Multimodal entity linking (MEL) aims to utilize multimodal information to map mentions to corresponding entities defined in knowledge bases. We release three MEL datasets: Weibo-MEL, Wikidata-MEL and Richpedia-MEL, containing 25,602, 18,880 and 17,806 samples from social media, encyclopedia and multimodal knowledge graphs respectively. A MEL dataset construction approach is proposed, including five stages: multimodal information extraction, mention extraction, entity extraction, triple construction and dataset construction. Experiment results demonstrate the usability of the datasets and the distinguishability between baseline models.
Multimodal entity linking (MEL) aims to utilize multimodal information to map mentions to corresponding entities defined in knowledge bases. We release three MEL datasets: Weibo-MEL, Wikidata-MEL and Richpedia-MEL, containing 25,602, 18,880 and 17,806 samples from social media, encyclopedia and multimodal knowledge graphs respectively. A MEL dataset construction approach is proposed, including five stages: multimodal information extraction, mention extraction, entity extraction, triple construction and dataset construction. Experiment results demonstrate the usability of the datasets and the distinguishability between baseline models.
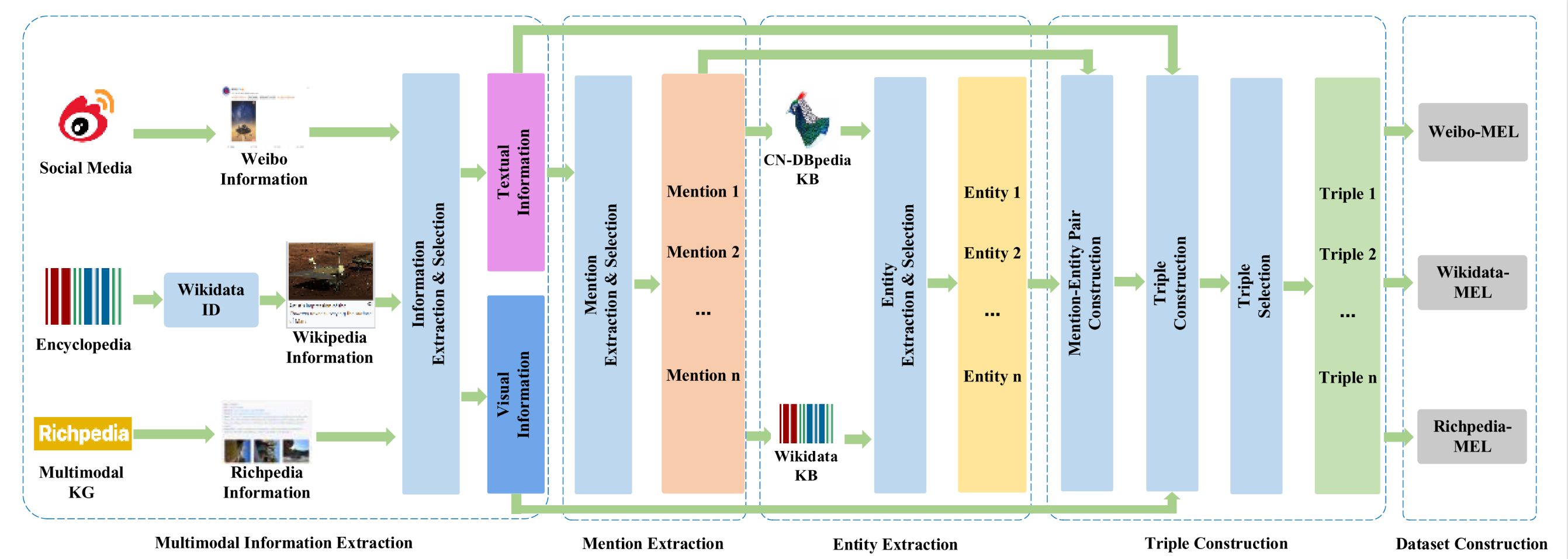
To construct large-scale MEL datasets, we propose a MEL dataset construction approach, including five stages. In Multimodal Information Extraction, we select multimodal data sources and extract textual and visual information. In Mention Extraction, we extract mentions from textual information and keep the mentions which corresponding entities may exist. In Entity Extraction, we query the knowledge bases with the filtered mentions, gather the entity lists, and save the correct entities. In Triple Construction, we merge the corresponding mentions and entities into mention-entity (M-E) pairs, and combine them into triples with textual and visual information. Then, we keep the correct triples as the samples of the MEL dataset. Finally, in Dataset Construction stage, we partition the dataset into training set (70%), validation set (10%) and testing set (20%). The overview of the approach is illustrated in figure below.
Due to the large size of the visual information and knowledge graph resources, we deposited these resources in the Baidu Cloud Disk.
Visual information download addresses:
Knowledge graph download addresses:
The extraction codes are 2021.
Visual information:

Textual information:
- 【感谢30年的坚守!#辽宁舰首位一级军士长退役# 】近日,辽宁舰为首位一级军士长刘德波举行了隆重的退役仪式。刘德波,1990年12月入伍,服役期间,荣获全军士官优秀人才奖二等奖1次,荣立二等功1次,三等功4次。入伍30年,他坚守在不见阳光的深舱,始终与高温和热浪相伴,穿梭于管路和设备之间,把最美好的青春年华都献给了心爱的战舰。致敬!(北海舰队)#我为中国军人点赞# [组图共9张] 原图
Mention-entity pairs:
- "刘德波": "刘德波"
- "中国": "中国(世界四大文明古国之一)"
- "辽宁舰": "中国人民解放军海军辽宁舰"
Visual information:

Textual information:
- Seattle Mayor Charles L. Smith (left) with Will Rogers, circa 1935.
Mention-entity pairs:
- "Charles L. Smith": "Charles L. Smith (Seattle politician)"
- "Will Rogers": "Will Rogers"
Visual information:

Textual information:
- Washington resigned his commission after the Treaty of Paris in 1783.
Mention-entity pairs:
- "Washington": "George Washington"