![]()

- Silero Models
Silero Models: pre-trained enterprise-grade STT / TTS models and benchmarks.
Enterprise-grade STT made refreshingly simple (seriously, see benchmarks). We provide quality comparable to Google's STT (and sometimes even better) and we are not Google.
As a bonus:
- No Kaldi;
- No compilation;
- No 20-step instructions;
Also we have published TTS models that satisfy the following criteria:
- One-line usage;
- A large library of voices;
- A fully end-to-end pipeline;
- Natural-sounding speech;
- No GPU or training required;
- Minimalism and lack of dependencies;
- Faster than real-time on one CPU thread (!!!);
- Support for 16kHz and 8kHz out of the box;
Also we have published a model for text repunctuation and recapitalization that:
- Inserts capital letters and basic punctuation marks, e.g., dots, commas, hyphens, question marks, exclamation points, and dashes (for Russian);
- Works for 4 languages (Russian, English, German, and Spanish) and can be extended;
- Domain-agnostic by design and not based on any hard-coded rules;
- Has non-trivial metrics and succeeds in the task of improving text readability;
You can basically use our models in 3 flavours:
- Via PyTorch Hub:
torch.hub.load(); - Via pip:
pip install sileroand thenimport silero; - Via caching the required models and utils manually and modifying if necessary;
Models are downloaded on demand both by pip and PyTorch Hub. If you need caching, do it manually or via invoking a necessary model once (it will be downloaded to a cache folder). Please see these docs for more information.
PyTorch Hub and pip package are based on the same code. All of the torch.hub.load examples can be used with the pip package via this basic change:
# before
torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_stt', # or silero_tts or silero_te
**kwargs)
# after
from silero import silero_stt, silero_tts, silero_te
silero_stt(**kwargs)All of the provided models are listed in the models.yml file. Any metadata and newer versions will be added there.
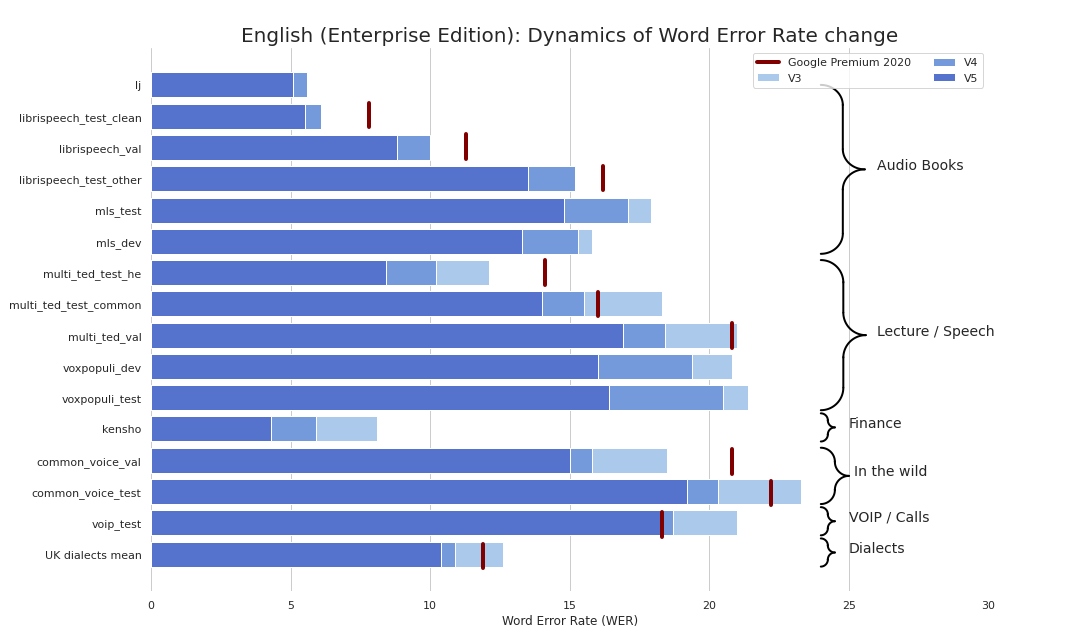
Currently we provide the following checkpoints:
| PyTorch | ONNX | Quantization | Quality | Colab | |
|---|---|---|---|---|---|
English (en_v6) |
✔️ | ✔️ | ✔️ | link | |
English (en_v5) |
✔️ | ✔️ | ✔️ | link | |
German (de_v4) |
✔️ | ✔️ | ⌛ | link | |
English (en_v3) |
✔️ | ✔️ | ✔️ | link | |
German (de_v3) |
✔️ | ⌛ | ⌛ | link | |
German (de_v1) |
✔️ | ✔️ | ⌛ | link | |
Spanish (es_v1) |
✔️ | ✔️ | ⌛ | link | |
Ukrainian (ua_v3) |
✔️ | ✔️ | ✔️ | N/A |
Model flavours:
| jit | jit | jit | jit | jit_q | jit_q | onnx | onnx | onnx | onnx | |
|---|---|---|---|---|---|---|---|---|---|---|
| xsmall | small | large | xlarge | xsmall | small | xsmall | small | large | xlarge | |
English en_v6 |
✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
English en_v5 |
✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
English en_v4_0 |
✔️ | ✔️ | ||||||||
English en_v3 |
✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ||
German de_v4 |
✔️ | ✔️ | ||||||||
German de_v3 |
✔️ | |||||||||
German de_v1 |
✔️ | ✔️ | ||||||||
Spanish es_v1 |
✔️ | ✔️ | ||||||||
Ukrainian ua_v3 |
✔️ | ✔️ | ✔️ |
- All examples:
torch, 1.8+ (used to clone the repo in TensorFlow and ONNX examples), breaking changes for versions older than 1.6torchaudio, latest version bound to PyTorch should just workomegaconf, latest should just work
- Additional dependencies for ONNX examples:
onnx, latest should just workonnxruntime, latest should just work
- Additional for TensorFlow examples:
tensorflow, latest should just worktensorflow_hub, latest should just work
Please see the provided Colab for details for each example below. All examples are maintained to work with the latest major packaged versions of the installed libraries.
import torch
import zipfile
import torchaudio
from glob import glob
device = torch.device('cpu') # gpu also works, but our models are fast enough for CPU
model, decoder, utils = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_stt',
language='en', # also available 'de', 'es'
device=device)
(read_batch, split_into_batches,
read_audio, prepare_model_input) = utils # see function signature for details
# download a single file in any format compatible with TorchAudio
torch.hub.download_url_to_file('https://opus-codec.org/static/examples/samples/speech_orig.wav',
dst ='speech_orig.wav', progress=True)
test_files = glob('speech_orig.wav')
batches = split_into_batches(test_files, batch_size=10)
input = prepare_model_input(read_batch(batches[0]),
device=device)
output = model(input)
for example in output:
print(decoder(example.cpu()))Our model will run anywhere that can import the ONNX model or that supports the ONNX runtime.
import onnx
import torch
import onnxruntime
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils
_, decoder, utils = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_stt', language=language)
(read_batch, split_into_batches,
read_audio, prepare_model_input) = utils
# see available models
torch.hub.download_url_to_file('https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml', 'models.yml')
models = OmegaConf.load('models.yml')
available_languages = list(models.stt_models.keys())
assert language in available_languages
# load the actual ONNX model
torch.hub.download_url_to_file(models.stt_models.en.latest.onnx, 'model.onnx', progress=True)
onnx_model = onnx.load('model.onnx')
onnx.checker.check_model(onnx_model)
ort_session = onnxruntime.InferenceSession('model.onnx')
# download a single file in any format compatible with TorchAudio
torch.hub.download_url_to_file('https://opus-codec.org/static/examples/samples/speech_orig.wav', dst ='speech_orig.wav', progress=True)
test_files = ['speech_orig.wav']
batches = split_into_batches(test_files, batch_size=10)
input = prepare_model_input(read_batch(batches[0]))
# actual ONNX inference and decoding
onnx_input = input.detach().cpu().numpy()
ort_inputs = {'input': onnx_input}
ort_outs = ort_session.run(None, ort_inputs)
decoded = decoder(torch.Tensor(ort_outs[0])[0])
print(decoded)SavedModel example
import os
import torch
import subprocess
import tensorflow as tf
import tensorflow_hub as tf_hub
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils using torch.hub for brevity
_, decoder, utils = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_stt', language=language)
(read_batch, split_into_batches,
read_audio, prepare_model_input) = utils
# see available models
torch.hub.download_url_to_file('https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml', 'models.yml')
models = OmegaConf.load('models.yml')
available_languages = list(models.stt_models.keys())
assert language in available_languages
# load the actual tf model
torch.hub.download_url_to_file(models.stt_models.en.latest.tf, 'tf_model.tar.gz')
subprocess.run('rm -rf tf_model && mkdir tf_model && tar xzfv tf_model.tar.gz -C tf_model', shell=True, check=True)
tf_model = tf.saved_model.load('tf_model')
# download a single file in any format compatible with TorchAudio
torch.hub.download_url_to_file('https://opus-codec.org/static/examples/samples/speech_orig.wav', dst ='speech_orig.wav', progress=True)
test_files = ['speech_orig.wav']
batches = split_into_batches(test_files, batch_size=10)
input = prepare_model_input(read_batch(batches[0]))
# tf inference
res = tf_model.signatures["serving_default"](tf.constant(input.numpy()))['output_0']
print(decoder(torch.Tensor(res.numpy())[0]))All of the provided models are listed in the models.yml file. Any metadata and newer versions will be added there.
V4 models support SSML. Also see Colab examples for main SSML tag usage.
| ID | Speakers | Auto-stress | Language | SR | Colab |
|---|---|---|---|---|---|
v4_ru |
aidar, baya, kseniya, xenia, eugene, random |
yes | ru (Russian) |
8000, 24000, 48000 |
|
v4_cyrillic |
b_ava, marat_tt, kalmyk_erdni... |
no | cyrillic (Avar, Tatar, Kalmyk, ...) |
8000, 24000, 48000 |
|
v4_ua |
mykyta, random |
no | ua (Ukrainian) |
8000, 24000, 48000 |
|
v4_uz |
dilnavoz |
no | uz (Uzbek) |
8000, 24000, 48000 |
|
v4_indic |
hindi_male, hindi_female, ..., random |
no | indic (Hindi, Telugu, ...) |
8000, 24000, 48000 |
V3 models support SSML. Also see Colab examples for main SSML tag usage.
| ID | Speakers | Auto-stress | Language | SR | Colab |
|---|---|---|---|---|---|
v3_en |
en_0, en_1, ..., en_117, random |
no | en (English) |
8000, 24000, 48000 |
|
v3_en_indic |
tamil_female, ..., assamese_male, random |
no | en (English) |
8000, 24000, 48000 |
|
v3_de |
eva_k, ..., karlsson, random |
no | de (German) |
8000, 24000, 48000 |
|
v3_es |
es_0, es_1, es_2, random |
no | es (Spanish) |
8000, 24000, 48000 |
|
v3_fr |
fr_0, ..., fr_5, random |
no | fr (French) |
8000, 24000, 48000 |
|
v3_indic |
hindi_male, hindi_female, ..., random |
no | indic (Hindi, Telugu, ...) |
8000, 24000, 48000 |
Basic dependencies for Colab examples:
torch, 1.10+ for v3 models/ 2.0+ for v4 models;torchaudio, latest version bound to PyTorch should work (required only because models are hosted together with STT, not required for work);omegaconf, latest (can be removed as well, if you do not load all of the configs);
# V4
import torch
language = 'ru'
model_id = 'v4_ru'
sample_rate = 48000
speaker = 'xenia'
device = torch.device('cpu')
model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_tts',
language=language,
speaker=model_id)
model.to(device) # gpu or cpu
audio = model.apply_tts(text=example_text,
speaker=speaker,
sample_rate=sample_rate)- Standalone usage only requires PyTorch 1.10+ and the Python Standard Library;
- Please see the detailed examples in Colab;
# V4
import os
import torch
device = torch.device('cpu')
torch.set_num_threads(4)
local_file = 'model.pt'
if not os.path.isfile(local_file):
torch.hub.download_url_to_file('https://models.silero.ai/models/tts/ru/v4_ru.pt',
local_file)
model = torch.package.PackageImporter(local_file).load_pickle("tts_models", "model")
model.to(device)
example_text = 'В недрах тундры выдры в г+етрах т+ырят в вёдра ядра кедров.'
sample_rate = 48000
speaker='baya'
audio_paths = model.save_wav(text=example_text,
speaker=speaker,
sample_rate=sample_rate)Check out our TTS Wiki page.
Supported tokenset:
!,-.:?iµöабвгдежзийклмнопрстуфхцчшщъыьэюяёђѓєіјњћќўѳғҕҗҙқҡңҥҫүұҳҷһӏӑӓӕӗәӝӟӥӧөӱӳӵӹ
| Speaker_ID | Language | Gender |
|---|---|---|
| b_ava | Avar | F |
| b_bashkir | Bashkir | M |
| b_bulb | Bulgarian | M |
| b_bulc | Bulgarian | M |
| b_che | Chechen | M |
| b_cv | Chuvash | M |
| cv_ekaterina | Chuvash | F |
| b_myv | Erzya | M |
| b_kalmyk | Kalmyk | M |
| b_krc | Karachay-Balkar | M |
| kz_M1 | Kazakh | M |
| kz_M2 | Kazakh | M |
| kz_F3 | Kazakh | F |
| kz_F1 | Kazakh | F |
| kz_F2 | Kazakh | F |
| b_kjh | Khakas | F |
| b_kpv | Komi-Ziryan | M |
| b_lez | Lezghian | M |
| b_mhr | Mari | F |
| b_mrj | Mari High | M |
| b_nog | Nogai | F |
| b_oss | Ossetic | M |
| b_ru | Russian | M |
| b_tat | Tatar | M |
| marat_tt | Tatar | M |
| b_tyv | Tuvinian | M |
| b_udm | Udmurt | M |
| b_uzb | Uzbek | M |
| b_sah | Yakut | M |
| kalmyk_erdni | Kalmyk | M |
| kalmyk_delghir | Kalmyk | F |
(!!!) All input sentences should be romanized to ISO format using aksharamukha. An example for hindi:
# V3
import torch
from aksharamukha import transliterate
# Loading model
model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_tts',
language='indic',
speaker='v4_indic')
orig_text = "प्रसिद्द कबीर अध्येता, पुरुषोत्तम अग्रवाल का यह शोध आलेख, उस रामानंद की खोज करता है"
roman_text = transliterate.process('Devanagari', 'ISO', orig_text)
print(roman_text)
audio = model.apply_tts(roman_text,
speaker='hindi_male')| Language | Speakers | Romanization function |
|---|---|---|
| hindi | hindi_female, hindi_male |
transliterate.process('Devanagari', 'ISO', orig_text) |
| malayalam | malayalam_female, malayalam_male |
transliterate.process('Malayalam', 'ISO', orig_text) |
| manipuri | manipuri_female |
transliterate.process('Bengali', 'ISO', orig_text) |
| bengali | bengali_female, bengali_male |
transliterate.process('Bengali', 'ISO', orig_text) |
| rajasthani | rajasthani_female, rajasthani_female |
transliterate.process('Devanagari', 'ISO', orig_text) |
| tamil | tamil_female, tamil_male |
transliterate.process('Tamil', 'ISO', orig_text, pre_options=['TamilTranscribe']) |
| telugu | telugu_female, telugu_male |
transliterate.process('Telugu', 'ISO', orig_text) |
| gujarati | gujarati_female, gujarati_male |
transliterate.process('Gujarati', 'ISO', orig_text) |
| kannada | kannada_female, kannada_male |
transliterate.process('Kannada', 'ISO', orig_text) |
| Languages | Quantization | Quality | Colab |
|---|---|---|---|
| 'en', 'de', 'ru', 'es' | ✔️ | link |
Basic dependencies for Colab examples:
torch, 1.9+;pyyaml, but it's installed with torch itself
- Standalone usage only requires PyTorch 1.9+ and the Python Standard Library;
- Please see the detailed examples in Colab;
import torch
model, example_texts, languages, punct, apply_te = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_te')
input_text = input('Enter input text\n')
apply_te(input_text, lan='en')Denoise models attempt to reduce background noise along with various artefacts such as reverb, clipping, high/lowpass filters etc., while trying to preserve and/or enhance speech. They also attempt to enhance audio quality and increase sampling rate of the input up to 48kHz.
All of the provided models are listed in the models.yml file.
| Model | JIT | Real Input SR | Input SR | Output SR | Colab |
|---|---|---|---|---|---|
small_slow |
✔️ | 8000, 16000, 24000, 44100, 48000 |
24000 |
48000 |
|
large_fast |
✔️ | 8000, 16000, 24000, 44100, 48000 |
24000 |
48000 |
|
small_fast |
✔️ | 8000, 16000, 24000, 44100, 48000 |
24000 |
48000 |
Basic dependencies for Colab examples:
torch, 2.0+;torchaudio, latest version bound to PyTorch should work;omegaconf, latest (can be removed as well, if you do not load all of the configs).
import torch
name = 'small_slow'
device = torch.device('cpu')
model, samples, utils = torch.hub.load(
repo_or_dir='snakers4/silero-models',
model='silero_denoise',
name=name,
device=device)
(read_audio, save_audio, denoise) = utils
i = 0
torch.hub.download_url_to_file(
samples[i],
dst=f'sample{i}.wav',
progress=True
)
audio_path = f'sample{i}.wav'
audio = read_audio(audio_path).to(device)
output = model(audio)
save_audio(f'result{i}.wav', output.squeeze(1).cpu())
i = 1
torch.hub.download_url_to_file(
samples[i],
dst=f'sample{i}.wav',
progress=True
)
output, sr = denoise(model, f'sample{i}.wav', f'result{i}.wav', device='cpu')import os
import torch
device = torch.device('cpu')
torch.set_num_threads(4)
local_file = 'model.pt'
if not os.path.isfile(local_file):
torch.hub.download_url_to_file('https://models.silero.ai/denoise_models/sns_latest.jit',
local_file)
model = torch.jit.load(local_file)
torch._C._jit_set_profiling_mode(False)
torch.set_grad_enabled(False)
model.to(device)
a = torch.rand((1, 48000))
a = a.to(device)
out = model(a)Also check out our wiki.
Please refer to these wiki sections:
Please refer here.
Try our models, create an issue, join our chat, email us, and read the latest news.
Please refer to our wiki and the Licensing and Tiers page for relevant information, and email us.
@misc{Silero Models,
author = {Silero Team},
title = {Silero Models: pre-trained enterprise-grade STT / TTS models and benchmarks},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/snakers4/silero-models}},
commit = {insert_some_commit_here},
email = {hello@silero.ai}
}-
STT:
-
TTS:
-
VAD:
-
Text Enhancement:
- We have published a model for text repunctuation and recapitalization for four languages - link
-
STT
- OpenAI решили распознавание речи! Разбираемся так ли это … - link
- Наши сервисы для бесплатного распознавания речи стали лучше и удобнее - link
- Telegram-бот Silero бесплатно переводит речь в текст - link
- Бесплатное распознавание речи для всех желающих - link
- Последние обновления моделей распознавания речи из Silero Models - link
- Сжимаем трансформеры: простые, универсальные и прикладные способы cделать их компактными и быстрыми - link
- Ультимативное сравнение систем распознавания речи: Ashmanov, Google, Sber, Silero, Tinkoff, Yandex - link
- Мы опубликовали современные STT модели сравнимые по качеству с Google - link
- Понижаем барьеры на вход в распознавание речи - link
- Огромный открытый датасет русской речи версия 1.0 - link
- Насколько Быстрой Можно Сделать Систему STT? - link
- Наша система Speech-To-Text - link
- Speech-To-Text - link
-
TTS:
- Теперь наш синтез также доступен в виде бота в Телеграме - link
- Может ли синтез речи обмануть систему биометрической идентификации? - link
- Теперь наш синтез на 20 языках - link
- Теперь наш публичный синтез в супер-высоком качестве, в 10 раз быстрее и без детских болячек - link
- Синтезируем голос бабушки, дедушки и Ленина + новости нашего публичного синтеза - link
- Мы сделали наш публичный синтез речи еще лучше - link
- Мы Опубликовали Качественный, Простой, Доступный и Быстрый Синтез Речи - link
-
VAD:
-
Text Enhancement:
Please use the "sponsor" button.