ELK是Elasticsearch、Logstash與Kibana的簡稱,三者皆為open-source工具。
- Elaticsearch - 使用Java所開發,是一個基於Apache Lucene的分散式全文檢索引擎,支援RESTful接口,並可對資料進行即時分析。
- Logstash - 對日誌進行管理、收集、過濾與儲存,Logstash目前是es家族成員之一。
- Kibana - 負責日誌的視覺化。
此repository為記錄k8s上,所有pod的日誌。
下載k8s-elk repository
git clone https://github.com/sayya9/k8s-elk.git
cd k8s-elk/helm/elk
該repository提供兩種架構:
- filebeat -> es -> kibana
helm install -n elk .
- filebeat -> logstash -> es -> kibana
helm install -n elk --set=logstash.enabled=true .
ELK所使用的資料庫,把收集到的日誌存在這裡,便於快速的查詢。
會從所有候選的主節點選出一個真的做事主節點,主要負責集群裡輕量級的操作,例如:建立或是刪除索引、透過廣播機制與其它節點聯繫、並決定哪些分片(shards)分給相關節點。
官方的master-eligible node的建議配置:
node.master: true
node.data: false
node.ingest: false
discovery.zen.minimum_master_nodes這個參數的數字,代表有目前有多少候選主節點可通訊的情況下,才會從中推選一個真正的主節點出來,否則不滿足這個數字的話,es為了避免腦裂,整個集群為不可用。
這個參數預設是1,且如果目前候選主節點也是1那麼這個集群為可用狀態。
如果這個參數一樣為1,候選的主節點目前為2,這個情況乍看如果任何一個候選主節點掛掉時,另外一個會自動提升為票選為主節點,這個假象看起來沒錯!但假設有2個候選主節點(Node1, Node2),Node1在啟動時被票選為主節點,但如果只是網路問題讓兩個候選主節點之間暫時失聯了,通訊斷了,兩個節點都認為彼此已經掛了,Node1不需要做什麼,它本來就被票選為主節點,關鍵在Node2會自動提升票選自己為主節點,此時Node2形成另外一個獨立的集群,如果Node2保存的是副分片的話,也會一併提升為主分片,因為它認為Node1已經掛了。現在集群在一個不一致的狀態,發在Node1與Node2的索引請求各自寫自己的!
因此建議配置3個以上的候選主節點,不但避免了腦裂的可能性,也同時保持高可用性的優點!
官方建議discovery.zen.minimum_master_nodes這個值的公式為:
(master_eligible_nodes / 2) + 1
例如:有3個候選主節點,(3/2)+1=2,那麼如果網路發生故障時,其中一個節點不能與其他節點通訊時,就不會形成另外一個獨立的集群!
存放資料的節點,負責CRUD操作,以及查詢、聚合操作,對CPU、Memory、IO要求較高。
官方的data node的建議配置:
node.master: false
node.data: true
node.ingest: false
es 5.x所新增的功能,原始數據在實際寫進資料庫之前,對數據執行管道預處理。例如:在document中增加field或是重命名field等操作,一個pipeline支援增加多個processor,按照順序輪流處理!
官方的ingest node的建議配置:
node.master: false
node.data: false
node.ingest: true
search.remote.connect: false
其實就是原來的client node,在所有節點預設就是coordinating node,主要用來發送請求與合併結果。因此,需要有足夠的CPU、Memory來處理合併資料的集合!
官方的coordinating node的建議配置:
node.master: false
node.data: false
node.ingest: false
search.remote.connect: false
es為了防止任一個節點無意間加入集群,提供了一個列表discovery.zen.ping.unicast.hosts,在此列表中的節點且具有集群相同名字才會加入集群。預設搜尋9300的port,且只有本機才能加入!
這個elk repository的es部分,使用了k8s的service cluster-ip,且es master deployment replicas為3,也就是我有3個候選主節點,因此當我k8s DNS解析這個es-discovery名稱時,會返回一個cluster-ip,這個cluster-ip有3個endpoint,每個endpoint對應的是master pod的ip,至於到哪個master pod由iptables決定!
因此,我只需要寫這樣就可以找到所有候選主節點,不需要每台都寫出來:
discovery.zen.ping.unicast.hosts: ["es-discovery"]
- master node: 3
- data node: 2
- coordinating node: 2
因為是裝在k8s裡面的,所以請打開NodePort或者是在Pod裡面操作!
透過es提供的API確認基本訊息:
GET http://localhost:9200
返回:
{
"name": "elk-es-coordinator-elk-79d687745d-mzhr6",
"cluster_name": "elk",
"cluster_uuid": "FPLbo5APSHCEQ5V3KhPmKA",
"version": {
"number": "6.2.4",
"build_hash": "ccec39f",
"build_date": "2018-04-12T20:37:28.497551Z",
"build_snapshot": false,
"lucene_version": "7.2.1",
"minimum_wire_compatibility_version": "5.6.0",
"minimum_index_compatibility_version": "5.0.0"
},
"tagline": "You Know, for Search"
}
集群健康值:
GET http://localhost:9200/_cluster/health?pretty
返回:
{
"cluster_name": "elk",
"status": "green",
"timed_out": false,
"number_of_nodes": 7,
"number_of_data_nodes": 2,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
各個node訊息:
GET http://localhost:9200/_cat/nodes?v
返回:
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.233.83.52 31 90 6 0.20 0.18 0.18 m - elk-es-master-elk-747456994d-rf6d6
10.233.68.101 37 83 3 0.34 0.56 0.47 m - elk-es-master-elk-747456994d-2nsb8
10.233.127.59 36 79 20 3.19 2.64 2.66 m * elk-es-master-elk-747456994d-ncs82
10.233.68.104 13 83 3 0.34 0.56 0.47 di - elk-es-data-elk-1
10.233.83.49 17 90 6 0.20 0.18 0.18 - - elk-es-coordinator-elk-79d687745d-mzhr6
10.233.68.112 28 83 3 0.34 0.56 0.47 - - elk-es-coordinator-elk-79d687745d-8p4bt
10.233.83.44 9 90 6 0.20 0.18 0.18 di - elk-es-data-elk-0
增加一個document:
PUT test-index1/test-type1/1?pretty
{
"user": "andrew",
"message": "hello elk"
}
返回:
{
"_index" : "test-index1",
"_type" : "test-type1",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
ELK所使用的日誌分析工具,可同時從多個來源接收數據,主要是把接收到的資料,做一些正則表達式的處理,變成特定的欄位,以便搜尋。
一般環境較大的話,為了減輕es或是logstash壓力,可以再細分如下圖的架構:
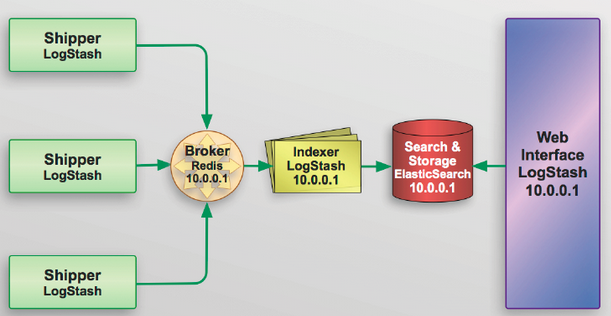
負責監控本機日誌的變化,收集日誌最新的內容,只做讀取或是轉發的動作。Shipper不一定是圖上的logstash,也可以是es公司的Beats platform(Golang寫的)。
Beats主要有下面這幾項:
- Packetbeat - 抓取網路流量,識別其中的通訊協定,支援這幾個協定:HTTP、MySQL、PostgreSQL、Redis、Thrift、DNS、MongoDB、Memcache。
- Filebeat - 對文件日誌的監控採集,如果公司環境數據量小且不需要對日誌欄位特別處理的話,可以用它,因為它比logstash輕量許多。
- Winlogbeat - Windows作業系統的日誌監控採集。
- Topbeat - 收集系統基本訊息,例如:負載、CPU、Memory、Process等。
- Metricbeat - 專門用來採集伺服器或應用服務性能指標的收集程式,支援:Apache、HAProxy、MongoDB、MySQL、Nginx、PostgreSQL、Redis、Zookeeper等。
作為緩衝區,通常使用Redis或是Kafka提供效能,類似日誌的HUB,可以用來連接多個shipper或是indexer。
負責資料的解析處理,寫入es的角色,例如:logstash的grok。
永久儲存資料的地方,例如:es
分析介面,例如:Kibana
資料量小,可靠性要求不高:
