The Discovery datasets consists of adjacent sentence pairs (s1,s2) with a discourse marker (y) that occured at the beginning of s2. They were extracted from the depcc web corpus.
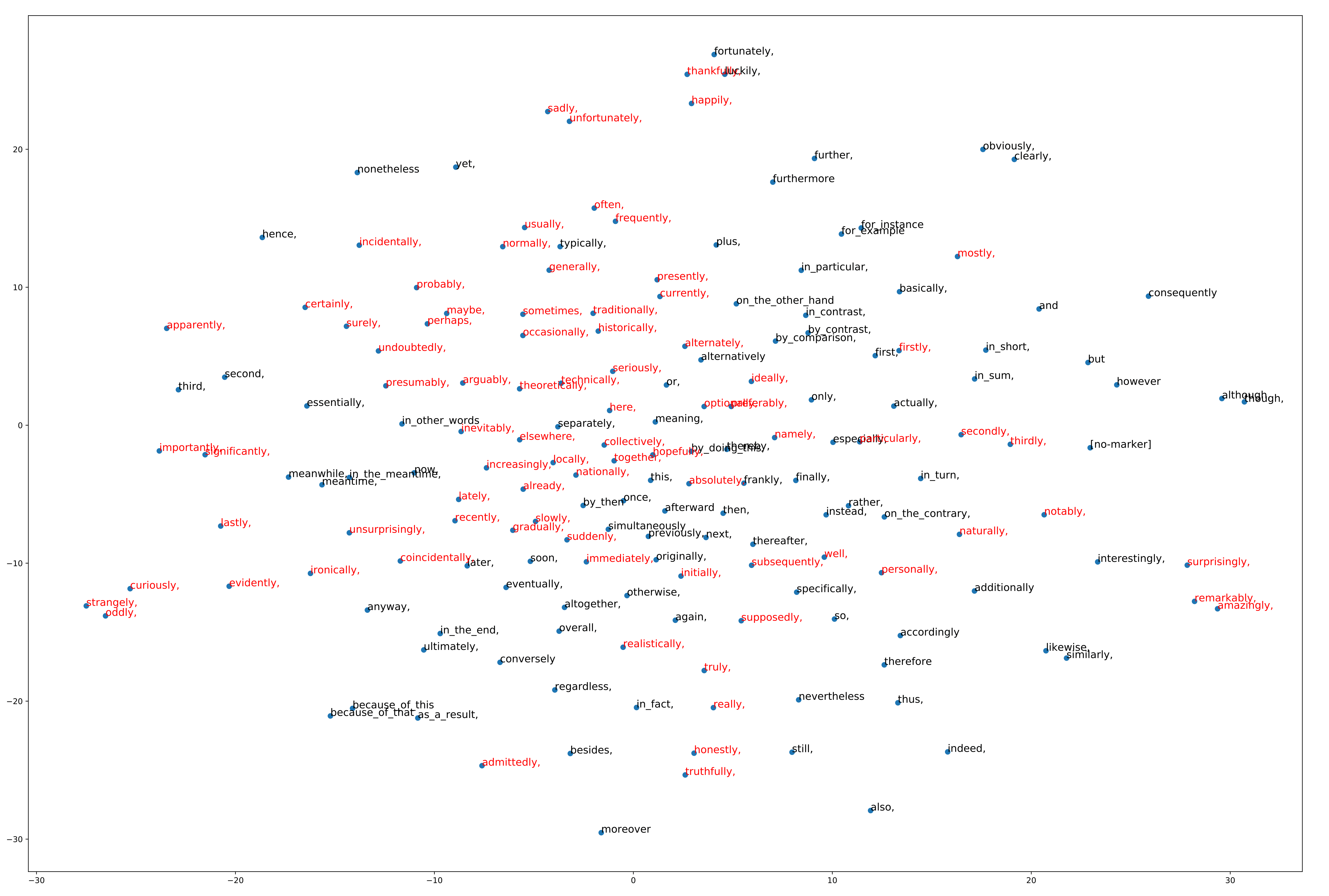
Markers prediction can be used in order to train a sentence encoders. Discourse markers can be considered as noisy labels for various semantic tasks, such as entailment (y=therefore), subjectivity analysis (y=personally) or sentiment analysis (y=sadly), similarity (y=similarly), typicality, (y=curiously) ...
The specificity of this dataset is the diversity of the markers, since previously used data used only ~10 imbalanced classes. In this repository, you can find:
- a list of the 174 discourse markers we obtained
- a
Baseversion of our dataset with 1.74 million pairs (10k exemples per marker) - a
Bigversion with 3.4 million pairs - a
Hardversion with 1.74 million pairs where the connective couldn't be predicted with a fasttext linear model
| s1 | s2 | y |
|---|---|---|
| The motivations for playing are vastly different , and yet Spin the Bottle manages to meet the needs of all its players . | It is a well crafted game . | truly, |
| Prefiguring The General many years later , Bernard liked nothing better than to cock a snoot at the law . | Men working on a bog , less than a mile from the Kirwan farm , dug up a human torso . | eventually, |
| Think a certain vertical market or knowledge about multilocations ' unique needs . | Ernest 's strength lay in the multilocation arena and gives Birch a new capability . | indeed, |
| @ Sklivvz : but you are implicitly using one such interpretation yourself . | One that tells you that it 's unphysical to ask anything except measurements . | namely, |
| Perhaps the Jeanneau 's are a bargain compared to similarly capable boats from B or C. . | Seattle , the prices for the 36 and 39 went down about 20G , a 39 now sells for a bit more than the 36 did . | locally, |
Now available on Huggingface Datasets 🤗 (GLUE-compatible format):
import datasets
datasets.load_dataset("discovery","discovery")We also provide a script to collect new datasets in demo.ipynb
We also provide a huggingface 🤗 pre-trained discourse connective prediction model built upon roberta-base.
https://huggingface.co/sileod/roberta-base-discourse-marker-prediction
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("sileod/roberta-base-discourse-marker-prediction")
model = AutoModelForSequenceClassification.from_pretrained("sileod/roberta-base-discourse-marker-prediction")This model can be used as a pretrained model for discourse/pragmatics related tasks.
We also provide a semantic analysis of the markers, which can be used for zero-shot classification (e.g. sentiment analysis) https://github.com/synapse-developpement/DiscSense/
@inproceedings{sileo-etal-2019-mining,
title = "Mining Discourse Markers for Unsupervised Sentence Representation Learning",
author = "Sileo, Damien and
Van De Cruys, Tim and
Pradel, Camille and
Muller, Philippe",
booktitle = "Proceedings of the 2019 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)",
month = jun,
year = "2019",
address = "Minneapolis, Minnesota",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/N19-1351",
pages = "3477--3486",
}
For further information, you can contact: