQueue.acquireAppender().writingDocument()) {
documentContext.wire().write("somekey").text("somevalue");
}
}
// now try to append using the queue configured with roll-cycle MINUTELY
try (DocumentContext documentContext2 = minuteRollCycleQueue.acquireAppender().writingDocument()) {
documentContext2.wire().write("otherkey").text("othervalue");
}
}console output:
[main] WARN SingleChronicleQueueBuilder - Overriding roll cycle from HOURLY to MINUTELY.It’s possible to configure how Chronicle Queue will store the data:
ChronicleQueue.singleBuilder(queuePath)
SingleChronicleQueueBuilder.fieldlessBinary(queuePath)
SingleChronicleQueueBuilder.defaultZeroBinary(queuePath)
SingleChronicleQueueBuilder.deltaBinary(queuePath)Although it’s possible to explicitly provide WireType when creating a builder, it is discouraged as not all wire types are supported by Chronicle Queue as of yet:
SingleChronicleQueueBuilder.builder(queuePath, wireType)In particular, the following wire types are not supported:
-
TEXT (and essentially all based on text, including JSON and CSV)
-
RAW
-
READ_ANY
-
Block Size
When the queue is read/written, it maps part of the file currently being read/written to a memory segment (block). This parameter controls the size of a memory mapping chunk.
-
Index Spacing
The space between excerpts that are explicitly indexed. A higher number means higher sequential write performance but slower random access read. The sequential read performance is not affected by this property. For example, the following default index spacing can be returned:
-
16 (MINUTELY)
-
64 (DAILY)
-
-
Index Count
the size of each index array, as well as the total number of index arrays per queue file.
NoteindexCount2 is the maximum number of indexed queue entries. -
Buffer Mode
-
None- The default (and the only one available for open source users), no buffering; -Copy- used in conjunction with encryption; -Asynchronous- use ring-buffer when reading and/or writing, provided by Chronicle Ring Enterprise product Buffer CapacityRing buffer capacity when using
bufferMode: Asynchronous
If you are running Chronicle Queue or Chronicle Queue Enterprise under Docker, the best practice is to use the following command:
--ipc=hostThis feature lets processes running on a host computer communicate with each other immediately, therefore the latency associated with network or pipe-based IPC does not degrade the Chronicle Queue (Enterprise) performance.
| RollCycle Name | Max Number of messages in each cycle in Decimal | Max Number of messages in each cycle in Hexadecimal | maximum messages per seconds over the length of the cycle ( on average ) |
|---|---|---|---|
FIVE_MINUTELY |
1,073,741,824 |
0x40000000 |
3,579,139 |
TEN_MINUTELY |
1,073,741,824 |
0x40000000 |
1,789,569 |
TWENTY_MINUTELY |
1,073,741,824 |
0x40000000 |
1,491,308 |
HALF_HOURLY |
1,073,741,824 |
0x40000000 |
596,523 |
FAST_HOURLY |
4,294,967,295 |
0xffffffff |
1,193,046 |
TWO_HOURLY |
4,294,967,295 |
0xffffffff |
596,523 |
FOUR_HOURLY |
4,294,967,295 |
0xffffffff |
298,261 |
SIX_HOURLY |
4,294,967,295 |
0xffffffff |
198,841 |
FAST_DAILY |
4,294,967,295 |
0xffffffff |
49,710 |
MINUTELY |
67,108,864 |
0x4000000 |
1,118,481 |
HOURLY |
268,435,456 |
0x10000000 |
74,565 |
DAILY |
4,294,967,295 |
0xffffffff |
49,710 |
LARGE_HOURLY |
4,294,967,295 |
0xffffffff |
49,710 |
LARGE_DAILY |
137,438,953,471 |
0x1fffffffff |
1,590,728 |
XLARGE_DAILY |
4,398,046,511,103 |
0x3ffffffffff |
50,903,316 |
HUGE_DAILY |
281,474,976,710,655 |
0xffffffffffff |
3,257,812,230 |
SMALL_DAILY |
536,870,912 |
0x20000000 |
6,213 |
LARGE_HOURLY_SPARSE |
17,179,869,183 |
0x3ffffffff |
4,772,185 |
LARGE_HOURLY_XSPARSE |
4,398,046,511,103 |
0x3ffffffffff |
1,221,679,586 |
HUGE_DAILY_XSPARSE |
281,474,976,710,655 |
0xffffffffffff |
78,187,493,530 |
TEST_SECONDLY |
4,294,967,295 |
0xffffffff |
4,294,967,295 |
TEST4_SECONDLY |
4,096 |
0x1000 |
4,096 |
TEST_HOURLY |
1,024 |
0x400 |
0 |
TEST_DAILY |
64 |
0x40 |
0 |
TEST2_DAILY |
512 |
0x200 |
0 |
TEST4_DAILY |
4,096 |
0x1000 |
0 |
TEST8_DAILY |
131,072 |
0x20000 |
1 |
More in-depth information can be found in the following topics:
-
Big Data and Chronicle Queue - a detailed description of some of the techniques utilised by Chronicle Queue
-
Encryption - describes how to encrypt the contents of a Queue
-
FAQ - questions asked by customers
-
How it works - more depth on how Chronicle Queue is implemented
-
Replication - an overview of the replication mechanism
-
Timezone rollover - describes how to configure file-rolling at a specific time in a given time-zone
-
Utilities - lists some useful utilities for working with queue files