- All in one(shipper + broker + indexer): logstash/filebeat -> es -> kibana
- filebeat -> logstash -> es -> kibana
資料量大,且不允許丟失,可靠性要求較高:
- filebeat/logstash -> redis/kafka -> logstash -> es -> kibana
filebeat或是logstash從各個節點抓到的pod log,寫入es之後,每個index套用filebeat/logstash設計的 template:
GET http://localhost:9200/_cat/indices?v
返回:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open logstash-2018.05.04 QvhLRLYCTyu-8cNypV_kAA 5 1 240 0 933kb 486.2kb
green open logstash-2018.04.27 u6IHvKs6Q-ui2zBC0TxVxA 5 1 1927 0 1.4mb 733.4kb
green open logstash-2018.04.18 IVzWO2I_Sei1zE1mE8gcbg 5 1 26030 0 8.9mb 4.5mb
green open logstash-2018.05.10 HlvhR9zTQgqxmF_VPPPIEg 5 1 3112 0 2.4mb 1.1mb
green open logstash-2018.05.05 7w411PdsRUmHrZ-iDhrrXQ 5 1 289 0 1.2mb 744.3kb
green open logstash-2018.05.01 NhfG7XjKT56j9HpaBgG2Mw 5 1 263 0 1.2mb 790.9kb
green open logstash-2018.05.09 _ORSbYrIR0-Yfguo5NAP_Q 5 1 59 0 607.9kb 463.1kb
green open logstash-2018.04.28 FQLHgXlmQ0uFC9gBE25B2w 5 1 1727 0 1.6mb 935.1kb
green open logstash-2018.05.02 A1WenXkjQYurYvXSDy_A_Q 5 1 239 0 601.5kb 310.3kb
green open logstash-2018.04.23 HYRyOXq8S8Kj85TzL_aDdw 5 1 96 0 400.8kb 285kb
green open logstash-2018.05.12 fZ2fJ_o1SL20iA9PytWenA 5 1 8306 0 4.2mb 2mb
green open logstash-2018.04.20 bfvH1LNaRsaMoeGNEo1diA 5 1 1411 0 1015.1kb 522.5kb
green open logstash-2018.05.03 QiNJu4Q7R0ev-UxmRG8tdA 5 1 237 0 759.6kb 414.8kb
green open logstash-2018.05.07 cxCMuhS9TN2-ICQl-1Kq2Q 5 1 8268 0 6.4mb 3.1mb
green open logstash-2018.05.13 lJIIF-ClQAORJboE9LKyyw 5 1 25035 0 18.8mb 9.3mb
green open logstash-2018.04.21 jW41lL_KTFC6n0KbyIluLg 5 1 46 0 385.4kb 193.3kb
green open logstash-2018.05.08 qPB-IGs3S-GC7h8569zBtA 5 1 1009 0 2.1mb 991kb
green open logstash-2018.05.11 bXk4VoLCSNGjGWAlnt6qGQ 5 1 30857 0 19.9mb 10.7mb
green open logstash-2018.05.06 Wk3xTBkjTT2anmfJo0vdVw 5 1 238 0 1.2mb 758.9kb
green open logstash-2018.04.29 jXfX11jOSoGuvZomolbryQ 5 1 25 0 155.5kb 96.9kb
green open logstash-2018.04.30 H0Aw-50DS5CHikd4Nu7HLg 5 1 15454 0 10.1mb 5.5mb
查看其中一筆document:
GET http://localhost:9200/logstash-2018.05.10/doc/66uyWmMBCbP7RxBVdGIc?pretty
返回:
{
"_index" : "logstash-2018.05.10",
"_type" : "doc",
"_id" : "66uyWmMBCbP7RxBVdGIc",
"_version" : 1,
"found" : true,
"_source" : {
"host" : "elk-elk-filebeat-hsxh5",
"@timestamp" : "2018-05-10T18:57:13.427Z",
"@version" : "1",
"beat" : {
"version" : "6.2.4",
"hostname" : "elk-elk-filebeat-hsxh5",
"name" : "elk-elk-filebeat-hsxh5"
},
"tags" : [
