Datasette Plugins #14
Comments
|
The plugin system can also allow alternative providers for the |
|
Plugins should be able to interact with the build step. This would give plugins an opportunity to modify the SQL databases and help prepare them for serving - for example, a full-text search plugin might create additional FTS tables, or a mapping plugin might pre-calculate a bunch of geohashes for tables that have latitude/longitude values. Plugins could really take advantage of the immutable nature of the dataset here. |
|
For visualizations, Google Maps should be made available as a plugin. The default visualizations can use Leaflet and Open Street Map, but there's no reason to not make Google Maps available as a plugin, especially if the plugin can provide a mechanism for configuring the necessary API key. I'm particularly excited in the Google Maps heatmap visualization https://developers.google.com/maps/documentation/javascript/heatmaplayer as seen on http://mochimachine.org/wasteland/ |
|
I'd also suggest taking a look at stevedore, which has a ton of tools for doing plugin stuff. I've had good luck with it in the past. |
|
Oh thanks, that definitely looks like an interesting option. |
|
I started a thread on Twitter asking people for good examples of Python projects with a strong plugin ecosystem: https://twitter.com/simonw/status/985377670388105216 The most impressive example that came back was pytest - which now has nearly 400 plugins: https://plugincompat.herokuapp.com/ The pytest plugin infrastructure is available as an independent package called pluggy - which appears to offer everything I need for Datasette. I'm going to give that a go and see how well it works: https://pluggy.readthedocs.io/en/latest/ |
|
Datasette 1.0 will be the release of Datasette that attempts to provide a stable plugin API: https://github.com/simonw/datasette/milestone/7 There's a lot of work to be done before then, but as a starting point I'm going to support two very simple extension mechanisms:
The template system hook will go near here: Lines 1225 to 1228 in efbb4e8 The SQLite connection hook will go near here: Lines 1094 to 1098 in efbb4e8 These two feel simple enough that I'm not worried that I might design an API that I later regret. |
|
Tox is a good example of a project that uses pluggy in the way I want to use it (function hooks rather than classes): https://github.com/tox-dev/tox/blob/master/tox/hookspecs.py |
Uses pluggy: https://pluggy.readthedocs.io/ Two example plugins - an uppercase template filter and a convert_units() SQL function.
|
OK, from that prototype in f2720b0 it looks like pluggy provides a solid path forward. Next steps:
|
|
Here's a demo of the
|

|
Once I've got the plugins mechanism stable and people start releasing plugins it would be useful to have a dedicated Trove classifier on PyPI for Datasette plugins - This would help me build a Datasette equivalent of the http://plugincompat.herokuapp.com/ site, which works by scanning PyPI for items with the It looks like the mechanism for requesting new PyPI classifiers is to file a ticket against warehouse, like these ones: pypi/warehouse#3570 and pypi/warehouse#2881 |
|
I created https://github.com/simonw/datasette-plugin-demos which is now published to PyPI and can be installed with |
|
Slight code design problem... when I tried installing my branch in a fresh virtual environment I got this error, because Looks like I've run into point 6 on https://packaging.python.org/guides/single-sourcing-package-version/ :
|
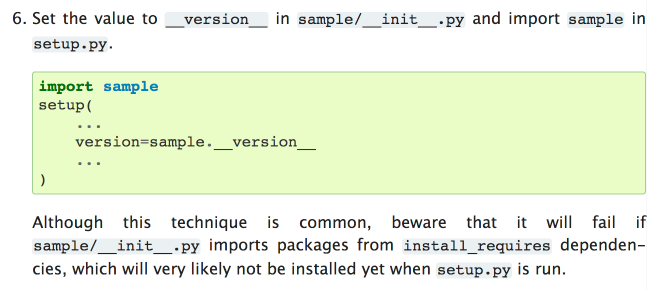
Running `from datasette import __version__` in `setup.py` was throwing an error `ModuleNotFoundError: No module named 'pluggy'` See https://packaging.python.org/guides/single-sourcing-package-version/ Refs #14
Uses https://pluggy.readthedocs.io/ originally created for the py.test project We're starting with two plugin hooks: prepare_connection(conn) This is called when a new SQLite connection is created. It can be used to register custom SQL functions. prepare_jinja2_environment(env) This is called with the Jinja2 environment. It can be used to register custom template tags and filters. An example plugin which uses these two hooks can be found at https://github.com/simonw/datasette-plugin-demos or installed using `pip install datasette-plugin-demos` Refs #14
|
I should check if it's possible to have two template registration function plugins in a single plugin module. If it isn't maybe I should use class plugins instead of module plugins. |
|
Annoyingly, the following only results in the last of the two |
|
I think that's OK. The two plugins I've implemented so far ( The syntactic sugar idea in #220 can help here too. |
|
I just shipped Datasette 0.19 with where I'm at so far: https://github.com/simonw/datasette/releases/tag/0.19 |
|
I added a mechanism for plugins to serve static files and define custom CSS and JS URLs in #214 - see new documentation on http://datasette.readthedocs.io/en/latest/plugins.html#static-assets and http://datasette.readthedocs.io/en/latest/plugins.html#extra-css-urls |
|
I released everything we have so far in Datasette 0.20 and built and released an example plugin, datasette-cluster-map. Here's my blog entry about it: https://simonwillison.net/2018/Apr/20/datasette-plugins/ |
|
Here's a link demonstrating my new plugin: https://datasette-cluster-map-demo.now.sh/polar-bears-455fe3a/USGS_WC_eartags_output_files_2009-2011-Status |
This change introduces a new plugin hook, publish_subcommand, which can be used to implement new subcommands for the "datasette publish" command family. I've used this new hook to refactor out the "publish now" and "publish heroku" implementations into separate modules. I've also added unit tests for these two publishers, mocking the subprocess.call and subprocess.check_output functions. As part of this, I introduced a mechanism for loading default plugins. These are defined in the new "default_plugins" list inside datasette/app.py Closes #217 (Plugin support for datasette publish) Closes #348 (Unit tests for "datasette publish") Refs #14, #59, #102, #103, #146, #236, #347
… heroku/now (#349) This change introduces a new plugin hook, publish_subcommand, which can be used to implement new subcommands for the "datasette publish" command family. I've used this new hook to refactor out the "publish now" and "publish heroku" implementations into separate modules. I've also added unit tests for these two publishers, mocking the subprocess.call and subprocess.check_output functions. As part of this, I introduced a mechanism for loading default plugins. These are defined in the new "default_plugins" list inside datasette/app.py Closes #217 (Plugin support for datasette publish) Closes #348 (Unit tests for "datasette publish") Refs #14, #59, #102, #103, #146, #236, #347
This adds two new plugin hooks: The `inspect` hook allows plugins to add data to the inspect dictionary. The `prepare_sanic` hook allows plugins to hook into the web router. I've attached a warning to this hook in the docs in light of simonw#272 but I want this hook now... On quick inspection, I don't think it's worthwhile to try and make this hook independent of the web framework (but it looks like Starlette would make the hook implementation a bit nicer). Ref simonw#14
This adds two new plugin hooks: The `inspect` hook allows plugins to add data to the inspect dictionary. The `prepare_sanic` hook allows plugins to hook into the web router. I've attached a warning to this hook in the docs in light of simonw#272 but I want this hook now... On quick inspection, I don't think it's worthwhile to try and make this hook independent of the web framework (but it looks like Starlette would make the hook implementation a bit nicer). Ref simonw#14
|
We've grown a bunch of plugin hooks over the past two years: https://datasette.readthedocs.io/en/latest/plugins.html#plugin-hooks Since the plugin system will never be 100% "finished", I'm closing this in favor of the label: plugins |
It would be neat if additional functionality could be opted-in to the system in the form of easy-to-add plugins, hosted as separate packages. First example: a Google Analytics plugin, which adds GA tracking code with your tracking ID to the web interface for your dataset.
This may be an opportunity to experiment with entry points: http://amir.rachum.com/blog/2017/07/28/python-entry-points/
The text was updated successfully, but these errors were encountered: