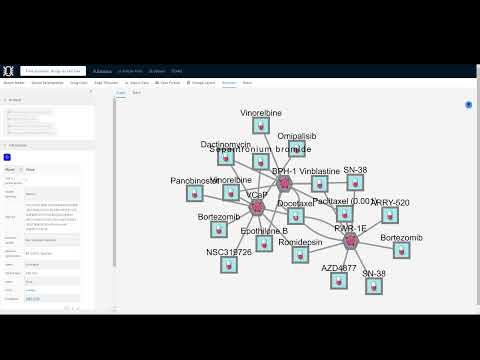
Our platform provides an immersive experience for exploring and analyzing a segment of the dataset from Gonçalves et al.. With a primary focus on identifying associated proteins and drugs for individual or groups of proteins, VISPER offers comprehensive tools for in-depth research.
This repository contains the code for the Visualization System for Interactions between Proteins and Drugs for Exploratory Research(VISPER). To use VISPER locally on your PC, we recommend using the Docker version of VISPER. For detailed instructions, see the Docker installation instructions.
The code is divided into three main categories:
- Frontend - Code for the VISPER frontend
- Backend - FastAPI server, Neo4j dump, and other utilities
- Docker - docker-compose.yml to install and run VISPER in a Docker container
- db - Includes almost all files to create a neo4j docker image
These categories are further divided into subcategories.
The frontend is divided into several components:
- public: Used images.
- src/components: Includes all the components of the web application.
- Database: List and information for used datasets.
- FAQ: General information, used licenses, and answers to common questions.
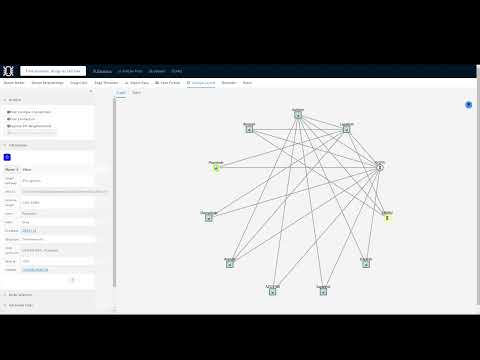
- Graph: Network graph and tools for the graph (e.g., filters).
- ListSearch: Search for a group of entities.
- NavigationBar: Allows access to all sub-websites.
- Overview: Show ProCan Plots.
- SearchBar: Search for one entity.
- Upload: Upload new data to the database.
- App: Main component of the React application.
- index: Entry point of the React application.
The backend is divided into several subcategories:
- data: Stores the uploaded files.
- data_info: Stores the uploaded md files.
- example: Contains example files that can be used for uploading data.
- help_data: Files created during data processing.
- help_tools: Programs that help with adding data to the database, performing investigations, and creating diagrams.
- neo4j_database_dump: Backup of the Neo4j database.
- plot_data: Contains the data for the ProCan plots.
- settings: Contains files that specify how an uploaded file should be integrated into the database.
- similarity_data: Calcukated similarity values.
- allgemeine_info: Contains all data for filter options.
- database: Contains all information about the used datasets.
- datasets: List of used datasets.
- file_converter: Integrates the uploaded file into the Neo4j database.
- main: FastAPI Server.
- updateDBInfo: Updates the allgemeine_info file after new data has been integrated into the database.
Contains almost all neo4j data to create a neo4j docker image. In addition, based on a neo4j backup, the database and transaction folders must be copied to the data folder. The executable jar files of apoc-5.12.0-core and neo4j-graph-data-science-2.5.5 must also be added to the plugins ornder.
- conf: Configuration files for neo4j.
- data: Folder which includes all data for the neo4j db.
- logs: Folder for debug and neo4j logs.
- plugins: Contains the neo4j plugins.
- Install all necessary Python and JS libraries.
- Setup a local Neo4j database (Version: 5.12.0 Community Edition) with the APOC and Graph Data Science Library. → Load backup into the new Neo4j database.
neo4j stop
neo4j-admin database load --from-path=C:\backup\backup neo4j --overwrite-destination=true
neo4j start
Note: change the file paths according to your configuration
- Call http://localhost:7474/browser/ and execute the following Neo4j cipher
CREATE INDEX IF NOT EXISTS FOR (d:Drug) ON (d.name);
CREATE INDEX IF NOT EXISTS FOR (p:Protein) ON (p.name);
CREATE INDEX IF NOT EXISTS FOR (c:Cell_Line) ON (c.name);
CREATE INDEX IF NOT EXISTS FOR (d:Drug) ON (d.uid);
CREATE INDEX IF NOT EXISTS FOR (p:Protein) ON (p.uid);
CREATE INDEX IF NOT EXISTS FOR (c:Cell_Line) ON (c.uid);
CREATE INDEX IF NOT EXISTS FOR (d:Drug) ON (d.drug_id);
CREATE INDEX IF NOT EXISTS FOR (d:Drug) ON (d.CHEMBL);
CREATE INDEX IF NOT EXISTS FOR (c:Cell_Line) ON (c.COSMIC_ID);
CREATE INDEX IF NOT EXISTS FOR (p:Protein) ON (p.swiss);
CALL gds.graph.project("graph", "Protein", {PPI: {orientation: "UNDIRECTED"}});
- Start the fastapi server
cd backend
python -m uvicorn main:app
- Start the development server
cd frontend
npm start
To use VISPER, you have two options: either utilize Docker or set up your own server.
- Install Docker Desktop
- Optional: Restart your pc after the installation
- Download the docker-compose.yml from the docker folder of this repository. Important: Do not use the wrong docker-compose file!
- Open the terminal in the folder where you placed the docker-compose.yml and run the following command:
docker-compose up
(Optional: First run docker-compose pull) This process can take some time (approximately 40 minutes). 5. Call http://localhost:7474/browser/ and execute the following Neo4j cipher (user: neo4j, password: workwork).
CREATE INDEX IF NOT EXISTS FOR (d:Drug) ON (d.name);
CREATE INDEX IF NOT EXISTS FOR (p:Protein) ON (p.name);
CREATE INDEX IF NOT EXISTS FOR (c:Cell_Line) ON (c.name);
CREATE INDEX IF NOT EXISTS FOR (d:Drug) ON (d.uid);
CREATE INDEX IF NOT EXISTS FOR (p:Protein) ON (p.uid);
CREATE INDEX IF NOT EXISTS FOR (c:Cell_Line) ON (c.uid);
CREATE INDEX IF NOT EXISTS FOR (d:Drug) ON (d.drug_id);
CREATE INDEX IF NOT EXISTS FOR (d:Drug) ON (d.CHEMBL);
CREATE INDEX IF NOT EXISTS FOR (c:Cell_Line) ON (c.COSMIC_ID);
CREATE INDEX IF NOT EXISTS FOR (p:Protein) ON (p.swiss);
CALL gds.graph.project("graph", "Protein", {PPI: {orientation: "UNDIRECTED"}});
- The website should be running on http://localhost:3000/
- Install all necessary python and js libraries
- Setup a local Neo4j database (Version: 5.12.0 Community Edition) with the APOC and Graph Data Science Library. → load backup in to the new neo4j database
neo4j stop
neo4j-admin database load --from-path=C:\backup\backup neo4j --overwrite-destination=true
neo4j start
Note: change the file paths according to your configuration
- Call http://localhost:7474/browser/ and execute the following Neo4j cipher
CREATE INDEX IF NOT EXISTS FOR (d:Drug) ON (d.name);
CREATE INDEX IF NOT EXISTS FOR (p:Protein) ON (p.name);
CREATE INDEX IF NOT EXISTS FOR (c:Cell_Line) ON (c.name);
CREATE INDEX IF NOT EXISTS FOR (d:Drug) ON (d.uid);
CREATE INDEX IF NOT EXISTS FOR (p:Protein) ON (p.uid);
CREATE INDEX IF NOT EXISTS FOR (c:Cell_Line) ON (c.uid);
CREATE INDEX IF NOT EXISTS FOR (d:Drug) ON (d.drug_id);
CREATE INDEX IF NOT EXISTS FOR (d:Drug) ON (d.CHEMBL);
CREATE INDEX IF NOT EXISTS FOR (c:Cell_Line) ON (c.COSMIC_ID);
CREATE INDEX IF NOT EXISTS FOR (p:Protein) ON (p.swiss);
CALL gds.graph.project("graph", "Protein", {PPI: {orientation: "UNDIRECTED"}});
- Start the fastapi server
cd backend
python -m uvicorn main:app
- Start the development server
cd frontend
npm run build
cd build
python -m SimpleHTTPServer 7000
- DrugBank under Creative Common's Attribution-NonCommercial 4.0 International License. Link to download
- BioGRID under MIT License. Link to download
- Cell Line node picture: Image of a biology cancer cell, obtained from Iconduck and licensed under CC BY 3.0. Link to image
- Spider picture: Modified image of bug spider 2, sourced from Iconduck and licensed under CC0. Link to image