"beats_input_codec_plain_applied"
],
"offset" : 4022,
"stream" : "stdout",
"message" : "2018-05-11T02:57:13.426+0800 I NETWORK [conn225235] received client metadata from 127.0.0.1:46116 conn225235: { application: { name: \"MongoDB Shell\" }, driver: { name: \"MongoDB Internal Client\", version: \"3.4.10\" }, os: { type: \"Linux\", name: \"PRETTY_NAME=\"Debian GNU/Linux 8 (jessie)\"\", architecture: \"x86_64\", version: \"Kernel 4.16.0-1.el7.elrepo.x86_64\" } }",
"kubernetes" : {
"node" : {
"name" : "tp-master01"
},
"namespace" : "lab01",
"labels" : {
"app" : "mongodb-mongodb-lab01",
"component" : "db",
"pod-template-hash" : "3730037732",
"release" : "mongodb-lab01"
},
"pod" : {
"name" : "mongodb-mongodb-lab01-7c7447cc76-s9cx4"
},
"container" : {
"name" : "mongodb"
}
},
"prospector" : {
"type" : "docker"
},
"source" : "/var/lib/docker/containers/63808bfa68a3ef3f08c0ba033bfc366d247149cdb68014372d364770be4c8752/63808bfa68a3ef3f08c0ba033bfc366d247149cdb68014372d364770be4c8752-json.log"
}
}
add_kubernetes_metadata processor很聰明的把Pod Name、Namespace、labels劃分好欄位。
將filebeat/logstash過濾完或是正則表達式處理完的資料,以視覺化的方式呈現給使用者。
查看ELK相關pod:
kubectl get po -l release=elk
返回:
NAME READY STATUS RESTARTS AGE
elk-elk-es-coordinator-76cbb74fd-f6jq2 1/1 Running 0 5m
elk-elk-es-coordinator-76cbb74fd-xrlx9 1/1 Running 0 5m
elk-elk-es-data-0 1/1 Running 0 5m
elk-elk-es-data-1 1/1 Running 0 4m
elk-elk-es-master-687d5bd4b4-4c2d6 1/1 Running 0 5m
elk-elk-es-master-687d5bd4b4-p96g6 1/1 Running 0 5m
elk-elk-es-master-687d5bd4b4-pv7k9 1/1 Running 0 5m
elk-elk-filebeat-44mqw 1/1 Running 0 5m
elk-elk-filebeat-tj2g8 1/1 Running 0 5m
elk-elk-filebeat-zjvk5 1/1 Running 0 5m
elk-elk-kibana-bfccb4fdd-9jfnw 1/1 Running 0 5m
elk-elk-logstash-78fd8d78f6-sgfh5 1/1 Running 0 5m
查看kibana pod log:
kubectl logs -f elk-elk-kibana-bfccb4fdd-9jfnw
返回:
{"type":"log","@timestamp":"2018-05-14T07:31:27Z","tags":["info","optimize"],"pid":1,"message":"Optimizing and caching bundles for stateSessionStorageRedirect, status_page, timelion, dashboardViewer, apm and kibana. This may take a few minutes"}
第一次kibana需要做優化跟cache的處理,所以時間會比較久。
使用瀏覽器,敲入:http://192.168.2.3:30061,打開kibana。
- 192.168.2.3 是 k8s node ip
- 30061是kibana的nodeport
由於現在kibana預設在k8s cm的設置已經跟es連上了,所以要configure index pattern:
點擊左側的Management -> Kibana Index Patterns -> Step 1 of 2: Define index pattern(鍵入logstash-*) -> Next step
Step 2 of 2: Configure settings -> 選@timestamp -> Create index pattern
如果index pattern加入成功的話,會如下圖:
