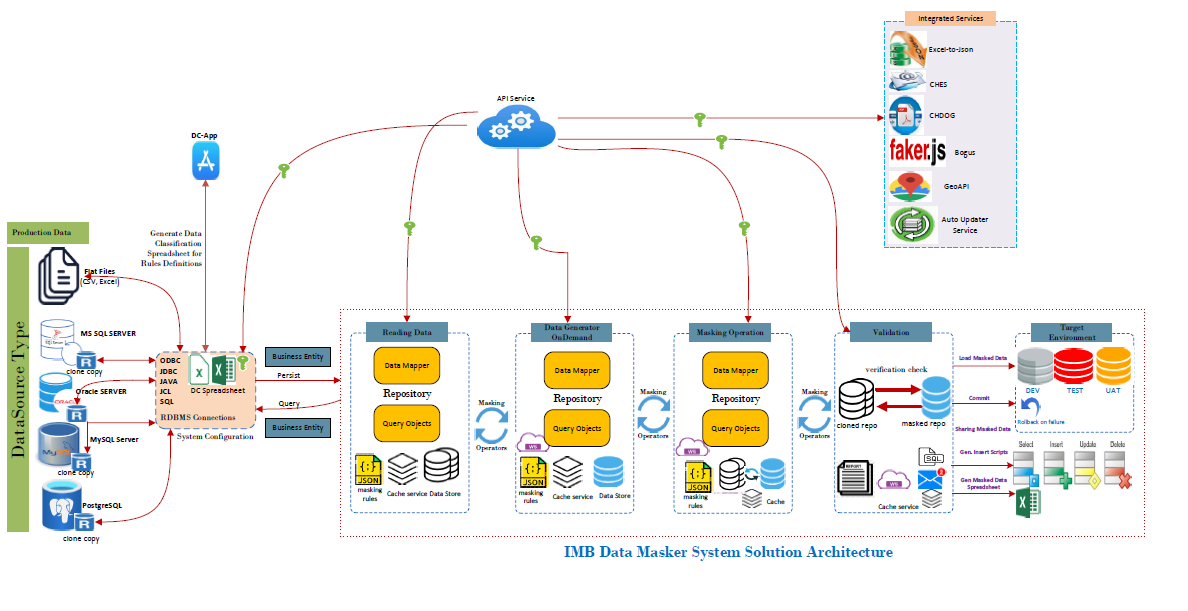
Solution Architecture
The Data Masker Client Application is an N-tier architecture designed using the Repository Architecture Pattern shown in Fig. 3. Repositories are classes or components that encapsulate the logic required to access data sources. They centralize common data access functionality, providing better maintainability and decoupling the infrastructure or technology used to access databases from the domain model layer. A repository performs the tasks of an intermediary between the domain model layers and data mapping, acting in a similar way to a set of domain objects in memory.
Client objects declaratively build queries and send them to the repositories for answers. Conceptually, a Repository encapsulates a set of objects stored in the database and operations that can be performed on them, providing a way that is closer to the persistence layer. Repositories, also, support the purpose of separating, clearly and in one direction, the dependency between the work domain and the data allocation or mapping
The Data Masker has 5 stages of operations:
- System Configuration - Configure the system with the required inputs i.e. Connection Strings of the source and target, data classification spreadsheet location
- Reading Data – read source data and store the data in a data store object (db01)
- Data Generator OnDemand – Generate fake data associated with the masking rule in the spreadsheet, store generated data in a data store object (db02)
- Masking Operation - replace the content of db01 with db02
- Validation– Check whether the replace operation was successful and all items are truly replaced by comparing db01 with db02. Sample is shown here
- Load to Target – Load masked data into the target environment or generate insert statements as output
- Report and Logs– Send email report and masking logs to the user